







先解决之前的遗留问题
前面说到,C标准库不是会默认打开三个文件流吗,其中stdout和stderr对应的硬件都是显示器,那么这俩有啥区别呢?
1,2 stdout & stderr
1,2对应的都是显示器文件,但是他们两个是不同的,如同认为,同一个显示器文件,被打开了两次。
一般而言,如果程序运行可能有问题的话,建议使用stderr,或者cerr来打印,如果是常规的文本内容,我们建议进行cout,stdout打印
代码示例:
13 printf("hello printf 1\n");
14 fprintf(stdout,"hello fprintf 1\n");
15
16 // stderr -> 2
17 perror("hello perror");
18
19 const char* s1="hello write 1\n";
20 write(1,s1,strlen(s1));
21
22 const char* s2="hello write 2\n";
23 write(2,s2,strlen(s2));
24
25 std::cout<<"hello cout 1"<<std::endl;
26
27 std::cerr<<"hello cerr 2"<<std::endl;
其中perror默认是向文件描述符2写入,也就是stderr,cerr也是向stderr写入。
运行程序结果如下:

但是当我们使用重定向将输出结果保存到另一个文件时,我们会发现只有输出到标准输出的内容会被重定向到文件中,而输出到标准错误的内容不会被重定向。

我们可以使用命令:./myfile > log.txt 2> err.txt将输出到stdout的内容重定向到log.txt 并且将输出到stderr的内容重定向到err.txt
那我们就想把所有内容输出到一个文件中怎么办呢,使用这样的命令即可:./myfile > log.txt 2>&1
perror函数
perror函数可以根据不同的errno值输出不同的错误信息,errno被包含在头文件errno.h中,当我们调用某些函数出现错误时,errno值会自动被设置,然后我们就可以用perror打印出不同的错误信息。
模拟实现自己的perror
10 void myperror(const char* msg)
11 {
12 fprintf(stderr,"%s: %s\n",msg,strerror(errno));
13 }
文件系统
背景知识:
- 有没有没有被打开的文件呢? 当然存在,在磁盘里面——叫做磁盘文件
- 我们学习磁盘级别的文件,我们的侧重点在哪里呢?
单个文件角度:这个文件在哪里?这个文件多大?这个文件的其他属性是什么?
站在系统角度:一共有多少文件?各自属性在哪里?如何快速找到?我还可以存储多少个文件?如何快速的找到指定的文件?
综上就是如何进行对磁盘文件进行分门别类的存储,用来支持更好的存取。
3. 磁盘文件——了解磁盘
内存 —— 掉电易失存储介质
磁盘 —— 永久性存储介质 - SSD , U盘 , flash卡 , 光盘,磁带
磁盘是一个外设,还是我们计算机中唯一的一个机械设备。
4. 磁盘结构
磁盘盘片,磁头,伺服系统,音圈马达。。。

磁盘盘面上会存储数据,但是计算机又只认识二进制,那么磁盘时通过什么来表示0,1状态的呢?通过南极北极,你可以认为磁盘就是很多细小的磁极颗粒压缩起来的,那么上面就分布着许多的0,1序列,所以向磁盘上写入,本质就是改变磁盘上的正负极。
磁盘的存储结构:
磁盘上有着许多同心圆,一个同心圆我们称之为一个磁道或者柱面,而一条条半径又把一条磁道分为多个扇区,扇区就是磁盘的基本存储单位,有的是512字节

那么我们怎么把数据写入到指定的扇区里面呢?也就是如何找到一个扇区?
CHS寻址:
- 找到在哪一个面上(对应的就是哪一个磁头)
- 在哪一个磁道(柱面)上
- 在哪一个扇区上
如果我们有了csh,那么所有的扇区我们就都能找到了。
磁盘的抽象结构
大家小时侯应该都玩过磁带吧,我们知道磁带原本是卷在一个圆环上的,其实看起来跟磁盘的盘面差不多,但是当我们把磁带拉出来,它就能伸展成一条直线
那么同理,我们是不是可以将磁盘也看成是一个线性结构呢?
当然可以,本来是一个环状结构,我们想想一个,如果我们拉着磁道,把它展开,一个扇区看成是一块空间,这是不是就成为了和数组类似的线性结构,我们访问一个扇区,就只需要数组的下标。
这样一来,我们对磁盘的管理就变成了对该数组的管理,找到扇区磁盘的特定位置就变成了找到数组的特定位置,将数据存储到磁盘就变成了将数据存储到数组。
但假如这个磁盘有500GB呢,那么大一个数组,我们怎么进行管理呢?
利用分治的思想,我们把数组分成不同的区,把每个区又分成一个个的小分区,那么对磁盘的管理就变成了对一个分区的管理,对一个分区的管理就变成了对一个小分区的管理!

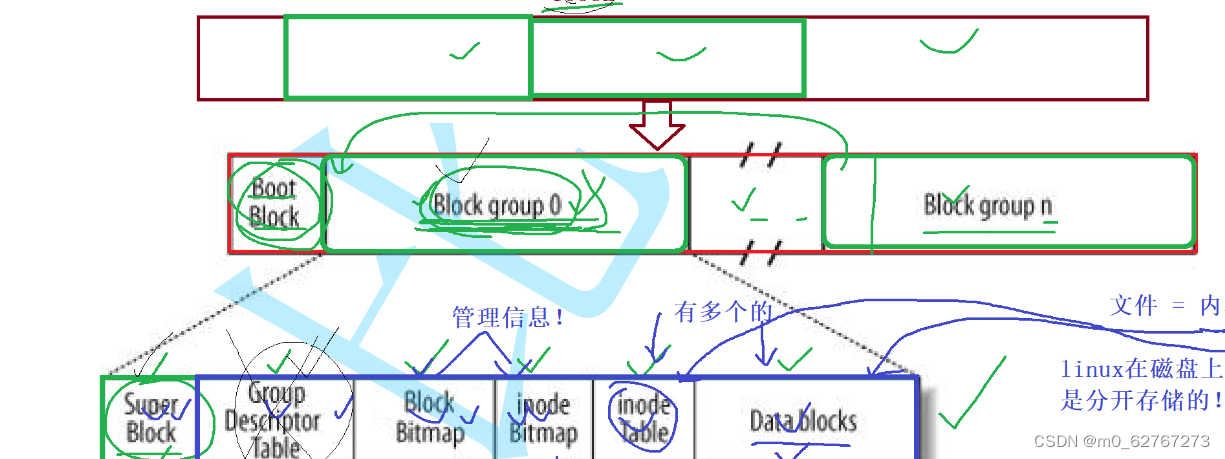
我们来看看这样一个小分区里面都有什么
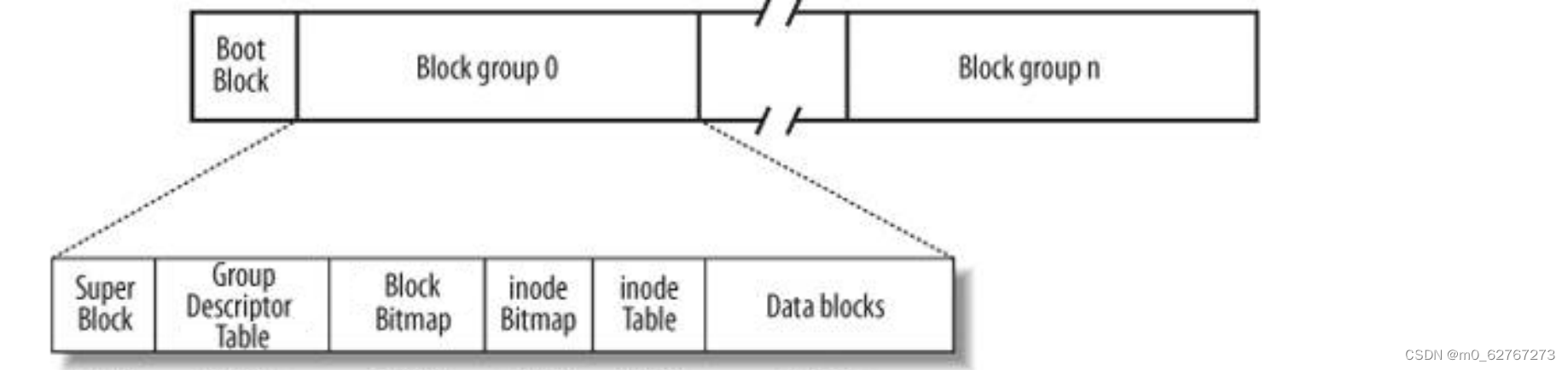
首先我们知道Linux在磁盘上存储文件的时候,将文件的内容和属性是分开存储的。
虽然磁盘的基本单位是扇区:512字节,但是操作系统和磁盘进行IO的基本单位是4KB(8*512字节)
那么为什么不以512字节为单位呢?
- 太小了,有可能会导致多次IO,进而导致效率的降低。
- 如果操作系统使用和磁盘一样的大小,万一磁盘的基本大小变了的话,OS的源代码要不要改呢?所以我们不将单位设置为跟扇区一样的大小,这就实现了在硬件和软件(OS)进行解耦。
Super Block:文件系统的属性信息,那你可能有疑惑,文件系统的属性信息为什么会保存在一个小块组中呢?
我们知道磁盘的磁盘不是距离磁头很近吗,一不小心磁头可能就会划伤盘面,万一你的文件系统属性信息只有一份,并且被划伤了呢,所以这其实是拷贝多份,存放在这里,也是为了便于修复。
Data blocks:多个4KB大小的集合,保存的都是特定文件的内容。
inode Table:inode是一个大小为128字节的空间,保存的是对应文件的属性,该块组内所有文件的inode空间的集合,需要标识唯一性,每一个inode块,都要有一个inode编号,一般而言一个文件,一个inode,一个inode编号。
Block Bitemap:假设有10000+个biocks,就有10000+比特位:比特位和特定的blocks是一 一对应的。其中比特位为1,代表该blocks被占用,否则表示可用。
inode Bitemap:假设有10000+个inode节点,就有10000+个比特位,比特位和特定的inode是一 一对应的,其中比特位为1,代表该inode被占用,否则表示可用。
Group Descriptor Table(GDT):块组描述符,这个块组多大,已经使用多少了,有多少个inode,已经占用了多少个,还剩多少,一共有多少了block,使用了多少。
这些信息,能够让一个文件的信息可追溯、可管理!
我们讲块组分割成为上面的内容,并且写入相关的管理数据——》每一个块组都这么干,那么整个分区就被写入了文件系统信息,这就叫做格式化。
现在我们还是有几个疑惑:
首先一个文件只对应一个inode属性节点,inode编号。
但是一个文件可能不止对应一个block
-
哪些block同属于一个文件?
我们可以通过inode编号找到对应的inode结构体,在这个inode结构体中保存着文件的各种属性信息,并且保存着一个blocks数组,这个数组一般大小有限,它可以保存文件内容对应的block的编号
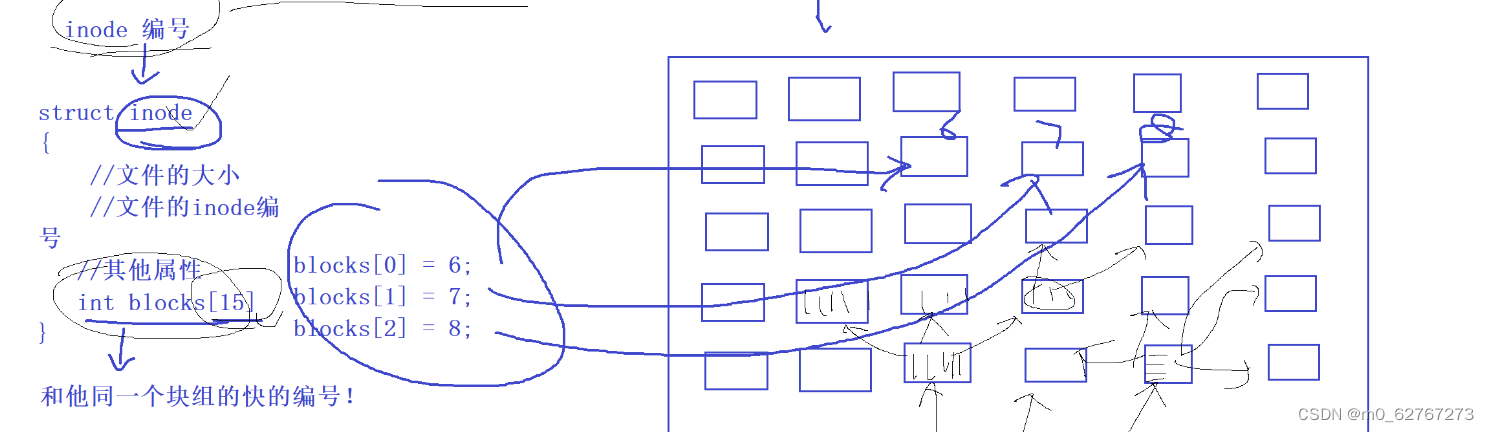
-
找到文件只要找到文件对应的inode编号,就能找到该文件的inode属性集合,可是文件的内容呢?
当文件较小的时候,如果对应的仅仅是几个block块,那么inode中的blocks数组还能保存各个块的编号,但是当文件很大的时候,占据的block很多,这时数组就存不下了,那么怎么办呢?
其实在data block中,data block不是只能存储数据,也可以存储其他块的块号。
这样一来,如果文件太大的话,那么在blocks数组的前12个block块存储的是文件的内容,后三个block块就可以存储文件对应其他block块的编号,一个block块中能存储相当多的block块编号,就算还是不够,那就用这种方式递归下去,在最后的几个编号对应的block块中继续存编号。
inode vs 文件名
找到一个文件:inode编号 – > 分区特定的块组 --> inode --> 属性 --> 内容
但是首要的问题是:你是怎么知道inode编号的。
在Linux中,inode属性里面其实是没有文件名这样的说法的。
既然这样,我们平常用那些命令比如创建一个文件,查看文件属性,都用的是文件名啊,inode中有有没有文件名,不仅如此,就算有我们又是如何找到inode编号的呢,找不到inode编号一切都无从谈起。
我们可以想一下,我们对文件的操作其实都是在某个目录下进行的。
- 一个目录下,可以保存很多文件,但是这些文件没有重复的文件名。
- 目录也是一个文件,既然是文件就有自己的 inode 和 data block,而目录下的文件的文件名以及inode编号,就是保存在目录的 data block中,inode编号和文件名构成映射映射关系,文件名 :inode编号,互为key值
知道了上面的信息,那我们就可以解释之前为什么我们创建一个文件,对于文件所在的目录我们需要有w权限,显示文件名和属性,需要目录的r权限了。
因为创建文件,新文件的inode编号和文件名的映射关系肯定要写入目录的 data block中,所以需要写权限
而显示文件名和文件属性,文件名和inode编号都在目录的data block中,我们肯定要去访问这个内存区域,所以就需要读权限。
三个问题
-
创建文件,系统做了什么?
首先找到目录所在的分区,在这个分区上找到inode bitmap,在里面从前往后找到首个为0的位置,然后记录编号,这就是inode编号,然后在inode table中找到对应的空闲位置,写入你要创建文件的属性信息,然后看你新创建的文件写入内容吗,没有的话就将inode中的blocks数组置为无效值。此时文件属性,内容都已创建完毕,然后就是把文件名和inode编号的映射关系写入目录的data block中。 -
删除文件,系统做了什么?
删除文件,首先我们知道文件名,通过文件名我们可以从目录的datablock得知inode编号,通过inode编号,找到文件对应的inode,然后把文件所占用的data block对应block bitmap中的位置0,把这个inode对应在inode bitemap中的位置0,然后还要删除目录data block中该文件和inode编号的映射。
所以我们可以知道,删除一个文件并没有把该文件的inode和data block的空间清空,它只是把对应空间置为空闲了,当你要创建其他文件时,可以直接覆盖式地写入这些空间。所以被删除的文件其实是可以被恢复的,只要把它的原来的inode位图对应位置置为1,block位图对应的位置置1就ok了,但前提是inode编号没有被使用,inode和data block没有被覆盖。 -
查看文件,系统做了什么?
老套路,找到目录的inode,访问目录的datablock信息这时就有了文件名以及文件的inode编号,找到对应文件的inode,就能找到文件对应的data block,访问就可以查看文件内容了。
分区格式化,就是初始化分区中的super block,GDT,block位图,inode位图,就是在磁盘中写入文件系统。
分区中的inode区域大小是固定的,datablock区域大小也是固定的。
所以有时候我们会遇见这样的情况,比如你看到你的磁盘还有空间但是创建文件却失败了,有可能就是你的inode域有空间,但是data block域没空间了,或者反过来。















 6402
6402











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









