







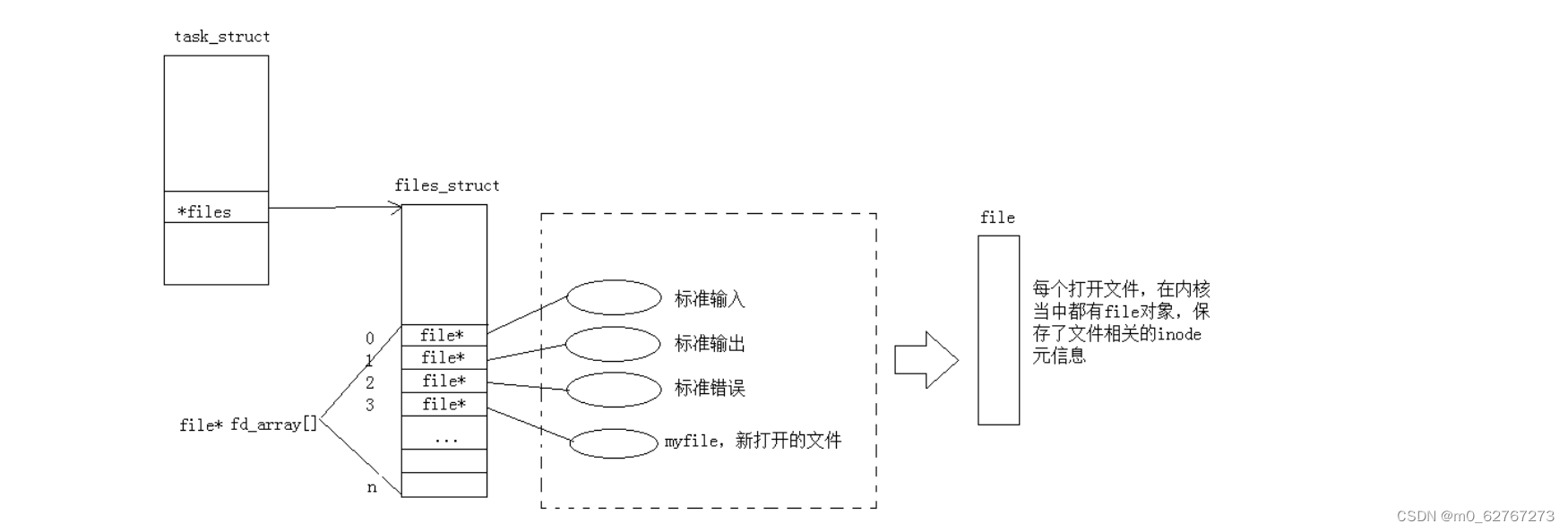
文件描述符
而现在知道,文件描述符就是从0开始的小整数。当我们打开文件时,操作系统在内存中要创建相应的数据结构来
描述目标文件。于是就有了file结构体。表示一个已经打开的文件对象。而进程执行open系统调用,所以必须让进
程和文件关联起来。每个进程都有一个指针*files, 指向一张表files_struct,该表最重要的部分就是包涵一个指针数组,每个元素都是一个指向打开文件的指针所以,本质上,文件描述符就是该数组的下标。所以,只要拿着文件描述符,就可以找到对应的文件
图解
文件描述符的分配规则
文件描述符的分配规则:在files_struct数组当中,找到当前没有被使用的最小的一个下标,作为新的文件描述符。
当我们在open一个文件之前,close(1),我们会发现这个文件的fd为1,如果我们关闭的是0,那么新打开文件的文件描述符就是0
重定向
输出重定向
看代码:
2 #include <string.h>
3 #include <unistd.h>
4 #include <sys/types.h>
5 #include <sys/stat.h>
6 #include <fcntl.h>
7
8 int main()
9 {
10 close(1);
12
13 int fd=open("log.txt",O_WRONLY|O_CREAT|O_TRUNC,0666);
14 if(fd<0)
15 {
16 perror("open");
17 return 1;
18 }
19
20 printf("fd:%d\n",fd);
21 printf("fd:%d\n",fd);
22 printf("fd:%d\n",fd);
23 printf("fd:%d\n",fd);
24 printf("fd:%d\n",fd);
25 printf("fd:%d\n",fd);
26 printf("fd:%d\n",fd);
27
28 fprintf(stdout,"hello fprintf\n");
29 const char* s="hello fwrite\n";
30 fwrite(s,strlen(s),1,stdout);
31 fflush(stdout);
32 close(fd);
33 return 0;
34 }
我们会发现,原本应该输出到显示器上的内容,全都输出到了log.txt文件中,这种现象叫做输出重定向。常见的重定向有:>, >>, < 。
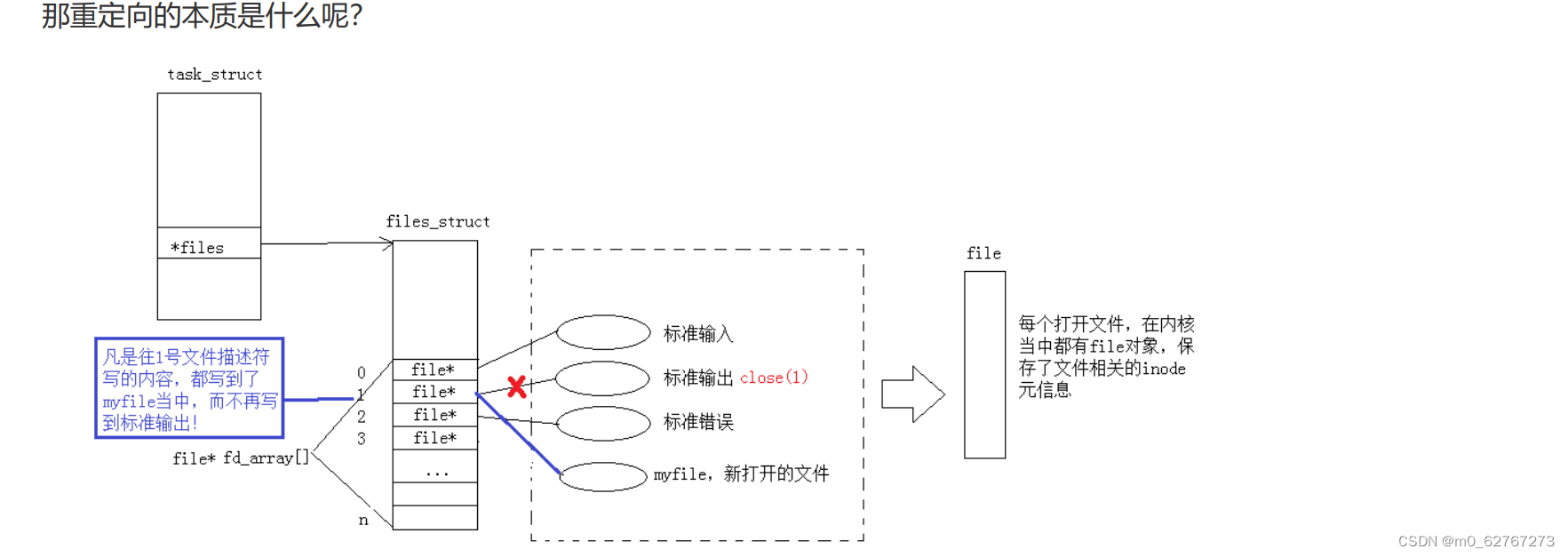
为什么会发生这种情况呢?
首先我们知道,给进程会默认打开三个文件,其中默认输出stdout对应的文件描述符就是1,对应的文件是显示器文件,而我们在创建文件log.txt之前close了1,这就会导致对应文件描述符表中下标1对应的指针置空,所以close就相当于关闭进程与显示器文件之间的联系,根据文件描述符的分配规则,当我们新建一个文件时,自然就会把文件描述符1分配给log.txt,这时我们再调用C库函数,printf或者fprintf(stdout,···)的时候,因为stdout里面对应的_fileno为1,所以在底层调用系统接口函数的时候就把1传进函数,自然原本对显示器的操作就变成了对文件log.txt的操作,这就是重定向。
重定向的本质,其实就是在OS的内部,更改fd对应的内容的指向
输入重定向
1 #include <stdio.h>
2 #include <string.h>
3 #include <unistd.h>
4 #include <sys/types.h>
5 #include <sys/stat.h>
6 #include <fcntl.h>
7
8
9 int main()
10 {
11 close(0);
12 int fd=open("log.txt",O_RDONLY);
13 if(fd<0)
14 {
15 perror("open");
16 return 1;
17 }
18 printf("%d\n",fd);
19 char buffer[64];
20 fgets(buffer,sizeof(buffer),stdin);
21 printf("%s\n",buffer);
22
23 return 0;
24 }
追加重定向
把输出重定向中的O_TRUNC改为O_APPEND即可
dup2函数
#include <unistd.h>
int dup2(int oldfd, int newfd);
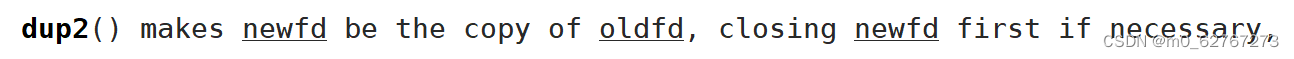
dup2函数的作用就是把文件描述符表中的oldfd位置的指针,拷贝到newfd中。
所以当我们进行重定向的时候,就不必先close掉0,1再打开文件,我们可以先打开一个文件,获取到文件描述符,然后把这个文件描述符作为oldfd,0或1作为newfd,这样就可以完成重定向的过程
8 int main(int argc,char* argv[])
9 {
10 if(argc!=2)
11 {
12 return 2;
13 }
14 int fd=open("log.txt",O_WRONLY|O_CREAT|O_TRUNC,0666);
15 if(fd<0)
16 {
17 perror("open");
18 return 1;
19 }
20
21 dup2(fd,1);
22 fprintf(stdout,"%s\n",argv[1]);
23
24 return 0;
25 }

理性认识——Linux下一切皆文件
这里的文件,其实就是一种对象,一切皆文件,其实也是一种面向对象的思想
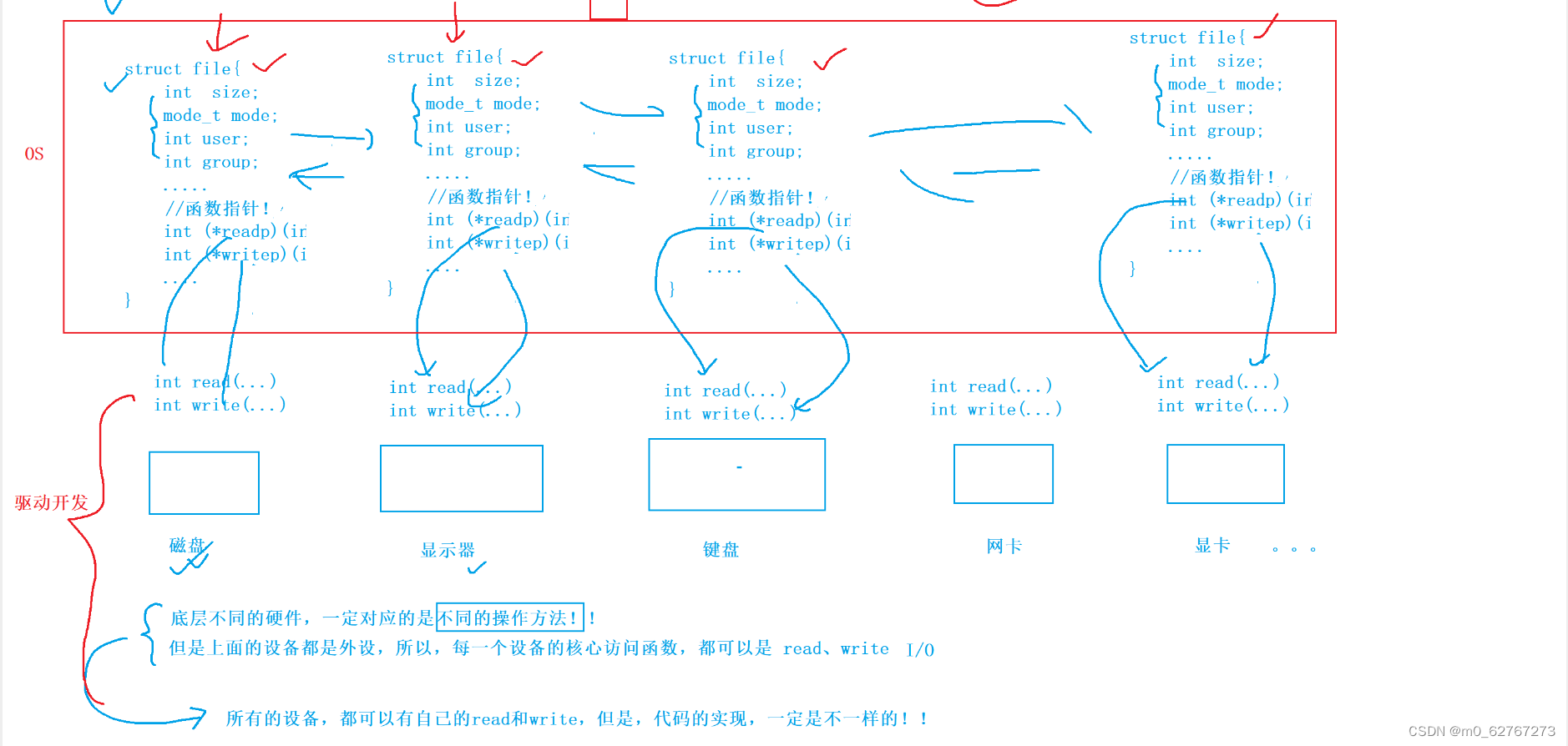
那我们知道,Linux是由C语言写的,那么C语言是如何实现面向对象的呢?,面向对象的实现,就是依靠类,
类里面既有成员属性,也包括成员方法,但是C语言的struct结构体中不能包含方法,那我们怎么办?
虽然不能有成员方法,但我们可以用一个指针指向外面写好的方法,这就是函数指针,综上在C语言中,我们可以在struct结构体中利用函数指针,实现面向对象。
struct file就是这样,我们抽象的描述一下:

既然说一切皆文件,文件就是读写呗,所以对于不同的外设,比如硬盘,显卡,显示器,键盘,网卡等,每一个设备的核心访问函数,都可以是read、write,同时对于底层不同的硬件,一定对应的是不同的操作方法。
所以对于所有的设备,都会有自己的read和write,但是代码的实现,一定是不一样的
利用函数指针,当我们在操作系统中打开不同的文件的时候,我们可以把对应struct file结构体中的函数指针指向对应文件的读写函数,这样在上层看来,就不存在任何硬件的差别了,所有看待文件的方式,都统一成为了struct file,这就是Linux下一切皆文件。(VFS)
缓冲区
- 什么是缓冲区?
就是一段内存空间 - 为什么要有缓冲区?
提高整机效率,主要是为了提高用户的响应速度。
缓冲区的刷新策略
- 立即刷新
- 行刷新(行缓冲 \n)
- 满刷新(全缓冲)
特殊情况: - 用户强强制刷新(fflush)
- 进程退出
缓冲区在哪里
我们先看一段代码
1 #include <stdio.h>
2 #include <string.h>
3 #include <unistd.h>
4 #include <sys/types.h>
5 #include <sys/stat.h>
6 #include <fcntl.h>
7
8 int main()
9 {
10 printf("hello printf\n");
11 fprintf(stdout,"hello fprintf\n");
12 const char* s="hello fputs\n";
13 fputs(s,stdout);
14
15 const char* ss="hello write\n";
16 write(1,ss,strlen(ss));
17
18 //fork();
19
20 return 0;
21 }
当没有后面fork的时候,运行程序不管是输出到屏幕上,还是重定向到文件中,输出内容都是那四行,但是当我在后面添加fork的时候
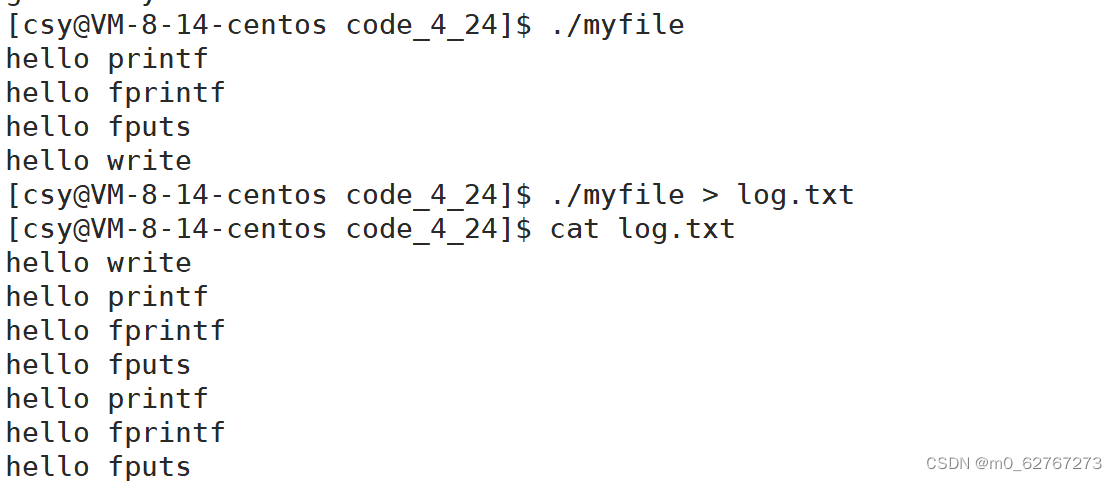
结果变成了这样,而且在文件中的结果hello write在最前面,只被打印了一次,其他的都被打印了两次,这是怎么回事呢?
关于缓冲区的认识
所有的设备,永远都倾向于全缓冲,因为缓冲区满了才刷新,这需要更少次数的IO操作,也就意味着更少次的外设访问,这会提高效率
因为和外部设备IO的时候,数据量的大小不是主要矛盾,和外设预备IO的过程是最耗费时间的!
一般而言,行缓冲的设备文件为显示器,全缓冲的文件设备为磁盘文件
这时我们分析一下,上面的问题。
从输出结果来看,系统接口并不会受到影响,如果有所谓的缓冲区,那这个缓冲区是由谁维护的呢?C标准库还是OS?
我们所说的缓冲区,绝对不是OS提供的,如果是OS提供的,那么我们上面的代码,表现应该是一样的,而不是说系统接口函数打印了一次,而C IO函数打印了两次
- 如果是向显示器打印的时候,刷新策略就是行刷新,那么我们这几个CIO函数,遇到\n就直接把缓冲区刷新了,当执行到fork的时候,数据已经被刷新完了,所以fork没有任何意义
- 如果我们是重定向,要向磁盘文件打印,那么刷新策略就变成了满刷新,就算遇到了\n数据也不会从缓冲区被刷新出去,当fork的时候,这几个函数虽然执行完毕,但是缓冲区的数据并没有被刷新出去,子进程和父进程此时是共享这部分缓冲区数据的,当子进程或父进程结束的时候,此时就要刷新缓冲区,这其实也是一种写操作此时就会发生写时拷贝,父子进程各有一份缓冲区数据,父子进程结束,就会把这两份数据都刷新出去,此时我们就会看到,Cio操作的内容被打印了两次,write没有所谓的缓冲区,所以就没有变化。
综上: printf fwrite 库函数会自带缓冲区,而 write 系统调用没有带缓冲区。另外,我们这里所说的缓冲区,都是用户级缓冲区。其实为了提升整机性能,OS也会提供相关内核级缓冲区,不过不再我们讨论范围之内。那这个缓冲区谁提供呢? printf fwrite 是库函数, write 是系统调用,库函数在系统调用的“上层”, 是对系统调用的“封装”,但是 write 没有缓冲区,而 printf fwrite 有,足以说明,该缓冲区是二次加上的,又因为是C,所以由C标准库提供。
当每个文件fopen的时候,返回了一个FILE*,FILE是一个结构体,里面不仅封装了fd,还有该文件fd对应的语言层的缓冲区结构。
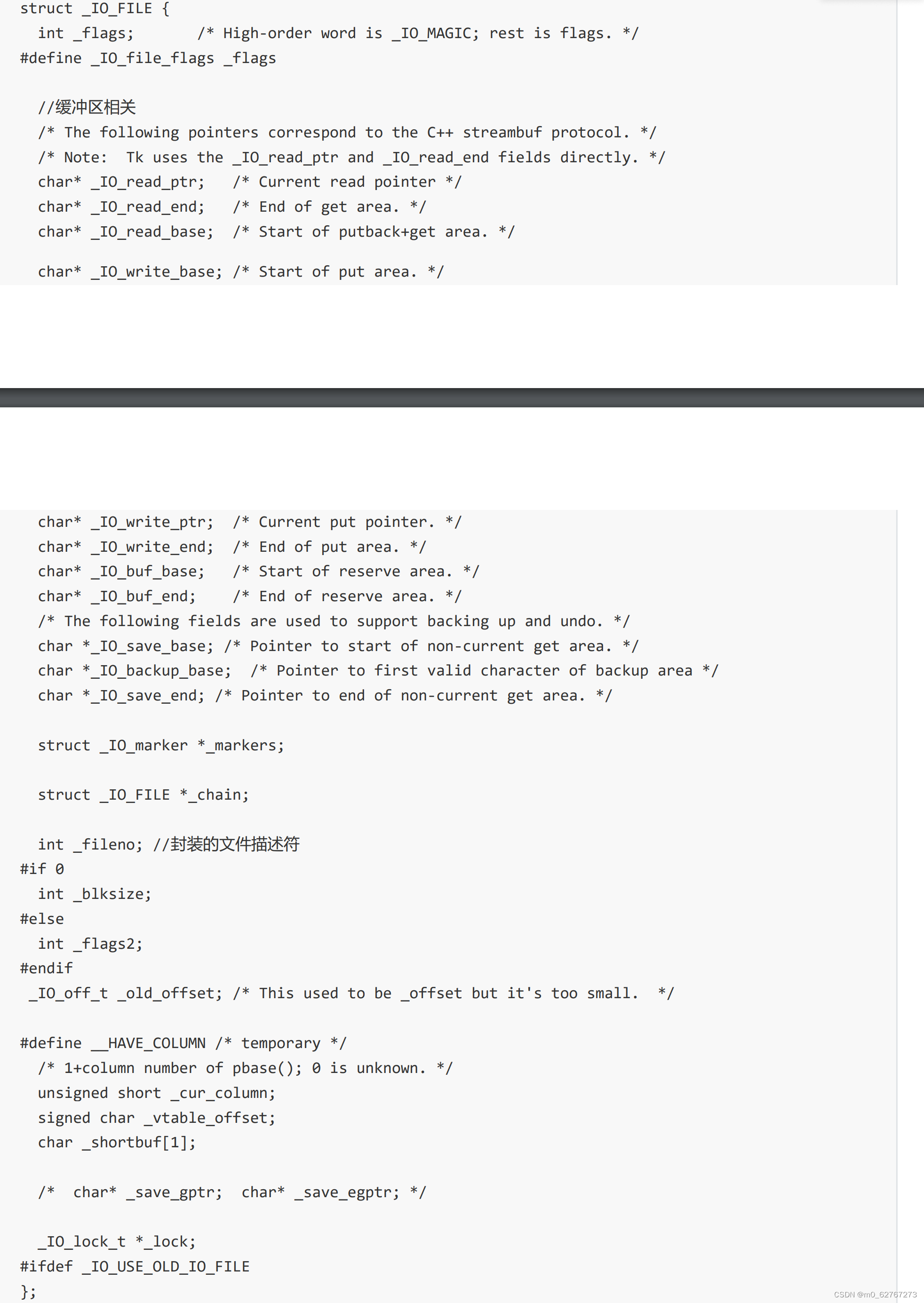
其实write就是直接写入了操作系统,而C写操作函数,就相当于先拷贝到对应的缓冲区空间中,按其对应的刷新策略再write到操作系统中,不要认为write就是直接写到对应的硬件上面了。
当我们以写的方式打开文件的时候,C语言会自动为其分配缓冲区并且指定缓冲区的类型,缓冲区的类型涉及到刷新策略,对于上面的代码,其实我有个疑问,重定向的时候不是仅仅改变了文件描述符的指向吗,但是对于C库函数来说它应该察觉不到这个变化啊,并且此时stdout对应FILE结构体中的缓冲区也没变化,类型也没变化,那么刷新策略怎么就变化了,可能是因为刷新策略也不仅仅是由缓冲区类型决定的,肯定跟文件描述符指定的具体的文件类型也有关系,就算你的缓冲区类型为行刷新,但是我是一个磁盘文件,默认刷新方式为满刷新,那么最后的刷新类型也为满刷新。但底层是如何实现的,仍未可知。















 1251
1251











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









