






 文章讲述了在第十八届挑战杯竞赛的华为云赛道中,团队经历线上跑分与答辩的复赛阶段,涉及模型部署、精度提升、疲劳检测逻辑优化、端云协同方案等。通过yolov7模型改进和策略调整,最终线上成绩达到0.846。
文章讲述了在第十八届挑战杯竞赛的华为云赛道中,团队经历线上跑分与答辩的复赛阶段,涉及模型部署、精度提升、疲劳检测逻辑优化、端云协同方案等。通过yolov7模型改进和策略调整,最终线上成绩达到0.846。
第十八届“挑战杯”全国大学生课外学术科技作品竞赛“揭榜挂帅”专项赛-华为云赛道
复赛项目总结:
首先复赛分为两个板块,线上跑分和答辩。线上板块部分较初赛难度和精度均有一个大的跨度,需要我们输出测试集视频里N段疲劳片段(N>=0)和疲劳对应的分类,片段定位需要精确到0.5秒内并根据整体的检测速度来评判分数,每天仅有一次提交代码刷新分数的的机会。答辩的时间给出了十天的时间,从7号到16号,其中11号需要提交方案的整体ppt以及实现的功能录屏。
线上跑分
线上跑分是将模型打包生成ModelArts在线服务,其中我们遇到的第一个问题就是无法部署,非常的焦急,精度还没有优化,但是本地测试已经可以实现片段的截取,一直卡在无法部署的困境中,后来只能通过手动部署的方式,我对应着代码的输出和华为云API文档查看了部署文件,修改了config.json文件
初赛的json

修改后的json

主要修改的是respons部分,输出是是四层嵌套,{‘resul’t:{‘duration’:,’drowsy’:[{‘category’:,periods:[,]},{},…]}},逐层解析。后面想更改requset想传入视频流或字节流(图像数组),但是华为云的modelarts在线服务好像不支持这个功能,模型成功配置后,第一次出分0.26分,


也算是对API调试的有了成功的经验。
接下来就是判断疲劳片段的逻辑代码了,初赛的逻辑是当判断出疲劳时即立刻break while 拼接此时的用时返回结果了,只存在真假集。复赛这个增加了难度,视频里可能有多段或者没有疲劳片段,既有真假集也包含如何定位还有如何持续记录。所以起初的设计逻辑是修改计数计时方式,初赛使用的是单帧累加计算,当每帧的判断结果在最后归类累加超过frame_3s的次数即结束。将逻辑改为增加一个行为帧列表,列表有很好的顺序性质可以定位,且列表内元素很直观,可以轻松的看到连续的行为。但是伴随着视频画面的每一帧的增加,列表的长度会不受控制,所以想出增一帧同时减一帧,这样的话列表长度和值就可以很直观的表现出来,当持续出现某种行为的时候,标记列表第二帧为起始时间,此时记录时长,一旦超过了3秒,那么写drowsy:[{category:,periods:[,]}]这个列表里,这个列表里包含着字典组,那么也就是说可以通过字典写入的方式写入对应的疲劳行为和开始时间,当不满足列表内元素相同的情况时记录结束帧更新结束时间。此方法在开始时需要规避检测出正常状态,复赛不允许检测出非疲劳/分神的行为。所以需要再加入一个条件即可。
逻辑代码:
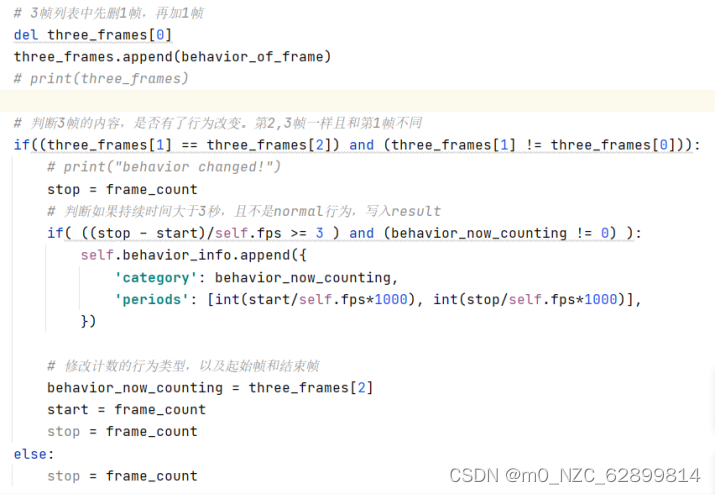
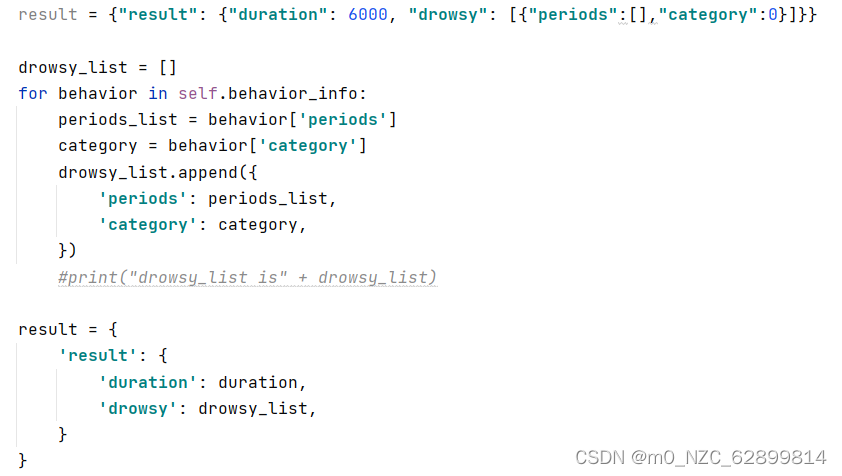
这里是一个很经典的方法,很好的利用了字典,列表,还需要优化if/else的逻辑,在开始帧和结束帧那里在如何更新开始时间纠结了很久。后面复赛群里有个研究生问老师顺序的问题,我的回答还被引用了
通过这种方式,不仅可以快速的得到片段,而且可以直观的看到过程。之前我是写了一个读取帧函数的方式,就是先记录行为的开始帧数和结束帧数,把行为存到列表里,最后再合并行为,因为是执行完整个视频读取才能去拼接,这样的单线程操作实在是慢了,而且过程也不直观。
模型的基本框架已经搭建好了,剩下的就是提高精度了
精度要控制在0.5秒的误差,也就是说fps=24,只能容许前后12帧的误判,也就是不能提前/漏检6帧在开始和结束的时候。这样的要求对于模型的精度的考验是巨大的,同时对判断逻辑不能有一点误差(我们后来又修正了模型在初始帧记录的时候是漏掉一帧的,需要额外加上)。
首先我们在初赛结束后训练了一个6分类的yolov7检测疲劳模型,一言难尽,在模型训练上(数据集,GPU)有不少值得反思和记录的点,数据集是官方给出的测试视频集与示例视频裁帧得到的。最开始对模型标注的时候比较随意,例如对手机的标注,标的范围太大了,导致后面其余的5个分类准确度都在0.9以上,只有手机是0.84,后面又得重新筛选出收集数据集,然后重新标注。其余几个分类都是或多或少的遇到了这样的问题。当然筛选出手机的xml文件可以写一个python脚本,只需要遍历读取name标签下的标签名,然后补充些os操作。但是标注和确认的整个过程中非常难熬,这样大的数据集,哪怕是分三组任务,都是巨大的,而且至少是经过了十次以上的大范围修改,动辄就是几千的工作量。
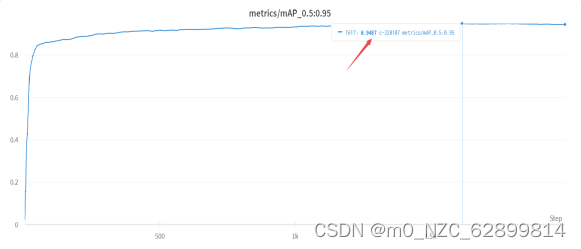
后来我们制作出几乎非常完美的数据集,训练了2000多轮,map@0.5值0.948,可以说精度很高了。接下来再说硬件方面,18000张图片,训练2000轮,这样的训练任务恐怕是靠电脑的CPU是没办法完成了,所以我们使用云端的算力,华为云服务的p100,V100,和RTX4000,都用过价格从8/h,28/h都有综合考虑最终选用了RTX4000,因为可以按周/月租赁较为划算。而且可以直接通过xshell远程访问服务器,华为云的训练其实也可以远程也可以在notebook里,但是计费方式不太合理。
 | |
 |
模型精度上去了,但是随之而来的就是过拟合。尤其是张嘴打哈欠的行为分类。只要嘴巴微微张开,那么就会被误判,太灵敏了,没办法,模型的conf只能调整整体的,只能回去再人工核查删掉嘴巴小的图片,然后再继续训练。这个过程想象不到的冗余,左顾右盼的角度,手机的手持位置,手指关节,闭眼是只检测闭眼还是整个面部,有些眼镜框挡住了眼睛线条标注还是丢弃,哈哈哈想起来就感觉当时有多心累
如此复杂的各种操作之下,我们的成绩也是由0.268涨到了0.756,可以说是一次很成功的磨砺。

接下来就是如何提高速度。首先提高速度的最直观办法就是进行隔帧检验,它和实时视频不同,可以跳帧检测,实时视频的话只能说等待隔帧。所以说,假如每3帧取一次,那么整体速度就相当于提升了3倍,但是这个数目是不能乱取的,这个虽然越高越块,但是精准度一下子就会跳下来,因为这是隔帧检测,片段的精度要控制在0.5秒内,前文也提到了,错过6帧就很危险了,隔得太多根本没办法确定到具体的位置,没有什么好的方案,只能一次一次的调整参数,最终本地数据集检测验证下达到最大时提交成绩,反复尝试,成绩提升到了0.82。还有什么办法可以提高速度,单帧检验的速度提升上去就可以了,经过反复研究,我们发现有两种办法可以加速单帧检验,一个是降低画质,一个是降低yolov7神经网络的深度,剪枝压缩。降低画质这个办法是修改imgsz参数,默认给的是640*640,我们研究发现,只有取32的倍数才可以成功,后来从最小的32到640之间所有的参数都试了一遍,结果发现,320*320的分数最高在0.844,160*160的性价比最好0.8369(后期实时检测的出来结论)。
对于模型的优化是在准备答辩期间想出来的,可惜了,没有应用到跑分上,就跟初赛没有把yolov7分类全用上,而是选用了各种的面部关键点方法浪费了大量的精力。如果说复赛还是要关键点计算的话,时间可能会更久。
“yolov7小模型要比大模型的速度更快,更适用于资源有限的嵌入式设备或需要实时性能的应用场景。于是我们尝试将大模型的参数进行改动,将原本的大模型深度由1改为0.33,宽度由1改为0.5。”
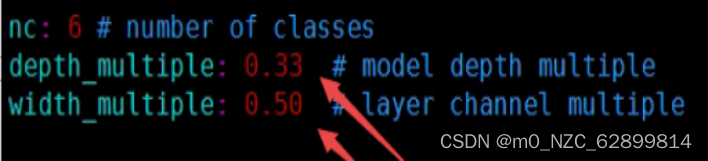


很直观的看到,本来一帧的检测是0.2秒,现在优化模型之后只用了0.06,唉,如此高效且准确的模型,如果放到我们复赛的打分上肯定能突破0.9,成为第一个夺魁的人。
没想到减小了训练的深度和宽度,map@0.5值也高达0.926。
最终复赛的线上成绩是0.846,也算是较好的成绩。
接下来就是准备端云协同方案了,这个过程其实和线上提交分数同步进行的,中间遇到了很多困难,也学到了很多知识。
首先老师给出了明确的方向,这样我们的进度才及时有效的推进:windows下实现端云协同,开发板上实现协同,开发板基于modelbox框架实现协同。大的方向下又包含了windows下使用python实现协同,开发板使用python协同,windows下使用C++实现协同,开发板使用C++协同。逐步推进计划,最终仅仅在两周不到的时间实现了windows和开发板下的python全方案流程实现。跟着老师做项目的最棒的好处就是能学到老师处理问题的经验方法,非常非常的难得,所以每次和老师开会讨论我都会十分珍惜这些机会,所以如果有学弟学妹们看到这里,我希望大家能在大学本科期间多多跟老师学习,虚心请教,俯身侧耳以请,我相信你一定会收获满满!
windows全方案包括:云端测试模型部署,端侧设备的检测可视化,端云协同的模拟,端侧与obs的链接,端侧采集图像生成xml文件的数据集,云测设备复检端侧结果。
开发板上除了实现windows下的全部方案还包括了应用modelbox框架,但是由于时间原因,导致modelbox只成功实现了初步的案例调试——视频文本插入显示和口罩检测。在口罩检测的时候首先使用的是windows下的modelbox框架,可以直接访问设备的摄像头,但是基于ubuntu的开发板接入摄像头由于没有显示器,无法显示视频,我们使用了FFmpeg 推流+ EasyDarwin转发+ vlc播放实现 RTSP 直播,参考文章
https://blog.csdn.net/chy555chy/article/details/107354427
通过网络的方式将视频流再通过VLC显示软件显示,这个方式存在网络延迟。所以后期没有采用这种视频流的方式,而是使用单帧检验。

全方案的代码和demo我已经共享至GitHub上,大家如果有相似的项目欢迎参考讨论。
答辩部分:
可以说是台上一分钟,台下十年功。答辩仅仅预留了五分钟的陈述与demo演示和两分钟的提问回答时间,但是为了这七分钟我和队友可以说练习了不止一百遍。答辩里面也有很多说道的地方,ppt的布局风格,讲解的时间控制,demo演示与备用方案,提问的所有问题准备。
首先是ppt的风格布局上:
这张是我最开始做的,可以说风格简约很适合日常的工作,but对于这种参赛,老师说这是绝对不允许的,因为需要一种震撼感。
于是我们对风格上进行了大的改动:

可以说,完全是视觉上的冲击是非常明显的。
接下来是讲解时间的把握,无他,唯嘴熟尔。从初稿的1000字,不断浓缩,言简意赅的浓缩到500字。值得注意的是,需要吐字清晰,可以准备ppt演示稿,穿插在ppt的每一页,打开演讲者模式,这样的话观众看不到稿子,当然能背下来更好。
demo演示上一定要有备用方案,比如这次我们的演示,整个环节用时4分30秒,完全的空出来30秒,这一点是出乎意料的,还会我们有备用的一套demo演示,不至于最后尴尬的草草收尾,就是因为最后的这个方案,让评委老师多问了一个感兴趣点,产生了较好的印象。
以上就是复赛的全部内容,希望能帮助到你,也是对自己这个项目的圆满收官。-2023.9.17


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











