






实验步骤:
步骤一:先定义一个结构体g,其中包含文法的左部和文法的右部,用来记录用户输入的所有文法信息;
步骤二:定义变量,整型变量i记录文法的总条数;结构体变量G记录文法信息;一维字符数组fzjf记录所有非终结符;二维字符数组FIRST记录所有非终结符各自的FIRST集;二维字符数组LAST记录所有非终结符各自的LAST集;一维字符数组test记录所要分析的字符串;一维字符数组Q记录符号栈,并将Q[0]置为‘#’;其余变量在需要的时候再定义(存在一定的不足);
步骤三:提示用户按规定输入文法;"请输入文法,例如Z bMb表示Z->bMb,# #表示结束,^表示空:\n";如果用户输入的文法存在两个产生式的右部相同,提示用户重新输入;
步骤四:用一个循环接受用户输入的文法,并将非终结符号记录下来;
步骤五:进行判断,如果i>1表明用户输入了文法,否则提示用户,"你没有输入文法!",并退出该程序;
步骤六:定义一个整型变量flag=0和count=0用来控制求FIRST和LAST集的无限循环,即一旦某一个非终结符的FIRST(LAST)被加入了新的符号,flag=1,而一旦某一个非终结符的FIRST(LAST)没有被加入了新的符号,flag=0,count根据flag的情况进行改变,flag=1,count=0;flag=0,count++;
步骤七:求FIRST(LAST)集:用一个循环无限遍历所有非终结符号,循环内用一个循环遍历所有的文法,如果文法的左部和非终结符相同,分两种情况讨论:(1)文法右部的第一个(最后一个)字符为终结符号,检查非终结符的FIRST(LAST),是否存在该终结符号,如果存在不将其加入FIRST(LAST);如果不存在将其加入FIRST(LAST)(2)文法右部的第一个(最后一个)字符为非终结符号,检查非终结符的FIRST(LAST),是否存在该非终结符号,如果存在不将其加入FIRST(LAST);如果不存在将其加入FIRST(LAST),再去遍历该非终结符的FIRST(LAST),并检查是否已经存在将要加入的符号,如果有则不加,如果没有要将其加入;直到退出该循环,即可求得每个非终结符的FIRST(LAST);
步骤八:定义一个二维字符串数组gx用来记录个符号之间的关系,首先求等号关系,遍历所有文法,如果文法的右部长度大于一,则存在等号关系,将等号记录在二维数组每行的第二个位置上,左右两边分别记录对应的符号;其次求大于号关系,遍历所有文法,如果文法的右部长度大于一,并且非终结符号在前,终结符号紧跟在非终结符号后面,则存在大于号关系,将大于号记录在二维数组每行的第二个位置上,左右两边分别记录非终结符号的LAST集里的所有符号,终结符号;最后求小于号关系,遍历所有文法,如果文法的右部长度大于一,并且终结符号在前,非终结符号紧跟在终结符号后面,则存在小于号关系,将小于号记录在二维数组每行的第二个位置上,左右两边分别记录终结符号,非终结符号的FIRST集里的所有符号;注意检查输入的文法是否存在两个符号有大于1中优先关系,如果有提示用户重新输入;
步骤九:打印关系表,并提示用户输入要分析的字符串,在字符串的最后一位添上‘#’;
步骤十:定义整型变量Qi = 1,testi = 0,foundflag,bt = 0;分别表示Q的栈顶“指针”,test队列的出队“指针”,出错标记,步骤序号;
步骤十一:一个无限循环,当符号栈里只有一个‘#’和一个开始符号,并且输入符号串只剩下一个‘#’时,打印当前的状态并退出该循环;否则用一个循环遍历关系表里的所有关系此时foundflag=0,并用关系表里的每条关系的比较符号的左右两边的符号分别与符号栈Q的最顶的符号和test[testi]进行匹配,如果都相同,看其比较符号为什么,有两种情况(1)‘<’和‘=’,下一步动作为移进,(2)‘>’下一步动作为规约;否则foundflag一直等于0,退出该循环后,判断foundflag的值,如果为0,退出无限循环并显示出错位置,如果为1,看是否满足退出大循环的条件,满足退出大循环,不满足继续进行循环。
步骤十二:步骤十一的两种情况:(1)移进:在移进的过程中,先把比较符号‘<’或‘=’移进再将testi所指的字符移进,testi++;(2)归约:找到可归约的文法,将文法的左部非终结符号与字符栈Q中的靠近栈顶小于号的左边的非‘#’符号进行比较,如果能找到关系先将其比较符号入栈在将归约后的非终结符入栈,否则提示用户出错。
特别说明:在本次实验中的简单优先分析表也是算法实现的。
#include<stdio.h>
#include<string.h>
struct g{
char left[2];//为1的时候可能越界了!!!
char right[100];
};
int main()
{
int i = 0,pf;//i表示共有i文法
struct g G[100];
char fzjf[100];
char FIRST[100][100];
char LAST[100][100];
char test[100];
char Q[100];//符号栈
Q[0] = '#';
printf("请输入文法,例如Z bMb表示Z->bMb,# #表示结束,^表示空:\n");
while(1) //后续应该加强输入的健壮性
{
i++;
scanf("%s %s",&G[i].left,&G[i].right);
for(int wf = 1;wf<i;wf++)//如果有两个产生式的右部相同,那么在寻找左部时,会出错!
{
int a = 0,aa = 0;
while(G[wf].right[a]!='\0'||G[i].right[aa]!='\0')
{
if(G[wf].right[a] != G[i].right[aa])
break;
else
{
a++;
aa++;
}
}
if(G[wf].right[a]=='\0'&&G[i].right[aa]=='\0')
{
printf("输入的文法存在两个产生式的右部相同!请重新输入!\n");
return 0;
}
}
if(G[i].left[0] == '#' && G[i].right[0] == '#')
break;
for(pf = 0;pf<strlen(fzjf);pf++)//求得所有的非终结符号
{
if(G[i].left[0] == fzjf[pf])
break;
}
if(pf == strlen(fzjf))
{
fzjf[pf] = G[i].left[0];
fzjf[pf + 1] = '\0';
}
}
if(i>1)
{
G[0].left[0] = '@';
G[0].right[0] = '#';
G[0].right[1] = G[1].left[0];
G[0].right[2] = '#';
}
else
{
printf("你没有输入文法!");
return (0);
}
// for(int j = 0;j<i;j++)//j变量用来遍历文法数组
// {
// printf("%s %s\n",G[j].left,G[j].right);
// }
// for(int j = 0;j<strlen(fzjf);j++)//遍历非终结符号数组
// {
// printf("%c\n",fzjf[j]);
// }
//求FIRST
int flag,count = 0;
for(int k = 0;;k++)//遍历所有非终结符
{
flag = 0;
k = k%strlen(fzjf);
for(int j = 0;j<i;j++)//遍历所有的文法
{
if(G[j].left[0] == fzjf[k])
{
if(!(G[j].right[0] >='A' && G[j].right[0] <='Z'))//文法右部的第一个字符为终结符号,将其去重后再加入对应的FIRST集中
{
int bl;
for(bl = 0;bl < strlen(FIRST[k]);bl++)
{
if(FIRST[k][bl] == G[j].right[0])
break;
}
if(bl == strlen(FIRST[k]))
{
FIRST[k][strlen(FIRST[k])] = G[j].right[0];
FIRST[k][strlen(FIRST[k]) + 1] = '\0';
flag = 1;
}
}
else//文法右部的第一个字符为非终结符号,去重后要将其本身加入,再去遍历该非终结符再看看其推导出来的右部
{
int bl1;
for(bl1 = 0;bl1 < strlen(FIRST[k]);bl1++)
{
if(FIRST[k][bl1] == G[j].right[0])
break;
}
if(bl1 == strlen(FIRST[k]))///
{
FIRST[k][strlen(FIRST[k])] = G[j].right[0];//将非终结符加入
FIRST[k][strlen(FIRST[k]) + 1] = '\0';
//将非终结符的FIRST集加入
}
int wz;//找到位置
for(wz = 0;wz<strlen(fzjf);wz++)
{
if(fzjf[wz] == G[j].right[0])
break;
}
int bl2;
for(bl2 = 0;bl2<strlen(FIRST[wz]);bl2++)
{
int a;
for(a = 0;a<strlen(FIRST[k]);a++)
{
if(FIRST[k][a] == FIRST[wz][bl2])
break;
}
if(a == strlen(FIRST[k]))
{
FIRST[k][strlen(FIRST[k])] = FIRST[wz][bl2];//将非终结符加入
FIRST[k][strlen(FIRST[k]) + 1] = '\0';
flag = 1;/
}
}
}
}
}
if(flag == 1)
count = 0;
else
count++;
if(count == strlen(fzjf))
break;
}
// for(int jj = 0;jj<strlen(fzjf);jj++)//遍历非FIRST数组
// {
// printf("%s\n",FIRST[jj]);
// } printf("\n");
//求LAST
flag,count = 0;
for(int k = 0;;k++)//遍历所有非终结符
{
flag = 0;
k = k%strlen(fzjf);
for(int j = 0;j<i;j++)//遍历所有的文法
{
if(G[j].left[0] == fzjf[k])
{
if(!(G[j].right[strlen(G[j].right)-1] >='A' && G[j].right[strlen(G[j].right)-1] <='Z'))//文法右部的最后一个字符为终结符号,将其去重后再加入对应的FIRST集中
{
int bl;
for(bl = 0;bl < strlen(LAST[k]);bl++)
{
if(LAST[k][bl] == G[j].right[strlen(G[j].right)-1])
break;
}
if(bl == strlen(LAST[k]))
{
LAST[k][strlen(LAST[k])] = G[j].right[strlen(G[j].right)-1];
LAST[k][strlen(LAST[k]) + 1] = '\0';
flag = 1;
}
}
else//文法右部的最后一个字符为非终结符号,去重后要将其本身加入,再去遍历该非终结符再看看其推导出来的右部
{
int bl1;
for(bl1 = 0;bl1 < strlen(LAST[k]);bl1++)
{
if(LAST[k][bl1] == G[j].right[strlen(G[j].right)-1])
break;
}
if(bl1 == strlen(LAST[k]))
{
LAST[k][strlen(LAST[k])] = G[j].right[strlen(G[j].right)-1];//将非终结符加入
LAST[k][strlen(LAST[k]) + 1] = '\0';
//将非终结符的LAST集加入
}
int wz;//找到位置
for(wz = 0;wz<strlen(fzjf);wz++)
{
if(fzjf[wz] == G[j].right[strlen(G[j].right)-1])
break;
}
int bl2;
for(bl2 = 0;bl2<strlen(LAST[wz]);bl2++)
{
int a;
for(a = 0;a<strlen(LAST[k]);a++)
{
if(LAST[k][a] == LAST[wz][bl2])
break;
}
if(a == strlen(LAST[k]))
{
LAST[k][strlen(LAST[k])] = LAST[wz][bl2];//将非终结符加入
LAST[k][strlen(LAST[k]) + 1] = '\0';
flag = 1;
}
}
}
}
}
if(flag == 1)
count = 0;
else
count++;
if(count == strlen(fzjf))
break;
}
// for(int jj = 0;jj<strlen(fzjf);jj++)//遍历非LAST数组
// {
// printf("%s\n",LAST[jj]);
// }
printf("\n");
char gx[200][5];
//求等号关系
int gxi = 0;
for(int j = 1;j<i;j++)//遍历所有文法
{
if(strlen(G[j].right)>1)
{
for(int t = 0;t<strlen(G[j].right)-1;t++)
{
for(int a = 0;a<gxi;a++)//判断输入的文法是否存在两个符号有大于1中优先关系
{
if(gx[a][0] == G[j].right[t]&&gx[a][1] != '='&&gx[a][2] == G[j].right[t+1])
{
printf("输入的文法存在两个符号有大于1中优先关系!请重新输入!\n") ;
return 0;
}
}
gx[gxi][0] = G[j].right[t];
gx[gxi][1] = '=';
gx[gxi][2] = G[j].right[t+1];
gxi++;
}
}
}
//求大于号关系
gx[gxi][0] = G[1].left[0];
gx[gxi][1] = '>';
gx[gxi][2] = '#';
gxi++;
for(int j = 0;j<i;j++)//遍历所有文法
{
if(strlen(G[j].right)>1)
{
for(int t = 0;t<strlen(G[j].right)-1;t++)
{
if((G[j].right[t]>='A'&&G[j].right[t]<='Z')&&!(G[j].right[t+1]>='A'&&G[j].right[t+1]<='Z'))
{
int wz;
for(wz = 0;wz<strlen(fzjf);wz++)
{
if(G[j].right[t] == fzjf[wz])
break;
}
for(int fz = 0;fz<strlen(LAST[wz]);fz++)
{
for(int a = 0;a<gxi;a++)
{
if(gx[a][0] == LAST[wz][fz]&&gx[a][1] != '>'&&gx[a][2] == G[j].right[t+1])//判断输入的文法是否存在两个符号有大于1中优先关系
{
printf("输入的文法存在两个符号有大于1中优先关系!请重新输入!\n") ;
return 0;
}
}
gx[gxi][0] = LAST[wz][fz];
gx[gxi][1] = '>';
gx[gxi][2] = G[j].right[t+1];
gxi++;
}
}
}
}
}
//求小于号关系
gx[gxi][0] = '#';
gx[gxi][1] = '<';
gx[gxi][2] = G[1].left[0];
gxi++;
for(int j = 0;j<i;j++)//遍历所有文法
{
if(strlen(G[j].right)>1)
{
for(int t = 0;t<strlen(G[j].right)-1;t++)
{
if(!(G[j].right[t]>='A'&&G[j].right[t]<='Z')&&(G[j].right[t+1]>='A'&&G[j].right[t+1]<='Z'))
{
int wz;
for(wz = 0;wz<strlen(fzjf);wz++)
{
if(G[j].right[t+1] == fzjf[wz])
break;
}
for(int fz = 0;fz<strlen(FIRST[wz]);fz++)
{
for(int a = 0;a<gxi;a++)
{
if(gx[a][0] == G[j].right[t]&&gx[a][1] != '<'&&gx[a][2] == FIRST[wz][fz])//判断输入的文法是否存在两个符号有大于1中优先关系
{
printf("输入的文法存在两个符号有大于1中优先关系!请重新输入!\n") ;
return 0;
}
}
gx[gxi][0] = G[j].right[t];
gx[gxi][1] = '<';
gx[gxi][2] = FIRST[wz][fz];
gxi++;
}
}
}
}
}
printf("关系表\n");
for(int j = 0;j<gxi;j++)
{
printf("%c %c %c\n",gx[j][0],gx[j][1],gx[j][2]);
}printf("\n");
printf("输入要识别的字符串:\n");
scanf("%s",&test);
test[strlen(test)] = '#';
test[strlen(test)+1] = '\0';
int Qi = 1,testi = 0,foundflag,bt = 0;
while(1)
{
int found = 0;
if(strlen(Q) == 2&&test[testi] == '#')
{
printf("%d ",bt++);
for(int f = 0;f<strlen(Q);f++)//输出符号栈
{
if(Q[f]!='>'&&Q[f]!='='&&Q[f]!='<')
printf("%c",Q[f]);
}printf(" ");
for(int bl = testi;bl<strlen(test);bl++)//输出剩余符号
{
printf("%c",test[bl]);
}printf(" ");
printf(" 接受");
break;
}
foundflag = 0;
for(found = 0;found<gxi;found++)
{
if(gx[found][0] == Q[strlen(Q) - 1] && gx[found][2] == test[testi])//查关系表 (第一个终结符和队列先出的字符进行比较!!!!!!!!!!!!!!!!)
{
if(gx[found][1] == '<'||gx[found][1] == '=')//动作:移进
{
if(bt == 0)
{
printf("步骤 符号栈 输入符号串 动作 出错信息\n");
bt++;
}
printf("%d ",bt++);
for(int f = 0;f<strlen(Q);f++)//输出符号栈
{
if(Q[f]!='>'&&Q[f]!='='&&Q[f]!='<')
printf("%c",Q[f]);
}printf(" ");
for(int bl = testi;bl<strlen(test);bl++)//输出剩余符号
{
printf("%c",test[bl]);
}printf(" ");
printf(" 移进\n");
Q[Qi] = gx[found][1];
Q[Qi+1] = test[testi];
Q[Qi+2] = '\0';
Qi = strlen(Q);
testi++;
}
else if(gx[found][1] == '>')//动作:归约
{
printf("%d ",bt++);
for(int f = 0;f<strlen(Q);f++)
{
if(Q[f]!='>'&&Q[f]!='='&&Q[f]!='<')
printf("%c",Q[f]);
}printf(" ");
for(int bl = testi;bl<strlen(test);bl++)
{
printf("%c",test[bl]);
}printf(" ");
printf(" 归约");
for(int bl1 = 0;bl1<i;bl1++)//遍历文法
{
int bl2,bl3,count = 0;
for(bl2 = strlen(G[bl1].right)-1,bl3 = strlen(Q)-1;bl2>=0;bl2--)
{//printf("找归约式");
if(Q[bl3] == '>'||Q[bl3] == '='||Q[bl3] == '<')
{
bl3--;
}
if(Q[bl3] != G[bl1].right[bl2])
break;
bl3--;
}
if(bl2 == -1&&Q[bl3] == '<')
{//printf("\n找到归约式\n");
if(Q[bl3-1]!='#')
{
int y;
for(y = 0;y<gxi;y++)
{//printf("\n%c %c %c %c\n",gx[y][0],Q[bl3-1],gx[y][2],G[bl1].left[0]);
if(gx[y][0] == Q[bl3-1] && gx[y][2] == G[bl1].left[0])
{
Q[bl3] = gx[y][1];
Q[bl3 + 1] = G[bl1].left[0];
Q[bl3 + 2] = '\0';
Qi = strlen(Q);
}
}
}
else
{
Q[bl3] = G[bl1].left[0];
Q[bl3+1] = '\0';
Qi = strlen(Q);
}printf("(%c->%s)\n",G[bl1].left[0],G[bl1].right);
break;
}
}
}
foundflag = 1;
}
}
if(foundflag == 0)
{
printf("%d ",bt++);
for(int f = 0;f<strlen(Q);f++)
{
if(Q[f]!='>'&&Q[f]!='='&&Q[f]!='<')
printf("%c",Q[f]);
}printf(" ");
for(int bl = testi;bl<strlen(test);bl++)
{
printf("%c",test[bl]);
}printf(" ");
printf(" 出错! %c与%c没有关系",Q[strlen(Q)-1],test[testi]);
break;
}
}
return 0;
} 测试样例
Z bMb
M a
M (L
L Ma)
# #
b(aa)b//出错
Z bMb
M a
M (L
L Ma)
# #
b(aa)//文法不全,导致分析出错
Z bMb
M (L
L Ma)
# #
b(aa)//非简单优先文法
//有两种字符的优先关系大于一
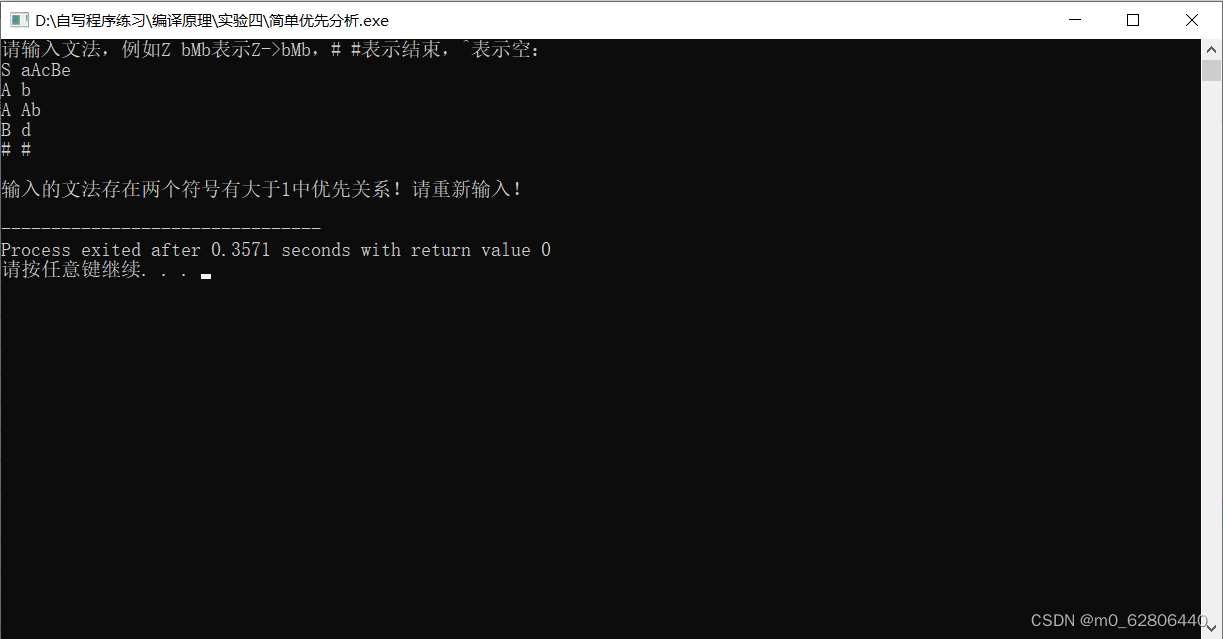
S aAcBe
A b
A Ab
B d
# #
abbcde//有两个文法的产生式相同
Z bMb
Z a
M a
M (L
L Ma)
# #
b(aa)b
结果
若输入的文法不是简单优先文法
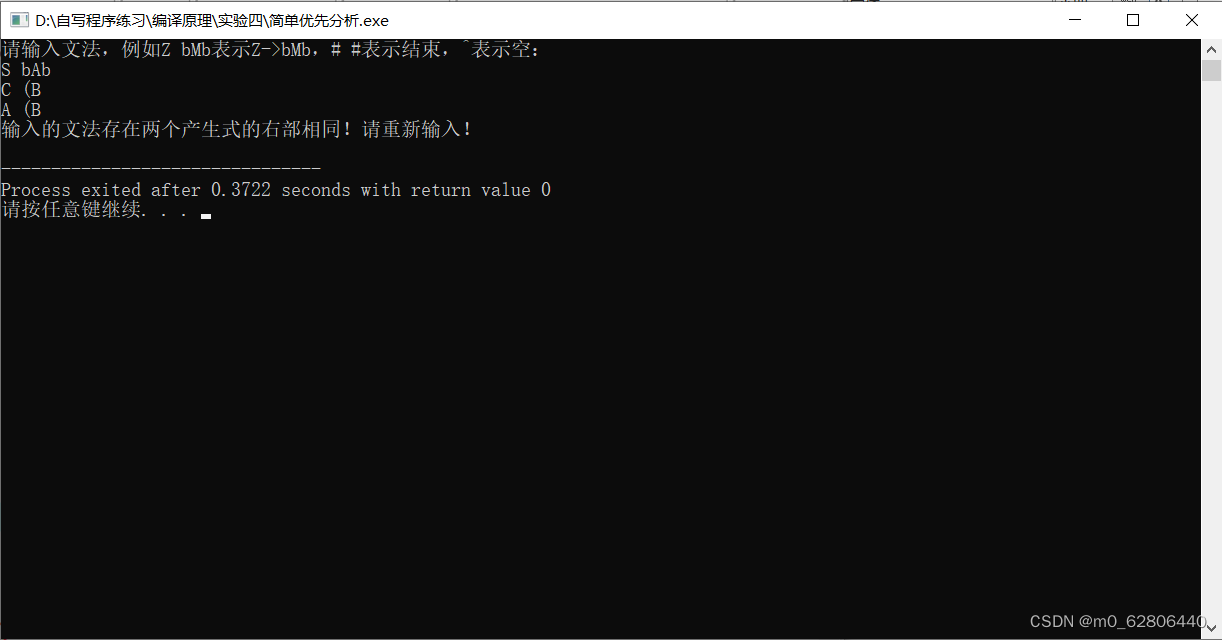
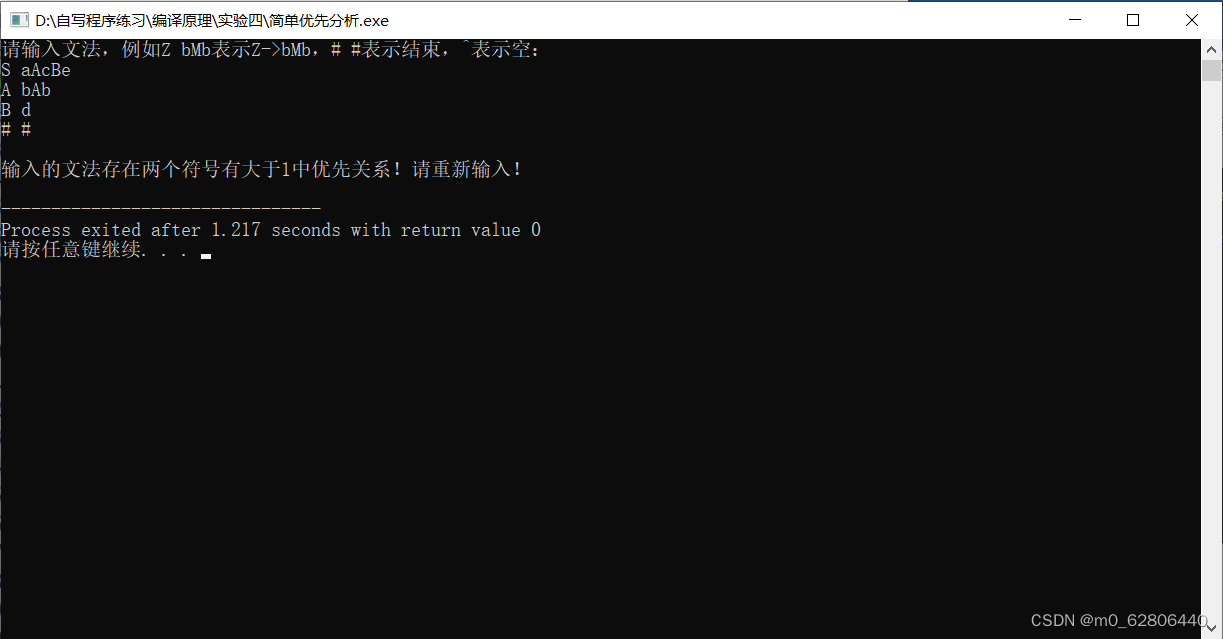
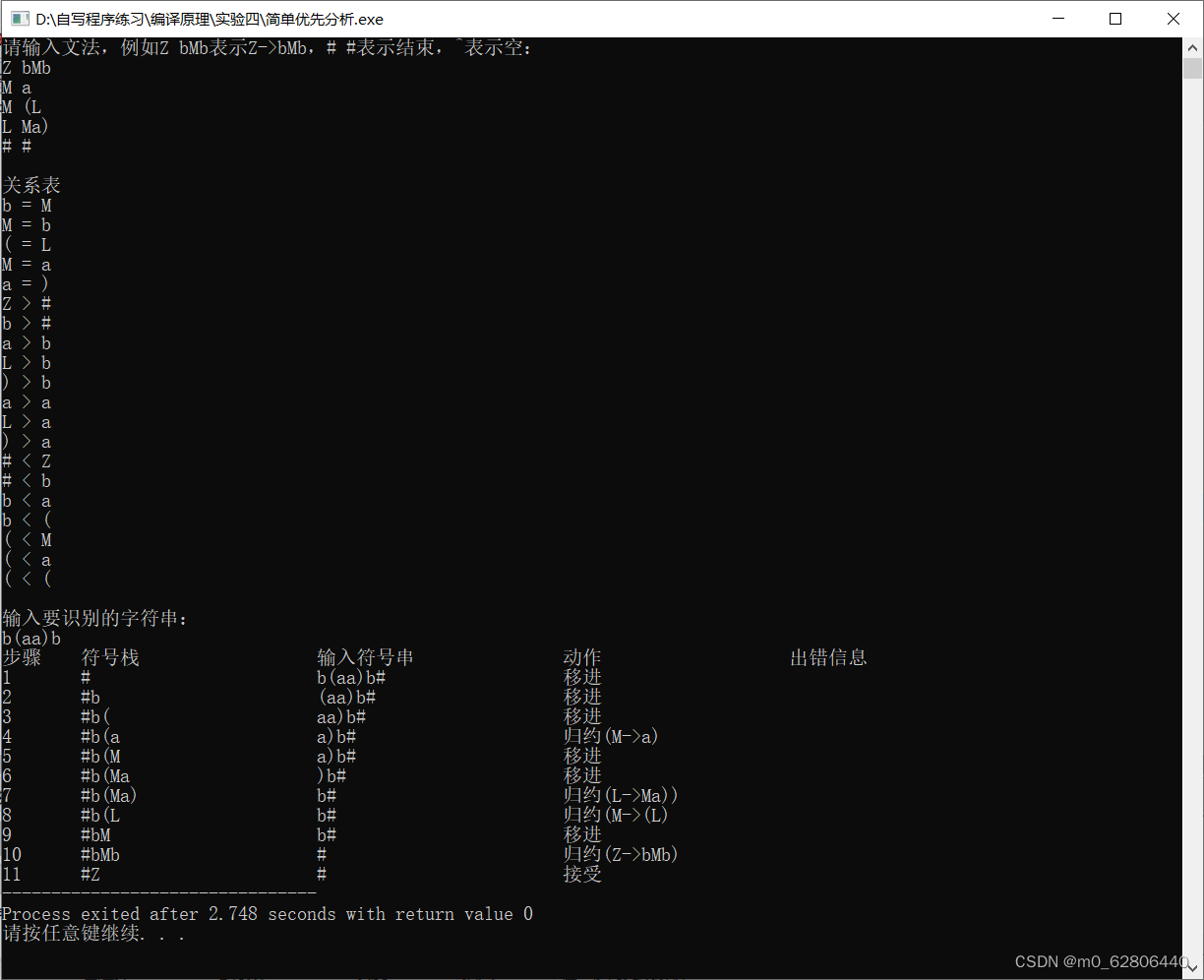
若输入的文法是简单优先文法,开始分析字符串
接受
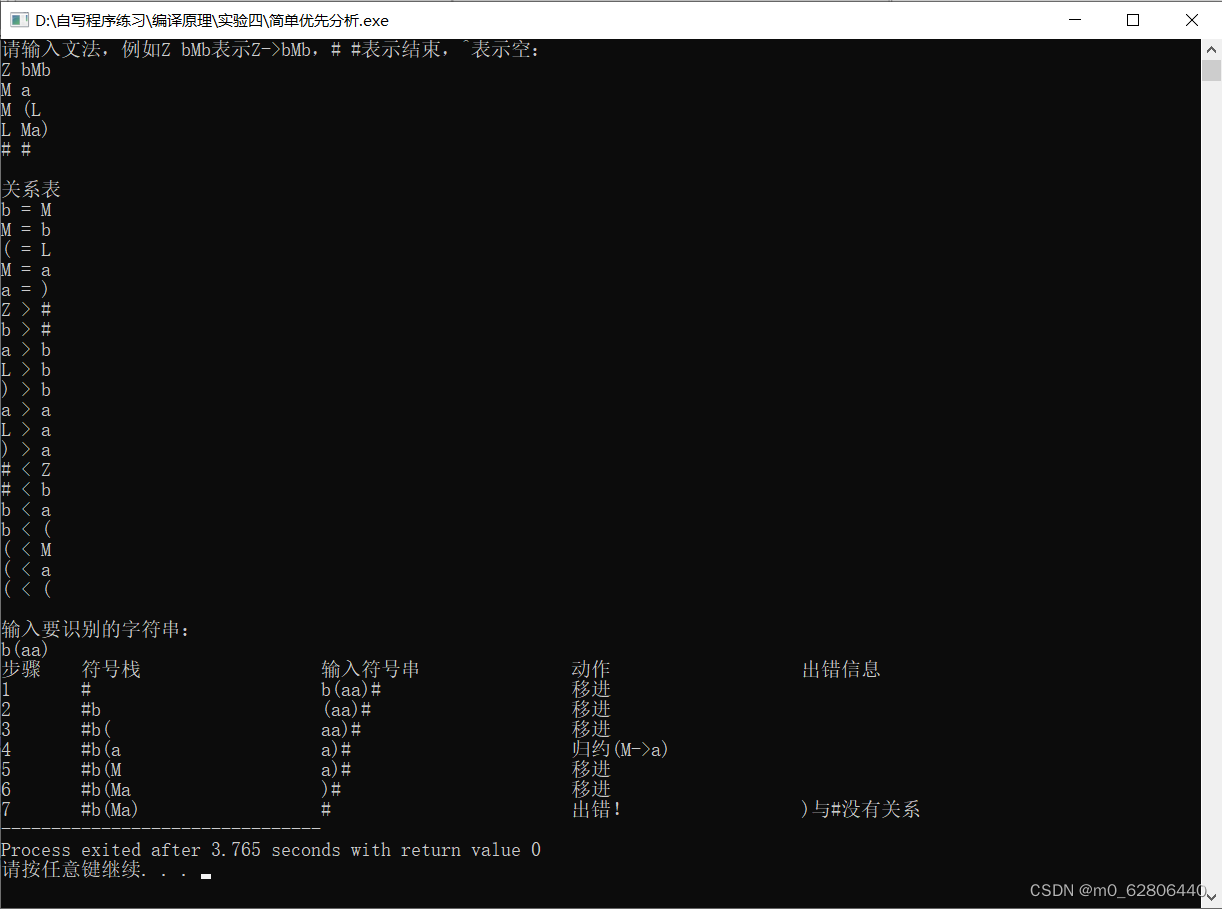
出错
总结:
- 数组要注意长度防止越界;
- 文法的输入有待提升其健壮性,比如当用户输入空行或非法的字符时,应提醒用户重新输入;
- 在使用简单优先分析法时,必须保证输入的文法是简单优先分析文法,当用户输入的文法有两个产生式的右部相同或者在分析关系表时两个字符有大于1的优先关系时,退出该程序并提示用户输入的文法不是简单优先文法。因不是简单优先算符文法,在归约时会有歧义;
- 在计算FIRST(LAST)集时,用变量去记录是否得到最终的FIRST(LAST)集;
- 在分析各个字符间的关系时,不能忘记#的优先性小于所有符号,所有符号的优先性大于#,当然这里只是对与#号有相邻关系的文法符号而言;
- 在分析各个字符间的关系时,同时还要看看是否已经存在不同的优先关系了,如果存在则退出该程序并提示用户输入的文法不是简单优先文法。因不是简单优先算符文法,在归约时会有歧义;
- 当用户输入识别的字符串后要在字符串后加入#号;
- 在识别字符串时要进行出错处理;
- 注意在归约得到非终结符号不能先将其压入栈中,而是将归约前的小于号前面的符号与归约后的非终结符去查关系表,得到比较符号,将比较符号替换原来的小于号,并将非终结符号压入栈中(即紧挨着查表得到的比较符号存放);
- 归约后得到的是非终结符号,将其与小于号前面的符号进行查表,不可能查到大于符号。















 5508
5508











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









