







目录
memcpy
使用举例:
模拟实现:
memmove
使用举例:
模拟实现:
memcmp
使用举例:
模拟实现:
memcpy
memcpy是一个内存拷贝函数,它可以从源地址处拷贝n个字节到目的地地址处。
头文件:
#include<string.h>
库中的声明:
void *memcpy( void *dest, const void *src, size_t count );
- dest:目的地(即要把数据拷贝到哪个数组)
- src:源(即从哪里拷贝数组)
- count:要拷贝的个数,单位是字节(byte)
使用举例:
比如我们要从src数组中,拷贝前三个元素到dest数组中,那么我们就可以这么写:
int main()
{
int src[] = { 1,2,3,4,5 };
int dest[20] = { 0 };
memcpy(dest, src, 12);
return 0;
}可以看到src是一个int数组,所以每个元素都是4个字节(环境32位,16位则是2个字节),因为memcpy是按照字节拷贝的,所以要拷贝前三个元素就是12个字节,需要注意的是dest数组中应该有足够大的空间,以便于接收拷贝来的数据。

在我们的监视窗口可以看到确确实实是把前三个元素拷贝过来了。
模拟实现:
接下来来模拟实现一下memcpy:
//模拟实现memcpy
void* my_memcpy(void* dest, const void* src, size_t byte)
{
void* ret = dest;
assert(dest && src);
while (byte--)
{
*(((char*)ret)++) = *(((char*)src)++);
}
return dest;
}因为是模拟实现,所以函数的返回值和形参的类型,都是按照库中来的,形参void*的设计也是因为memcpy可以拷贝不同类型的数据,而因为它是按照字节来拷贝的,所以函数体中把dest和src都强制转换成char*,因为char所占大小时一个字节,所以解引用就可以访问一个字节的大小,这样就可以做到一个字节一个字节的拷贝了。
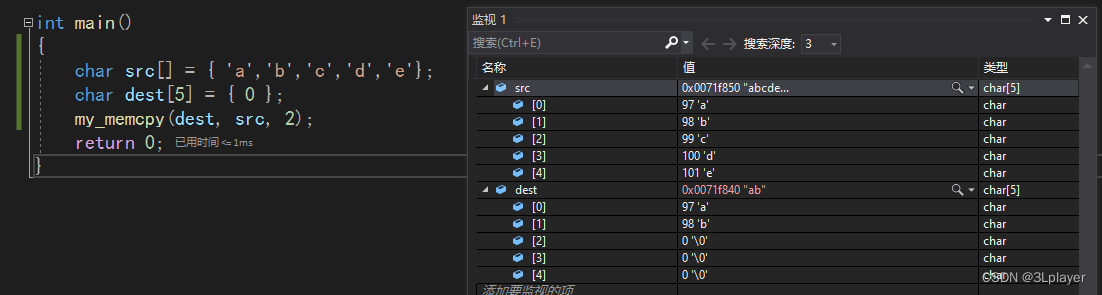
可以看到模拟实现的my_memcpy也可以完成拷贝。
memmove
memmove是一个内存移动函数,其实和memcpy类似,都是可以用来拷贝数据的,只不过memmove可以拷贝重叠的区域。
头文件:
#include<string.h>
库中的声明:
void *memmove( void *dest, const void *src, size_t count );
重叠的区域怎么理解呢?
举个例子:
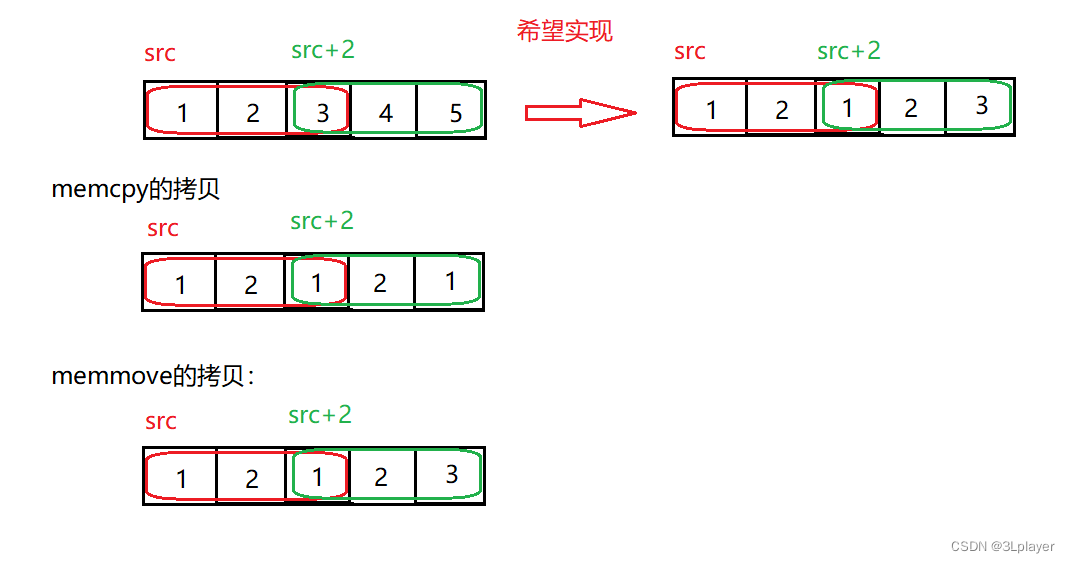
假设在同一块内存空间中,我们要把红框src的内容移动到绿框src+2的位置,这就是重叠区域的拷贝,可以看到memcpy会拷贝失败,而memmove可以拷贝成功,这是为什么呢?
很显然是因为两个函数的实现不同,memcpy是从前往后拷贝,这样在拷贝1的时候3就会被覆盖,所以到时了绿框的最后一个元素不是3而是1,而memmove根据不同的情况,可以有不同的拷贝的方法,就比如这里src+2的地址是大于src的,所以它在移动的时候采取的是从后往前拷贝的方法,也就是先把3拷贝到5的位置,再把2拷贝到4的位置,再把1拷贝到3的位置,这样就避免了元素可能被覆盖的问题。
使用举例:
- 不重叠区域的拷贝:
int main()
{
char src[] = { 'a','b','c','d','e'};
char dest[5] = { 0 };
memmove(dest, src, 3);
return 0;
}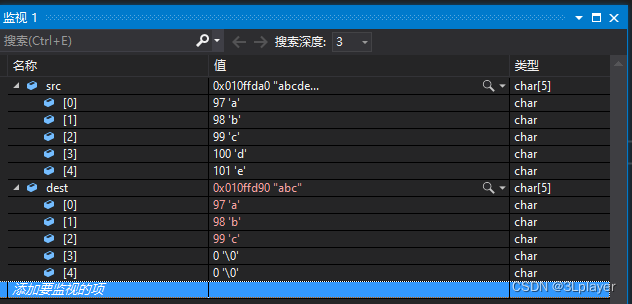
可以看到使用和功能都是和memcpy是一致的,拷贝了3个字节的数据到目的地数组。
- 重叠区域的拷贝:
int main()
{
char src[] = { 'a','b','c','d','e'};
char dest[5] = { 0 };
memmove(src + 2, src, 3);
return 0;
}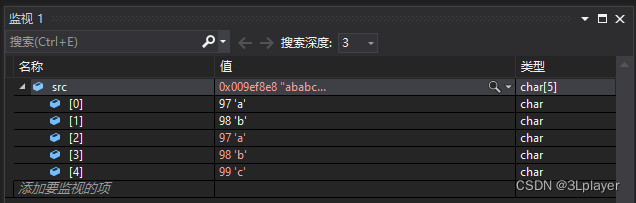
把src的前三个字母a、b、c拷贝到了src + 2的地址处,拷贝了memcpy所无法拷贝的重叠区域。
模拟实现:
接下来来模拟实现一下memmove:
//模拟实现memmove
void* my_memmove(void* dest, const void* src, size_t byte)
{
void* ret = dest;
assert(dest && src);
if (dest >= src)
{
while (byte--)
{
*(((char*)ret) + byte) = *(((char*)src) + byte);
}
}
else
{
while (byte--)
{
*(((char*)ret)++) = *(((char*)src)++);
}
}
return dest;
}可以看到在模拟实现中,分为了两种情况:
- dest地址 ≥ src地址
- dest地址 < src地址
dest地址大于等于src地址的情况我所采用的是从后往前拷贝,而小于的情况和memcpy是一致的,之前从前往后拷贝即可。
看图可能更方便理解,如下图:
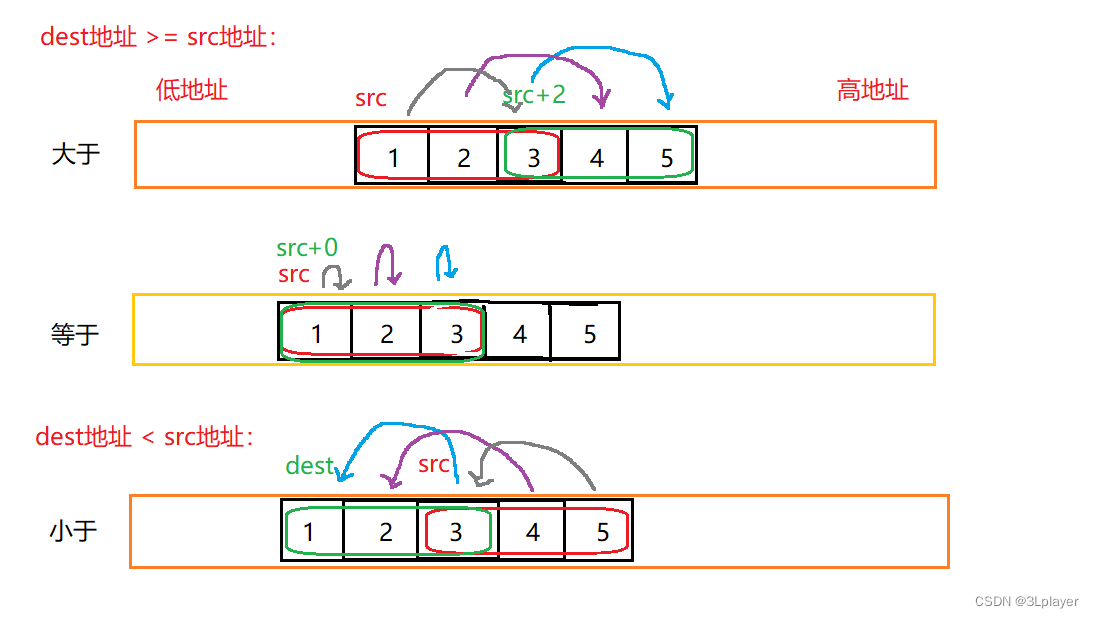
dest地址大于src地址时,为了最后一个元素不被覆盖,所以要从后往前拷贝。
dest地址小于src地址时,为了第一个元素不被覆盖,所以要从前往后拷贝。
dest地址等于src地址时,从前往后拷贝亦或从后往前拷贝都可以。
memcmp
memcmp是一个内存比较函数,它和strcmp不同,strcmp是比较每一个字符,而memcmp是比较每一个字节,根据返回值来判断双方的大小。
头文件:
#include<string.h>
库中的声明:
int memcmp( const void *buf1, const void *buf2, size_t count );
判断大小:
- buf1 > buf2(返回大于0的数)
- buf1 < buf2(返回小于0的数)
- buf1 == buf2(返回0)
使用举例:
- 接收返回值:
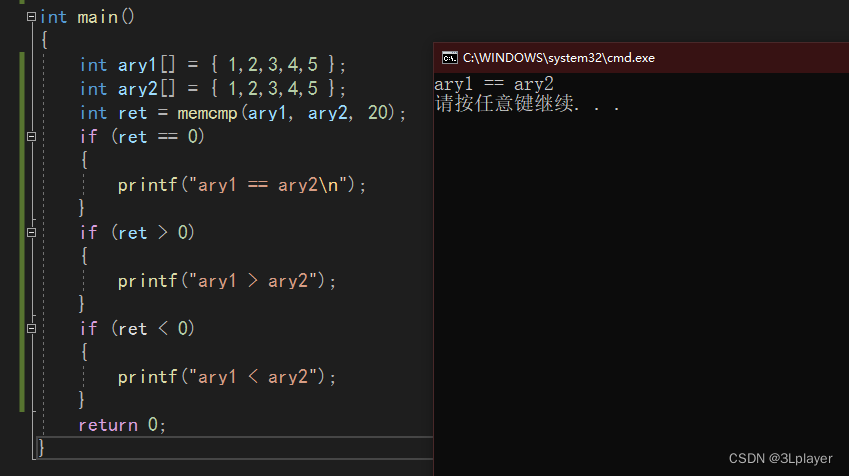
memcmp的返回值是int,所以用一个int变量来接收返回值,最后判断返回值属于哪种情况即可。
- 链式访问:
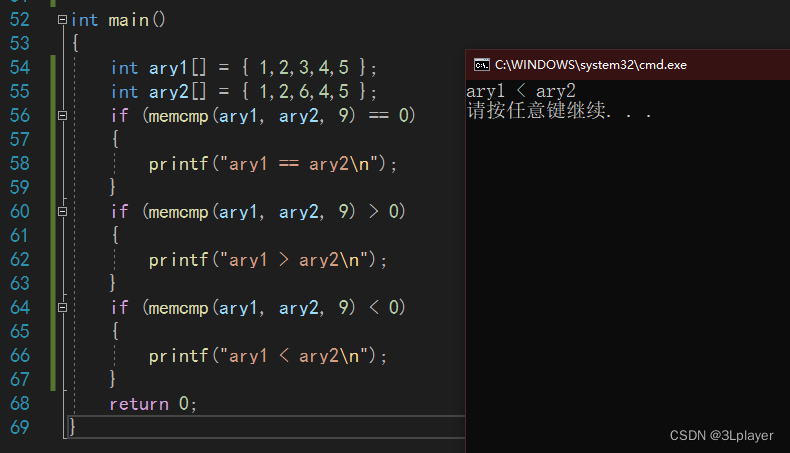
直接把memcmp的返回值,作为if语句中的一个参数,这样写也是可以的。
模拟实现:
//模拟实现memcmp
int my_memcmp(const void* buf1, const void* buf2, size_t count)
{
assert(buf1 && buf2);
while (*((char*)buf1) == *((char*)buf2) && count--)
{
((char*)buf1)++;
((char*)buf2)++;
}
return (*(char*)buf1) - (*(char*)buf2);
}因为是一个字节一个字节的比较,所以强制转换为char*就非常合适,然后再循环比较,最后返回buf1和buf2的差值,根据差值来判断大小关系。















 6875
6875











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









