








降维
概念
降维是指在某些限定条件下,降低随机变量(特征)个数,得到一组 “不相关” 主变量的过程
维数
维数:嵌套的层数
- 0维 标量
- 1维 向量
- 2维 矩阵
- 3维
- …
- n维
特征选择
定义
数据中包含 冗余 或者 相关变量(或称为 特征、属性、指标等),旨在从原有特征中找出主要特征
方法
Filter(过滤式)
Embeded(嵌入式)
Filter(过滤式)
主要探究特征本身特点、特征与特征和目标值之间关联
- 方差选择法:低方差特征过滤
特征方差小:某个特征大多样本的值比较接近
特征方差大:某个特征很多样本的值都有差别
-
相关系数
衡量特征与特征之间的相关性
API
sklearn.feature_selection.VarianceThreshold( threshold = 0.0 )
# 删除所有低方差特征
Variance.fit_transform(x)
# x:numpy array格式的数据[n_samples , n_features]
# 返回值: 训练集差异低于threshold的特征将被删除。默认值 # 是保留所有非零方差特征,即删除样本中具有相同值的特征。
相关系数
皮尔逊相关系数( Pearson Correlation Coefficient)
反应变量之间相关关系密切程度的统计指标
公式:
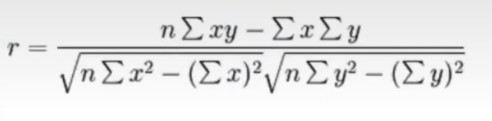
举例:

最终结果:0.9942
所以最终得出结论:广告投入费与月平均销售额之间有高度的正相关关系
特点
相关关系的值介于 [ -1 ,1 ] 之间,性质如下:
-
当 r > 0 时,表示两变量正相关,r < 0 时,表示两变量负相关
-
当 | r | = 1时,表示两变量完全相关,当 r = 0时,表示两变量间无关
-
当 0 < | r | < 1 时,表示两变量有一定程度的相关
-
一般分为三个等级:
| r | < 0.4 为低度相关
0.4 ≤ | r | ≤ 0.7 为显著性相关
0.7 ≤ | r | < 1 为高度线性相关
API
计算特征与目标变量之间的相关度
from scipy.stats improt pearsonr pearsonr(x,y) # x : 特征 # y : 目标变量 # 返回:r: 相关系数 [-1,1]之间,p-value: p值。 #注: p值越小,表示相关系数越显著,一般p值在500个样本以上 时有较高的可靠性
Embeded(嵌入式)
主成分分析(PCA)
定义: 高维数据转化为低维数据的过程,在此过程中可能会舍弃原有数据、创造新的变量
作用:数据维数压缩,尽可能降低原数据的维数 (复杂度),损失少量的信息
应用:回归分析或者聚类分析
API
sklearn.decomposition.PCA(n_components = None)
#将数据分解为较低维数空间
# n_components:如果你传整数或者浮点数
# 小数:表示保留百分之几的信息
# 整数:减少到多少特征
PCA.fit_transform(x)
#x: numpy array格式的数据
#[n_samples , n_features]
# 返回值: 转换后指定维度的array
举例
from sklearn.decomposition import PCA
def pca_demo():
# 传入数据
data = [[2,8,4,5],[6,3,0,8],[5,4,9,1]]
# 实例化一个对象
transfer = PCA(n_components=2) #转换为2维
# 调用fit_transform
data_n = transfer.fit_transform(data)
print("data_n:\n",data_n)
if __name__ == "__main__":
pca_demo()
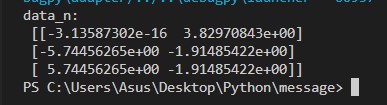
把4个变量降成了2个
拓展
merge()函数
用于合并表
















 469
469











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









