







原论文标题:STaR-GATE: Teaching Language Models to Ask Clarifying Questions
适读人群:对大语言模型、个性化对话、智能体交互感兴趣的开发者、研究者或AI应用从业者
一、为什么这篇论文值得读?
在使用ChatGPT、Claude或其他AI助手时,你是否有以下经历:
-
你问了一个问题,但模型给出的答案看起来不够贴合,似乎它误解了你的真实需求;
-
你希望AI更像一个“聪明人”,能在不清楚的时候先反问你几句,而不是一味猜答案;
-
在某些场景下(如医疗、教育、产品推荐),你发现只有足够了解用户,AI才能做出更准确的回答。
如果你也有这些感受,那么这篇论文可能正好击中你的痛点。
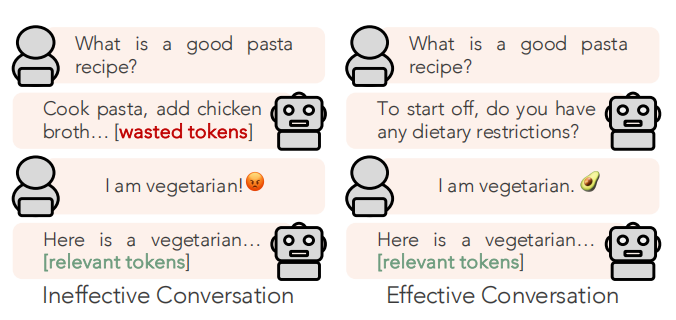
STaR-GATE 的核心目标就是:训练一个语言模型,让它在面对模糊的任务或用户请求时,学会主动提问,弄清楚你到底想要什么,再给出个性化回答。
传统训练方式,比如我们熟悉的RLHF(用人类反馈进行微调),虽然提高了模型的安全性和基本礼貌,却往往抑制了它“追问”和“互动”的能力。模型变得更像"答题机",不再"追根问底"。
而STaR-GATE的方法,让模型恢复“好奇心”,拥有真正的交互智慧。它就像一个擅长交谈的专家,在不清楚你的需求时,不是草率回答,而是一步步澄清信息,最终给出你真正需要的答案。
二、STaR-GATE做了什么?一句话总结:自我提问、自我学习、自我进化
论文提出一个新的训练框架叫 STaR-GATE,它的名字拆解如下:
-
STaR: Self-Taught Reasoner(自学型推理器)
-
GATE: Generative Active Task Elicitation(生成式主动任务提问)
整个框架结合了两个核心理念:
-
主动提问(Elicitation):让语言模型学会自己提出问题,而不是被动地接受输入。
-
自我改进(Self-Play):通过模拟对话、反复试错和筛选,逐步优化自己的“提问”和“回答”策略。
最终目的:教会一个小模型如何主动获取用户的真实需求信息,并基于这些信息生成更加精准的答案。
三、STaR-GATE的工作流程,简单通俗解释
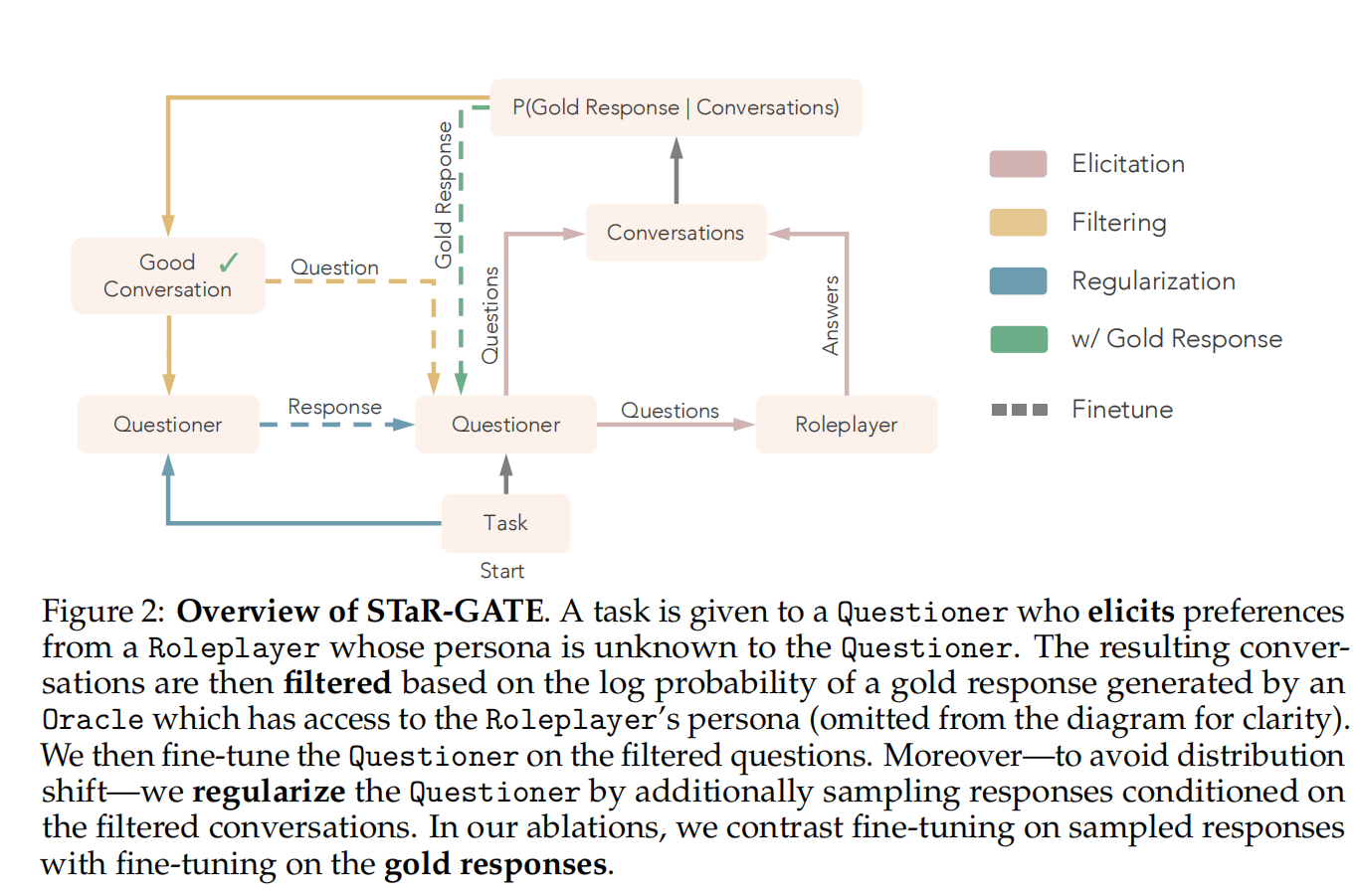
我们把STaR-GATE整个方法看作一次“交互式采访训练营”,分成四个角色:
-
Task(任务):比如“请推荐一款护肤品”或“帮我写一封道歉邮件”。这是用户的原始请求。
-
Roleplayer(扮演用户):我们模拟一个虚拟用户,背后有自己的偏好、人设(如“敏感肌、讨厌香精”),但不会一开始全告诉AI。
-
Questioner(提问者模型):我们要训练的AI,它面对用户任务,只知道最初的问题,要通过多轮提问逐步搞清楚对方的真实需求。
-
Oracle(金牌答题者):一个“全知模型”,知道任务+完整人设,可以给出完美的回答。我们用它生成标准答案 gold response,用来做训练参考。
整个流程如下:
-
Questioner看到任务,比如“推荐一道意面”,但不知道用户吃不吃辣,是不是吃素。
-
它通过多轮提问,比如:
-
“你有没有饮食偏好?”
-
“有没有过敏成分?”
-
“你更喜欢清淡的还是重口味?”
-
-
Roleplayer 根据人设作答。
-
Oracle 用任务+完整人设生成完美答案:比如“菠菜青酱意面,不含奶制品”
-
用评分系统判断:Questioner问的这些问题有没有问到点子上?
-
选出“问得最好”的一条问答历史,对模型进行微调
-
这个过程重复几轮,模型越来越会问、越来越会答。
四、STaR-GATE的数据是怎么来的?(合成数据构建)
为了训练和评估模型,作者构建了一个包含25,500组“任务-用户人设-gold response”的数据集。
每组数据包含:
-
一个真实任务(比如“推荐一部电影”);
-
一个模拟用户人设(比如“浪漫主义者、对暴力镜头敏感、喜欢80年代”);
-
一个Gold Response(个性化答案,比如“推荐你《真爱至上》,温馨感人、无暴力”)
数据来源:
-
任务来自公开数据集 instruct-human-assistant-prompt
-
人设由GPT-4 few-shot生成(21种模板变形)
-
Gold Response由GPT-4生成,作为Oracle输出
这样每组样本都具备真实感+个性化+可控性。
五、STaR-GATE的训练过程具体是怎么实现的?(核心技术流程详解)

本节我们来一条一条拆解 STaR-GATE 是如何训练模型学会“会问、会答”的。
1️⃣ 输入输出是什么?
-
输入: 任务 t_i(如“请推荐一道晚餐”)+ 提问历史 s_{ij}(由Questioner与Roleplayer互动生成)
-
输出: 模型生成的最终回答 r,或下一轮问题 q
-
监督信号: gold response(Oracle提供)用于引导模型学会发问与个性化回答
2️⃣ 每一轮训练都做了什么?(一图胜千言,结构化说明)
-
从数据集中采样一个任务 t_i 和一个用户人设 u_j
-
让 Questioner 模拟与 Roleplayer 的多轮对话(最多三轮),采样 N=10 个问答历史 s_{ij}^{(n)}
-
用 Oracle(GPT-4)在“知道任务 + 知道人设”条件下生成 gold response g_{ij}
-
使用 Q_BASE(未训练模型)计算每个 s_{ij}^{(n)} 下生成 g_{ij} 的 log probability,选出最优一条
-
用这条“最有价值的对话历史”作为训练数据:
-
微调模型的提问能力(对话中的问题序列)
-
微调模型的回答能力(基于历史生成回答)
-
使用正则化防止模型偏离人设或忘记如何作答
-
3️⃣ 核心目标函数(非数学推导,简要理解)
-
最大化模型在对话历史下生成 gold response 的概率
-
同时鼓励模型提出能有效提升这个概率的问题
-
引入 response regularization 正则项,约束模型不要偏离原始分布(防止幻觉/过拟合)
4️⃣ 简化伪代码(直观理解)
For each task t_i and persona u_j:
Generate gold_response = Oracle(t_i, u_j)
For n = 1 to 10:
dialog_n = SimulateDialog(Questioner, Roleplayer)
score_n = Q_BASE.log_prob(gold_response | t_i, dialog_n)
Select best dialog_n*
Finetune Questioner on:
- dialog_n*.questions
- self-generated response
- with response regularization这一流程正是 STaR-GATE 的核心所在 —— 把主动提问变成模型可学、可优化、可自我提升的能力。
接下来,我们将看看这些训练出来的模型,表现究竟如何。
六、STaR-GATE如何判断“问得好不好”?
核心评估指标:
-
Gold Log-Probability:
-
模型根据当前对话历史生成 gold response 的概率。
-
概率越高,说明你“问”的问题让模型更接近真实答案。
-
-
Win Rate(胜率):
-
把新模型和老模型回答的答案交给GPT-4,让它投票哪个更贴合用户。
-
新模型胜率越高,说明主动追问确实帮忙了。
-
七、消融实验:什么策略最有效?
作者通过多组实验发现:
-
只训练“怎么问” → 模型变成“话痨AI”,不断追问但不会总结回答。
-
只用gold response训练 → 模型容易出现“幻觉”,在没问清楚时就乱答。
-
不进行正则化 → 模型容易忘记怎么答题。
最终有效方案是:提问 + 自答 + 正则化 = 全面升级。
八、真实样例展示(来自论文附录)
我们来看一个简化示例:
任务:
帮我推荐一道适合晚餐的菜
人设:
健身人士,不吃碳水、乳糖不耐、讨厌炒菜味道
传统模型直接答:
推荐你番茄意面,简单美味!
STaR-GATE提问流程:
-
Q1:你对饮食有没有特殊限制?
-
A1:我乳糖不耐,不太吃碳水。
-
Q2:你喜欢什么口味类型?
-
A2:清淡为主,讨厌重油重盐。
最终回答:
推荐你凉拌鸡胸肉佐藜麦沙拉,低碳高蛋白,清爽健康。
是不是瞬间专业了?这就是主动追问带来的价值!
九、这篇论文的意义是什么?
现实意义:
-
让AI不仅“答得好”,更“问得准”;
-
面向未来智能体系统,主动理解用户是关键能力;
-
适用于医疗、教育、推荐、办公助手等场景。
方法优势:
-
不依赖大模型做最终部署(训练完可压缩);
-
数据合成+评分体系完全可复现;
-
方法简单明了,工程可落地性强。
十、你能如何用这个方法?
你可以:
-
用STaR-GATE思路训练自己的对话系统(开源模型+数据+prompt)
-
将其用于推荐系统、客服系统、教育AI中,让模型主动澄清模糊需求
-
设计自己的数据生成机制(参考附录A.2-A.6)
十一、结语
这篇论文不是在卷大模型,而是在回答一个朴素而重要的问题:
“AI到底能不能像人一样,真正懂我们?”
STaR-GATE给出了一个方向:
学会主动追问,是迈向智能体的第一步。
它给开发者、研究者、产品设计师都提供了一个新视角。
不止会答题,而是先问“你是谁?你真正想要的是什么?”



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











