






目录
第一章 概述
待续…
第2章 HDFS
【问题1】分布式文件系统有很多,为何Hadoop要单独再开发一个HDFS?
答:
Hadoop开发了自己的分布式文件系统(HDFS)主要是为了满足其大数据处理框架的需求。下面是一些原因解释为何Hadoop选择单独开发HDFS:
- 适应大数据处理:Hadoop旨在处理大规模数据集,传统的文件系统无法有效地处理这样的数据规模。HDFS是专门为大数据处理而设计的,它采用分布式存储和计算的架构,可以处理PB级数据,并能够在集群中高效地存储和处理大型文件。
- 容错性和可靠性:Hadoop的设计目标之一是能够在大规模集群中运行,并处理大量的数据。HDFS采用了冗余机制,将数据划分为块并在集群中复制多个副本,以确保数据的容错性和可靠性。如果某个节点或硬盘发生故障,仍然可以从其他副本中访问数据,保证了数据的可靠性。
- 数据局部性:HDFS的设计考虑了数据局部性原理。它将数据块存储在集群中的不同节点上,并尽可能将计算任务分配给存储有相应数据块副本的节点。这样可以最大程度地减少数据的网络传输,提高数据访问和计算的效率。
- 与Hadoop生态系统的集成:Hadoop不仅仅是一个分布式文件系统,还包括了一个分布式计算框架(MapReduce)和许多其他组件(如YARN调度器)。HDFS作为Hadoop的底层存储系统,与其他组件紧密集成,可以提供高效的数据读写和处理能力。
尽管有其他分布式文件系统可用,但Hadoop选择开发HDFS是为了满足其特定的大数据处理需求,并与其生态系统紧密集成。HDFS在大规模数据存储和处理方面具有优势,并已成为Hadoop框架的核心组件之一。
【问题2】为何HDFS不支持对文件数据的修改?
答:
HDFS(Hadoop分布式文件系统)主要是为大规模数据的存储和批量处理而设计的,因此不支持对文件数据的直接修改是出于以下几个考虑:
-
数据一致性:HDFS的设计目标之一是提供高度的数据可靠性和一致性。为了实现这一目标,HDFS采用了一种写一次、多次读取的模式,即一旦数据被写入HDFS,就不再修改。这种设计保证了数据的完整性和一致性,并简化了系统的复杂性。
-
分布式存储和处理:HDFS采用了分布式存储和计算的架构,将文件切分为多个数据块并在集群中分散存储。这种分布式存储的方式使得对文件数据的直接修改变得复杂和低效。如果允许修改文件数据,可能需要协调和同步大量分布在不同节点上的数据副本,增加了系统的复杂性和开销。
-
顺序写入优化:HDFS的写入操作是以追加(append)方式进行的,即只能在文件末尾添加新的数据块,而不能在文件中间或任意位置插入数据。这种顺序写入的方式对于大规模数据处理和批量操作来说是高效的,但对于随机访问和修改操作则不太适合。
【问题3】对HDFS来讲,什么是文件的元数据(metadata)?为何NameNode的元数据需要做持久化处理?为何持久化又需要使用FSImage+EditsLog的方式进行?
答:
对于HDFS来说,文件的元数据(metadata)是指关于文件的描述信息,包括文件名、路径、文件大小、创建时间、访问权限、副本数量、数据块的位置等。元数据并不包括文件的实际数据内容,而是关于文件的属性和结构的信息。
NameNode是HDFS的关键组件,负责管理文件系统的元数据。NameNode的元数据需要进行持久化处理的主要原因是确保元数据的可靠性和可恢复性。持久化元数据意味着将元数据写入磁盘,以防止系统故障或重启后丢失。
为了实现元数据的持久化,HDFS使用了FSImage+EditsLog的方式:
- FSImage:FSImage是一个镜像文件,它包含了NameNode在特定时间点的完整文件系统状态的元数据。FSImage文件是通过将内存中的元数据写入磁盘而创建的,每当NameNode启动时,它会从FSImage文件中读取元数据并加载到内存中。
- EditsLog:EditsLog是一个日志文件,用于记录NameNode上的所有文件系统操作(如文件创建、重命名、删除等)的变更。这些变更以追加(append)的方式写入EditsLog文件,而不是立即写入FSImage文件。EditsLog文件记录了元数据的增量变更,可以看作是元数据的事务日志。
通过将FSImage文件和EditsLog文件结合使用,HDFS可以实现元数据的持久化和恢复。在NameNode启动过程中,它会首先加载FSImage文件,恢复到最近一次持久化的文件系统状态,然后将EditsLog文件中的增量变更应用于内存中的元数据,使其更新到最新状态。
这种FSImage+EditsLog的方式允许NameNode在故障恢复时快速加载持久化的FSImage文件,然后应用相对较小的EditsLog文件以恢复最新的文件系统状态,减少了系统恢复的时间和资源开销。此外,将元数据的变更记录在EditsLog文件中,也为元数据的审计、回溯和复制提供了方便。
【问题4】为何说block和offset是HDFS中两个重要的属性?
答:
在HDFS(Hadoop分布式文件系统)中,"block"和"offset"是两个重要的属性,具有以下重要性:
- Block(数据块):HDFS将大文件切分为固定大小的数据块进行存储。每个数据块通常默认大小为128MB(可以根据配置进行调整)。数据块是HDFS进行数据存储和传输的基本单位。将文件切分为数据块的方式有助于提高数据的并行处理能力和容错性。数据块的大小通常要比传统文件系统中的块(通常为4KB)大得多,这是为了减少存储和检索大数据集时的元数据开销。数据块还支持在集群中分布式存储,以便并行地处理数据。
- Offset(偏移量):Offset指的是文件中特定位置的字节偏移量。在HDFS中,文件被划分为多个数据块,而每个数据块又被划分为固定大小的数据块(通常为64KB)。偏移量用于标识文件中的特定位置,以便进行数据的读取和写入操作。通过指定偏移量,可以精确地读取或写入文件的特定位置,而无需处理整个文件。
这两个属性的重要性在于它们提供了数据在HDFS中的物理存储和访问的基础。通过将文件划分为数据块并使用偏移量来定位特定位置,HDFS能够实现高效的并行数据访问和处理。数据块的概念使得HDFS可以将大文件分布式存储在多个节点上,并实现数据的冗余备份,提高了数据的容错性和可靠性。同时,通过指定偏移量,可以在文件中进行随机或定位读写操作,而无需加载整个文件,这在大数据集的处理中尤为重要。
【问题5】心跳机制是分布式系统中的重要运行策略,为何在HDFS中也要采用心跳机制去做NameNode和DataNode之间的通信?
答:
在HDFS中,采用心跳机制进行NameNode和DataNode之间的通信是为了实现集群的健康监测、状态更新和故障检测。下面是几个原因解释为何在HDFS中采用心跳机制:
- 健康监测和状态更新:通过心跳机制,DataNode可以定期向NameNode发送心跳信号,表明自己处于正常工作状态。这使得NameNode能够监测DataNode的健康状况,并了解集群中各个DataNode的状态信息。心跳信号还包含了DataNode上存储的块信息、空闲存储容量以及负载等重要数据,帮助NameNode了解集群的整体情况,进行负载均衡和资源管理。
- 故障检测和容错性:心跳机制允许NameNode实时监测DataNode的状态。如果NameNode在一定时间内没有收到某个DataNode的心跳信号,就会认为该DataNode发生了故障或失去了连接。通过心跳机制,NameNode可以及时检测并处理DataNode的故障,比如重新复制存储在故障DataNode上的数据块到其他正常节点,确保数据的容错性和可靠性。
- 动态扩展和节点加入:当新的DataNode加入HDFS集群时,它会发送心跳信号,告知NameNode自己的存在和可用性。NameNode接收到新节点的心跳信号后,将其纳入集群管理,并为其分配数据块和任务。这种方式使得HDFS能够动态扩展并适应新节点的加入。
总之,通过心跳机制,HDFS可以实现对集群中DataNode的健康状况、状态信息和故障检测的监控,确保集群的正常运行和数据的可靠性。同时,心跳机制也支持集群的动态扩展和节点的加入,使得HDFS能够应对不断变化的分布式环境。
【问题6】HDFS中的HA和联邦机制的区别是什么?
答:
HDFS中的HA(高可用性)和联邦机制是两种不同的架构和部署方式,它们有以下区别:
- 高可用性(HA):HA是为了提高HDFS的可用性而设计的一种机制。在HA模式下,HDFS集群中有两个关键组件:一个是主NameNode(Active NameNode),另一个是备用NameNode(Standby NameNode)。主NameNode负责处理客户端的请求和元数据操作,而备用NameNode则处于热备状态,与主NameNode保持同步。如果主NameNode发生故障,备用NameNode可以快速接管成为新的主节点,确保HDFS的持续可用性。HA机制通过ZooKeeper
(ZooKeeper是一个开源的分布式协调服务,用于构建可靠的分布式系统。它提供了一个高性能的、可靠的分布式协调基础设施,用于解决分布式系统中的一致性问题和协调问题。)进行故障检测和状态同步,确保只有一个NameNode处于活动状态。 - 联邦机制:联邦机制是为了解决单个NameNode的性能和存储限制而引入的一种架构。在联邦机制下,HDFS集群中有多个独立的NameNode,每个NameNode管理一部分文件系统命名空间和数据块。这样,不同的NameNode可以并行地处理客户端的请求和元数据操作,提高了整个集群的性能和容量。每个NameNode都有自己的命名空间和元数据,相互之间是独立的,但可以通过共享数据块和命名空间的方式进行协作。
总的来说,HA机制主要关注提高HDFS的可用性,通过主备的方式确保在主节点故障时快速切换到备用节点,保持服务的连续性。而联邦机制则关注提高整个HDFS集群的性能和容量,通过将命名空间和数据块分布到多个独立的NameNode上,实现并行处理和扩展。
【问题7】总结本学期到目前为止,你在学习HDFS时已经接触到的一些分布式系统机制/策略,并猜测它们是否会被其他模块/项目借鉴,给出案例说明。
答:
在学习HDFS期间,我接触到了几个分布式系统机制/策略,它们可能会被其他模块/项目借鉴。以下是一些例子:
- 数据切片与数据块:HDFS将大文件切分为固定大小的数据块进行存储,这种数据切片的机制可以提高数据的并行处理和容错性。其他分布式系统也可以采用类似的数据切片策略,将大数据集切分为小块进行并行处理,例如分布式计算框架Apache Spark就使用了类似的数据切片机制。
- 心跳机制:HDFS中使用心跳机制实现了NameNode和DataNode之间的通信和故障检测。这种心跳机制可以在其他分布式系统中用于实现节点之间的健康监测、状态更新和故障检测。例如,Apache Storm是一个分布式实时计算系统,它使用心跳机制来监测和管理其分布式计算节点。
- 高可用性(HA):HDFS的HA机制通过主备NameNode的方式确保了系统的高可用性。这种HA机制可以被其他分布式系统借鉴,以提供容错和故障恢复能力。例如,Apache HBase是一个分布式的NoSQL数据库,它借鉴了HDFS的HA机制来实现主备节点的切换,确保数据库的持续可用性。
- 分布式协调服务:HDFS中使用ZooKeeper作为分布式协调服务,用于实现一致性和协调。其他分布式系统也可以使用类似的分布式协调服务来解决一致性问题和分布式锁分布式锁(是一种用于实现分布式系统中资源互斥访问的机制。)问题。例如,Apache Kafka是一个分布式流处理平台,它使用ZooKeeper来管理集群的元数据和协调分布式订阅者。
这些机制和策略在HDFS中已经被验证和应用,并且它们的设计和实现思想具有普遍适用性。因此,其他分布式系统和项目可以从中借鉴和应用这些机制,以提高系统的性能、可靠性和可扩展性。
ZooKeeper:
ZooKeeper是一个开源的分布式协调服务,用于构建可靠的分布式系统。它提供了一个高性能的、可靠的分布式协调基础设施,用于解决分布式系统中的一致性问题和协调问题。
ZooKeeper的设计目标是为分布式系统提供简单和可靠的协调机制,使开发人员可以更专注于业务逻辑而不是分布式系统的复杂性。它提供了一组原语(例如节点创建、写入、读取、删除等),可以用于构建各种分布式应用场景。
以下是一些ZooKeeper的特性和用途:
-
原子性:ZooKeeper提供原子性操作,确保分布式系统中多个节点之间的操作是原子的,避免了并发冲突和数据不一致的问题。
-
顺序一致性:ZooKeeper保证对于所有客户端请求的执行顺序是一致的,这对于实现分布式锁和选举算法非常重要。
-
可靠性:ZooKeeper通过多个副本和选举算法来保证高可用性和容错性,即使在部分节点故障的情况下仍能提供可靠的服务。
-
监听机制:ZooKeeper提供了监听机制,允许客户端注册对节点变化的监听器,当节点发生变化时,客户端可以接收通知并采取相应的操作。
-
分布式锁:ZooKeeper可以用于实现分布式锁,保证在分布式环境下的互斥访问。
-
配置管理:ZooKeeper可以用于存储和管理分布式系统的配置信息,当配置发生变化时,通知相关的节点进行更新。
总之,ZooKeeper是一个高性能、可靠的分布式协调服务,为构建分布式系统提供了一致性和协调的基础设施。它广泛应用于分布式数据库、分布式缓存、分布式锁、分布式队列等各种分布式应用场景中。
分布式锁:
分布式锁是一种用于实现分布式系统中资源互斥访问的机制。在分布式环境中,多个进程或节点可能同时访问共享资源,为了避免数据竞争和保证数据的一致性,需要使用分布式锁来实现同步和互斥。
分布式锁的主要目标是确保在分布式系统中只有一个进程或节点可以获取到锁,从而保证在任意时刻只有一个进程能够访问共享资源。当一个进程获取到分布式锁后,其他进程需要等待或阻塞直到锁被释放。
分布式锁的实现可以借助于分布式协调服务(如ZooKeeper、etcd等)或者其他分布式一致性协议。常见的分布式锁实现方式包括:
-
基于数据库:可以使用数据库的事务机制来实现分布式锁,通过在数据库中创建一个特定的行或记录作为锁标识,并使用事务的原子性来确保只有一个进程可以成功插入或更新该行。
-
基于共享存储:可以使用分布式文件系统或分布式共享存储来创建锁文件或锁节点。通过创建和获取特定的文件或节点来表示锁的状态,只有一个进程能够成功创建或获取到该文件或节点,其他进程需要等待。
-
基于分布式协调服务:可以使用分布式协调服务如ZooKeeper等来实现分布式锁。通过在协调服务上创建临时节点或者基于有序节点的方式来实现互斥访问。只有成功创建临时节点或者获取到最小有序节点的进程才能够获得锁。
分布式锁的设计和实现要考虑到高可用性、性能、死锁避免等方面的问题。分布式锁被广泛应用于分布式系统中,例如分布式数据库、分布式缓存、分布式任务调度等场景,以确保数据的一致性和正确性。
第3章 MapReduce
【问1】什么是Map计算?什么是Reduce计算?为何说Map+Redcue的计算组合非常适合拆解计算任务,并套用分布式计算?
答:
在分布式计算中,Map计算和Reduce计算是一种常见的计算模型,它们被广泛应用于分布式处理大规模数据集的任务。以下是对Map计算、Reduce计算以及它们为何适合拆解计算任务并应用于分布式计算的解释:
- Map计算:Map计算是指将输入数据集中的每个元素映射为一组键-值对的过程。在Map计算中,针对输入的每个数据项,都会应用一个映射函数,将其转换为一组键-值对,其中键表示数据项的某个特征,值表示对应的转换结果。Map计算是一种并行计算模型,不同的输入数据项可以并行地进行转换,提高了计算的速度和效率。
- Reduce计算:Reduce计算是指将Map计算输出的键-值对按照键进行分组,并对每个组进行聚合计算的过程。在Reduce计算中,相同键的键-值对会被合并在一起,并应用一个聚合函数来生成最终的结果。Reduce计算也是一种并行计算模型,不同组的计算可以并行进行,从而加快整体计算的速度。
- Map+Reduce的计算组合:Map+Reduce的计算组合非常适合拆解计算任务并套用分布式计算的原因如下:
(1) 易于拆解:Map计算和Reduce计算模型的结构清晰,易于将复杂的计算任务拆解为多个独立的Map和Reduce任务。每个Map任务之间是相互独立的,可以并行处理不同的数据项,而每个Reduce任务也可以独立处理不同的键组,从而实现任务的并行执行。
(2) 数据本地性:Map+Reduce模型利用数据本地性原则,将计算任务分发到存储数据的节点上进行处理。由于数据存储在分布式文件系统(如HDFS)中,Map和Reduce任务可以在存储数据的节点上执行,减少了数据传输的开销,提高了计算效率。
(3) 容错性:Map+Reduce模型具有良好的容错性。由于计算任务被分解为多个Map和Reduce任务,每个任务可以独立执行并产生中间结果。如果某个任务失败,可以重新启动失败的任务,而不需要重新执行整个计算过程,从而提高了计算的可靠性。
(4) 扩展性:Map+Reduce模型可以方便地扩展到大规模的计算集群。通过增加计算节点,可以并行执行更多的Map和Reduce任务,从而实现水平扩展和加速计算过程。
因此,Map+Reduce的计算组合非常适合拆解计算
【问题2】为何会出现YARN这个开源项目?
答:
YARN(Yet Another Resource Negotiator)是Apache Hadoop生态系统中的一个开源项目,它被引入的主要原因是为了解决Hadoop MapReduce计算框架的一些限制和不足。以下是一些导致出现YARN项目的主要原因:
- 资源利用率和多样化计算模型:早期的Hadoop MapReduce计算框架主要针对批处理任务,它的资源调度和管理方式比较简单,只适用于特定类型的计算工作负载。然而,随着大数据处理的发展和多样化的计算需求,需要一种更灵活和通用的资源管理系统,以提高资源利用率并支持各种计算模型,如实时流处理、图计算等。
- 集中式资源管理:早期的Hadoop MapReduce框架中,资源的调度和管理由JobTracker负责,它是一个单点故障,并且无法满足大规模集群的需求。为了提高集群的可扩展性和可靠性,需要引入一种分布式的资源管理系统,使资源管理能够分布到多个节点上,提供高可用性和横向扩展能力。
- 多租户支持:在共享的大数据集群中,不同用户或不同应用程序需要公平地共享资源,并且需要限制资源的使用量,以避免资源的过度分配和不公平的竞争。因此,需要一种能够支持多租户的资源调度和隔离机制,使不同的用户或应用程序可以在共享集群中公平地使用资源。
基于以上需求和考虑,YARN项目被引入作为Hadoop生态系统的资源管理和调度平台。YARN将资源管理与计算任务的调度分离开来,引入了一个全局的资源管理器(ResourceManager)和一个应用程序主管(ApplicationMaster)的概念。ResourceManager负责集群级别的资源分配和管理,而ApplicationMaster则负责应用程序级别的资源管理和任务调度。这种分离的架构使得YARN更加灵活、可扩展,并能够支持多样化的计算模型和多租户需求。
通过YARN,Hadoop生态系统得以支持更广泛的计算框架和应用程序,使得Hadoop集群成为一个通用的大数据处理平台。同时,YARN的设计思想和架构也为其他分布式计算和资源管理项目提供了参考和借鉴的价值。
【问题3】对照下面这张图,用自己的语言描述MR执行过程。
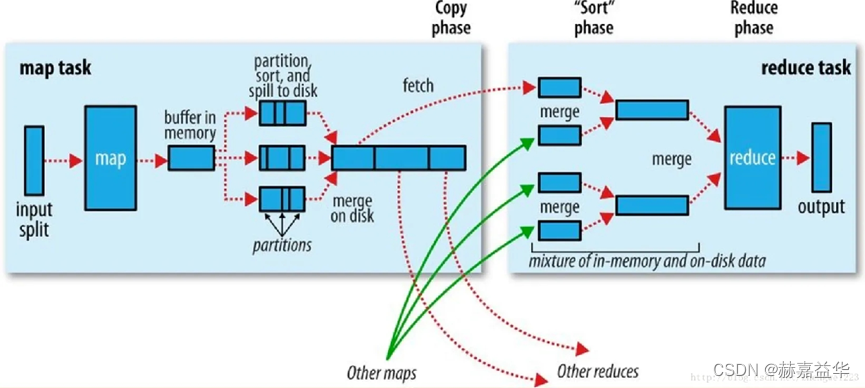
答:
详解:
MapReduce是一种并行处理大规模数据集的计算模型,它将计算任务分解为两个主要阶段:Map阶段和Reduce阶段。以下是对MapReduce执行过程中各个步骤的描述:
-
Map Task阶段:
- Input Split:输入数据被切分成多个块,称为Input Split。每个Input Split都由一个Map任务处理。这样可以将输入数据并行地分配给不同的Map任务。
- Map函数:每个Map任务读取一个Input Split,并将其转换为一系列键-值对。Map函数对每个输入数据项应用特定的映射逻辑,将其转换为一组中间结果。
- Buffer in Memory:Map任务将中间结果存储在内存中的缓冲区中,称为Buffer in Memory。这个缓冲区用于临时存储Map任务生成的键-值对,以便后续处理。
-
Partition, Sort, and Spill to Disk阶段:
- Partition:Map任务根据键的哈希值将中间结果分发到不同的分区中。每个分区包含一组具有相同键的键-值对。分区的数量通常与Reduce任务的数量相同。
- Sort:在每个分区内,键-值对根据键进行排序。这是为了便于后续的合并和归并操作。
- Spill to Disk:如果缓冲区中的数据超过一定阈值,Map任务会将部分数据写入磁盘,以释放内存空间。这个过程称为Spill to Disk。数据被分成多个片段,并根据键进行排序和存储。
-
Fetch和Other Maps的Fetch阶段:
- Fetch:Reduce任务通过网络从Map任务所在的节点获取分区数据。Reduce任务向Map任务发送请求,获取它所需的中间结果数据。
- Other Maps的Fetch:Reduce任务还可以从其他Map任务获取数据,以确保所有相关的中间结果都被传输到Reduce任务所在的节点。
-
Merge,Sort Phase到Reduce阶段:
- Merge:Reduce任务对获取的中间结果数据进行合并。它将来自不同Map任务的中间结果按键进行合并,以形成全局排序的数据集。
- Sort Phase:在合并后,Reduce任务对数据进行排序,以便按键分组。
- Reduce函数:Reduce任务对每个分组的数据应用特定的Reduce函数。Reduce函数根据键和相应的值集合执行聚合、计算或其他操作,生成最终的结果。
-
Output阶段:
- Reduce任务将最终的结果写入输出文件或存储系统。每个Reduce任务生成一个或多个输出文件,包含计算结果。
总体而言,MapReduce的执行过程包括Map任务和Reduce任务的并行执行,中间结果的合并和排序,以及最终结果的生成。通过这种方式,MapReduce模型,MapReduce能够高效地处理大规模数据集。
需要注意的是,MapReduce执行过程中的各个步骤是交替进行的。一旦一部分Map任务完成了特定的阶段(如Spill to Disk),相应的Reduce任务就可以开始进行后续的处理(如Fetch和Merge)。这种并行和交替的执行方式使得整个计算过程更加高效和快速。
最终,MapReduce将大规模数据的处理任务分解为多个并行的Map任务和Reduce任务,利用分布式计算的优势来加速数据处理过程。通过合理的切分、排序和聚合操作,MapReduce能够在分布式环境下高效地处理大规模数据集,并生成最终的计算结果。
总结:
MapReduce执行过程中,首先,输入数据被切分为多个input split,并由一组Map任务并行处理。每个Map任务将输入数据映射为一组键-值对,并将中间结果存储在内存中的缓冲区中。当缓冲区达到阈值时,部分数据会被写入磁盘进行临时存储。同时,Map任务将中间结果根据键的哈希值分发到不同的分区,并在每个分区内对键-值对进行排序。然后,Reduce任务通过网络从Map任务所在节点获取分区数据,并可以从其他Map任务获取数据。接下来,Reduce任务对获取的中间结果进行合并和排序,形成全局排序的数据集。最后,Reduce任务根据键和相应的值集合应用Reduce函数,生成最终的计算结果,并将结果写入输出文件或存储系统。通过这种方式,MapReduce利用分布式计算的能力,高效地处理大规模数据集,实现并行计算和结果生成的过程。
【问题4】尝试讨论shuffle为何是MR的灵魂?能否从源码角度介绍shuffle的排序机制?
答:
shuffle认为是MapReduce的灵魂,因为它在整个计算过程中起着关键的作用。Shuffle的主要功能是将Map阶段输出的中间结果按键进行排序和重新分区,以便将具有相同键的记录聚合到一起,并传递给对应的Reduce任务进行处理。通过Shuffle,MapReduce能够将数据从Map任务传递到Reduce任务,并进行合并和归并操作,从而实现最终结果的生成。
从源码角度来看,Shuffle的排序机制可以通过以下步骤进行概括:
-
Map任务的排序:
(1) Map任务在内存中维护一个环形缓冲区,称为环形缓冲区
(2) Map任务将中间结果写入环形缓冲区,每个键-值对都被赋予一个唯一的标识符
(3) 环形缓冲区根据键进行排序,以确保具有相同键的记录相邻存放。 -
环形缓冲区的溢写:
(1) 当环形缓冲区的数据量超过一定阈值时,Map任务会将部分数据溢写到磁盘上的临时文件中。
(2) 溢写过程包括将缓冲区中的数据分段,并根据分区将数据写入对应的临时文件。 -
数据的合并和排序:
(1) Reduce任务启动时,会从Map任务所在的节点上获取对应的分区数据。
(2) Reduce任务会将从不同Map任务获取的分区数据进行合并,并进行排序操作。
(3) 合并和排序过程会利用合并排序算法,将具有相同键的记录聚集到一起。 -
数据的传输和归并:
(1) Reduce任务会根据Reduce函数的输入键范围,将合并后的数据划分成多个分组。
(2) Reduce任务会从不同节点上的Map任务获取对应分组的数据,这个过程称为Fetch。
(3) Fetch过程可以通过网络进行数据的传输和接收,以获取Reduce任务所需的所有数据。
(4) Reduce任务接收到数据后,会进行进一步的归并操作,将具有相同键的记录归并到一起,为Reduce函数的调用做准备。
通过以上步骤,Shuffle机制能够对Map任务的输出进行排序、分区和归并,以便将数据传递给对应的Reduce任务进行最终的计算和结果生成。Shuffle的排序机制在源码中涉及到环形缓冲区的排序、溢写和临时文件的生成,以及Reduce任务对数据的合并、排序和归并过程。这些步骤保证了MapReduce的关键特性,如高效的数据传递、数据聚合和结果生成。
在源码实现中,Shuffle的排序机制涉及到多个组件和算法的协同工作,例如环形缓冲区的数据排序、分区和溢写,合并排序算法的应用以及数据的传输和归并等。这些步骤的设计和实现旨在优化数据的处理和传递效率,以提高整体的计算性能和吞吐量。
需要注意的是,不同版本和实现的MapReduce可能会有一些细微的差异,但基本的思想和机制通常是相似的。Shuffle作为MapReduce的核心组件之一,确保了数据的有序传递和合并,为Reduce阶段的计算提供了必要的输入。它在分布式计算中扮演着重要的角色,并且被广泛应用于许多大数据处理框架和系统中,如Hadoop的MapReduce、Apache Spark等。
【问题5】已知HDFS+MR形成了block+split的双层机制去控制数据处理粒度,请问:照这个策略去切分数据,会不会出现默认128MB切分导致某一行数据被切坏(即分割到两个数据微粒)的情况?Hadoop又是怎么避免or解决这个问题的?能否从源码角度解释?
答:
会,在默认情况下,Hadoop将输入数据切分为128MB大小的数据块,这些数据块称为HDFS块(HDFS blocks),并且MapReduce任务会对这些数据块进行进一步切分为输入分片(input splits)。这样的双层切分机制确实存在一种可能性,即某一行数据被切分到两个不同的数据微粒中,从而导致数据的不完整性。
为了解决这个问题,Hadoop采用了一种称为"RecordReader"的机制。RecordReader负责读取输入分片(input split)并将其切分为逻辑上的记录(records),确保每个记录都完整地位于一个输入分片内。这样,即使某一行数据跨越了多个HDFS块的边界,RecordReader仍然能够将其识别为一条完整的记录。
从源码角度来看,Hadoop中的RecordReader是一个抽象类,不同的输入格式(InputFormat)会提供自己的RecordReader实现。RecordReader负责解析输入数据,并生成逻辑上的记录。它通过实现next()方法来获取下一个记录,确保每个记录的完整性。
在默认的TextInputFormat中,使用LineRecordReader作为RecordReader的实现。LineRecordReader会读取输入分片,并根据行结束符来切分记录。它会处理行跨越多个输入分片的情况,确保每一行数据都完整地属于一个记录。
通过这种机制,Hadoop能够避免或解决默认128MB切分导致数据被切坏的问题。RecordReader确保了数据的完整性,将跨越多个HDFS块边界的数据识别为一条完整的记录,从而保证了数据处理的准确性和一致性。
【问题6】[编程题]
某市连锁书店共有4个门店,每个门店的每一笔图书销售记录都会自动汇总到该市分公司的销售系统后台,销售记录数据如下(约100万数量级):
BTW-08001
2011
年
1
月
2
日
2011年1月2日
2011年1月2日鼎盛书店$BK-83021$12
BTW-08002
2011
年
1
月
4
日
2011年1月4日
2011年1月4日博达书店$BK-83033$5
BTW-08003
2011
年
1
月
4
日
2011年1月4日
2011年1月4日博达书店$BK-83034$41
…
其中记录样例说明如下:
//[流水单号]
[
交易时间
]
[交易时间]
[交易时间][书店名称]
[
图书编号
]
[图书编号]
[图书编号][售出数量]
BTW-08001
2011
年
1
月
2
日
2011年1月2日
2011年1月2日鼎盛书店$BK-83021$12
年底,公司市场部需要统计本年度各门店图书热销Top3,并做成4张报表上报公司经理;请在MR框架下编程实现这个需求,对应数据文件已经附上。
销售记录.txt
链接:销售记录.txt:
提取码:gc23
注意:
如果在Linux中文件内容乱码了:请用工具转换为UTF-8编码
我自己写了一个工具:文件编码转换链接
提取码:fn6t
思路:
-
序列化(SalesRecord类):定义了一个
SalesRecord类,实现了Hadoop的Writable接口,用于实现对象的序列化和反序列化。SalesRecord类包含了销售记录的各个字段,提供了构造函数、Getter和Setter方法以及序列化和反序列化方法。 -
Map阶段(SalesMapper类):继承了Hadoop的
Mapper类,将输入的文本行按照"$"进行分割得到字段数组。然后从字段数组中获取各个字段的值,并解析日期字段获取年份信息。创建输出键值对,其中键由书店名称和年份组成,值为SalesRecord对象。最后将输出键值对写入上下文。 -
分区(SalesPartitioner类):继承了Hadoop的
Partitioner类,根据书店名称将记录分配到不同的分区。根据书店名称的不同,分别返回对应的分区索引。 -
Reduce阶段(SalesReducer类):继承了Hadoop的
Reducer类,用于处理Map阶段输出的键值对。在Reduce阶段,将同一书店名称和年份的销售记录聚合起来,并计算每种书籍类型的销量总和。使用TreeMap对销量总和进行排序,取销量总和最高的前三个书籍类型。最后输出门店每个年份销量前三的书籍类型和对应的销量总和。 -
Main函数(Main类):配置Hadoop作业的相关参数,包括作业名称、主类、Mapper类、Partitioner类、Reducer类、输入输出键值对类型、输入输出格式、输入路径、输出路径和Reduce任务数量。然后提交作业并等待完成。
代码:
1.序列化
SalesRecord.java
package BookTOP.Maven_booktop.BookTOP;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.Writable;
public class SalesRecord implements Writable {
private String transactionId; // 交易ID
private String transactionDate; // 交易日期
private String storeName; // 书店名称
private String bookId; // 图书编号
private int quantity; // 售出数量
public SalesRecord() {
// 无参构造函数,必须提供以便反序列化时使用
}
//这是 SalesRecord 类的有参构造函数,用于创建一个带有给定属性值的 SalesRecord 对象。
public SalesRecord(String transactionId, String transactionDate, String storeName, String bookId, int quantity) {
this.transactionId = transactionId;
this.transactionDate = transactionDate;
this.storeName = storeName;
this.bookId = bookId;
this.quantity = quantity;
}
//序列化方法:将java对象转化为可跨机器传输数据流(二进制串/字节)的一种技术
public void write(DataOutput out) throws IOException {
// 将对象的字段按指定顺序写入输出流
out.writeUTF(transactionId);
out.writeUTF(transactionDate);
out.writeUTF(storeName);
out.writeUTF(bookId);
out.writeInt(quantity);
}
//反序列化方法:将可跨机器传输数据流(二进制串)转化为java对象的一种技术
public void readFields(DataInput in) throws IOException {
// 从输入流中按指定顺序读取字段并设置对象的值
transactionId = in.readUTF();
transactionDate = in.readUTF();
storeName = in.readUTF();
bookId = in.readUTF();
quantity = in.readInt();
}
@Override
//这是 toString() 方法的重写,将 SalesRecord 对象转换为字符串形式,方便输出。
public String toString() {
return transactionId + "\t" + transactionDate + "\t" + storeName + "\t" + bookId + "\t" + quantity;
}
// Getter和Setter方法
public String getTransactionId() {
return transactionId;
}
public void setTransactionId(String transactionId) {
this.transactionId = transactionId;
}
public String getTransactionDate() {
return transactionDate;
}
public void setTransactionDate(String transactionDate) {
this.transactionDate = transactionDate;
}
public String getStoreName() {
return storeName;
}
public void setStoreName(String storeName) {
this.storeName = storeName;
}
public String getBookId() {
return bookId;
}
public void setBookId(String bookId) {
this.bookId = bookId;
}
public int getQuantity() {
return quantity;
}
public void setQuantity(int quantity) {
this.quantity = quantity;
}
public String getBookType() {
// TODO Auto-generated method stub
return bookId;
}
}
2.Map
SalesMapper.java
package BookTOP.Maven_booktop.BookTOP;
import java.io.IOException;
import java.time.LocalDate;
import java.time.format.DateTimeFormatter;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class SalesMapper extends Mapper<LongWritable, Text, Text, SalesRecord> {
// map()方法是Mapper类中的核心方法,用于处理输入键值对并生成输出键值对
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 将输入的文本行按照"$"进行分割得到字段数组
String[] fields = value.toString().split("\\$");
// 判断输入的字段数量是否足够
if (fields.length >= 5) {
// 从字段数组中获取各个字段的值
String transactionId = fields[0];
String transactionDateStr = fields[1];
String storeName = fields[2];
String bookId = fields[3];
int quantity = Integer.parseInt(fields[4]);
// 解析日期字段获取年份信息
LocalDate transactionDate = parseTransactionDate(transactionDateStr);
int year = transactionDate.getYear();
// 创建输出键值对
Text outputKey = new Text(storeName + "-" + year);
SalesRecord outputValue = new SalesRecord();
outputValue.setTransactionId(transactionId);
outputValue.setTransactionDate(transactionDateStr);
outputValue.setStoreName(storeName);
outputValue.setBookId(bookId);
outputValue.setQuantity(quantity);
// 将输出键值对写入上下文
context.write(outputKey, outputValue);
} else {
// 处理字段数量不足的情况,可以输出日志或进行其他适当的处理
System.err.println("Invalid input format: " + value.toString());
}
}
private LocalDate parseTransactionDate(String transactionDateStr) {
// 使用适当的日期解析逻辑解析日期字段
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy年M月d日");
return LocalDate.parse(transactionDateStr, formatter);
}
}
3.分区
SalesPartitioner.java
package BookTOP.Maven_booktop.BookTOP;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class SalesPartitioner extends Partitioner<Text, SalesRecord> {
public int getPartition(Text key, SalesRecord value, int numPartitions) {
// 获取书店名称
String storeName = key.toString().split("-")[0];
// 将记录分配到不同的分区
if (storeName.equals("鼎盛书店")) {
return 0;
} else if (storeName.equals("博达书店")) {
return 1;
} else if (storeName.equals("隆华书店")) {
return 2;
}
// 如果门店名称不匹配任何条件,将记录分配到默认的第4个分区(分区索引为3)
return 3;
}
}
4.Reduce
SalesReducer.java
package BookTOP.Maven_booktop.BookTOP;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
import java.util.TreeMap;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class SalesReducer extends Reducer<Text, SalesRecord, Text, Text> {
// 使用TreeMap来保持销售记录按照销售数量排序
private TreeMap<Integer, String> topSales = new TreeMap<Integer, String>();
public void reduce(Text key, Iterable<SalesRecord> values, Context context) throws IOException, InterruptedException {
// 用于存储每种书籍类型的销量总和
Map<String, Integer> bookTypeSales = new HashMap<String, Integer>();
for (SalesRecord record : values) {
String bookType = record.getBookType();
int quantity = record.getQuantity();
// 累加每种书籍类型的销量总和
if (bookTypeSales.containsKey(bookType)) {
int totalSales = bookTypeSales.get(bookType) + quantity;
bookTypeSales.put(bookType, totalSales);
} else {
bookTypeSales.put(bookType, quantity);
}
}
// 使用TreeMap对销量总和进行排序
TreeMap<Integer, String> sortedSales = new TreeMap<Integer, String>();
for (Map.Entry<String, Integer> entry : bookTypeSales.entrySet()) {
sortedSales.put(entry.getValue(), entry.getKey());
}
// 取销量总和最高的前三个书籍类型
int count = 0;
StringBuilder result = new StringBuilder();
for (Map.Entry<Integer, String> entry : sortedSales.descendingMap().entrySet()) {
String bookType = entry.getValue();
int totalSales = entry.getKey();
result.append(bookType).append(":").append(totalSales).append("\t");
count++;
if (count >= 3) {
break;
}
}
// 输出门店每个年份销量前三的书籍类型和对应的销量总和
context.write(key, new Text(result.toString()));
topSales.clear();
}
}
5.Main
main.java
package BookTOP.Maven_booktop.BookTOP;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class Main {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJobName("BookTOP Sales Analysis");
// 设置作业的主类为当前的Main类
job.setJarByClass(Main.class);
// 设置Mapper类、Partitioner类和Reducer类
job.setMapperClass(SalesMapper.class);
job.setPartitionerClass(SalesPartitioner.class);
job.setReducerClass(SalesReducer.class);
// 设置Reducer的输出键值对类型为Text
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// 设置Mapper的输出键值对类型为Text和SalesRecord
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(SalesRecord.class);
// 设置输入格式为TextInputFormat,输出格式为TextOutputFormat
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
// 设置输入路径和输出路径
TextInputFormat.setInputPaths(job, new Path(args[0]));
TextOutputFormat.setOutputPath(job, new Path(args[1]));
// 设置Reduce任务的数量为4
job.setNumReduceTasks(4);
// 提交作业并等待完成,如果成功则返回0,否则返回1
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
输出结果:

第4章 YARN
一样,等一下传
第5章
这个待续















 881
881











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









