







规则引导的知识图谱联合嵌入方法
本文来自《计算机研究与发展》 ,作者姚思雨等
摘 要 近年来,大量研究工作致力于知识图谱的嵌入学习,旨在将知识图谱中的实体与关系映射到低维连续的向量空间中.且所学习到的嵌入表示已被成功用于缓解大规模知识图谱的计算效率低下问题.然而,大多数现有嵌入学习模型仅考虑知识图谱的结构信息.知识图谱中还包含有丰富的上下文信息和文本信息,它们也可被用于学习更准确的嵌入表示.针对这一问题,提出了一种规则引导的知识图谱联合嵌入学习模型,基于图卷积网络,将上下文信息与文本信息融合到实体与关系的嵌入表示中.特别是针对上下文信息的卷积编码,通过计算单条上下文信息的置信度与关联度来度量其重要程度.对于置信度,定义了一个简单有效的规则并依据该规则进行计算.对于关联度,提出了一种基于文本表示的计算方法.最后,在2个基准数据集上进行的实验结果证明了模型的有效性.
关键词 知识图谱;表示学习;图卷积网络;上下文信息;文本信息
近年来,由于具有表达能力强、歧义性低、模式统一、且支持推理等优点,知识图谱已被广泛用于组织和发布各领域的结构化数据.通常,知识图谱由实体、实体所具有的属性以及实体间的关系所组成.例如,其中可能包含有实体中国、关系首都以及实体属性“China”. 如图1所示,知识图谱的基础构成则是描述2个实体之间的关系或实体及其属性之间关系的三元组,如(中国,首都,北京)、(中国,英语标签,“China”).
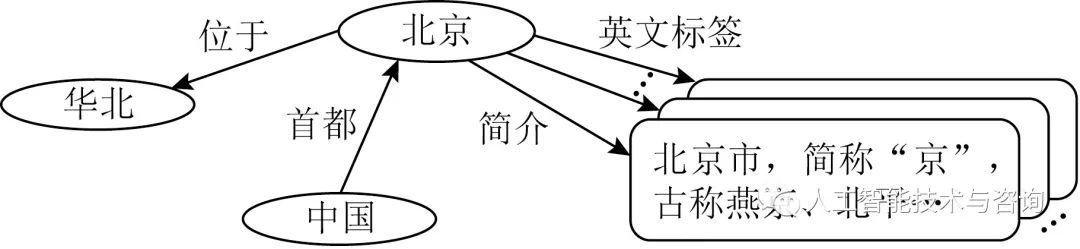
Fig. 1 Several triples which contain the entity Beijing and the related literals
图1 包含实体“北京”的若干三元组及文本信息
目前,知识图谱已被广泛应用在智能问答[1]、推荐系统[2]和信息检索[3]等任务中,其突出表现在学术与工业界均获得了广泛关注[4].但是,受益于知识图谱所包含丰富信息的同时,其庞大的规模与数据稀疏性问题也给知识图谱的应用带来了挑战.例如,Freebase[5], Yago[6]和Dbpedia[7]等开放领域知识图谱中通常包含有数百万个实体,以及上亿条描述实体关系的三元组.将子图匹配等传统图算法应用在这些大规模知识图谱上往往存在计算低效性问题.为此,研究人员提出了知识图谱嵌入学习模型(knowledge graph embedding learning model),将知识图谱映射到低维、连续的向量空间中,学习实体与关系的嵌入表示[8].
通过设计特定的表示学习机制,知识图谱的结构和语义等信息可被编码在所学习到的嵌入表示中.一方面,原本需要对大规模知识图谱进行频繁访问的操作,例如结构化查询构建(structured query construction)[9]、逻辑查询执行(logical query pro-cessing)[10]和查询放缩(query relaxation)[11],均可在所学习到的嵌入表示空间中通过数值计算完成,极大地提高了效率.另一方面,知识图谱的嵌入学习提供了一种抽取并高效表示知识图谱特征信息的方法,类似于自然语言处理领域中被广泛应用的词嵌入(word embedding),知识图谱的嵌入表示也为基于知识图谱的深度学习工作提供了极大的便利.
现有知识图谱嵌入学习模型大多仅关注知识图谱中以三元组表示的结构信息.例如,Bordes等人提出了基于翻译机制(translation mechanism)的TransE模型[12],其目标任务为链接预测(link prediction)与三元组分类(triple classification),概括而言就是判断知识图谱中给定的2个实体之间是否存在某个关系.因此TransE模型仅关注所学习到的嵌入表示对单条三元组结构信息的编码,其在嵌入学习过程中将知识图谱简化为互不相关的三元组的有限集合.因此,TransE及其后续改进模型[13-16]对知识图谱中上下文信息的编码能力非常弱,很难应用于语义相关的任务.针对这一问题,相继有一些基于上下文信息的嵌入表示模型被提出,如GAKE[17], RDF2Vec[18].但是它们仍然仅关注知识图谱中由子图、路径等结构所表示的上下文信息.例如,在学习图1中实体北京的嵌入表示时,上述方法仅关注(中国,首都,北京)与(北京,位于,华北)等描述实体间关系的三元组,而忽略了北京的简介、英文标签等文本信息.显然,文本信息的缺失限制了所学到嵌入表示对语义信息的表达.
为解决这一问题,本文提出了一种规则引导的知识图谱联合嵌入学习模型.受Vashishth等人[19]所提出的图卷积网络启发,模型首先通过多关系型图卷积将实体在知识图谱中的上下文信息编码到实体的嵌入表示中.与Vashishth等人的工作所不同的是,本文认为实体的多条上下文信息应该具有不同的重要程度,并且某条上下文信息的重要程度取决于2个因素:该条上下文信息的置信度,以及其相对于实体的关联度.为此,本文提出了一条简单有效的规则引导上下文信息置信度的计算,并基于知识图谱中的文本信息表示提出了实体与其上下文信息之间关联度的计算方法.最后,模型将图卷积网络所编码的嵌入表示与文本信息的向量表示整合,以链接预测任务的结果作为训练目标,学习知识图谱中实体与关系的嵌入表示.
本文贡献主要体现在3个方面:
1) 基于图卷积网络,创新地提出了一种联合考虑知识图谱中上下文信息与文本信息,由规则引导的嵌入表示学习模型.
2) 针对上下文信息在图卷积中的重要程度,提出了应用规则以及知识图谱中文本信息来计算单条上下文信息置信度与关联度的新方法.
3) 在基准数据集上进行了充分的实验,并与相关的知识图谱嵌入学习方法进行了对比,实验结果验证了本文模型的有效性.
1 相关工作
本节对与本文工作较相关的知识图谱嵌入学习模型进行介绍,由于本文所提出的模型是基于图神经网络的,因此分别介绍基于图神经网络的知识图谱嵌入学习模型和其他非图神经网络的嵌入学习模型.
1.1 基于图神经网络的模型
基于图神经网络的模型主要包括R-GCN[20], W-GCN[21], CompGCN[19]等.该类模型通常将图卷积网络作为编码器,对图结构数据进行编码,并结合对应的解码器进行知识图谱上的链接预测、节点分类等任务.在R-GCN中,每层网络中节点与关系的特征利用权重矩阵进行计算,并通过领域聚合的方式传递至后续网络层.具体而言,R-GCN利用基分解和块对角分解构造特定关系的权重矩阵,以处理不同类型的邻居关系,将其与邻居节点信息进行融合,并传递到目标实体上进行更新.W-GCN在图卷积网络聚合过程中为每个权重矩阵分配可学习的权重参数,使模型获得更优的实体嵌入表示.CompGCN则提出了针对中心节点的领域信息聚合方法,在理论上使用多种“实体-关系”组合算法对当前主流的基于多关系的图卷积网络模型进行了概括.
1.2 非图神经网络的模型
非图神经网络的嵌入学习模型类别较多,主要包括基于翻译机制的模型,如TransE[12]及其后续改进模型,包括TransH[13],TransR[14],TransD[15],TransAH[16],基于上下文信息的模型,如GAKE[17],RDF2Vec[18],基于张量分解的模型,如ComplEx[22],RESCAL[23].
其中,基于翻译机制的模型应用较为广泛.该类模型通常仅关注知识图谱的结构信息,将实体之间的关系表示为嵌入向量空间中的某种翻译操作(translation operation).以TransE为例,其将知识图谱中的实体与关系都表示在同一个低维欧几里得空间中,以向量表示一个实体或关系.具体而言,对于知识图谱中的一条三元组(h,r,t),TransE 将其中的关系r看作在欧几里得空间中从头实体h到尾实体t的平移操作,即其期望头实体所对应的向量h经过关系所对应的向量r的平移操作后可以非常逼近尾实体所对应的向量t,即h+r≈t.
TransE的翻译机制较为简单,因此可以高效地应用于大规模知识图谱,但同时又限制了其模型的表达能力,使其难以处理一对多、多对一以及多对多类型的复杂关系[14].为解决这一问题,TransE之后相继有一些翻译机制更加复杂的模型被提出.例如,TransH[15]相对于所给定三元组中关系的超平面空间设计翻译机制,TransR[16]则针对知识图谱中的每一个关系额外学习一个矩阵,借助该矩阵将头、尾实体通过线性变换映射到相应的关系向量空间中,然后再计算其翻译机制的损失值.
2 联合嵌入表示学习
本节首先对知识图谱嵌入学习问题进行形式化定义,介绍相关概念的符号表示,然后详细介绍所提出的规则引导的联合嵌入学习模型.
2.1 问题定义
本文将知识图谱表示为
![]()
其中
![]()
分别代表知识图谱中的实体与关系集合.对于某个三元组
![]()
其中头尾实体均属于实体集合,即
![]() <
<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









