






正则表达式的由以下两类字符中的一种或者两种组成
1、原义字符
2、元字符:基本元字符
重复元字符
范围元字符
转义字符
分组
后向引用
非贪婪匹配符
零宽断言
创建正则表达式:
let 变量=/正则表达式/;
let 实例名=new RegExp("正则表达式");
一、基本元字符
. 表示除了\n以外的任意字符
* 表示前一个字符出现0次或多次
? 表示前一个字符出现0次或1次
+ 表示前一个字符出现1次或多次
^ 表示以后面的字符开头
$ 表示以前面的字符结尾
| 表示两端字符选择其中一个
(1) 正则表达式相关的字串方法
字符串.match(reg); //返回指定字符串中能够匹配正则表达式reg的子串
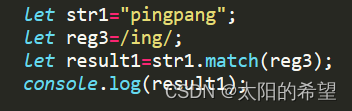
![]()
字符串.search(reg); //返回指定字符串中能够匹配正则表达式reg的子串的索引
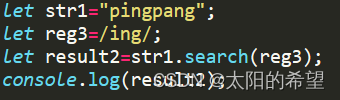
![]()
(2)正则表达式修饰符
g 全局匹配修饰符
i 忽略大小写匹配修饰符
let 变量=/正则表达式/修饰符;
let 实例名=new RegExp("正则表达式","修饰符");
(3)与测试字符串是否匹配正则表达式相关的正则表达式方法
正则表达式.test(字符串);(逻辑型)
二、重复元字
{m} 表示前面的字符重复m次。
{m,} 表示前面的字符重复m次或多次。
{m,n} 表示前面的字符最少重复m次,最多n次。
三、范围元字符
[a-z] 表示a到z其中的1个字符
[A-Z] 表示A到Z其中的1个字符
[0-9] 表示0-9其中的1个字符
[a-zA-Z0-9] 表示大小写字母数字
[n-v] 表示小写字母n到v的一部分
[^c-f] 表示除了c到f以外的所有字符
[abc] 表示a、b、c、中的1个字符,与/a|b|c/等同
例:匹配手机号码的正则表达式
(1) 13 和 18 开头的手机号是全段 1[38][0-9]{9}
(2) 15 和 19 开头的手机号后面除 4 外都有 1[59][0-35-9][0-9]{8}
(3) 17 开头的手机号后面除 9 外都有。 17[0-8][0-9]{8}
(4) 14 开头的手机号除 2,3 外都有。 14[014-9][0-9]{8}
(5) 16 开头的手机号后面只有 2、 5、 6、 7。 16[2567][0-9]{8}
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>正则表达式</title>
</head>
<body>
手机号码:<input type="text" class="tel" />
<button onclick="test()">判断</button>
<script type="text/javascript" src="js/index.js"></script>
</body>
</html>let telNode=document.querySelector(".tel");
function test(){
let tel=telNode.value;
let reg=/^1[38][0-9]{9}|1[59][0-35-9][0-9]{8}|17[0-8][0-9]{8}|14[014-9][0-9]{8}|16[2567][0-9]{8}$/;
if(!reg.test(tel)){
window.alert(`请输入正确的手机号码。`);
}
}四、转义字符
\w 匹配数字、大小写字母 ,相当于[a-zA-Z0-9]
\W 与\w相反,相当于[^a-zA-Z0-9]
\d 匹配数字,相当于[0-9]
\D 匹配非数字,相当于[^0-9]
\s 匹配空白符,(空格、回车、Tab键)
\S 匹配非空白符
\b 匹配单词边界,(句子开头、空格、标点符号)
\B 匹配非单词边界
(1)根据 ASCII码或Unicode码指代的特殊字符
\ddd 表示利用三位八进制数字作为ASCII码对应的字符。
\xhh 表示利用两位十六进制数字作为ASCII码对应的字符,其中x是固定格式。
\uxxxx 表示利用四位十六进制数字作为Unicode码对应的字符,其中u是固定格式。
转换公式:R进制转换为10进制:Number.parseInt(str,radix);
10进制转换为R进制:toString(radix)















 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











