










🌳🌳🌳前言:本文总结了介绍了词向量的两种表示方式:one-hot表示和分布式表示
目录
🌈在自然语言处理任务中,首先要考虑字、词如何在计算机中表示,通常有两种表示方式:
one-hot表示和分布式表示。
🌸one-hot表示(离散式表示)
- one-hot表示就是把每个词表示为一个长向量。
- 这个向量的维度是词表的大小。
- 向量中只有一个维度的值为,其余维度的值为0。
🌰举个例子:
苹果 [0,0,0,1,0,0,0,0,···] 。
🌟 one-hot相当于给每个词分配一个id,这样就表示不能展示词与词之间的关系,且特征空间非常大。
🌸分布式表示
-
word embedding指的是将词转化成一种分布式表示,又称词向量。
- 分布式表示将词表示成一个定长的连续的稠密向量。
🌵分布式表示的优点:
- (1)词之间存在相似关系:使词之间存在“距离”概念,这对很多自然语言处理的任务非常有帮助。
- (2)包含更多信息:词向量能够包含更多信息,并且每一维都有特定的含义。在采用one-hot特征时,可以对特征向量进行删减,词向量则不能
🌵分布式表示-word2vec
🌈在自然语言处理领域,使用上下文描述一个词语的语义是一个常见且有效的做法。2013年,Mikolov提出的经典word2vec算法就是通过上下文来学习语义信息。
word2vec包含两个经典模型:CBOW(Continuous Bag-of-Words)和Skip-gram。
- CBOW:通过上下文的词向量推理中心词。
- Skip-gram:根据中心词推理上下文。
🌰举个例子——CBOW
🌸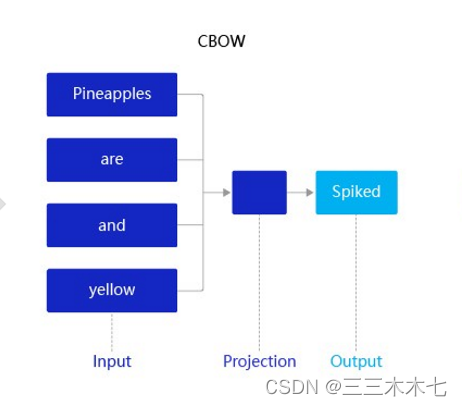
假设有一个句子“Pineapples are spiked and yellow”,它在CBOW中的推理如下:
1.先在句子中选定一个中心词,并把其他词作文这个中心词的上下文。如上图CBOW表示,把把“spiked”作为中心词,把“Pineapples、are、and、yellow”作为中心词的上下文。
2.在学习过程中,使用上下文的词向量推理中心词,这样中心词的语义就被传递到上下文的词向量中,如“spiked → pineapple”,从而达到学习语义信息的目的。
🌰举个例子——Skip-gram
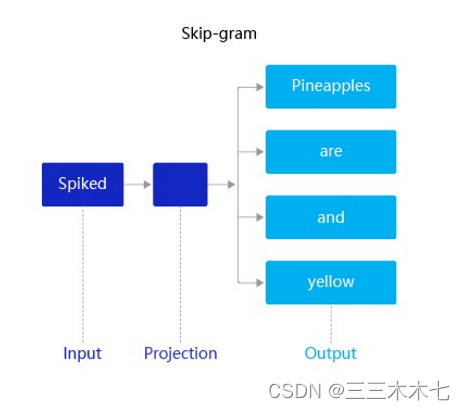
假设有一个句子“Pineapples are spiked and yellow”,它在Skip-gram中的推理如下:
1.在Skip-gram中,同样先选定一个中心词,并把其他词作为这个中心词的上下文。如上图Skip-gram所示,把“spiked”作为中心词,把“Pineapples、are、and、yellow”作为中心词的上下文。
2.不同的是,在学习过程中,使用中心词的词向量去推理上下文,这样上下文定义的语义被传入中心词的表示中,如“pineapple → spiked”, 从而达到学习语义信息的目的。
本文摘自百度飞桨的nlp课程,飞桨AI Studio - 人工智能学习与实训社区 (baidu.com)。
💬一起加油!
















 1131
1131











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











