






我选择爬虫作为python期末作业,爬取成都链家租房网站信息。
先说一下我的思路:
1、请求租房首页,获取列表中各个房屋的详情页url
2、请求各个房屋的详情页,爬取其中的房屋详情信息
3、翻页,爬取更多数据
4、保存数据至本地
首先打开我们的目标网站,我想爬的是链家官方的锦江区一居室,七百多条条数据完全够用了。
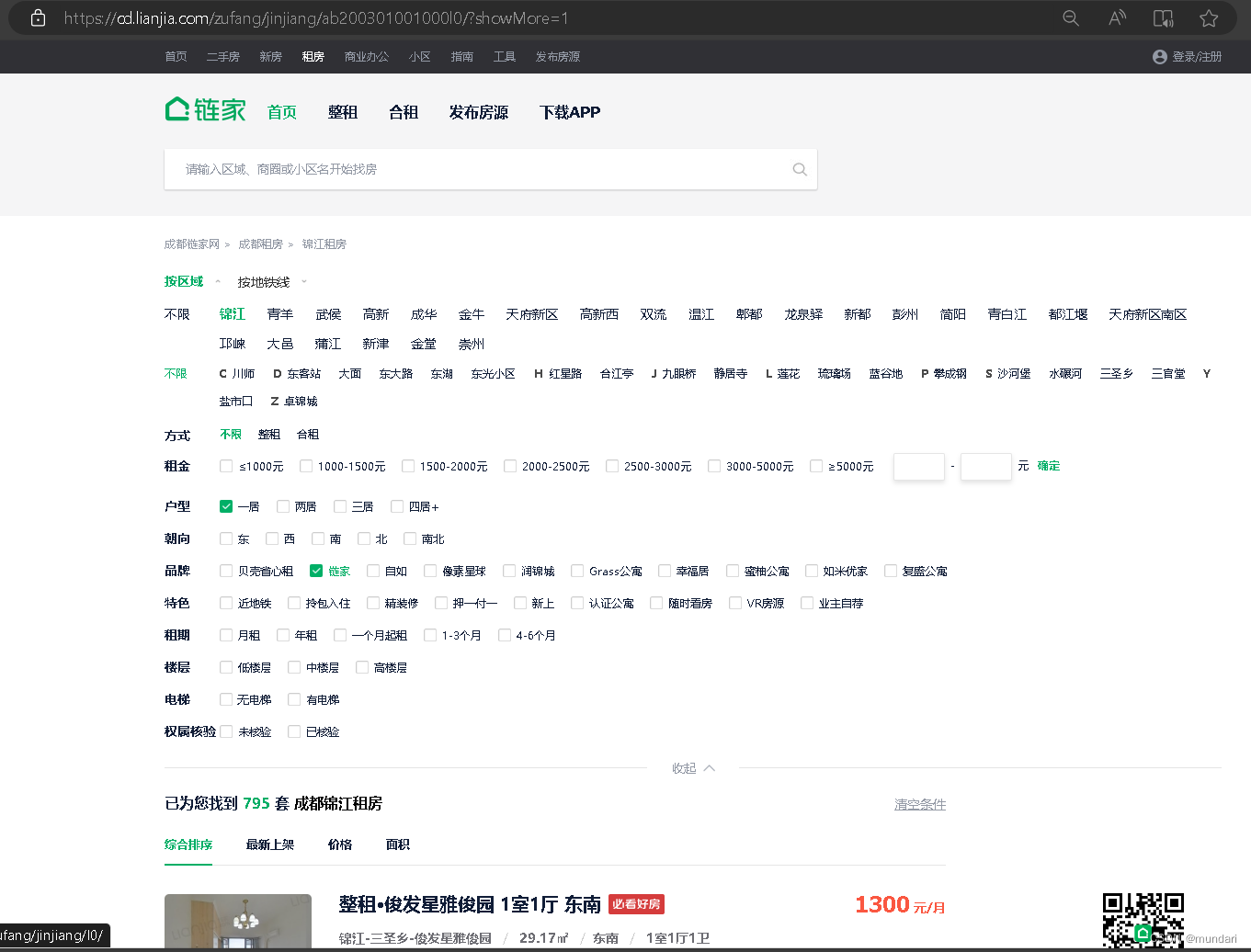
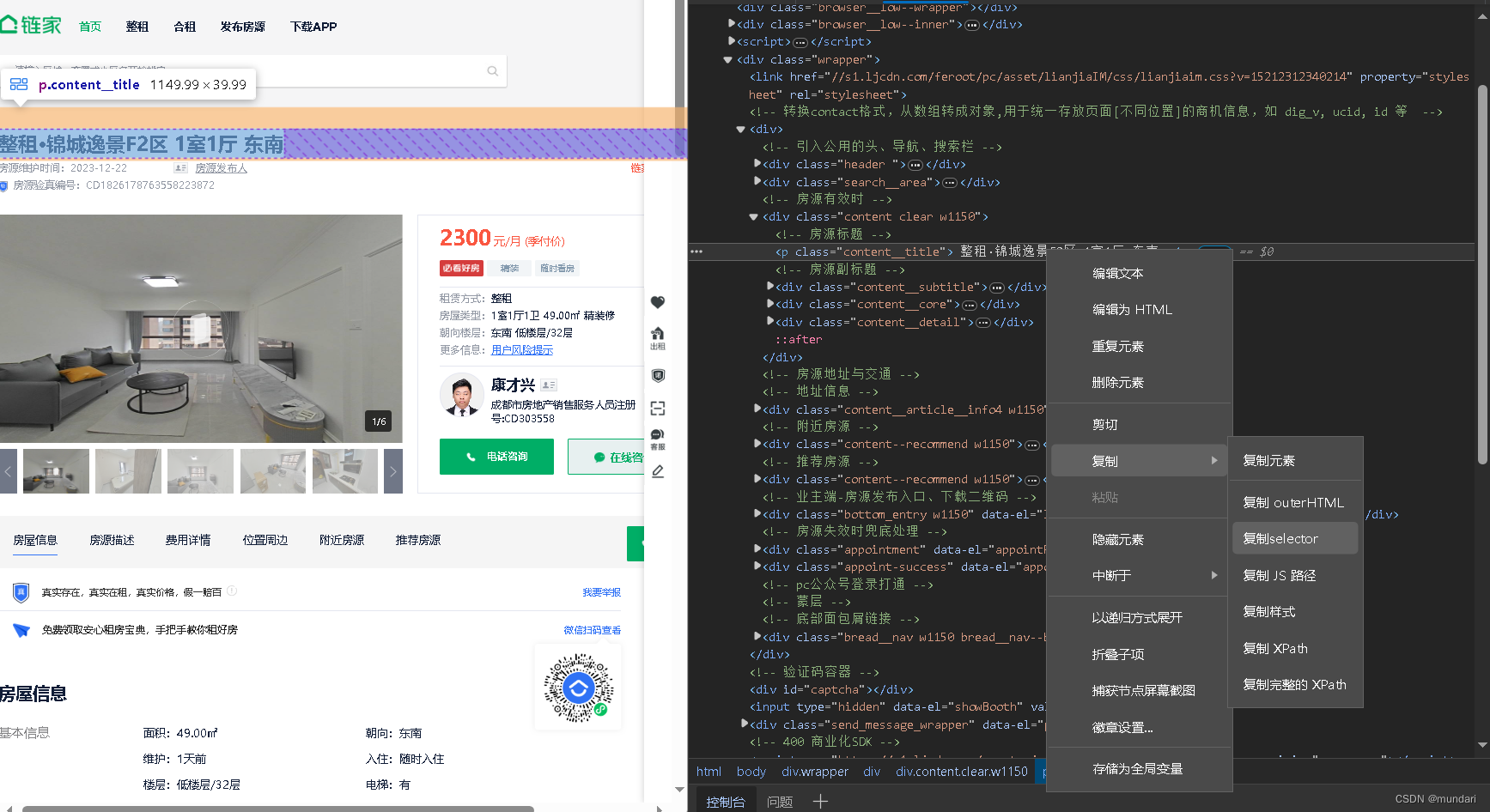
然后鼠标右键进行检查:
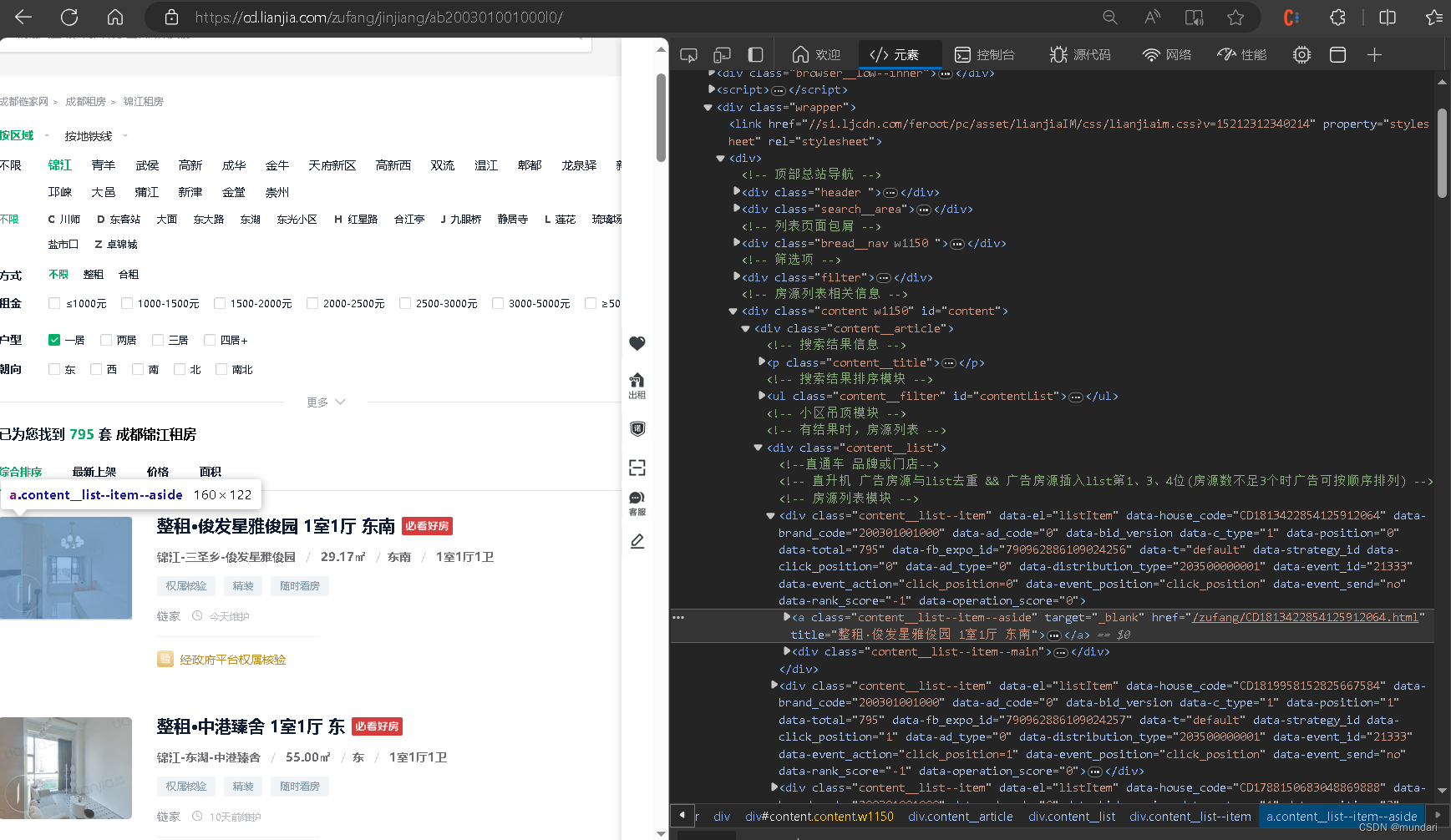
发现href中的url,这是我们第二次请求所需要的
import parsel
import random
import requests
import pprint
import csv
import re
from bs4 import BeautifulSoup
import time
user_agents =[
'Mozilla/5.0 (Windows; U; Windows NT 5.1; it; rv:1.8.1.11) Gecko/20071127 Firefox/2.0.0.11',
'Opera/9.25 (Windows NT 5.1; U; en)',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)',
'Mozilla/5.0 (compatible; Konqueror/3.5; Linux) KHTML/3.5.5 (like Gecko) (Kubuntu)',
'Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.8.0.12) Gecko/20070731 Ubuntu/dapper-security Firefox/1.5.0.12',
'Lynx/2.8.5rel.1 libwww-FM/2.14 SSL-MM/1.4.1 GNUTLS/1.2.9',
'Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:10.0) Gecko/20100101 Firefox/10.0',
]
agent = random.choice(user_agents)
headers = {
'User-Agent': agent
}
response = requests.get(url=url,headers=headers)
#parsel模块无法直接对字符串数据解析提取
selector = parsel.Selector(response.text)
#css选择器,根据标签属性内容提取对应数据
href = selector.css('#content > div.content__article > div.content__list > div > a::attr(href)').getall()
接下来查看房屋详情页,我想要的是标题、月租价格、以及”房屋信息“中的面积、朝向、楼层、电梯、车位、用水、用电、燃气、采暖这些信息。
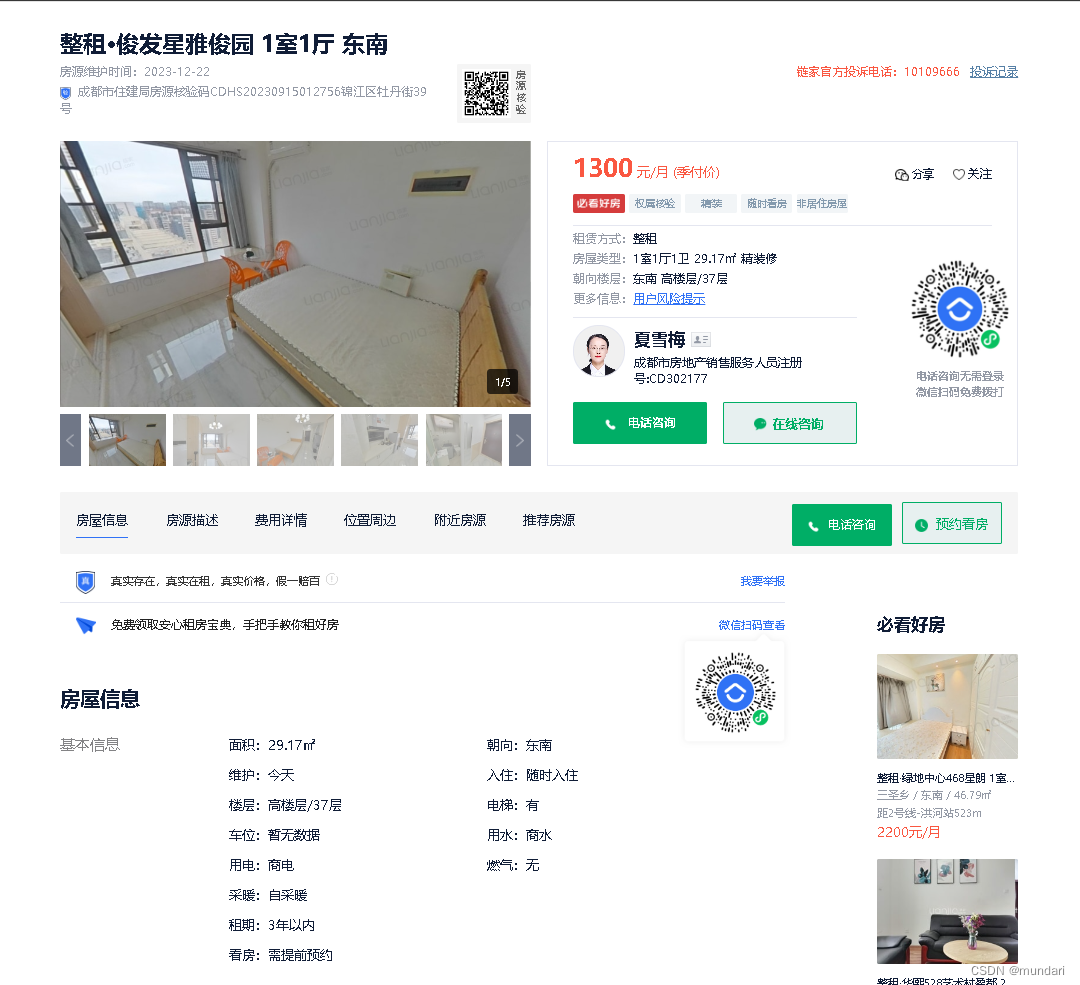
for index in href:
link = "https://cd.lianjia.com"+index
print(link)
house_data = requests.get(url=link,headers=headers).text
selector_house = parsel.Selector(house_data)
title = selector_house.css('body > div.wrapper > div > div.content.clear.w1150 > div.top_content > div.top_left > p::text').get().replace(" ","").replace("\n","")
price = selector_house.css('#aside > div.content__aside--title > span::text').get()
house_info = selector_house.css('#info > ul > li::text').getall()
area = house_info[1][3:]
direction = house_info[2][3:]
floor = house_info[7][3:]
lift = house_info[8][3:]
car = house_info[10][3:]
water = house_info[11][3:]
electricity = house_info[13][3:]
gas = house_info[14][3:]
heating = house_info[16][3:]
info = {
'详情页': link,
'标题': title,
'月租': price,
'面积': area,
'朝向': direction,
'楼层': floor,
'电梯': lift,
'车位': car,
'用水': water,
'用电': electricity,
'燃气': gas,
'暖气': heating
}
# pprint.pprint(info)
print(info)保存至本地:
f = open('house_data.csv',mode='a',encoding='utf-8',newline='')
csv_writer = csv.DictWriter(f, fieldnames=[
'标题',
'月租',
'面积',
'朝向',
'楼层',
'电梯',
'车位',
'用水',
'用电',
'燃气',
'暖气',
'详情页'
])
# 写入表头
csv_writer.writeheader()记得import csv,以及在info字典后面加上:
csv_writer.writerow(info)于是变成了这样:
info = {
'详情页': link,
'标题': title,
'月租': price,
'面积': area,
'朝向': direction,
'楼层': floor,
'电梯': lift,
'车位': car,
'用水': water,
'用电': electricity,
'燃气': gas,
'暖气': heating
}
# pprint.pprint(info)
csv_writer.writerow(info)
print(info)获取多页:(需要通过观察和尝试,此处不赘述)
学习跳转链接:在万维网爬虫中进行翻页爬取的三种常用方案-CSDN博客
for i in range(1,27):
url=f'https://cd.lianjia.com/zufang/jinjiang/ab200301001000pg{i}l0/'可以跑起来了,但是出现了报错:

打印出错的url地址,发现这个页面的结构和其他的不同

于是把它也加上
title = selector_house.css('body > div.wrapper > div > div.content.clear.w1150 > div.top_content > div.top_left > p::text'
or 'body > div.wrapper > div:nth-child(2) > div.content.clear.w1150 > p::text').get().replace(" ","").replace("\n","")但是仍然会报错,我就把replace删了,最后把七百多条全爬完了,在excel表格里手工修改了一下格式:
















 9679
9679

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









