






接上一篇的博客,上一篇的博客中对chatgml3-6b模型进行了微调,在这篇博客中介绍如何将微调后的模型包装成接口,并提供给我们的网站使用。
一、使用微调后的模型
我们使用的是lora微调方式,而对于 LORA 和 P-TuningV2,ChatGLM没有合并训练后的模型,而是在adapter_config.json 中记录了微调型的路径。因此,需要合并微调后的参数和基础模型参数。对ChatGLM3/finetune_demo at main · THUDM/ChatGLM3 · GitHub 中的加载方式进行了简化(在我们生成的检查点文件夹中存在adapter_config.json文件,不需要进行判断,直接使用该分支提供的方式进行加载)。
from transformers import AutoTokenizer, AutoModel
from peft import AutoPeftModelForCausalLM, PeftModelForCausalLM
model_dir='/root/autodl-tmp/ChatGLM3/finetune_demo/output/checkpoint-300'#微调后的检查点模型路径
model = AutoPeftModelForCausalLM.from_pretrained(
model_dir, trust_remote_code=True, device_map='auto'
)
tokenizer_dir = model.peft_config['default'].base_model_name_or_path
tokenizer = AutoTokenizer.from_pretrained(
tokenizer_dir, trust_remote_code=True
)
out_dir='autodl-tmp/ChatGLM3/finetuneMode2'
# 把加载原模型和lora模型后做合并,并保存
merged_model = model.merge_and_unload()
merged_model.save_pretrained(out_dir, safe_serialization=True)
tokenizer.save_pretrained(out_dir)之后调用模型的merge_and_unload()方法合并预训练和微调的参数,输出合并的模型到指定文件夹中。之后用合并模型的路径替换原本的chatglm6b路径即可使用微调后的模型。
注意这里直接调用微调模型可能会出错,我参考以下博客修改后成功运行:
注:lora后的模型是具备垂直领域的能力,但这时候模型对很多通用能力已经不具备了或者回答很差,也就是所谓的灾难性遗忘。如果要想模型也具备通用领域能力,通常的做法是将lora权重和主模型进行融合,但这时候融合会带来一部分损失。需要对专业性和通用性进行权衡。
二、将模型封装成API供网站连接使用
使用flask框架提供的功能将服务器上运行的代码封装成接口的形式。
该部分是为了能够在本地上使用远程服务器上部署的模型。
在服务器端,接受客户端post过来的交互数据,传给合并后的模型(这里暂时没有使用历史记录),直接将json化的模型生成结果返回给客户端。
下面的host='0.0.0.0'表示监听来自任意ip地址的请求。
@app.route('/', methods=['POST'])
def infer():
data = request.json
input_text = data.get('input_text')
result = generate_response(input_text)
#result="回复"
return jsonify({'result': result})#将结果返回给本机的6006
def generate_response(input_text):
response, _ = model.chat(tokenizer, input_text, history=[])
return response
# 以上实现模型推理逻辑
if __name__ == '__main__':
app.run(host='0.0.0.0', port=6006)在客户端,使用request库中的post方法将请求传给服务器端,之后从返回的respose中获取到请求内容。
import requests
def run_client(input_text):
url = 'http://localhost:6006'
data = {'input_text': input_text}
response = requests.post(url, json=data)#发送给远程终端
if response.status_code == 200: # 200 表示请求成功
result = response.json()
print(result['result'])
else:
print('Error:', response.status_code)
if __name__ == '__main__':
input_text = "。。。"
run_client(input_text)三、内网穿透
在检索了一些内网穿透方法后,发现很多教程都要求服务器有公网ip,我们使用的服务器只能获取到它内网的ip
因为我们之前所有的部署都是在autodl算力平台上完成的(强推),检索后发现,autodl本身提供的开放端口供客户端使用的方法。
使用容器提供的自定义服务方法,按照教程使用ssh隧道,autodl默认开放6006端口,将客户端和服务器传递信息使用的端口号都统一成6006,即可在本地使用localhost地址,与服务器端进行交互。
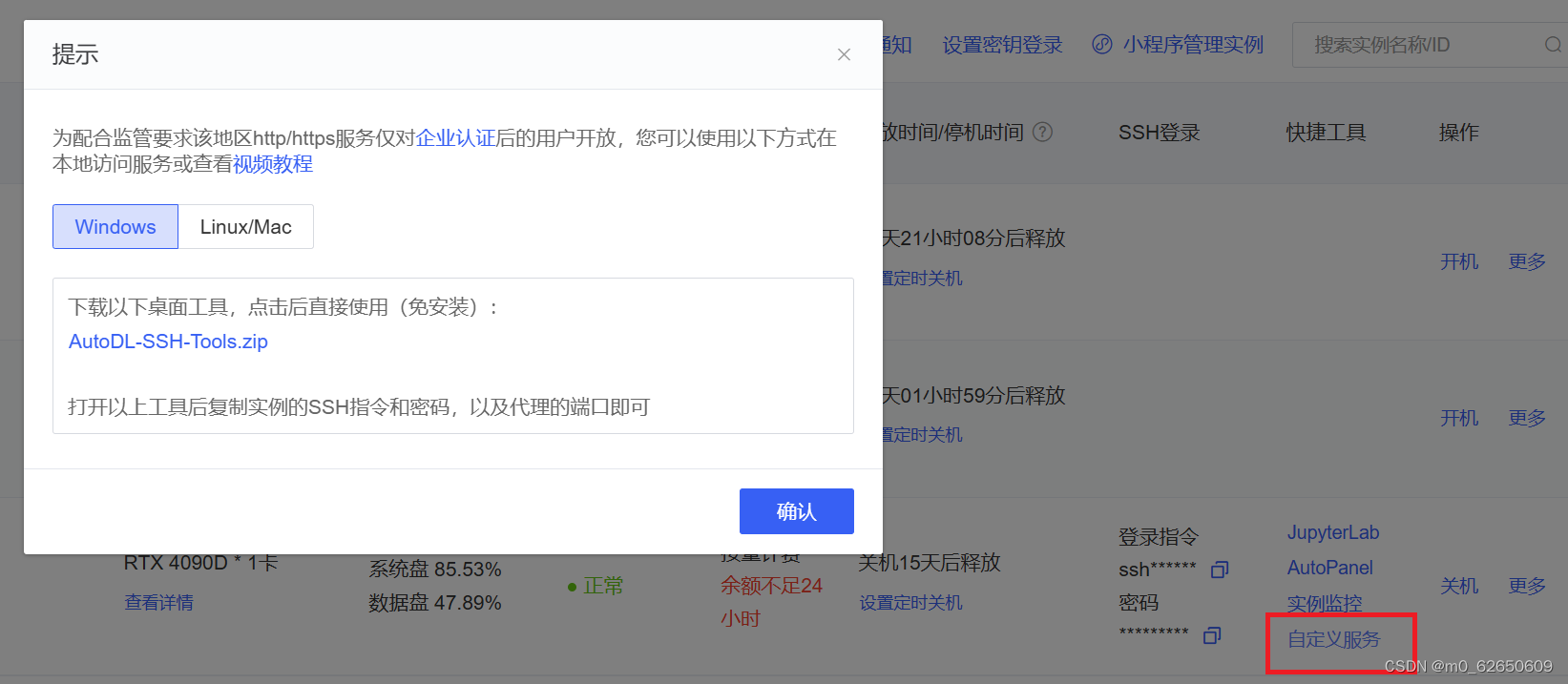
之后将调整客户端的请求方式,即可实现远程服务器支持的本地自定义功能。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









