






MapReduce详解及实战
(本篇改写自Hadoop_Liang博主,若有侵权,望告知)
1.什么是MapReduce ?
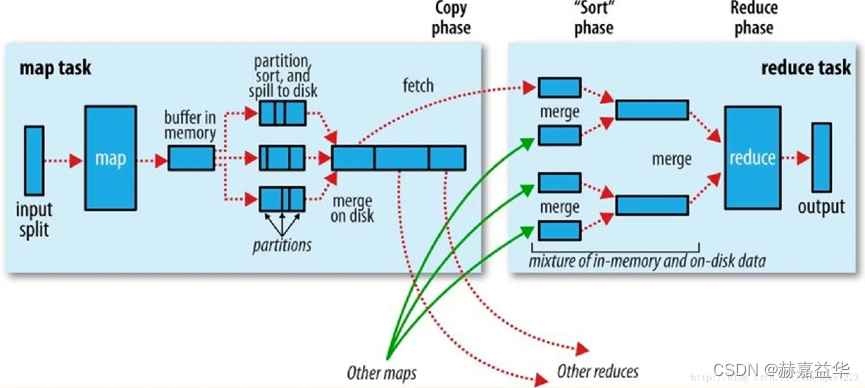
MapReduce工作流程图
答:
MapReduce是一种并行处理大规模数据集的计算模型,它将计算任务分解为两个主要阶段:Map阶段和Reduce阶段。以下是对MapReduce执行过程中各个步骤的描述:
Map Task阶段:
Input Split:输入数据被切分成多个块,称为Input Split。每个Input Split都由一个Map任务处理。这样可以将输入数据并行地分配给不同的Map任务。
Map函数:每个Map任务读取一个Input Split,并将其转换为一系列键-值对。Map函数对每个输入数据项应用特定的映射逻辑,将其转换为一组中间结果。
Buffer in Memory:Map任务将中间结果存储在内存中的缓冲区中,称为Buffer in Memory。这个缓冲区用于临时存储Map任务生成的键-值对,以便后续处理。
Partition, Sort, and Spill to Disk阶段:
Partition:Map任务根据键的哈希值将中间结果分发到不同的分区中。每个分区包含一组具有相同键的键-值对。分区的数量通常与Reduce任务的数量相同。
Sort:在每个分区内,键-值对根据键进行排序。这是为了便于后续的合并和归并操作。
Spill to Disk:如果缓冲区中的数据超过一定阈值,Map任务会将部分数据写入磁盘,以释放内存空间。这个过程称为Spill to Disk。数据被分成多个片段,并根据键进行排序和存储。
Fetch和Other Maps的Fetch阶段:
Fetch:Reduce任务通过网络从Map任务所在的节点获取分区数据。Reduce任务向Map任务发送请求,获取它所需的中间结果数据。
Other Maps的Fetch:Reduce任务还可以从其他Map任务获取数据,以确保所有相关的中间结果都被传输到Reduce任务所在的节点。
Merge,Sort Phase到Reduce阶段:
Merge:Reduce任务对获取的中间结果数据进行合并。它将来自不同Map任务的中间结果按键进行合并,以形成全局排序的数据集。
Sort Phase:在合并后,Reduce任务对数据进行排序,以便按键分组。
Reduce函数:Reduce任务对每个分组的数据应用特定的Reduce函数。Reduce函数根据键和相应的值集合执行聚合、计算或其他操作,生成最终的结果。
Output阶段:
Reduce任务将最终的结果写入输出文件或存储系统。每个Reduce任务生成一个或多个输出文件,包含计算结果。
总体而言,MapReduce的执行过程包括Map任务和Reduce任务的并行执行,中间结果的合并和排序,以及最终结果的生成。通过这种方式,MapReduce模型,MapReduce能够高效地处理大规模数据集。
需要注意的是,MapReduce执行过程中的各个步骤是交替进行的。一旦一部分Map任务完成了特定的阶段(如Spill to Disk),相应的Reduce任务就可以开始进行后续的处理(如Fetch和Merge)。这种并行和交替的执行方式使得整个计算过程更加高效和快速。
最终,MapReduce将大规模数据的处理任务分解为多个并行的Map任务和Reduce任务,利用分布式计算的优势来加速数据处理过程。通过合理的切分、排序和聚合操作,MapReduce能够在分布式环境下高效地处理大规模数据集,并生成最终的计算结果。
2.初步认识MapReduce编程:
先去参考此博客,写的非常好:如何编写MapReduce程序?有套路吗?
代码解读:
Mapper类:
WordCountMapper.java
package com.MRWordCount; //声明类所在的包名
import java.io.IOException;
import org.apache.hadoop.io.IntWritable; //导入Hadoop中的IntWritable类,用于表示整数类型的可序列化数据
import org.apache.hadoop.io.LongWritable; //导入Hadoop中的LongWritable类,用于表示长整型类型的可序列化数据
import org.apache.hadoop.io.Text; //导入Hadoop中的Text类,用于表示文本类型的可序列化数据
import org.apache.hadoop.mapreduce.Mapper; //导入Hadoop MapReduce中的Mapper类
//继承Mapper类,声明类名,指定键值对的类型,LongWritable, Text为输入键值对类型,Text, IntWritable为输出键值对类型。
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override //表示这个方法是重写了其父类中的一个方法。
//提供了map函数的实现,map函数用于将输入的数据进行拆分,生成新的键值对。
protected void map(LongWritable k1, Text v1, Context context)
throws IOException, InterruptedException {
//将v1有Text转换为Java的String类型,方便处理
String data = v1.toString(); //将value v1从Text类型转成Java String类型。
//分词:v1为“hello world”,按空格来划分为多个单词,存入数组,即: hello 和 world
String[] words = data.split(" ");
//输出k2 , v2
//遍历单词列表
for (String word : words) {
//将单词作为键,计数器1为值,输出键值对,用于下一个步骤的处理。
context.write(new Text(word), new IntWritable(1));
}
}
}
Reducer类:
WordCountReducer.java
package com.MRWordCount; //声明类所在的包名
import java.io.IOException; //导入IOException类
import org.apache.hadoop.io.IntWritable; //导入Hadoop中的IntWritable类,用于表示整数类型的可序列化数据
import org.apache.hadoop.io.Text; //导入Hadoop中的Text类,用于表示文本类型的可序列化数据
import org.apache.hadoop.mapreduce.Reducer; //导入Hadoop MapReduce中的Reducer类
//继承Reduce类,指定键值对的类型,Text, IntWritable为输出键值对类型。
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override //表示这个方法是重写了其父类中的一个方法。
//提供reduce函数的实现,reduce函数在调用之前,map任务已经完成了将数据分组的工作,它的任务是将相同的键合并起来,并对相同键对应的值进行累加。
protected void reduce(Text k3, Iterable<IntWritable> v3,
Context context) throws IOException, InterruptedException {
//由于k3和k4是一样的数据类型,因此可以直接用赋值符来基于k3创建一个k4,准备进行输出。
Text k4 = k3;
//定义一个变量total,用于存放单词出现的总次数。
int total=0;
//对传入的迭代器中的值(即划分到当前键值的所有值),进行遍历。
for (IntWritable v : v3) {
//将所有值相加,最终用total存储所有值的和。v.get()方法是将IntWritable类型的数据转换为Int类型。
total = total + v.get();
}
//输出 k4, v4
context.write(k4, new IntWritable(total));
}
}
Main类:
WordCountMain.java
package com.MRWordCount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCountMain {
public static void main(String[] args) throws Exception {
// 1. 创建一个job和任务入口(指定主类)
Job job = Job.getInstance(new Configuration());
job.setJarByClass(WordCountMain.class);
// 2. 指定job的mapper和输出的类型<k2 v2>
job.setMapperClass(WordCountMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 3. 指定job的reducer和输出的类型<k4 v4>
job.setReducerClass(WordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 4. 指定job的输入和输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 5. 执行job
job.waitForCompletion(true);
}
}
总结一下:编写MapReduce程序的方法(套路)是:
- 编程模型分析(最重要):明确输入输出数据及其类型。
- 明确编程思路(只要把一两个程序的思路研究透了,其他程序也就自然会写)
- 编写代码,一般包括三个类,分别是:
Mapper类,继承Mapper()方法,并重写其mapper()方法;
Reducer类,继承Reducer方法,并重写其reducer()方法;
Main类,实现程序入口main()方法,主要功能是把定义一个Job作业,把Mapper类和Reducer类整合起来。
3.MapReduce优化:
参考此博客:Maven工程的MapReduce程序3—实现统计各部门员工薪水总和功能(优化)
4.MapReduce实战:
【问题】[编程题]
某市连锁书店共有4个门店,每个门店的每一笔图书销售记录都会自动汇总到该市分公司的销售系统后台,销售记录数据如下(约100万数量级):
BTW-08001
2011
年
1
月
2
日
2011年1月2日
2011年1月2日鼎盛书店$BK-83021$12
BTW-08002
2011
年
1
月
4
日
2011年1月4日
2011年1月4日博达书店$BK-83033$5
BTW-08003
2011
年
1
月
4
日
2011年1月4日
2011年1月4日博达书店$BK-83034
41......
其中记录样例说明如下:
/
/
[
流水单号
]
41 ...... 其中记录样例说明如下: //[流水单号]
41......其中记录样例说明如下://[流水单号][交易时间]
[
书店名称
]
[书店名称]
[书店名称][图书编号]$[售出数量]
BTW-08001
2011
年
1
月
2
日
2011年1月2日
2011年1月2日鼎盛书店$BK-83021$12
年底,公司市场部需要统计本年度各门店图书热销Top3,并做成4张报表上报公司经理;请在MR框架下编程实现这个需求,对应数据文件已经附上。
销售记录.txt
链接:https://pan.baidu.com/s/1xhumXjTu0EMbJeMmkbpBLA?pwd=gc23
提取码:gc23
注意:
如果在Linux中文件内容乱码了:请用工具转换为UTF-8编码
我自己写了一个工具:文件编码转换链接
提取码:fn6t
思路:
-
序列化(SalesRecord类):定义了一个
SalesRecord类,实现了Hadoop的Writable接口,用于实现对象的序列化和反序列化。SalesRecord类包含了销售记录的各个字段,提供了构造函数、Getter和Setter方法以及序列化和反序列化方法。 -
Map阶段(SalesMapper类):继承了Hadoop的
Mapper类,将输入的文本行按照"$"进行分割得到字段数组。然后从字段数组中获取各个字段的值,并解析日期字段获取年份信息。创建输出键值对,其中键由书店名称和年份组成,值为SalesRecord对象。最后将输出键值对写入上下文。 -
分区(SalesPartitioner类):继承了Hadoop的
Partitioner类,根据书店名称将记录分配到不同的分区。根据书店名称的不同,分别返回对应的分区索引。 -
Reduce阶段(SalesReducer类):继承了Hadoop的
Reducer类,用于处理Map阶段输出的键值对。在Reduce阶段,将同一书店名称和年份的销售记录聚合起来,并计算每种书籍类型的销量总和。使用TreeMap对销量总和进行排序,取销量总和最高的前三个书籍类型。最后输出门店每个年份销量前三的书籍类型和对应的销量总和。 -
Main函数(Main类):配置Hadoop作业的相关参数,包括作业名称、主类、Mapper类、Partitioner类、Reducer类、输入输出键值对类型、输入输出格式、输入路径、输出路径和Reduce任务数量。然后提交作业并等待完成。
代码:
1.序列化
SalesRecord.java
package BookTOP.Maven_booktop.BookTOP;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.Writable;
public class SalesRecord implements Writable {
private String transactionId; // 交易ID
private String transactionDate; // 交易日期
private String storeName; // 书店名称
private String bookId; // 图书编号
private int quantity; // 售出数量
public SalesRecord() {
// 无参构造函数,必须提供以便反序列化时使用
}
//这是 SalesRecord 类的有参构造函数,用于创建一个带有给定属性值的 SalesRecord 对象。
public SalesRecord(String transactionId, String transactionDate, String storeName, String bookId, int quantity) {
this.transactionId = transactionId;
this.transactionDate = transactionDate;
this.storeName = storeName;
this.bookId = bookId;
this.quantity = quantity;
}
//序列化方法:将java对象转化为可跨机器传输数据流(二进制串/字节)的一种技术
public void write(DataOutput out) throws IOException {
// 将对象的字段按指定顺序写入输出流
out.writeUTF(transactionId);
out.writeUTF(transactionDate);
out.writeUTF(storeName);
out.writeUTF(bookId);
out.writeInt(quantity);
}
//反序列化方法:将可跨机器传输数据流(二进制串)转化为java对象的一种技术
public void readFields(DataInput in) throws IOException {
// 从输入流中按指定顺序读取字段并设置对象的值
transactionId = in.readUTF();
transactionDate = in.readUTF();
storeName = in.readUTF();
bookId = in.readUTF();
quantity = in.readInt();
}
@Override
//这是 toString() 方法的重写,将 SalesRecord 对象转换为字符串形式,方便输出。
public String toString() {
return transactionId + "\t" + transactionDate + "\t" + storeName + "\t" + bookId + "\t" + quantity;
}
// Getter和Setter方法
public String getTransactionId() {
return transactionId;
}
public void setTransactionId(String transactionId) {
this.transactionId = transactionId;
}
public String getTransactionDate() {
return transactionDate;
}
public void setTransactionDate(String transactionDate) {
this.transactionDate = transactionDate;
}
public String getStoreName() {
return storeName;
}
public void setStoreName(String storeName) {
this.storeName = storeName;
}
public String getBookId() {
return bookId;
}
public void setBookId(String bookId) {
this.bookId = bookId;
}
public int getQuantity() {
return quantity;
}
public void setQuantity(int quantity) {
this.quantity = quantity;
}
public String getBookType() {
// TODO Auto-generated method stub
return bookId;
}
}
2.Map
SalesMapper.java
package BookTOP.Maven_booktop.BookTOP;
import java.io.IOException;
import java.time.LocalDate;
import java.time.format.DateTimeFormatter;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class SalesMapper extends Mapper<LongWritable, Text, Text, SalesRecord> {
// map()方法是Mapper类中的核心方法,用于处理输入键值对并生成输出键值对
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 将输入的文本行按照"$"进行分割得到字段数组
String[] fields = value.toString().split("\\$");
// 判断输入的字段数量是否足够
if (fields.length >= 5) {
// 从字段数组中获取各个字段的值
String transactionId = fields[0];
String transactionDateStr = fields[1];
String storeName = fields[2];
String bookId = fields[3];
int quantity = Integer.parseInt(fields[4]);
// 解析日期字段获取年份信息
LocalDate transactionDate = parseTransactionDate(transactionDateStr);
int year = transactionDate.getYear();
// 创建输出键值对
Text outputKey = new Text(storeName + "-" + year);
SalesRecord outputValue = new SalesRecord();
outputValue.setTransactionId(transactionId);
outputValue.setTransactionDate(transactionDateStr);
outputValue.setStoreName(storeName);
outputValue.setBookId(bookId);
outputValue.setQuantity(quantity);
// 将输出键值对写入上下文
context.write(outputKey, outputValue);
} else {
// 处理字段数量不足的情况,可以输出日志或进行其他适当的处理
System.err.println("Invalid input format: " + value.toString());
}
}
private LocalDate parseTransactionDate(String transactionDateStr) {
// 使用适当的日期解析逻辑解析日期字段
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy年M月d日");
return LocalDate.parse(transactionDateStr, formatter);
}
}
3.分区
SalesPartitioner.java
package BookTOP.Maven_booktop.BookTOP;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class SalesPartitioner extends Partitioner<Text, SalesRecord> {
public int getPartition(Text key, SalesRecord value, int numPartitions) {
// 获取书店名称
String storeName = key.toString().split("-")[0];
// 将记录分配到不同的分区
if (storeName.equals("鼎盛书店")) {
return 0;
} else if (storeName.equals("博达书店")) {
return 1;
} else if (storeName.equals("隆华书店")) {
return 2;
}
// 如果门店名称不匹配任何条件,将记录分配到默认的第4个分区(分区索引为3)
return 3;
}
}
4.Reduce
SalesReducer.java
package BookTOP.Maven_booktop.BookTOP;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
import java.util.TreeMap;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class SalesReducer extends Reducer<Text, SalesRecord, Text, Text> {
// 使用TreeMap来保持销售记录按照销售数量排序
private TreeMap<Integer, String> topSales = new TreeMap<Integer, String>();
public void reduce(Text key, Iterable<SalesRecord> values, Context context) throws IOException, InterruptedException {
// 用于存储每种书籍类型的销量总和
Map<String, Integer> bookTypeSales = new HashMap<String, Integer>();
for (SalesRecord record : values) {
String bookType = record.getBookType();
int quantity = record.getQuantity();
// 累加每种书籍类型的销量总和
if (bookTypeSales.containsKey(bookType)) {
int totalSales = bookTypeSales.get(bookType) + quantity;
bookTypeSales.put(bookType, totalSales);
} else {
bookTypeSales.put(bookType, quantity);
}
}
// 使用TreeMap对销量总和进行排序
TreeMap<Integer, String> sortedSales = new TreeMap<Integer, String>();
for (Map.Entry<String, Integer> entry : bookTypeSales.entrySet()) {
sortedSales.put(entry.getValue(), entry.getKey());
}
// 取销量总和最高的前三个书籍类型
int count = 0;
StringBuilder result = new StringBuilder();
for (Map.Entry<Integer, String> entry : sortedSales.descendingMap().entrySet()) {
String bookType = entry.getValue();
int totalSales = entry.getKey();
result.append(bookType).append(":").append(totalSales).append("\t");
count++;
if (count >= 3) {
break;
}
}
// 输出门店每个年份销量前三的书籍类型和对应的销量总和
context.write(key, new Text(result.toString()));
topSales.clear();
}
}
5.Main
main.java
package BookTOP.Maven_booktop.BookTOP;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class Main {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJobName("BookTOP Sales Analysis");
// 设置作业的主类为当前的Main类
job.setJarByClass(Main.class);
// 设置Mapper类、Partitioner类和Reducer类
job.setMapperClass(SalesMapper.class);
job.setPartitionerClass(SalesPartitioner.class);
job.setReducerClass(SalesReducer.class);
// 设置Reducer的输出键值对类型为Text
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// 设置Mapper的输出键值对类型为Text和SalesRecord
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(SalesRecord.class);
// 设置输入格式为TextInputFormat,输出格式为TextOutputFormat
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
// 设置输入路径和输出路径
TextInputFormat.setInputPaths(job, new Path(args[0]));
TextOutputFormat.setOutputPath(job, new Path(args[1]));
// 设置Reduce任务的数量为4
job.setNumReduceTasks(4);
// 提交作业并等待完成,如果成功则返回0,否则返回1
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
输出结果:
















 965
965











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









