






 本文介绍了如何下载并使用WikiExtractor从Wikipedia获取数据,包括中文语料的下载、工具的准备、以及在过程中遇到的常见问题如.extractor不存在和ValueError:cannotfindcontextforfork的解决方法。还提到了模板错误的处理和注意事项。
本文介绍了如何下载并使用WikiExtractor从Wikipedia获取数据,包括中文语料的下载、工具的准备、以及在过程中遇到的常见问题如.extractor不存在和ValueError:cannotfindcontextforfork的解决方法。还提到了模板错误的处理和注意事项。
一、数据准备:
下载Wikipedia的语料。
中文语料下载地址:https://dumps.wikimedia.org/zhwiki/latest/zhwiki-latest-pages-articles.xml.bz2,可通过查询自己需要的语种的639-1码,将zh替换成你需要的语种即可。(下载之后不要解压)
不同语种的639-1码查询链接:ISO 639-1代码表 各种语言语种对应缩写表_iso语言代码-CSDN博客
二、工具准备:
下载WikiExtractor。地址:项目目录预览 - wikiextractor - GitCode
三、提取语料:
将提前下载好的语料包clone到WikiExtractor.py同一目录下,cd到当前路径
python WikiExtractor.py -b 1024M -o zhwiki zhwiki-latest-pages-articles.xml.bz2-b 1024M 其中1024M是指单个文件允许的最大的占用硬盘的大小
-o 文件输出路径
zhwiki 指输出数据存放文件夹(按1024M为单位切分生成多个文件)
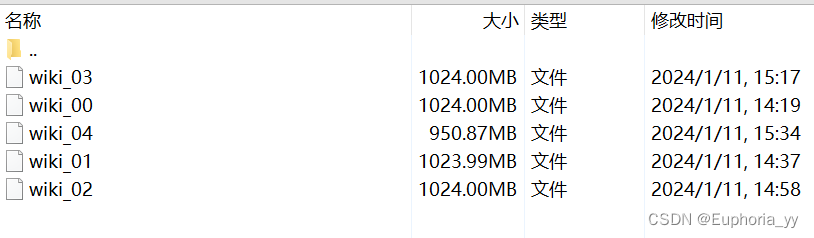
zhwiki-latest-pages-articles.xml.bz2 指需要提取的语料
常见报错:
1.解决Wikiextractor运行出现.extractor不存在的问题

出现了_main_.extractor不存在的问题。问题的地方在Wikiextractor.py的66行
解决方案:在.extract前加wikiextractor或者去掉.

from extract import Extractor, ignoreTag, define_template, acceptedNamespaces2. ValueError: cannot find context for fork
这个错误通常出现在 Windows 系统上,因为 Windows 不支持 fork方法,而 fork 是 Multiprocessing 模块默认使用的创建进程的方式。
解决方案:
1.尝试更换创建进程的方式,可以使用 spawn 或者 forkserver 方法来创建进程,这两种方法可以在 Windows 上使用
2.升级到 Python 3.8 及以上版本,Python 3.8 引入了新的 multiprocessing.get start method 方法,可以方便地更改创建进程的方式。
3.修改代码。如果你的代码中使用了 fork() 方法,那么你需要修改代码,使用其他方式创建进程。
4.在Linux系统上使用WikiExtractor。
3.Template errors in article

其实这个不算报错,是因为某些模板包含错误或无效的语法。只是不符合代码的模板,不影响提取的进行,可能最后会影响提取的效果。

















 1871
1871

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









