






这里对我们使用微调/rag技术得到的psyLLM和原本未经过调整的ChatGLM进行对比和评估。
一、具体问题表现
因为我们使用的训练数据都是对话数据集,目的是想要提升模型对人们日常生活中各种情感琐事等的理解能力,所以我们准备的问题都是与之较为相关的对话类问题。
问题一:最近失恋了,心情不好
原本的chatglm:

微调后的模型:

rag后的模型:

问题二:想回家吃妈妈做的红烧肉了
原本的chatglm:

微调后的模型:

微调+rag:

问题三:最近工作很忙,时间安排不过来,不知道该怎么办了
原本的chatglm:

微调后的模型:

rag后的模型:

从上面的这些问题可以看出原本的ChatGLM模型对对话式的问题总是返回条目式的结果,与其沟通并不像与人沟通一样自然;微调和rag改善了这一情况,虽然加上rag可能会因为知识库中存在不相关的内容返回导致误导模型的回答,但对于知识库中较为相关的问题还是能够很大程度上提升回答质量。微调的效果显得比较生硬,经过检查后发现是 部署的基础模型本身参数量不如我们使用的基本模型的原因。
二、问卷调查结果
我们对原本的模型和我们使用微调+rag改进后的模型进行问卷调查,让参与调查的同学在使用过我们两个模型后,对两个模型进行盲审打分。
其中分四个打分指标:模型回答的易理解程度、切中心理感受程度、合理性、逻辑性
模型1:6.44,6.61,6.5,6.5
模型2:7.29,7.47,7.35,7.53
下面给出部分打分结果的展示:
请给模型1/2回答的易理解程度打分
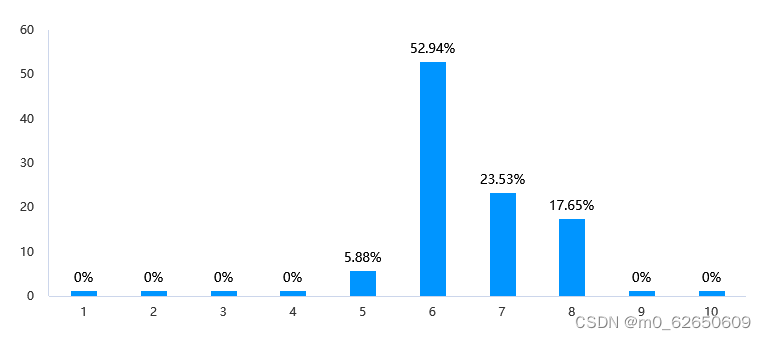
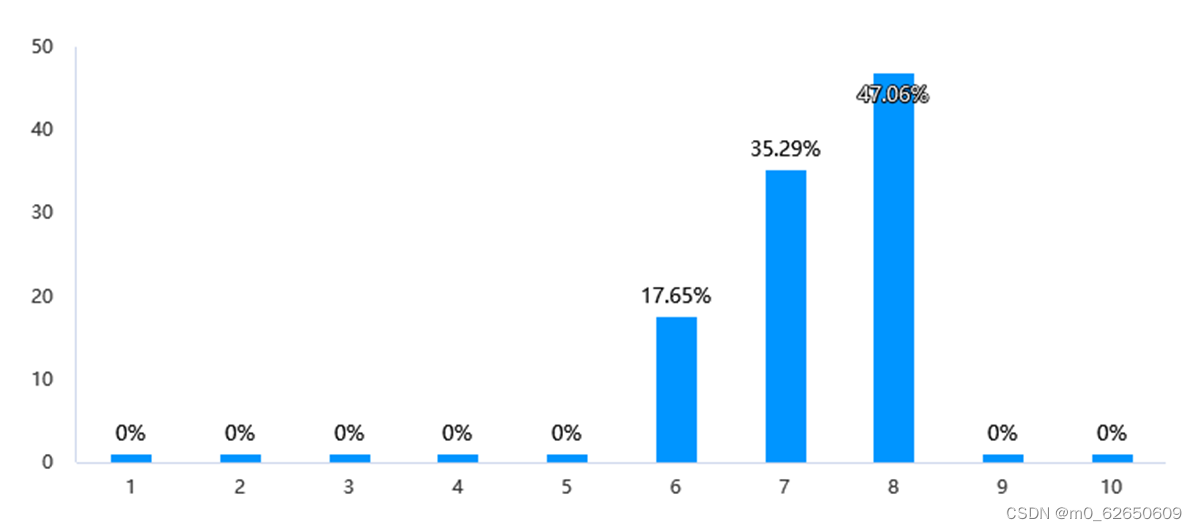
分析结论:模型1回答的易理解程度评分主要集中在6分和7分,分别占比52.94%和23.53%,合计76.47%。可以得出结论,大部分受访者认为模型1回答的易理解程度在中等偏上水平。模型2回答的易理解程度评分主要集中在7分和8分,分别占比35.29%和47.06%,合计超过80%。说明大多数人认为模型2回答的易理解程度较高,处于中高水平。
模型1易理解程度:
模型2易理解程度:
总结:
模型1评分情况
模型1易理解程度方面,大部分受访者给出了6分(52.94%)和7分(23.53%)的评分,整体易理解程度较高。
模型1的回答切中心理感受程度方面,大部分受访者给出了7分(52.94%)的评分,说明模型1在切中受访者心理感受方面表现较好。
在合理性和逻辑性方面,受访者对模型1的评分相对较为均衡,合理性主要集中在6-8分之间,逻辑性主要集中在6-8分之间。
模型2评分情况
模型2易理解程度方面,大部分受访者给出了8分(47.06%)的评分,易理解程度较高。
模型2的回答切中心理感受程度方面,受访者给出的评分相对较为均衡,主要集中在7-8分之间。
在合理性和逻辑性方面,受访者对模型2的评分也相对均衡,合理性主要集中在7-8分之间,逻辑性主要集中在7-8分之间。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









