







1.基本概念
支持向量机(Support Vector Machine,SVM)是一种有监督学习方法,主要用于分类和回归分析。它的基本思想是在特征空间中找到一个超平面,能够将不同类别的样本分开,并且使得离这个超平面最近的样本点到该平面的距离(即间隔)最大化。支持向量机在处理高维数据和非线性问题时表现良好。
以下是支持向量机的一些关键概念:
-
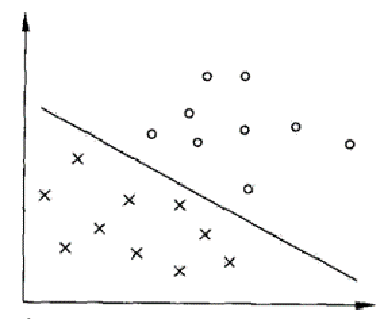
超平面(Hyperplane): 在一个 n 维空间中,一个 n-1 维的子空间就是一个超平面。在二维空间中,超平面就是一条直线;在三维空间中,超平面是一个平面。在支持向量机中,我们试图找到一个超平面,使得样本点能够被分成两个类别。
-
支持向量(Support Vectors): 这些是离超平面最近的数据点,它们对于定义超平面并确定分类决策边界起着关键作用。支持向量机的训练过程中,只有支持向量的位置才会影响最终模型。
-
间隔(Margin): 间隔是指超平面与支持向量之间的距离。支持向量机的目标是最大化这个间隔,从而提高模型的泛化能力。
-
核函数(Kernel Function): 在处理非线性问题时,可以使用核函数将数据映射到更高维的空间中,使其在高维空间中线性可分。常用的核函数包括线性核、多项式核和径向基函数(RBF)核。
-
C 参数: C 是一个正则化参数,它控制了对误分类样本的惩罚程度。较小的 C 值会导致更大的间隔,但可能允许一些样本被错误分类;较大的 C 值则会强调对误分类样本的惩罚,可能导致更复杂的决策边界。

【补充】:
面对近似线性可分的情况,需要适当放宽这个间隔,引入软间隔和松弛因子。而面对更复杂的低维线性不可分的情况,通过使用核函数将数据点映射到高维,进行寻找超平面进行划分。
🌍支持向量机(Support Vector Machine,SVM)是一种有监督学习方法,它的基本思想是在特征空间中找到一个超平面,能够将不同类别的样本分开,并且使得离这个超平面最近的样本点到该平面的距离(即间隔)最大化。
2.SVM的推导(看西瓜书)
支持向量机的推导涉及到优化问题和拉格朗日对偶性,具体看西瓜书。
1.间隔和支持向量机
我们的目标是使间隔最大化。

【补充】
在支持向量机的图示中,通常X轴和Y轴表示的是特征空间的两个特征,这两个特征是用来描述数据样本的属性的。
-
支持向量(Support Vectors): 这些是离超平面最近的数据点,它们对于定义超平面并确定分类决策边界起着关键作用。支持向量机的训练过程中,只有支持向量的位置才会影响最终模型。
-
间隔(Margin): 间隔是指超平面与支持向量之间的距离。支持向量机的目标是最大化这个间隔,从而提高模型的泛化能力。
2.SMO
SMO(Sequential Minimal Optimization)是用于训练支持向量机(SVM)的一种算法。
由John C. Platt于1998年提出,SMO旨在解决支持向量机的二次规划问题。它通过将大问题拆分为一系列小规模的子问题,并针对每个子问题进行优化,从而加速了支持向量机的训练过程。
SMO的基本思想是先固定之外的所有参数,然后求
上的极值。
由于存在约束,若固定之外的其他变量,则
可由其他变量导出。
所以,SMO每次选择两个变量和
,并固定其他参数,然后不断执行如下两步直至收敛:
第一步:选取一对需要更新的变量
和
第二步:固定
以外的参数,求解对偶问题获得更新后的
3.核函数
在现实任务中,原始样本空间内也许并不存在一个能正确划分两类样本的超平面。
对这样的问题,可将样本从原始空间映射到一个更高维的特征空间,使得样本在这个特征空间内线性可分。
常见的核函数

注意:若核函数选择不合适,则意味着将样本映射到了一个不合适的特征空间,很可能导致性能不佳。
4.软间隔与正则化
前面的做法是一直假设存在一个超平面能将不同类的样本完全划分开,为了解决线性不可分的情况,使用了核函数进行特征空间的变换。
然而,即使我们进行特征空间变换后把样本完全的分开,也有可能这个“线性可分”是因为噪声点而过拟合造成的。(很多情况下,训练数据中有一些噪声点,把这些噪声点去除后,剩下的大部分样本组成的特征空间是线性可分的。)
缓解该问题的一个办法是允许支持向量机在一些样本上出错,因此引入了“软间隔”。
我们可以对SVM适当的放松条件,不再要求所有的点都分对,而是对不能满足约束的样本进行一些“惩罚”,为此引入惩罚因子,并写出软间隔SVM的形式如下:

C为惩罚参数,较大的 C 值则会强调对误分类样本的惩罚,可能导致更复杂的决策边界。小的 C 值会导致更大的间隔,但可能允许一些样本被错误分类。
C越大,即对分错样本的惩罚程度越大,因此在训练样本中准确率越高,但是泛化能力降低,也就是对测试数据的分类准确率降低。 相反,减小C的话,容许训练样本中有一些误分类错误样本,泛化能力强。 对于训练样本带有噪声的情况,一般采用后者(较小的C),把训练样本集中错误分类的样本作为噪声。
C较大要求尽可能的分对所有的点,C较小说明对错误的容忍程度较大,间隔可以较宽。
(小的C可能会欠拟合,大的C可能会过拟合。因此要小心的选择参数。 )
3.总结
支持向量机(Support Vector Machine,SVM)是一种有监督学习方法,主要用于分类和回归分析。它的基本思想是在特征空间中找到一个超平面,能够将不同类别的样本分开,并且使得离这个超平面最近的样本点到该平面的距离(即间隔)最大化。支持向量机在处理高维数据和非线性问题时表现良好。
优点:
适用于高维空间: SVM在高维空间中表现出色,特别适用于处理具有许多特征的数据集,如文本分类或图像识别。
泛化能力强: SVM通过最大化间隔的方式,有助于提高模型对新样本的泛化能力,降低过拟合的风险。
对小样本数据效果好: 即使在样本量相对较小的情况下,SVM也能表现良好,这是因为它主要关注支持向量。
核函数的灵活性: 使用核函数可以处理非线性问题,将数据映射到更高维的空间中,使其在高维空间中变得线性可分。
对异常值的鲁棒性: SVM对于一些噪声和异常值的影响相对较小,支持向量主要受到那些距离超平面最近的样本的影响。
缺点:
计算开销较大: 对于大规模的数据集,SVM的训练和预测的计算开销较大,尤其在高维空间中。
参数调优复杂: SVM有一些参数需要调优,例如C参数和核函数的选择,这可能需要通过交叉验证等方法来找到最优的参数设置。
不适用于非线性大数据集: 在非线性大数据集上,训练和预测的速度可能会受到影响,且可能需要更长的时间。
不适用于非平衡数据集: 对于类别不平衡的数据集,SVM可能会偏向于对多数类别进行优化,而忽略少数类别。
不直接提供概率估计: SVM本身不直接提供类别的概率估计,而是通过一些启发式方法进行近似,这在某些应用中可能不够理想。(逻辑回归直接输出概率)
1.为什么SVM 支持向量机(SVM)在高维空间中表现出色,特别适用于处理具有许多特征的数据集呢?
最大间隔分隔超平面: SVM的目标是找到一个最大间隔的分隔超平面,使得不同类别的样本在特征空间中的投影距离最远。在高维空间中,样本点相对于样本数量的维度较远,更容易找到一个超平面使得不同类别之间的距离最大化。
高维度下线性可分性的增加: 随着特征维度的增加,数据在高维空间中更有可能变得线性可分。这是由于在高维空间中,不同类别的样本更容易在某个维度上有较大的差异,使得找到一个超平面来分隔它们变得更为可能。
避免维度灾难: 在高维空间中,样本点之间的距离可能更加有意义。在低维空间中,由于维度较少,样本点之间的距离可能较小,这会导致模型更容易过拟合。而在高维空间中,样本点之间的距离相对较大,有助于避免维度灾难。
支持向量的稀疏性: 在高维空间中,支持向量(决策边界附近的样本点)的数量相对较少,因为只有这些样本点对模型的构建起关键作用。这种稀疏性使得SVM在高维空间中更加高效。
核技巧: SVM使用核函数将样本映射到高维空间,从而在低维空间中非线性可分的问题在高维空间中变得线性可分。这种核技巧在处理文本分类、图像识别等高维特征数据时尤为有效。
4.SVM的过程
支持向量机的过程可以分为训练和预测两个阶段。
1. 数据准备:
在训练和预测阶段,需要一个已标记的数据集,其中包含输入特征和相应的类别标签。
2. 训练阶段:
2.1 特征映射(如果需要):
对于非线性问题,可以使用核函数将数据映射到更高维的空间。这可以通过内积运算来完成,而无需实际计算新空间中的坐标。
2.2 寻找超平面:
SVM的目标是找到一个能够最大化间隔(支持向量到超平面的距离)的超平面,以分隔不同类别的样本。这通常是一个凸优化问题。常见的优化方法包括序列最小优化(Sequential Minimal Optimization,SMO)等。
2.3 确定支持向量:
找到超平面后,支持向量就是离该超平面最近的训练样本点。它们对于定义超平面并确定分类决策边界起着关键作用。
2.4 决策函数:
根据找到的超平面和支持向量,建立一个决策函数。对于新的未标记样本,通过这个决策函数来预测其类别。
3. 预测阶段:
3.1 特征映射(如果需要):
对于测试数据,如果在训练阶段使用了特征映射,则需要将测试数据映射到相同的高维空间。
3.2 应用决策函数:
使用训练阶段得到的决策函数,根据测试样本的特征进行分类预测。
4. 参数调优:
支持向量机有一些参数需要调优,例如核函数的选择、C参数的设定等。这可以通过交叉验证等方法来完成,以提高模型的性能和泛化能力。
5.SVM的实践
# 导入必要的库
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score, classification_report
# 加载数据集(以鸢尾花数据集为例)
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 特征缩放(可选,但在SVM中常常需要)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 初始化SVM模型
svm_model = SVC(kernel='linear', C=1.0)
# 训练模型
svm_model.fit(X_train_scaled, y_train)
# 预测
y_pred = svm_model.predict(X_test_scaled)
# 评估模型性能
accuracy = accuracy_score(y_test, y_pred)
report = classification_report(y_test, y_pred)
print(f"Accuracy: {accuracy}")
print(f"Classification Report:\n{report}") 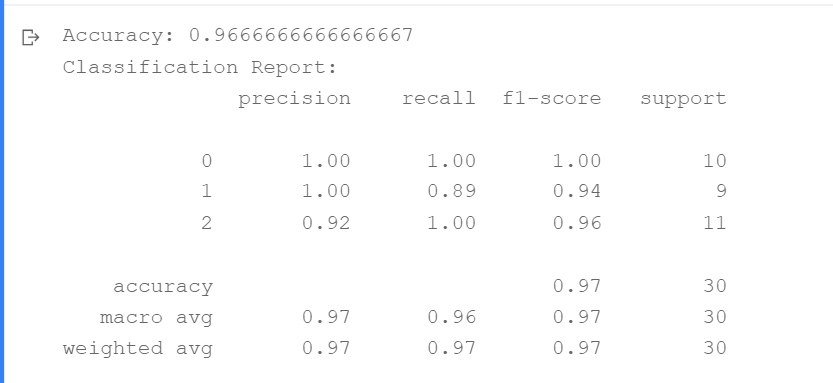















 6229
6229











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











