






written by TINU TOM, pubished by leanpub
Since I can't contact the author now, I'd like to make it clear that what follows is only a rough translation and cherry-picked content, not the original text of the book, and it's only out of personal interest, not for profit!
1 Getting started
下载QEMU,notepad++,NASM,SASM,MinGW,将QEMU,NASM,MinGW添加到系统变量的Path中
所有的安装是在windows环境下进行的,以这个前提对安装进行进一步说明
1.1 QEMU
选择下载qemu-w64-setup-20230822.exe这个文件
1.2 MinGW

在官网安装界面的File一栏中选择X86_64-win32-sjlj 或者X86_64-win32-seh进行下载
2 Programming In C
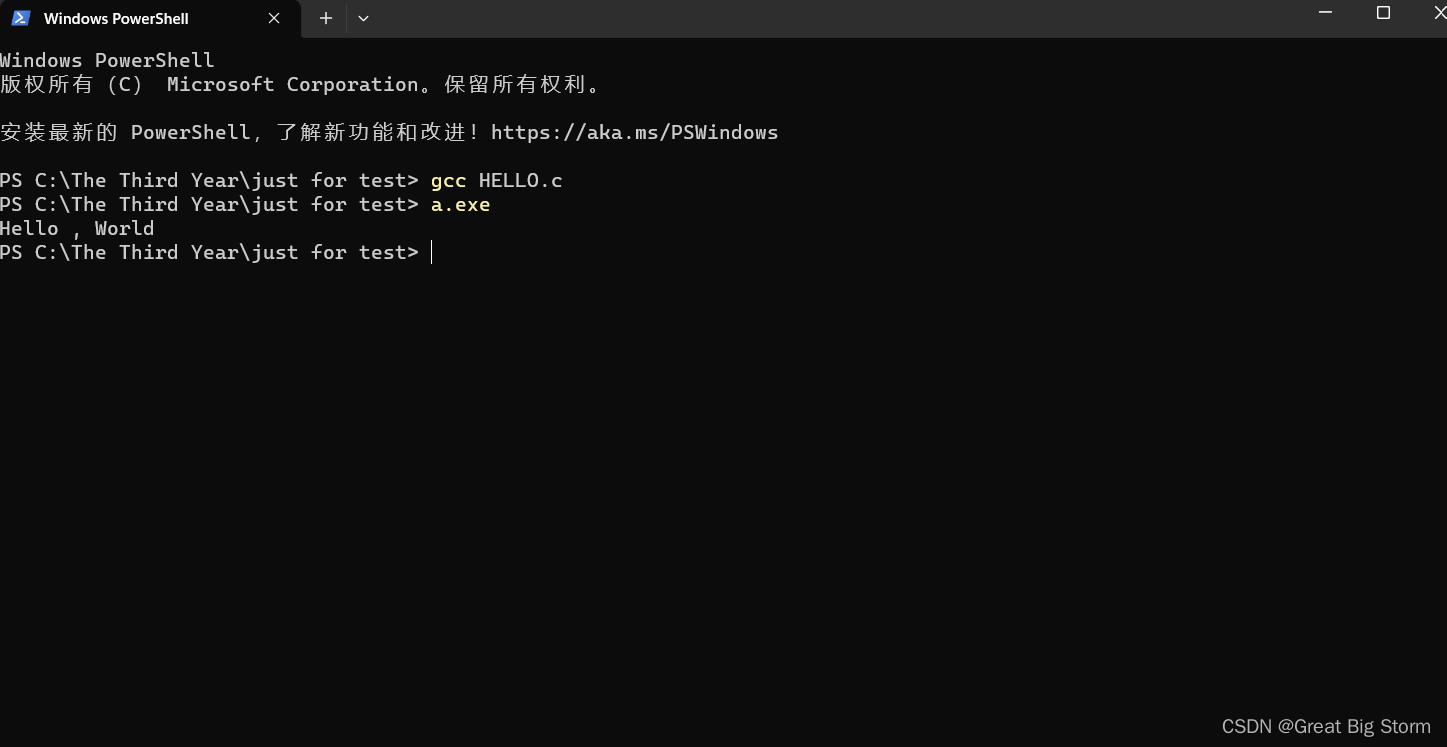
写一段C语言代码,以最简单的hello world为例,现尝试在终端运行这个代码
gcc HELLO.c
这个命令结束后产生一个名为“a.exe”的可执行文件,在终端继续输入
a.exe
你将会在终端看见hello world 这一运行结果
其余是一些基本的C语言语法知识,不再赘述
需要重新回过头看一看位操作,联合,指针
3 Programming in Assembly Language
用QEMU定义一个380计算机
X86硬件类书籍
add x, 5作为一个例子:汇编程序将这个人类可读的代码转换为二进制。
对于这个例子,请考虑以下十六进制值(它不是绝对准确的,仅用来表述汇编语言的思想):
0x83 0x45ff 0x5汇编程序将add指令本身转换为一个十六进制值:0x83,然后用0x45f表示x的地址,为了表示加5的算数,所加值被转换为0x5
在执行期间,处理器将首先获取字节0x83。
它是在处理器电路中预先定义的,因此当它看到十六进制值0x83时,准备处理器获取一些下一个二进制值来执行加法操作。
现在,处理器获取这些值0x45ff 0x5最后,处理器将0x5(十进制5)添加到位于地址0x45ff的值。
同样,处理器也有一个二进制值表,这些值表示每个操作。这些值称为机器码。
市场上有不同的微处理器架构。每个处理器体系结构都有自己独特的值表(机器码)。这意味着为特殊处理器体系结构编写的程序不能在另一种处理器体系结构中工作。
我们将要使用的处理器架构是英特尔的x86架构。
接下来在终端执行gcc指令,来看到之前Hello World这一C语言程序的汇编代码
gcc -S HELLO.c然后你会得到一个S文件,内容为:
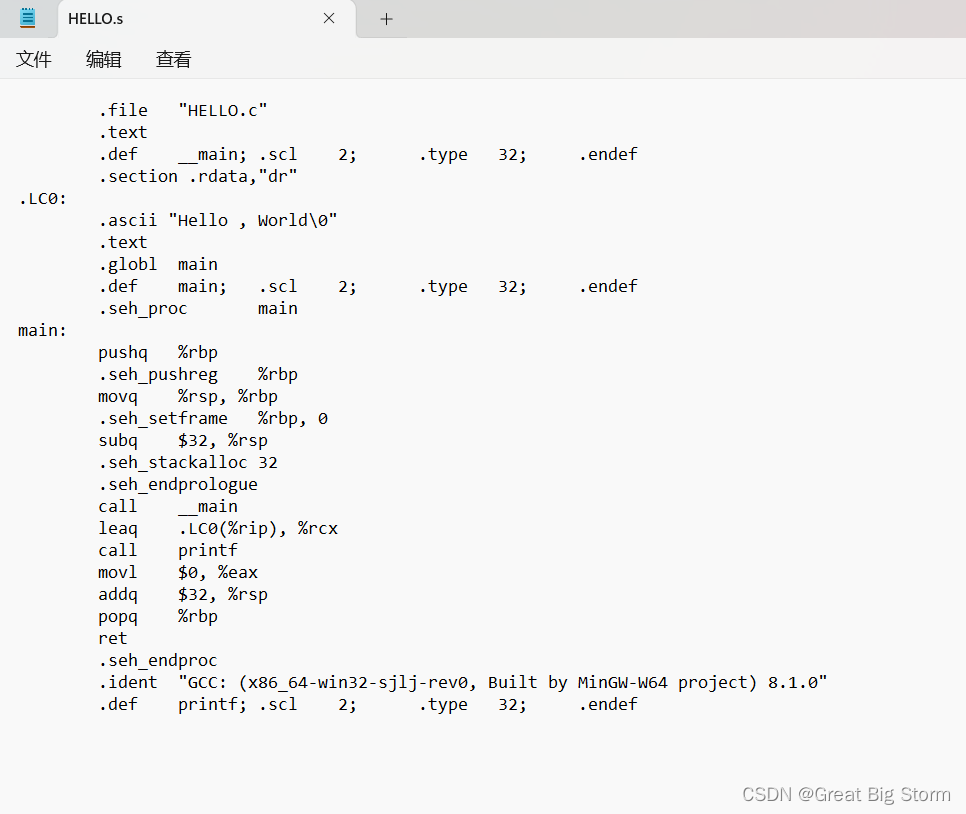
不需要担心这里看到的汇编代码的复杂性。我们不会编写这样的汇编程序,我们将只用一个整洁的样式来学习这个而不是使用编译器自带的汇编器。这就是我们下载nasm作为汇编程序的原因
现回顾X86系统对数据大小单位的定义:
Word: 2字节
Doubleword: 4字节(32位)
Quadword: 8字节(64位)
Paragraph: 16字节(128位)
Kilobyte: 1024字节
Megabyte::1,048,576字节
现在打开sasm,运行下列代码:
%include "io.inc"
section .data
msg db 'Hello, world!!', 0
section .text
global CMAIN
CMAIN:
PRINT_STRING msg
ret稍后我们对这些代码做出解释
现在,我们将学习一些理论。
处理器的主要功能是处理数据。这些数据主要存储在主存储器(也称为RAM或随机存取存储器)中。由于处理器的工作是处理数据,它可能需要经常访问内存。
这里,我们必须考虑一个因素,那就是速度。处理器比RAM快得多,频繁访问主存会大大降低它的处理速度。
这就是寄存器概念的由来。寄存器是处理器内部的存储器。
但是我们不能使用用来实现寄存器的技术来构建主存储器。如果这是可行的,我们可以考虑一个没有寄存器的架构,只有一个主存。但这种想法只会停留在理论上。现在处理器中的寄存器不是32位就是64位。但是当谈到主内存时,我们至少需要2或4 GB。
如果我们使用用于实现寄存器的技术来构建主存,它将花费难以想象的金钱,那样只有少数人才能负担得起这项技术的使用。这就是为什么我们采用将RAM作为慢速存储器- >缓存作为比RAM更快的存储器- >最终寄存器作为比缓存更快的存储器这一结构的原因。
以下是计算机中速度增加而容量减少的设备列表:
1)硬盘-永久存储器
2)Ram -当计算机关闭时数据消失
3)缓存-当计算机关闭时数据消失
4)寄存器-当计算机关闭时数据消失
寄存器分为三类:
1)通用寄存器
2)控制寄存器
3)段寄存器
通用寄存器又分为以下几组:
1)数据寄存器
2)指针寄存器
3)索引寄存器
通用寄存器
1)数据寄存器
共四种数据寄存器用于算术和其他操作。
这些是64位数据寄存器:
1)RAX
2)RBX
3)RCX
4)RDX
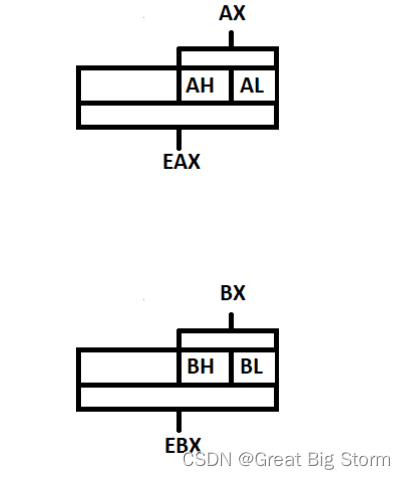
64位数据寄存器的低32位部分可以用作32位数据寄存器,它们是:
1)EAX
2)EBX
3)ECX
4)EDX
32位数据寄存器的低16位部分可以用作16位数据寄存器,它们是:
1)AX
2)BX
3)CX
4)DX
16位数据寄存器的高8位与低8位可以用作8位数据寄存器,它们是:
1)AH, AL
2)BH, BL
3)CH, CL
4)DH, DL
下为32位数据寄存器划分的图像:
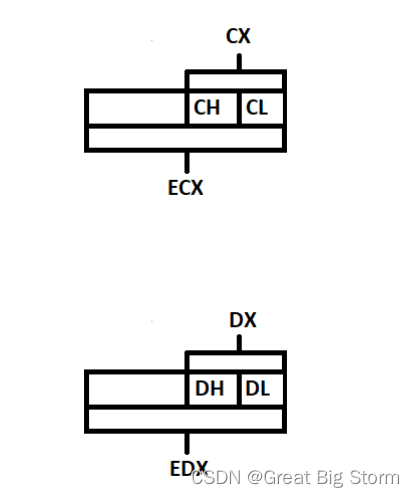
AX是主累加器:它用于输入/输出和大多数算术运算。
BX被称为基寄存器:它可以用于索引寻址(稍后我们将看到这一点)。
CX被称为计数寄存器:它主要用于存储循环计数。
DX被称为数据寄存器:它也用于输入/输出操作。它还与AX寄存器一起用于算术运算。
2)指针寄存器
共三种指针寄存器。
64位的指针寄存器:
1)RIP
2)RSP
3)RBP
32位:
1)EIP
2)ESP
3)EBP
16位:
1)IP
2)SP
3)BP
指令指针(IP) -这个寄存器存储下一个要执行的指令的地址。X86架构使用分段寻址。IP与CS寄存器相关联。CS:IP给出了下一个要执行的指令的完整地址(我们将在后面看到)。
堆栈指针(SP) -主要用于指向堆栈的顶部。SS:SP在分段寻址中给出完整的地址(我们将在后面看到)。
基指针(BP)——主要用于相对访问内存。一个特殊的偏移量,用于访问内存中的变量。SS:BP在分段寻址中给出完整的地址(我们稍后将看到这一点)。
3)索引寄存器
共2种索引寄存器。
64位:
1)RSI
2)RDI
32位:
1)ESI
2)EDI
16位:
1)SI
2)DI
源索引(SI) -主要用作字符串操作的源索引。
目标索引(DI)——这主要用作字符串操作的目标索引。
控制寄存器x86架构中的许多指令涉及比较和数学运算。这将改变一些标志的状态,并且其他一些条件指令将测试这些标志的值以影响控制流。
常用标志位包括:
1)溢出标志(OF)
2)方向标志(DF)
3)中断标志(IF)
4)陷阱标志(TF)
5)签名标志(SF)
6)零标志(ZF)
7)辅助进位标志(AF)
8)奇偶标志(PF)
9)进位标志(CF)
段寄存器
段是程序中包含数据、代码和堆栈的特定区域。X86最初是一个16位体系结构。所以我们只能用16位地址访问内存中的数据。这将限制可实现的ram的大小。分段内存用于允许我们访问更多的内存,由此诞生了段寄存器
段寄存器包括:
1)代码段(CS):用于指向可执行代码。这个寄存器存储代码段的起始地址。
2)数据段(DS):用于指向数据。存储数据段的起始地址。
3)堆栈段(SS):用于指向堆栈段的起点。堆栈段是存储函数本地变量的地方。
x86处理器字节存储顺序
x86处理器端序处理器序定义了多字节数据类型如何存储在内存中。
早期的计算机采用4位或8位处理器架构。
X86体系结构是16位体系结构,它的寄存器中的数据项可以为多字节数据类型。
存储端序分为小端序和大端序。x86使用小端存储。小端序架构即字节或半字节的最低位字节存放于内存最低位字节地址上,或者简而言之,在内存中以相反的顺序存储多字节数据。例如0x12345678,存放在存储字长为32位的存储单元中,按低字节到高字节的存储顺序为0x78、0x56、0x34和0x12。整个存储字从低字节到高字节读出的结果就是:0x78 56 34 12
从上面这个例子我们也可以看到,所谓反转式的存储并不意味着第一个比特被存储在最后,最后一个比特被存储在第一个。反转受到存储字节大小的约束
当将数据从内存复制到任何寄存器时,将进行另一次字节反转,这将一个单纯的、仅为存储的数字转化还原为原来具有实际意义的数据。
例如:将0xaa bb视为多字节数据。在内存中,它将被存储为0xbbaa。将其复制到任何寄存器后,它将以还原为0xaabb。
当谈到x86架构的C编程语言时,char类型似乎 “不会受到” 小端存储的影响,因为char是一个单字节数据类型,而int类型的内部存储却直观可见地受到存储端序的影响,因为int一般占4 - 8个字节。
寄存器操作命令(注释这些指令我们使用' ; ' 作为分隔符)
1)mov指令
常用于赋值
考虑这样一种情况:将值10复制到eax寄存器
代码如下:
mov eax, 10
我们在sasm中这样操作:
%include "io.inc"
section .text
global CMAIN
CMAIN:
mov eax , 10
PRINT_DEC 4 , eax
ret只需要查看CMAIN之后的代码:命令mov eax, 10,将值10复制到eax寄存器。
在PRINT_DEC 4, eax中,PRINT_DEC不是命令。它只是在io中定义的例程。Inc .文件包含在代码的顶部。在这里,它帮助我们将二进制值在eax寄存器转换成十进制形式,并打印它作为输出。
在PRINT_DEC 4中,eax告诉例程操作是在一个四字节的数据项中完成的(这里是eax寄存器)。
暂不需要关注这个打印功能,因为我们在开发操作系统时不会有这个例程。我们将为此构建自己的例程。
最后一个命令ret实际上将终止该程序,ret命令的功能不是终止进程。我们稍后再讨论。
我们可以在更多的寄存器中做这个操作,代码如下:
%include"io.inc"
section .text
global CMAIN
CMAIN:
mov eax , 10
PRINT_DEC 4 , eax
NEWLINE
mov ebx , 20
PRINT_DEC 4 , ebx
NEWLINE
mov ecx , 30
PRINT_DEC 4 , ecx
NEWLINE
mov edx , 40
PRINT_DEC 4 , edx
NEWLINE
ret运行结果为:
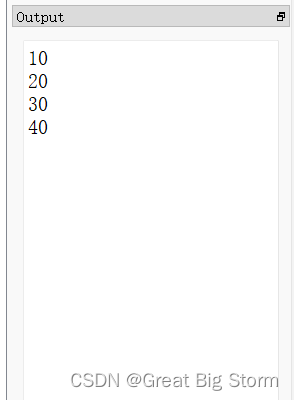
NEWLINE将在输出中放置一个换行符。它不是x86架构中的命令而是在顶部文件中预定义的
2)add指令
顾名思义,add命令是执行加法操作的命令
我们在之前的指令中增添一行,给ebx寄存器里的值再加10:

那么输出结果变为:
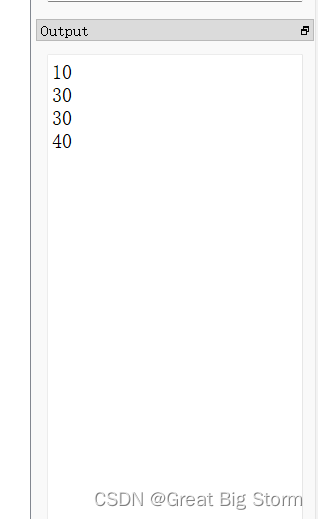
输出的值从20变为了30
sub指令(减法)也是差不多的道理
3)push和pop指令
栈(stack)是主存(RAM)中的一个区域,我们可以在其中存储变量和其他数据项。
我们可以在堆栈内存中执行的两个操作是push和pop。Push基本上意味着在内存中存储一个值(压栈),Pop意味着从内存中获取一个值(弹出)。
在x86架构上,将值压入堆栈意味着将值放入较低位的内存地址。
当我们尝试另一个push操作时,处理器将把指定的值放在前一个值 “之前” 的内存中。这意味着堆栈从高位向低位存储。
从内存中弹出值(或取值)意味着从堆栈当前的最低地址取值。
我们将看到一个示例图像,这张图模拟了堆栈的内部结构,其中已包含一些初始值:
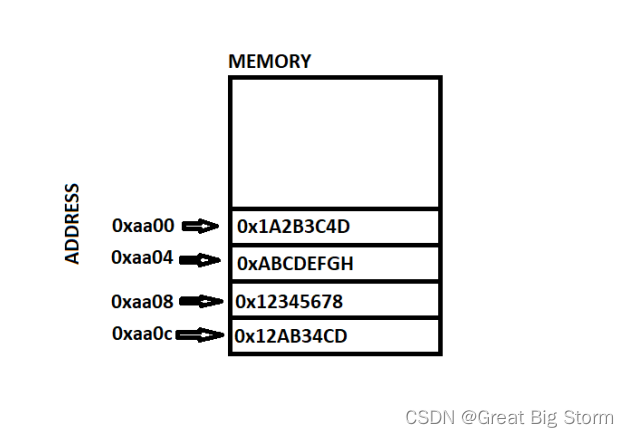
现压入一个值0xFFFFFFFF:
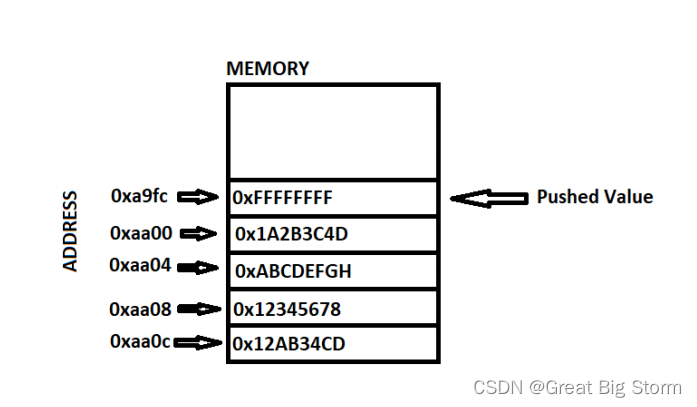
在这个阶段,如果我们发出一个pop命令,堆栈内存看起来像这样:
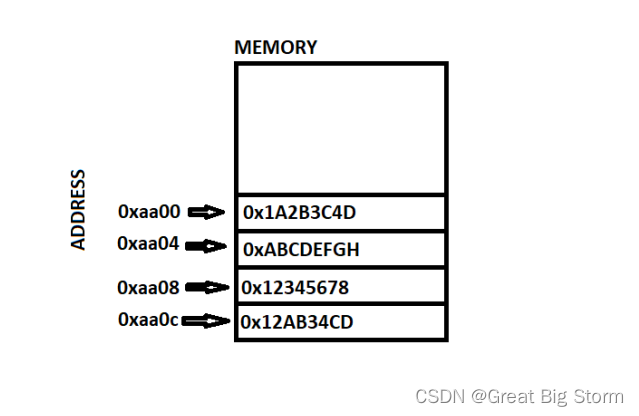
由寄存器指令来进行这个过程:
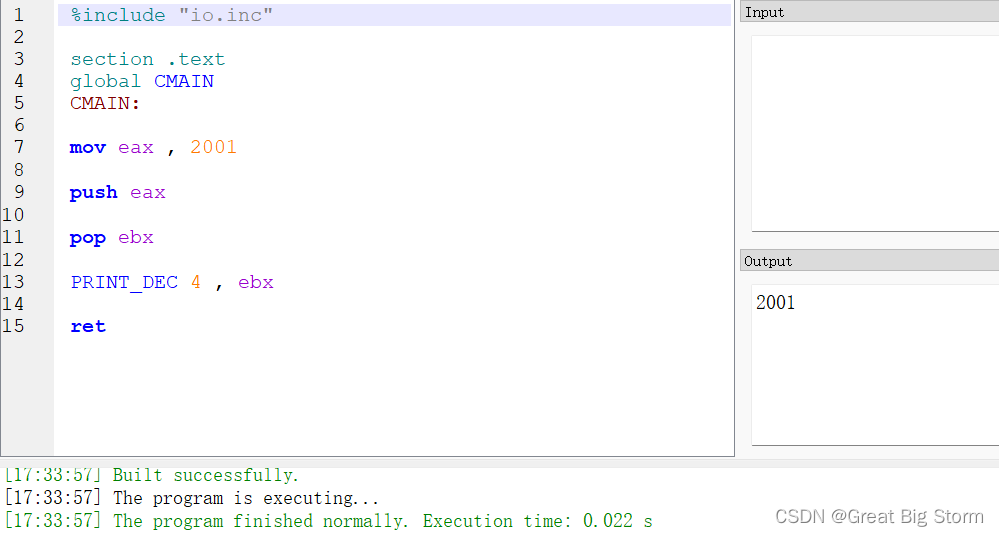
在这里,我们首先给eax初始化一个值2001。然后使用指令push eax将eax中的值压入堆栈
然后我们发出以下指令,pop ebx。这条指令把最后压入堆栈的值放到ebx寄存器中。现在,ebx寄存器中的值是2001。
然后在输出ebx中的值,如output区可见,正是2001
但是处理器怎么知道最后一个被压入堆栈的是什么呢?这就是esp寄存器的由来。esp寄存器特用来存储堆栈内存中最后一项的地址。
例如:如果我们要将eax寄存器中的值压入堆栈,处理器所做的是首先将esp中的值减4个字节(这是eax寄存器的大小,下ebx同理),然后将eax寄存器中的值压入esp寄存器所指向的地址。
同样,当我们将一个值弹出到寄存器(例如ebx寄存器)时,处理器首先将esp寄存器指向的内存中的值复制到ebx寄存器,并将esp中的值增加4个字节。
4)pushAll和popAll指令
如果想将所有寄存器中的值临时存储到堆栈中,以便可以将新值加载到这些寄存器中,然后将堆栈中的先前值分配回寄存器,该怎么办?在x86汇编中,我们有一些特殊的命令来做到这一点。
要将32位通用寄存器中的值临时存储到堆栈中,可以使用命令pushad;要将值检索回寄存器,可以使用命令popad。
当在16位寄存器上工作时,可以使用pusha和popa命令进行这些操作。
让我们来看一个例子:
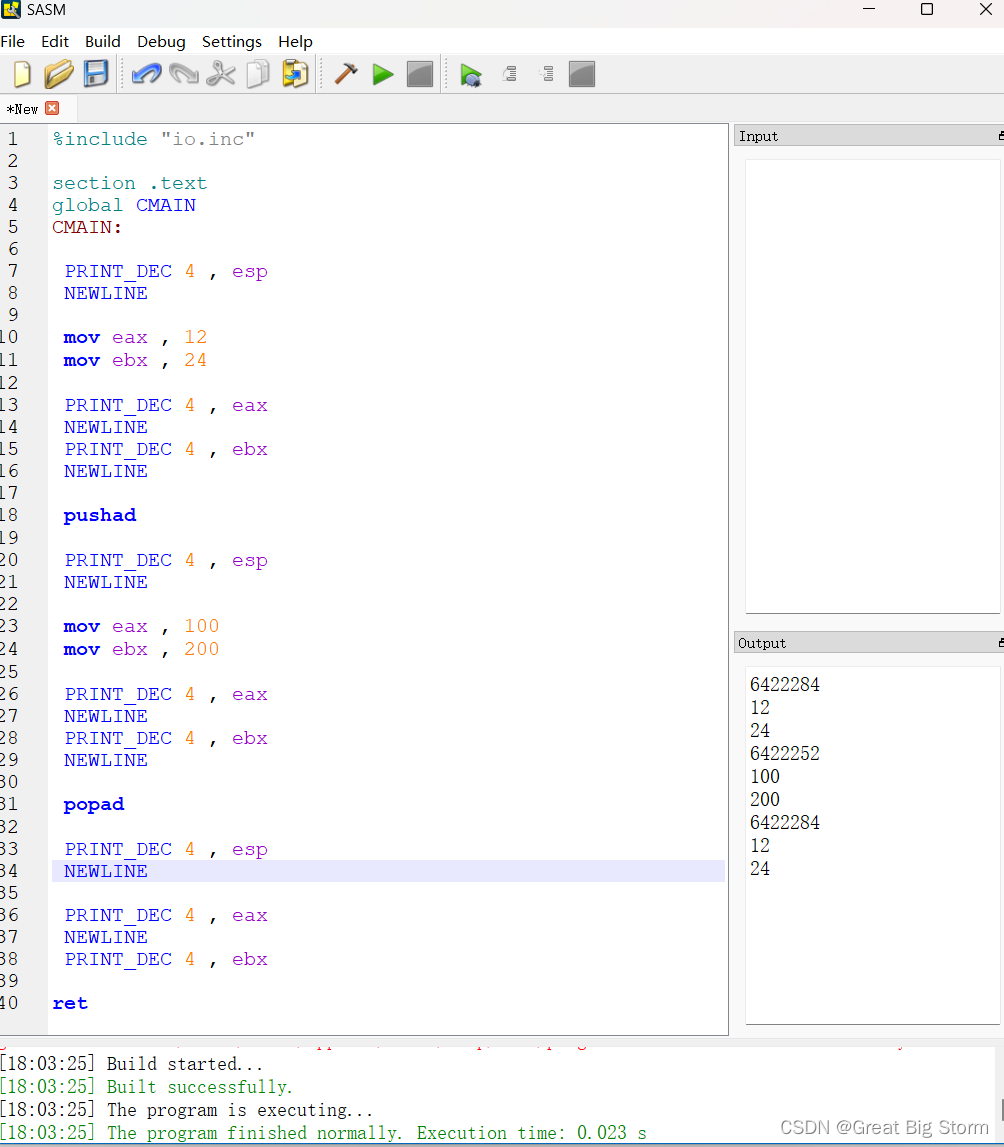
这里,我们首先将一些值移到eax和ebx寄存器中,然后将其打印出来。现在是我们的重点:我们使用pushad指令把所有通用寄存器中的值压入堆栈。这里eax和ebx寄存器中的值被推入。
然后我们将值100移动到eax寄存器,将值200移动到ebx寄存器并打印出来。这里,eax和ebx寄存器中的先前值被新值覆盖。
然后执行popad指令。这个指令将复制之前我们用pushad指令推送到堆栈的值,返回到寄存器。因此,在pushad指令之前复制到eax和ebx寄存器的值也将返回到这些寄存器中。
5)inc和dec指令
inc和dec命令都很简单。inc命令将寄存器中的值增加1,dec命令将寄存器中的值减少1
6)jmp指令
jmp是一个用于跳转到指定代码段的命令
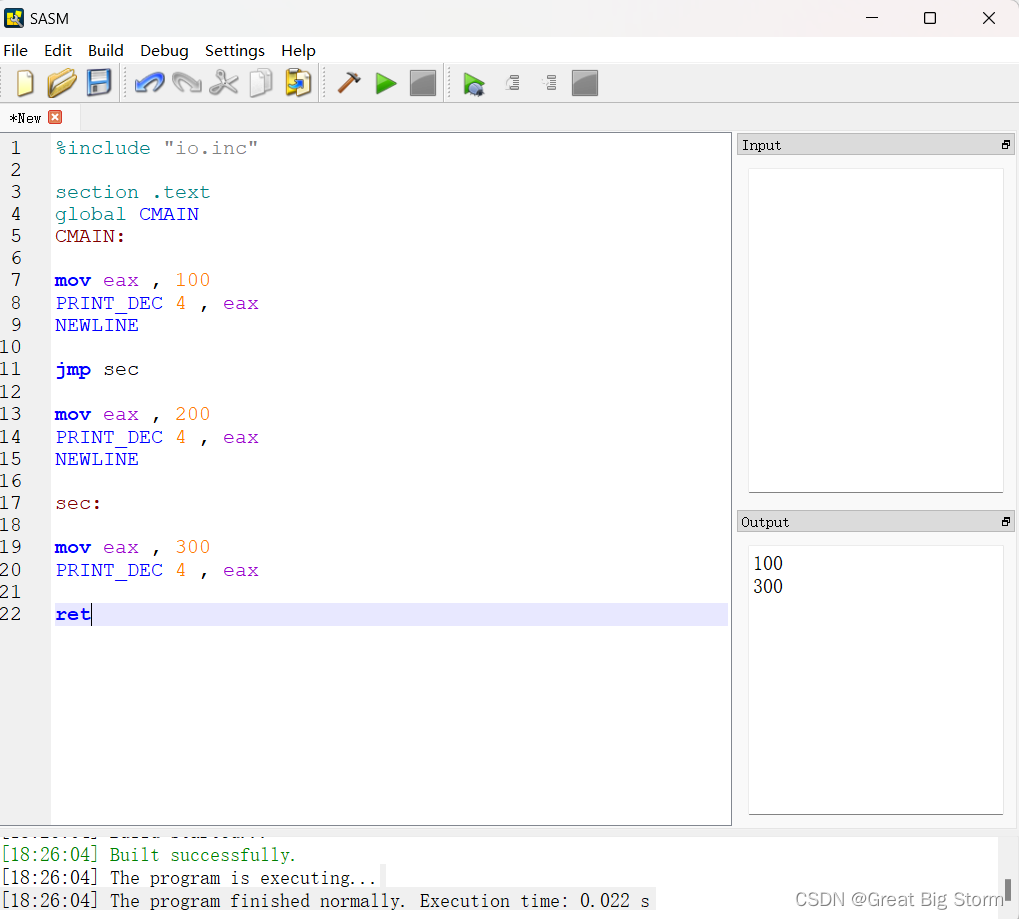 可见jmp指令使之跳过了中间部分,转而执行了sec冒号后的指令段,并且不会折返回他们所跳过的部分
可见jmp指令使之跳过了中间部分,转而执行了sec冒号后的指令段,并且不会折返回他们所跳过的部分
7)call指令
%include "io.inc"
section .text
global CMAIN
CMAIN:
mov eax , 100
PRINT_DEC 4 , eax
NEWLINE
call sec
mov eax , 200
PRINT_DEC 4 , eax
NEWLINE
ret
sec:
mov eax , 300
PRINT_DEC 4 , eax
NEWLINE
ret 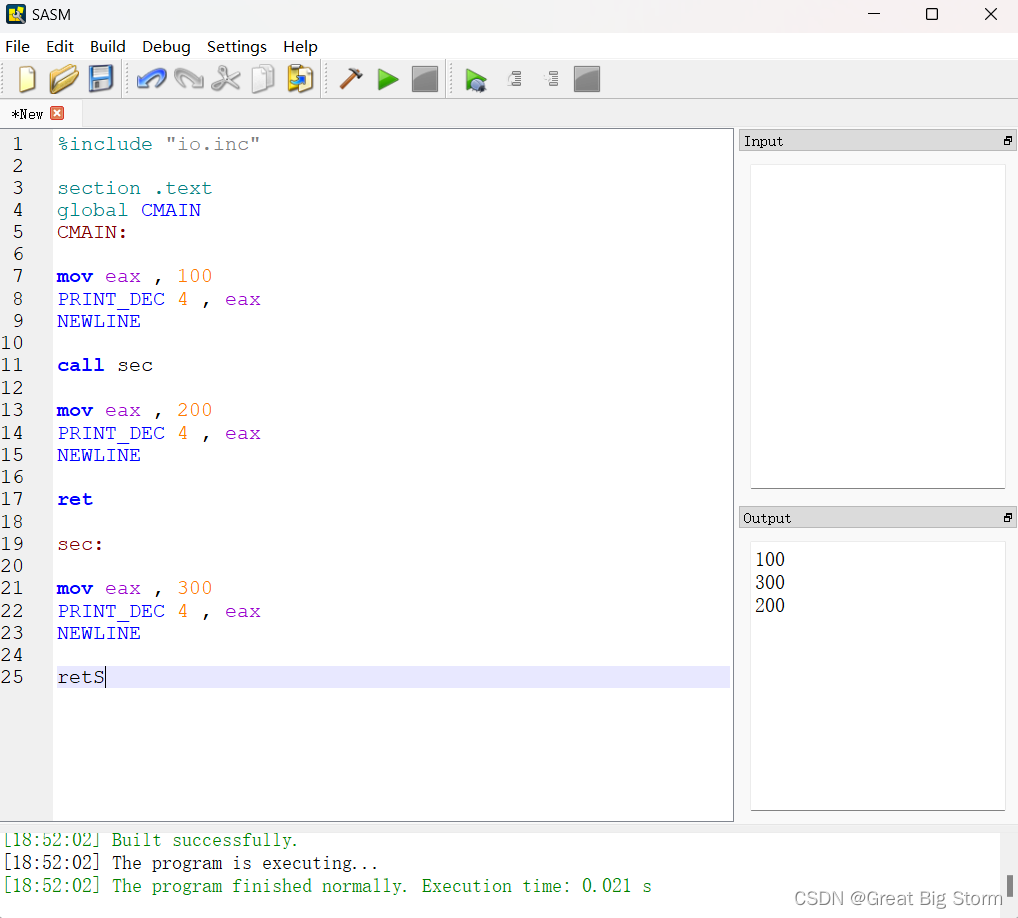
在这段代码中,我们首先将值100移动到一个寄存器并打印出来。
然后,我们采用另一种方法使用call指令跳转到sec部分。
这里,与jmp指令的不同之处在于,在跳转到名为sec的段之前,cpu在跳转到sec段之前将调用指令之后的指令的地址推入堆栈。
在本代码中,当cpu执行call指令时,它首先将指令mov eax, 200的地址推入堆栈并跳转到sec段。
在sec部分,我们将数字300打印到屏幕上。
sec部分的最后一个代码是ret, ret指令总是弹出堆栈顶部的值,并将其存储在eip寄存器中(这是下一个要执行的指令的地址所在的寄存器)。
由于之前执行的调用指令,将一个地址推入堆栈,当ret指令被满足时,这个推入的地址本身将被弹出到eip寄存器。即执行指令mov eax, 200,然后打印该数字和换行符。在这之后下一个要执行的指令也是ret。当这段代码被执行时,cpu将跳转到调用我们定义为CMAIN的代码段,从而执行终止进程的代码。
如果没有ret,程序将会崩溃
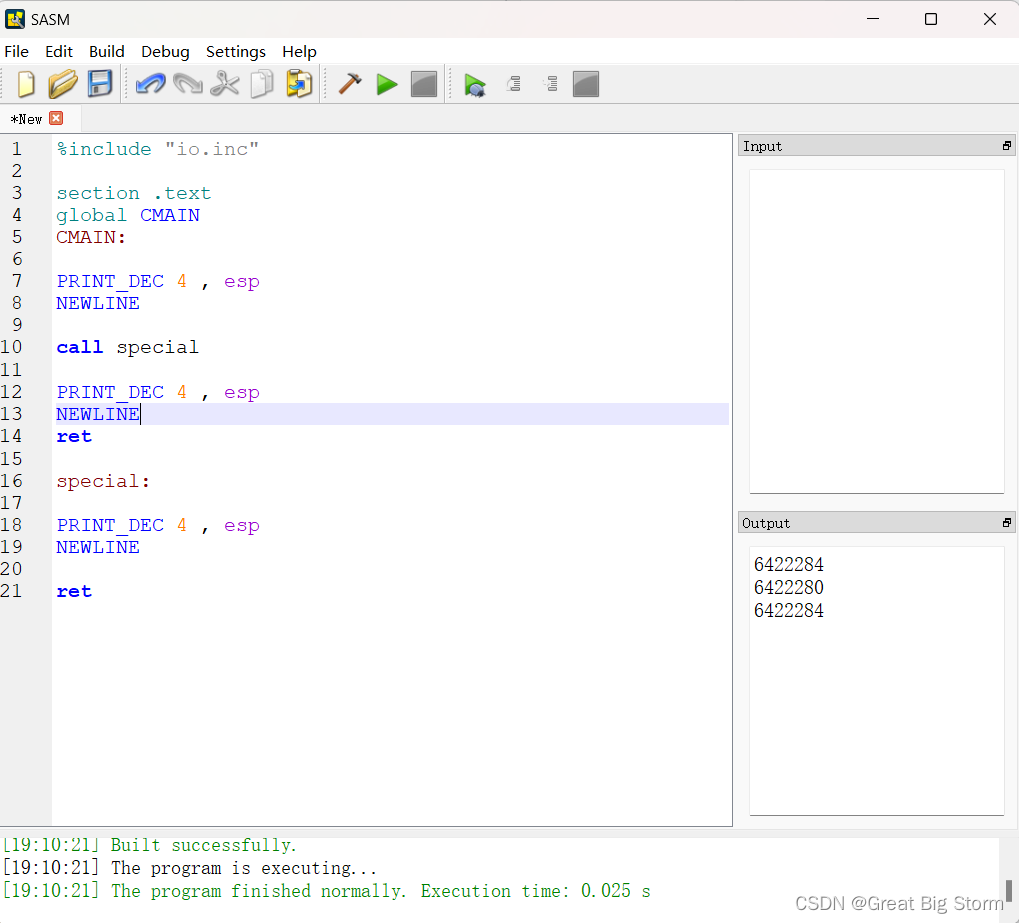
为了进一步说明压入下一条指令这个操作,我们将用如下程序进行说明:
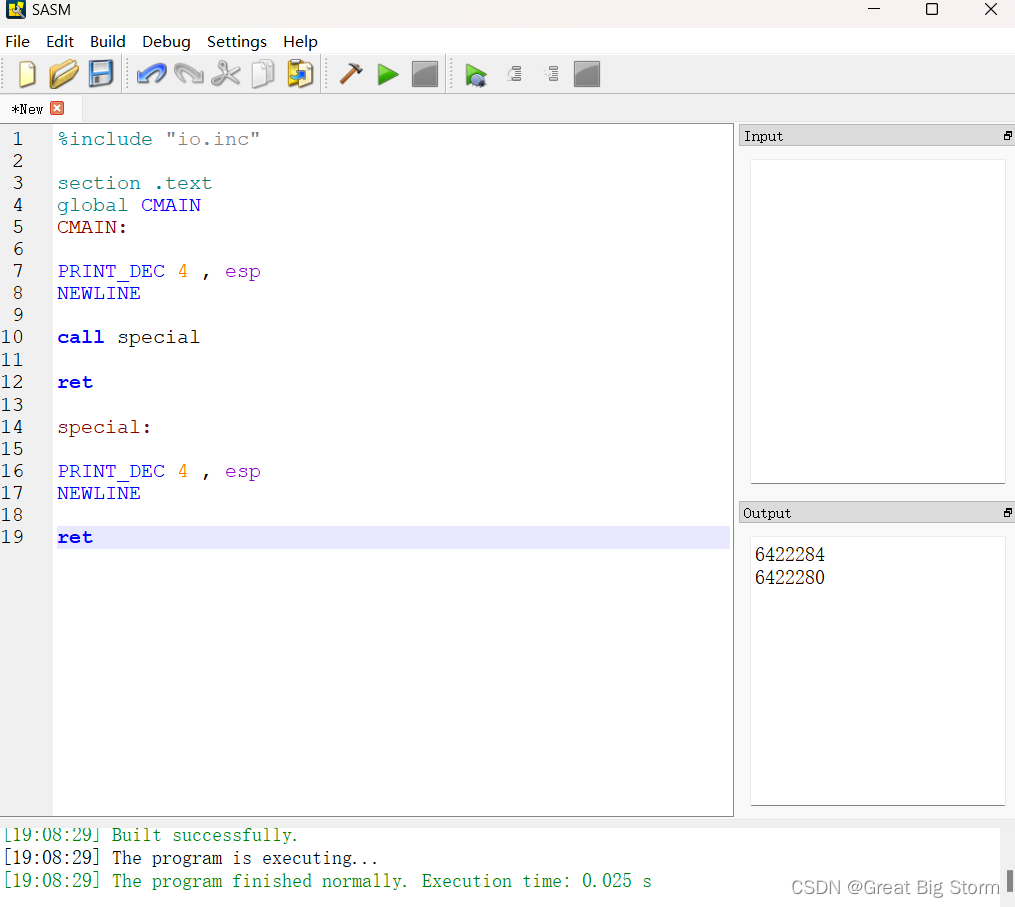
在这段代码中,我们首先在esp寄存器中打印值。这是位于堆栈顶部的数据的地址。
然后,我们用call指令调用一段名为special的代码。
这将把调用指令之后的指令地址推入堆栈,并跳转到名为special的代码段。
在特殊部分中,我们打印了esp中的值,可以看到值发生了变化。这是因为调用指令将一个地址推入堆栈。这个改变后的值是堆栈顶部value的地址,这里是调用指令之后的指令的地址。从特殊部分返回后,esp中的值将回到最初值,演示如下:
8)cmp指令
cmp用于通过比较两个值来执行条件执行
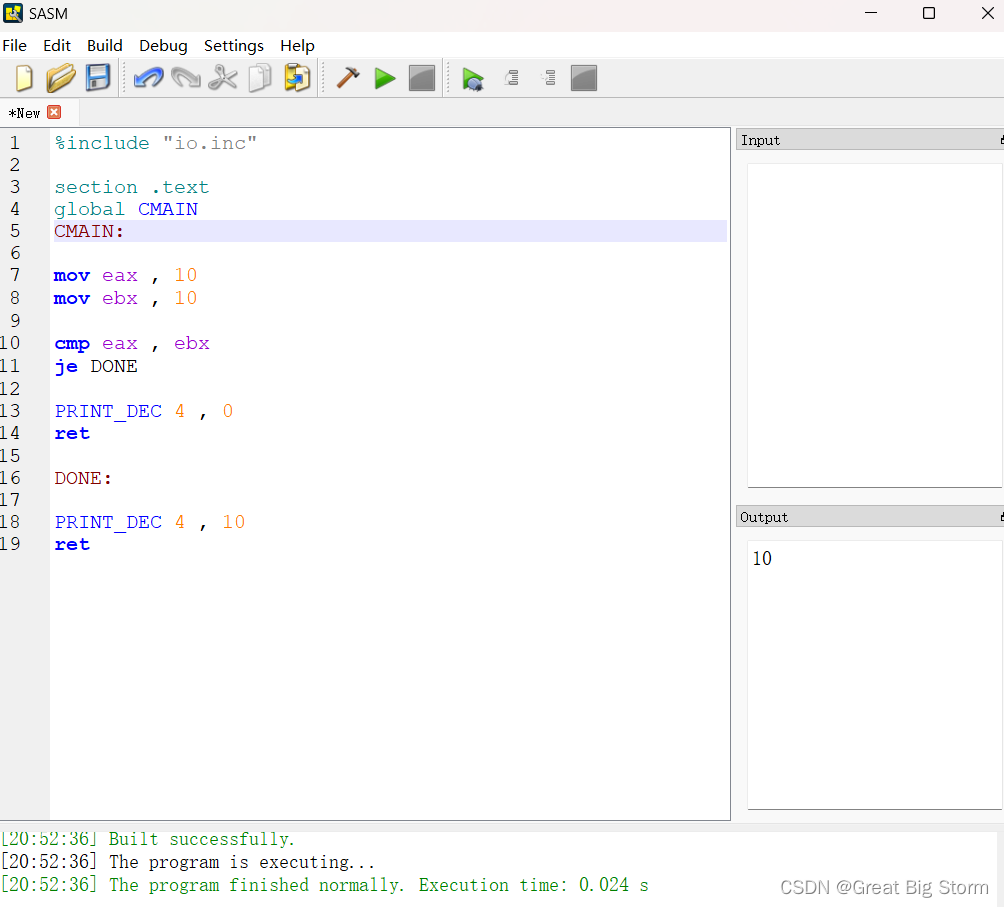
在这里,我们首先将值10复制到eax和ebx寄存器。
然后,使用命令cmp eax, ebx,我们比较了eax和ebx寄存器中的值。
我们发出的下一个指令是je指令。它代表Jump Equal或Jump If Equal。
当执行je DONE指令时,处理器检查我们使用cmp指令完成的比较结果,如果eax和ebx寄存器中的值相等,那么它将跳转到名为DONE的代码段。
如果值不相等,它将继续执行PRINT_DEC 4,0的指令。这意味着如果值不相等,cpu将不会跳转到DONE段。
在这里,我们使用je作为条件操作符,但是在cmp命令之后,我们有更多的命令可以使用。它们是:
1)JE:相等跳转
2)JNE:不等跳转
3)JG:较大跳转
4)JGE:大于或等于跳转
5)JL:较小跳转
6)JLE:小于或等于跳转
变量
Nasm为我们提供了将变量存储在堆栈段以外的区域的特性。Define指令帮助我们分配这些位置。
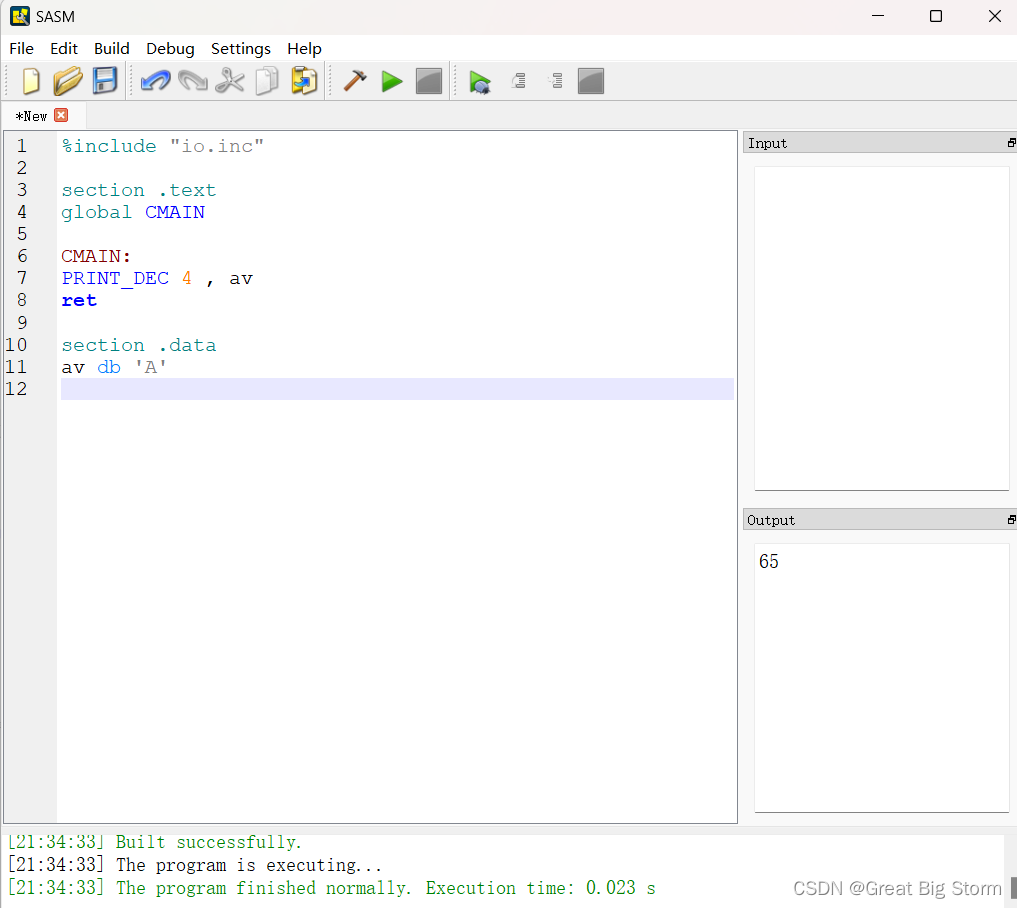
在这里,你可以看到一段以section .data开头的代码,在该section中声明了一个变量。
这里av是变量的名称,db表示给该变量分配一个字节,' a '将分配给为av保留的位置。
您在屏幕上看到的输出是分配给该变量的字符的ascii值。
db指令还可以创建字符数组(String)。
比方说这个指令:
msg db 'Hello, world!', 0
这个指令分配了一些内存来存储字符串Hello, world!,并以空字符(0)结尾,可以通过引用变量名msg来访问。
我们有更多的关键字来分配不同长度的变量。完整选项如下:
1)db:分配1个字节
2)dw:分配2个字节(Word)
3)dd:分配4个字节(Doubleword)
4)dq:分配8个字节(Quadword)
5)dt:分配10个字节
内存寻址
好比在C语言中我们通过指针来访问内存,汇编语言里也有直接访问内存的方式
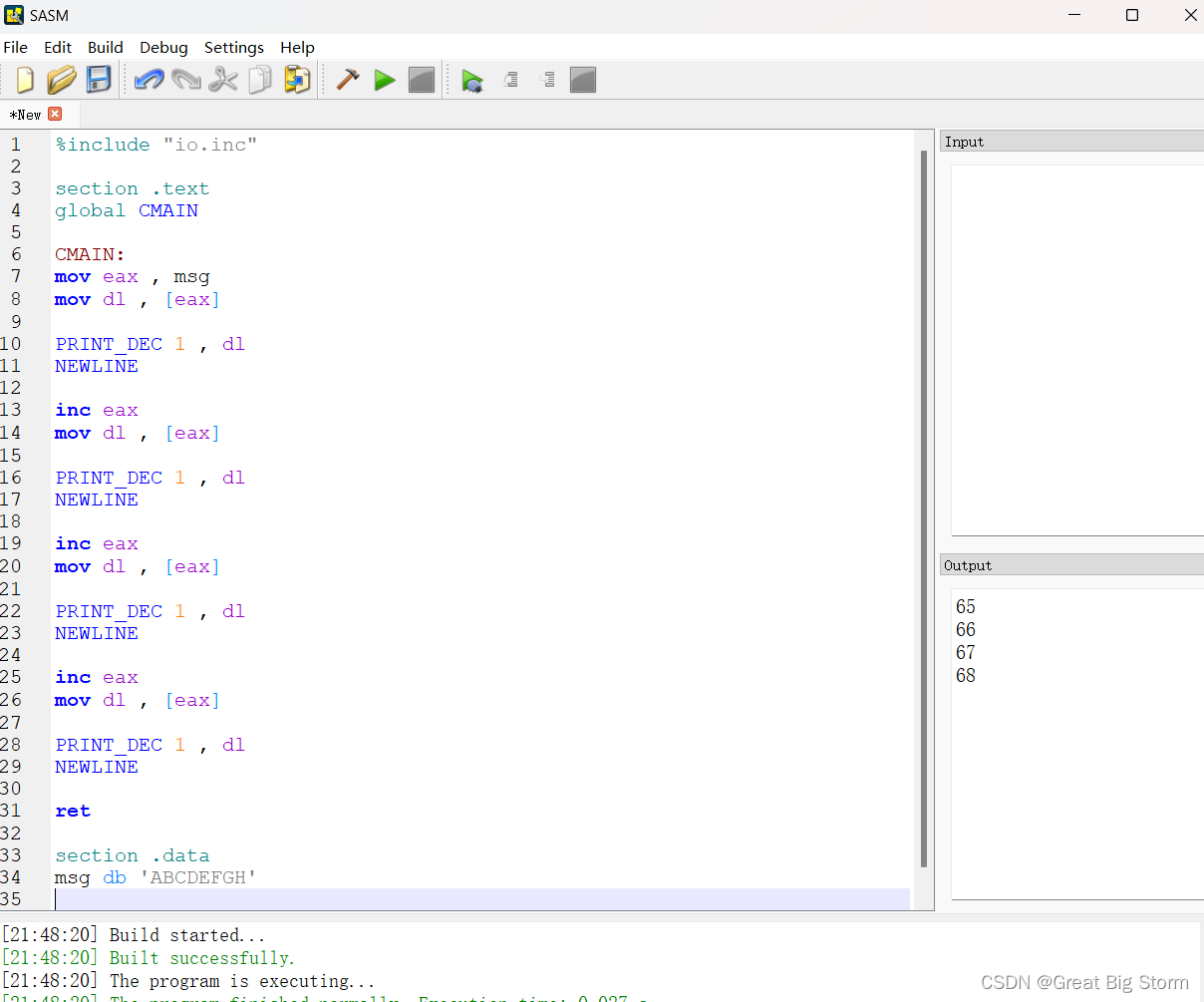
程序末尾声明了一个名为msg的字符串变量msg ,每当我们引用名为msg的东西时,我们将获得字符串ABCDEFGH的地址。
代码中的第一行是:这一行将字符串ABCDEFGH的地址移动到eax寄存器。
下一行,[eax]中的方括号被用来使计算机在执行时,将eax寄存器中的值作为地址(即msg的首地址),并将该地址中的数据带到dl寄存器中。这里,方括号被用作访问内存的标志。
处理器将只从dl寄存器中取出一个字节,因为dl寄存器的大小只有一个字节。
然后我们用命令PRINT_DEC 1, dl打印dl寄存器中的值。
这将打印字符A的ascii值,因为变量msg中的第一个字符就是A本身。
然后我们增加地址并打印每个字符的ascii值。
在这里,我们使用命令mov dl, [eax]来复制第一个字符的ascii。我们使用inc命令增加地址后访问下一个值。如果我们想在不使用inc命令的情况下访问第二个字符的ascii,你可以使用像mov dl, [eax + 1]这样的命令。这将为我们提供第二个字符的ascii,同样,命令mov dl, [eax + 2]将为我们提供第三个字符的ascii。进一步的增量将在msg变量中为我们提供更多的值。
考虑另一种情况,我们想要访问地址61ff0c中的数据。我们可以使用命令mov eax, [0x61ff0c]。这将始终将地址61ff0c中的值移动到eax寄存器。但是像这样访问一个特定的地址并不是每次都有效,因为当我们在一个预先制作的操作系统(这里是Windows)上工作时,操作系统可能会拒绝访问该内存,这可能会导致进程崩溃。这是因为在windows和大多数其他当前操作系统中,一些内存部分是受保护的。但是如果我们指定的地址不受保护,我们将获得数据。
但是当运行我们制作的操作系统时,我们将访问每个位置,因为没有什么可以阻止我们这样做。操作系统的内核可以访问所有的内存位置。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









