






搭建hadoop需要的软件
-
VMware Workstation 用于管理虚拟机的软件
-
Xshell 7 用于远程操控虚拟机
-
-
Xftp 7 用于远程传输文件到虚拟机(将文件从windows传输到linux)
注:以下是在linux系统采用三台虚拟机搭建Hadoop集群的步骤
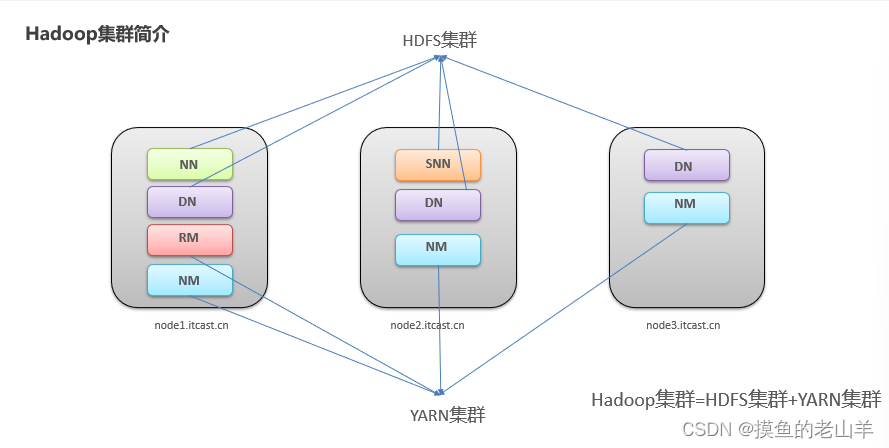
第一步 集群角色规划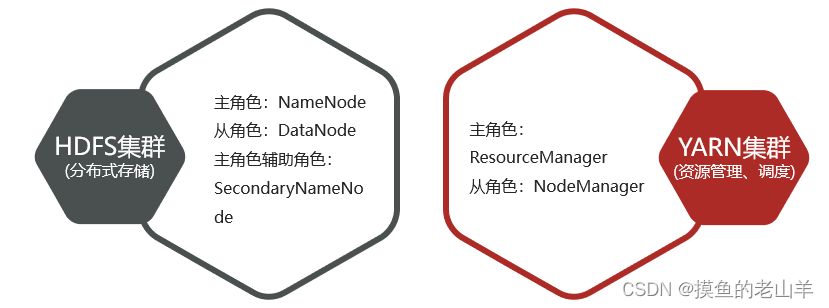
给每台虚拟机分配角色,以及IP地址
-
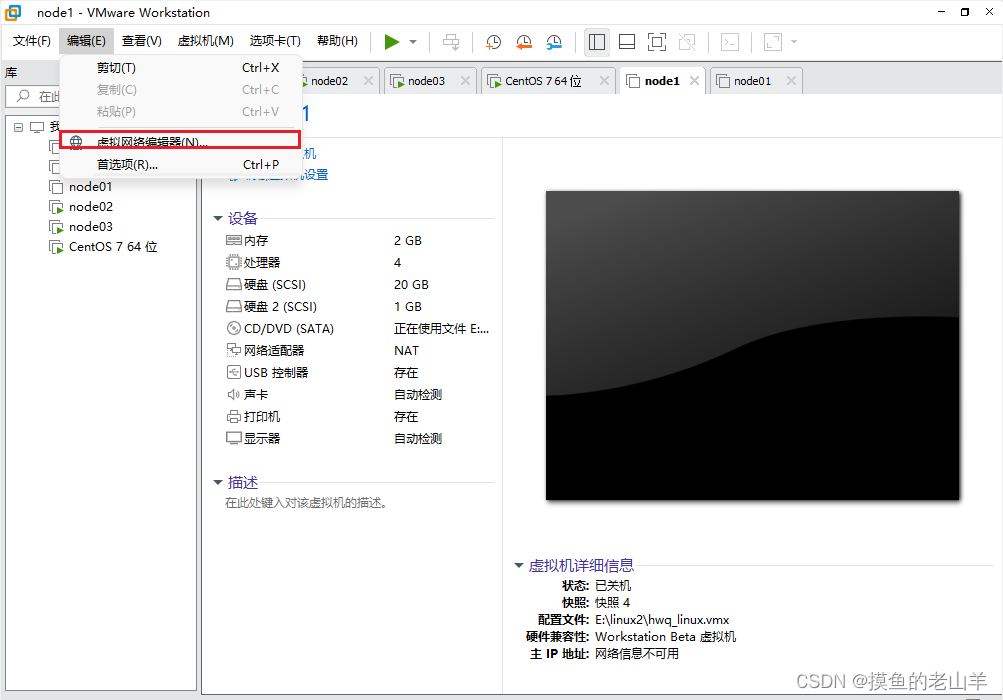
判断当前主机的网络号,才能规划集群的IP地址
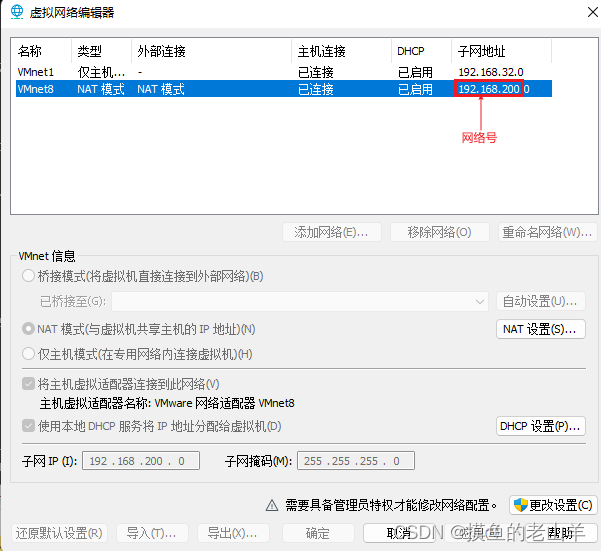
-
可知我当前机器的网络号是192.168.200
-
那么我规划的三台机器的IP地址就可以是192.168.200.80 192.168.200.81 192.168.200.82
-
按照这个思路,规划你的集群IP地址

-
![]()
注意事项
-
一定要设定一个namenode角色,并且尽量将namenode分配在内存大的机器上
-
将经常联系的角色分配在一个机器上,有利于提高数据传输速度
-
将互相争夺资源的角色,尽量分配在不同的机器上
第二步 先新建一台虚拟机
-
先在第一台虚拟机配置,后面的两台虚拟机,可以直接克隆第一台虚拟机
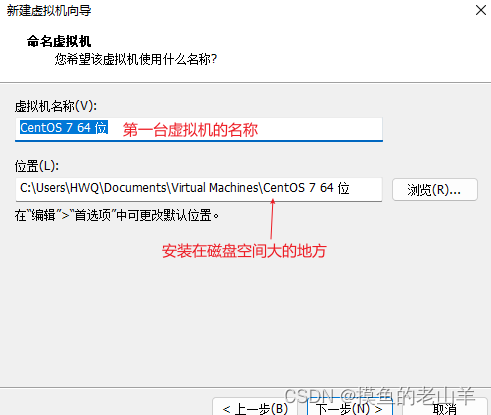
-
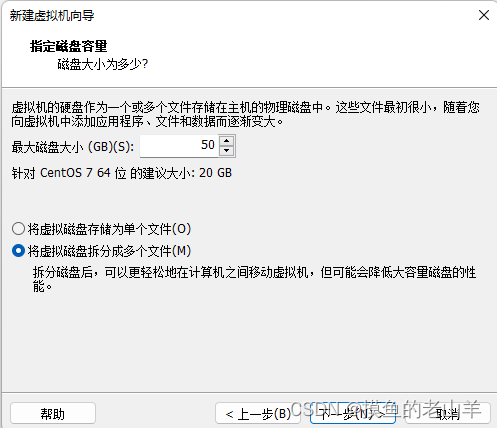
最大磁盘空间,不代表虚拟机直接占用这么大的磁盘空间,所以尽量设置大一点,毕竟集群处理的都是大数据,需要的磁盘空间比较大,建议设置50G
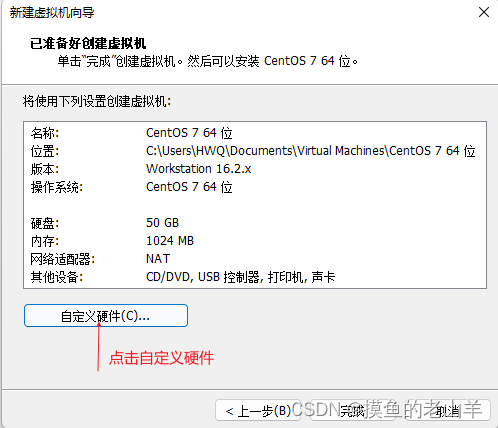
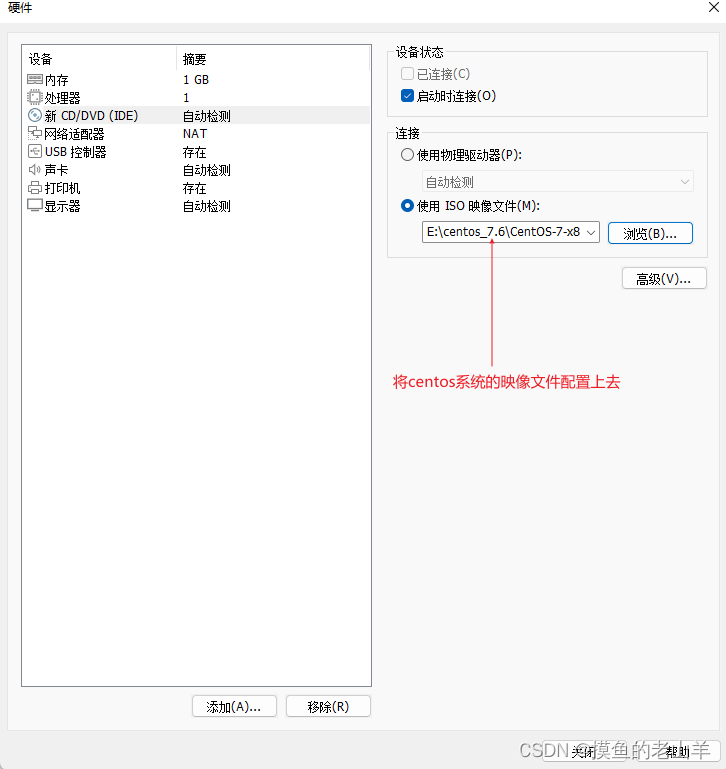
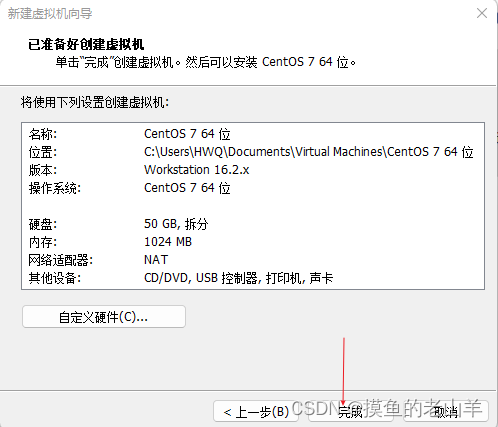
-
然后点击开启虚拟机
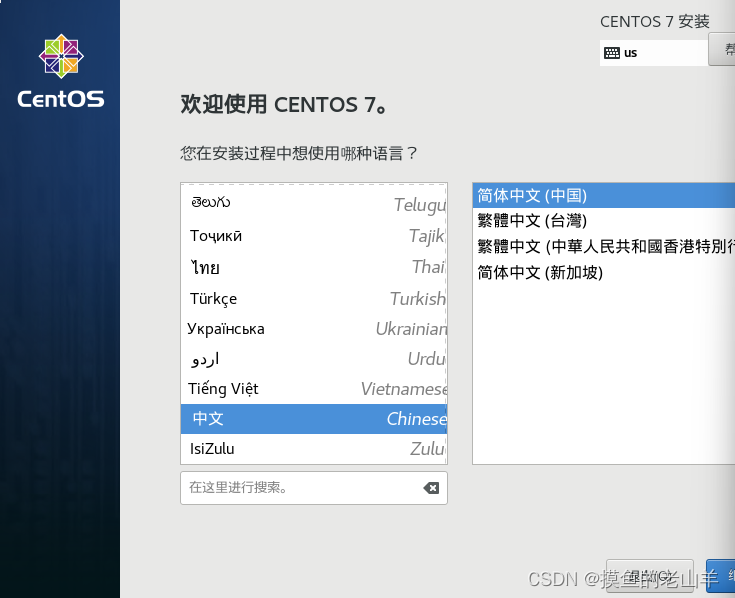
-
选择中文
-
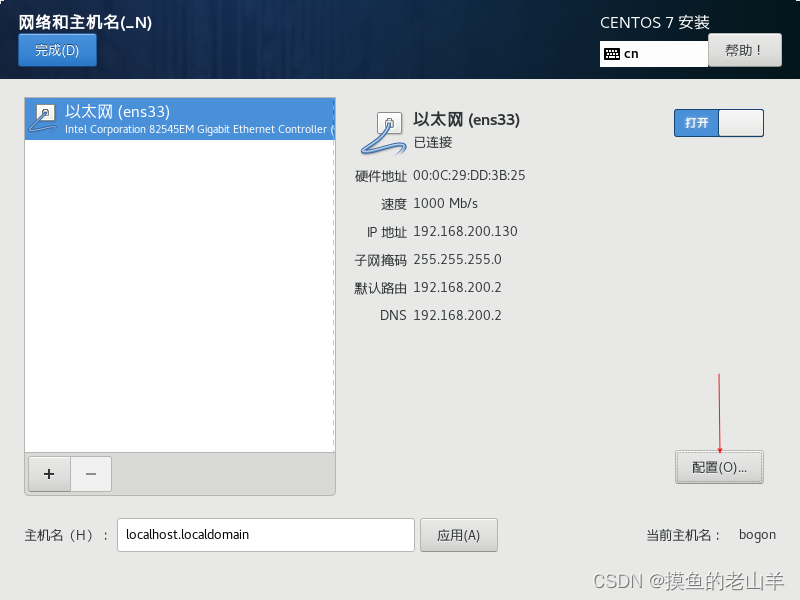
点击网络和主机名,打开以太网
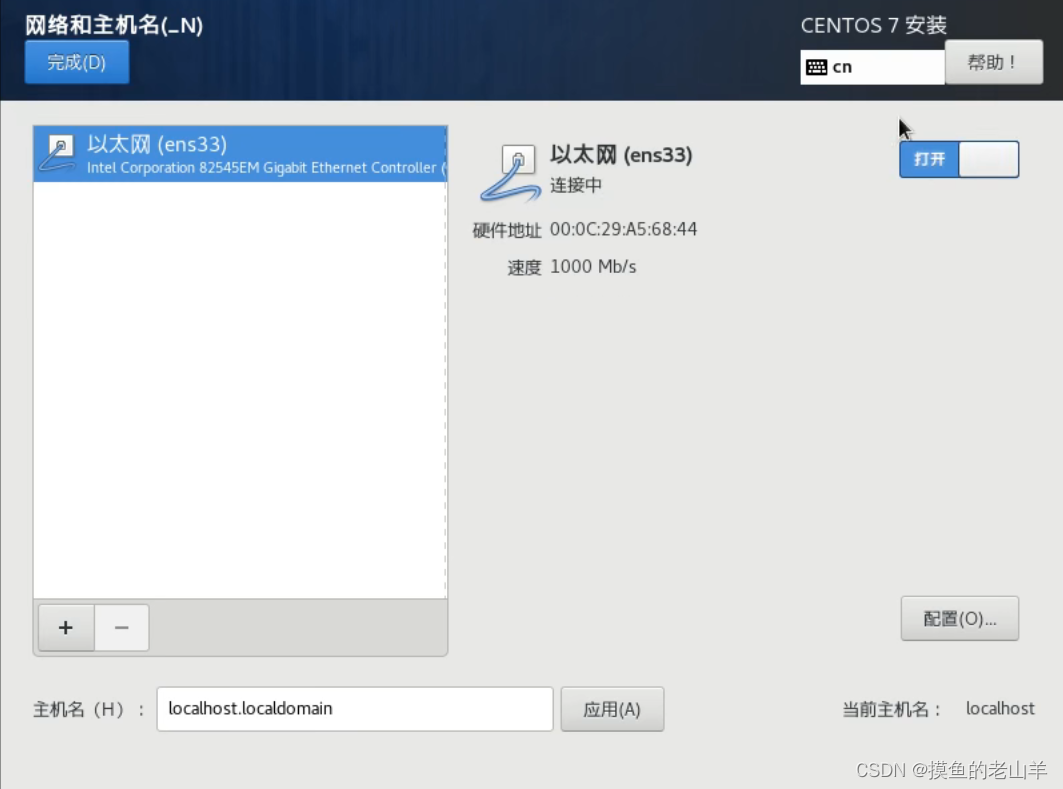
-
点击配置
-
选项IPv4设置
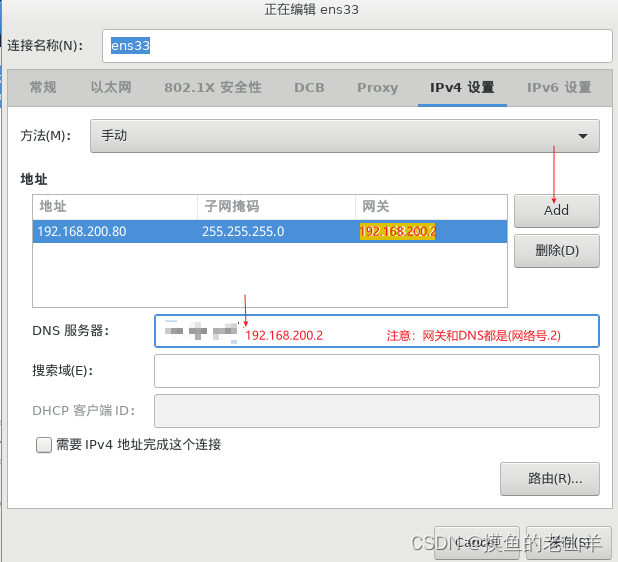
-
地址也就是IP地址,是我们提取规划好的第一台机器的IP,网关和子网掩码是固定的
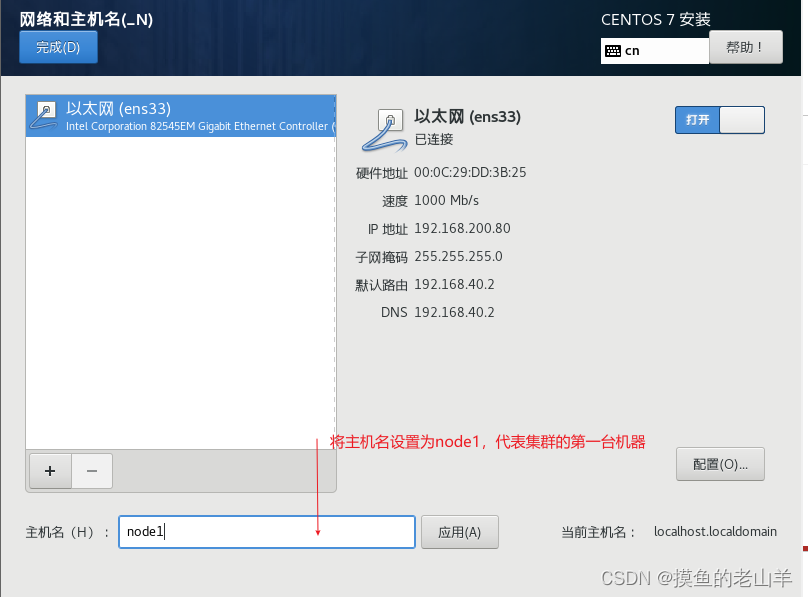
-
然后点击应用
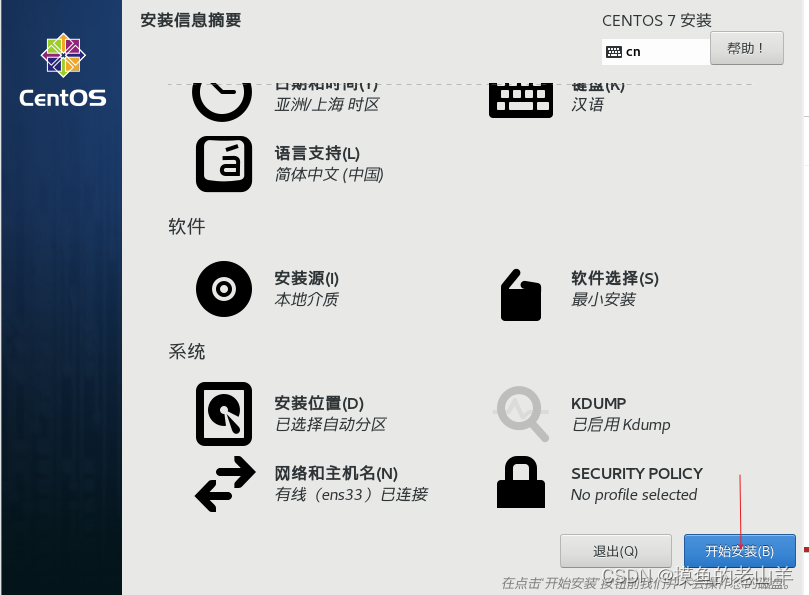
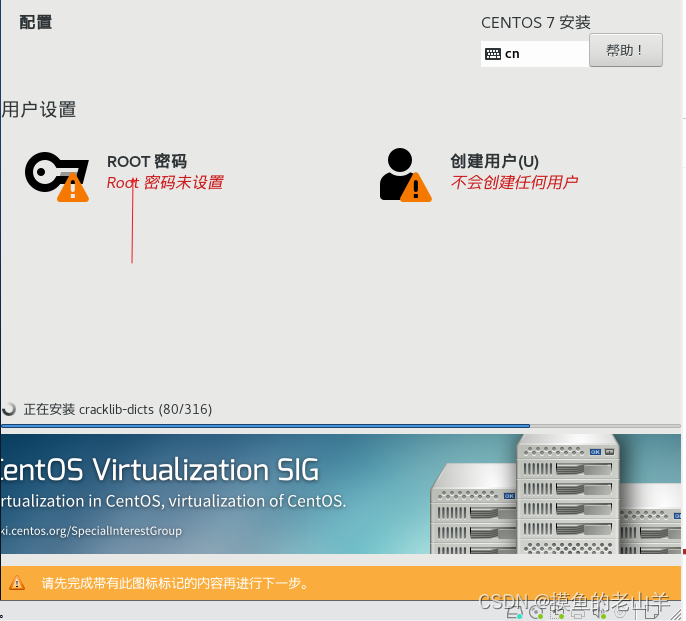
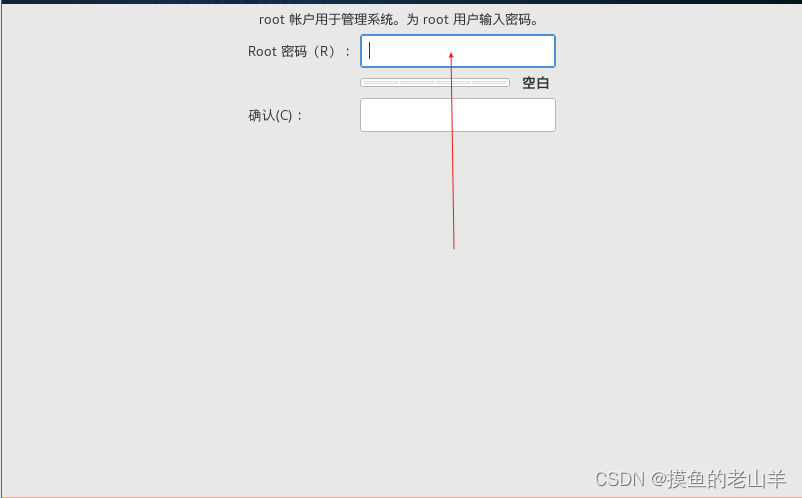
-
设置root账户密码
-
重启过后第二步就完成了
第三步 下载Hadoop安装包、JDK1.8
-
首先下载需要用到的工具net-tools和vim
yum install net-tools yum install vim
注意:下载在window的安装包可以通过xftp 7传输到Linux虚拟机
Hadoop安装包地址:Index of /dist/hadoop/common/hadoop-3.3.0
-
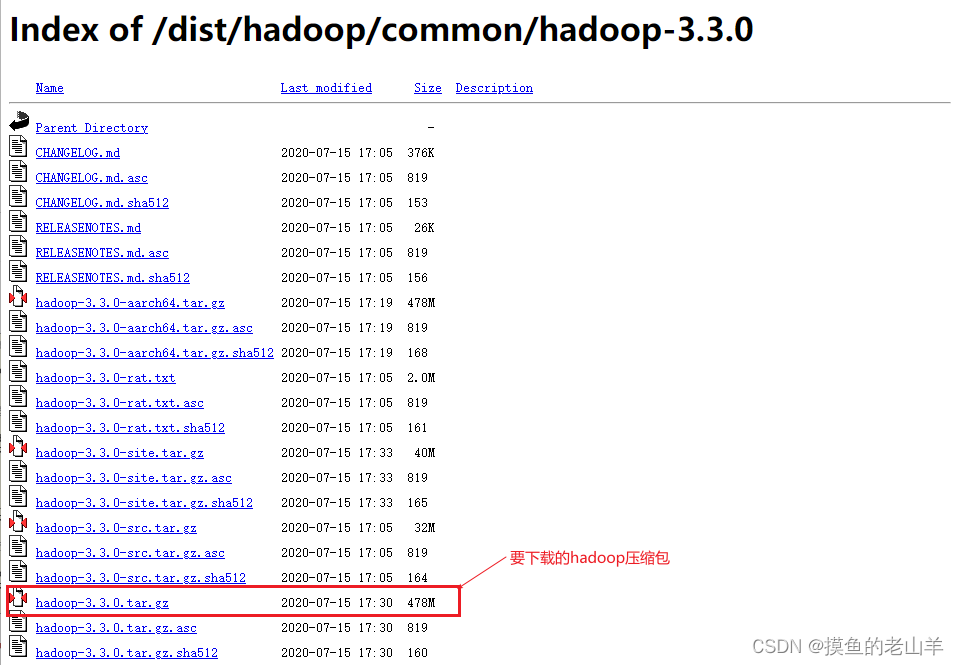 将安装包下载到本地后,拉到Linux的目录中,新建一个/export/server目录(放Hadoo以及JDK的包)
将安装包下载到本地后,拉到Linux的目录中,新建一个/export/server目录(放Hadoo以及JDK的包) -
然后,在当前目录将hadoop安装包解压一下,注意我下载的是hadoop3.3.0版本,根据不同的版本文件名也不同
-

-
会生成一个

JDK1.8安装包地址:Java Downloads | Oracle
-
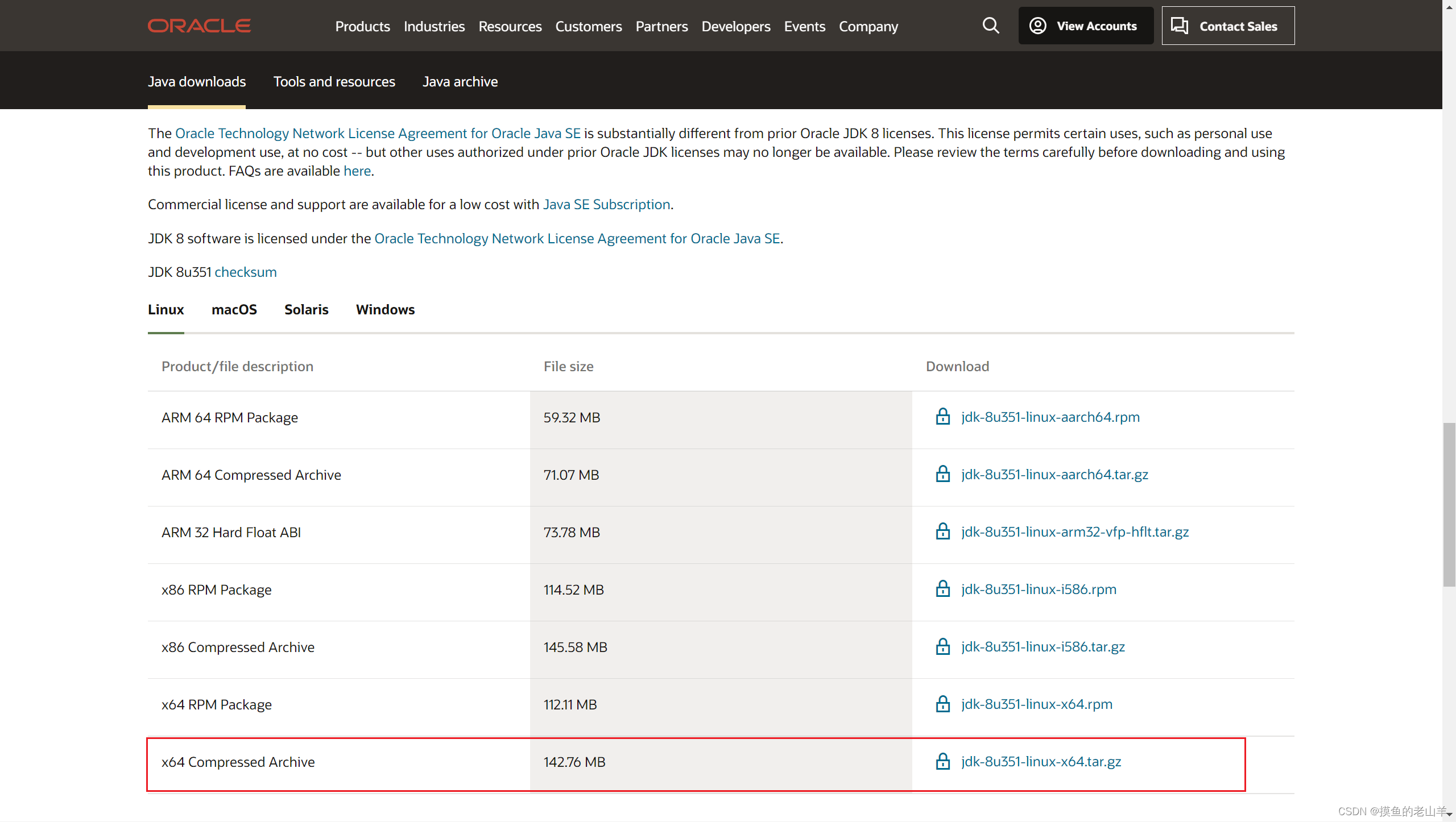
-
同样将JDK1.8的压缩包放到/export/server目录下,并解压,会得到两个包
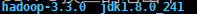
-
然后在/etc/profile去配置hadoop和jdk的环境变量
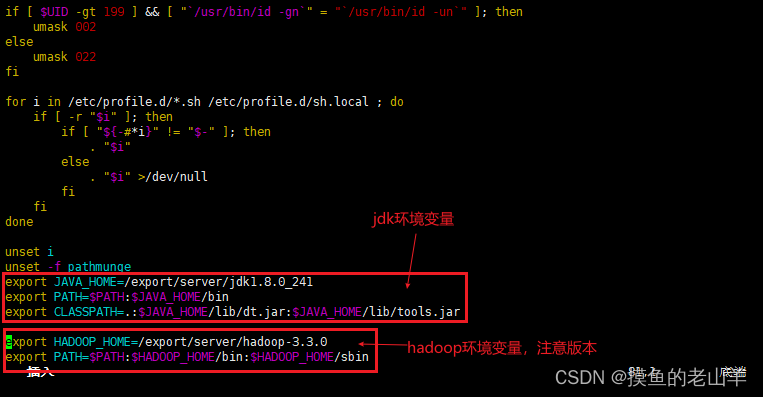
/etc/profile文档版
export JAVA_HOME=/export/server/jdk1.8.0_241 export PATH=$PATH:$JAVA_HOME/bin export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export HADOOP_HOME=/export/server/hadoop-3.3.0 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
第四步 配置服务器基础环境
-
修改Hosts映射
-
根据你集群上规划的不同的IP地址,输入IP,以下图片是以我集群的IP为例
-
![]()

-
关闭防火墙
systemctl stop firewalld.service #关闭防火墙 systemctl disable firewalld.service #禁止防火墙开启自启
-
创建统一工作目录
mkdir -p /export/data/ #数据存储路径
第五步 编辑Hadoop配置文件
| 配置文件的名称 | 作用 |
|---|---|
| core-site.xml | 核心配置文件,主要定义了我们文件访问的格式 hdfs:// |
| hadoop-env.sh | 主要配置我们的java路径 |
| hdfs-site.xml | 主要定义配置我们的hdfs的相关配置 |
| mapred-site.xml | 主要定义我们的mapreduce相关的一些配置 |
| workers | 控制我们的从节点在哪里 datanode nodemanager在哪些机器上 |
| yarm-site.xml | 配置我们的resourcemanager资源调度 |
-
hadoop-env.sh
cd /export/server/hadoop-3.3.0/etc/hadoop/ vim hadoop-env.sh
配置文件
#配置JAVA_HOME export JAVA_HOME=/export/server/jdk1.8.0_241 #设置用户以执行对应角色shell命令 export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root
-
core-site.xml
cd /export/server/hadoop-3.3.0/etc/hadoop/ vim core-site.xml
配置文件
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://node1:8020</value> </property> <!-- 设置Hadoop本地保存数据路径 --> <property> <name>hadoop.tmp.dir</name> <value>/export/data/hadoop-3.3.0</value> </property> <!-- 设置HDFS web UI用户身份 --> <property> <name>hadoop.http.staticuser.user</name> <value>root</value> </property> </configuration>
-
hdfs-site.xml
cd /export/server/hadoop-3.3.0/etc/hadoop/ vim hdfs-site.xml
配置文件
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node2:9868</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>[DISK]file://${hadoop.tmp.dir}/dfs/data,[ARCHIVE]file://${hadoop.tmp.dir}/dfs/data/archive</value>
</property>
<property>
<name>dfs.client.read.shortcircuit</name>
<value>true</value>
</property>
<property>
<name>dfs.domain.socket.path</name>
<value>/var/lib/hadoop-hdfs/dn_socket</value>
</property>
</configuration>
-
mapred-site.xml
cd /export/server/hadoop-3.3.0/etc/hadoop/ vim mapred-site.xml
配置文件
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- MR程序历史服务地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>node1:10020</value>
</property>
<!-- MR程序历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node1:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>
-
yarn-site.xml
cd /export/server/hadoop-3.3.0/etc/hadoop/ vim yarn-site.xml
配置文件
<configuration>
<!-- 设置YARN集群主角色运行机器位置 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1.itcast.cn</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 是否将对容器实施物理内存限制 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!-- 是否将对容器实施虚拟内存限制。 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 开启日志聚集 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置yarn历史服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://node1:19888/jobhistory/logs</value>
</property>
<!-- 历史日志保存的时间 7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
-
workers
cd /export/server/hadoop-3.3.0/etc/hadoop/ vim workers
配置文件
node1.itcast.cn node2.itcast.cn node3.itcast.cn
第六步 克隆及启动
-
克隆我们搭建好的第一台机器
1.克隆
进入VMware,右键点击我们的虚拟机,点击管理,再点击克隆(克隆之前需要把虚拟机关机)
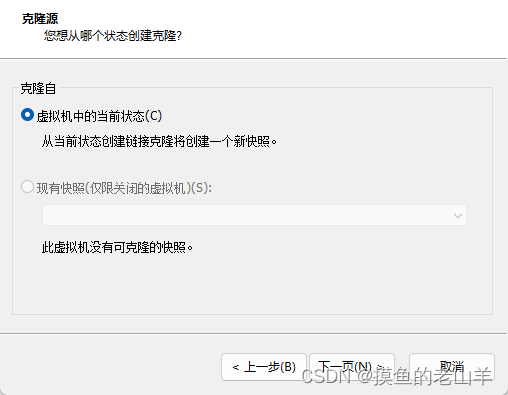
-
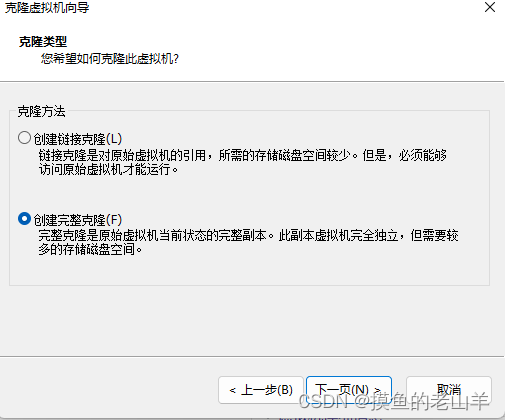
注意一定要选择完整克隆
-
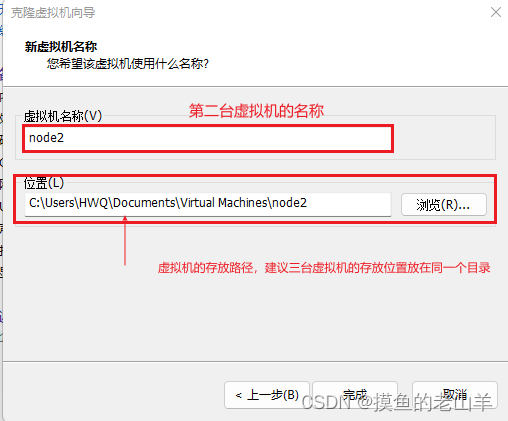
点击完成
第三台机器同理,只需要修改一下名称
2.启动配置
2.1.修改第二台和第三台机器的主机名
vim /etc/hostname
-
如果是第二台机器,就直接在里面输入node2
-
同理第三台输入node3
2.2修改第二台和第三台机器的IP
vim /etc/sysconfig/network-scripts/ifcfg-ens33
配置文件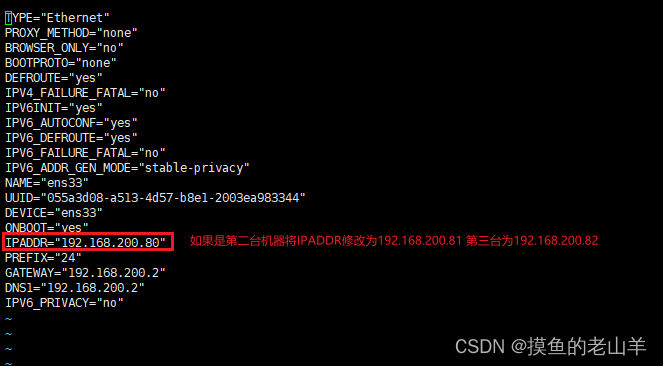
-
只需要修改IPADDR即可
3.设置免密登录
-
先把三台机器在xshell启动
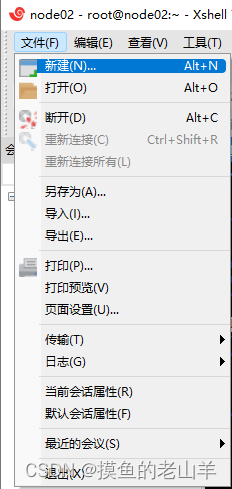
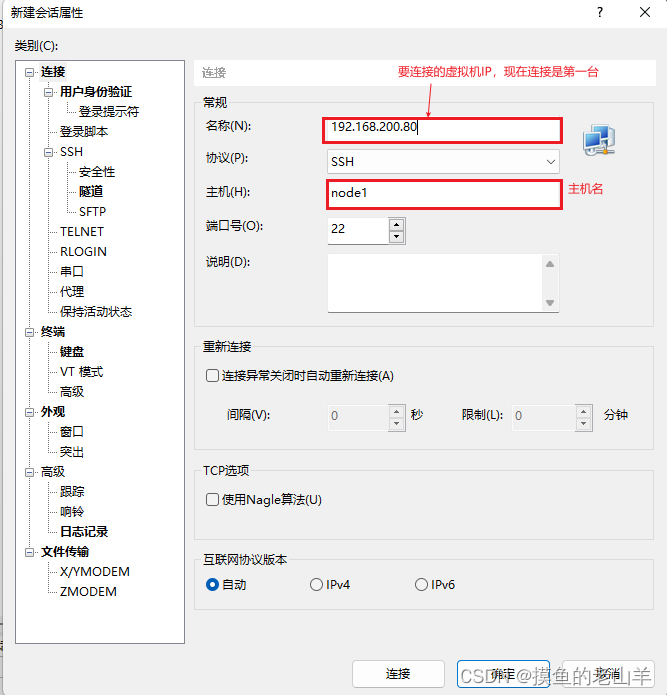

-
然后点击连接,同理操作连接第二台和第三台机器
-
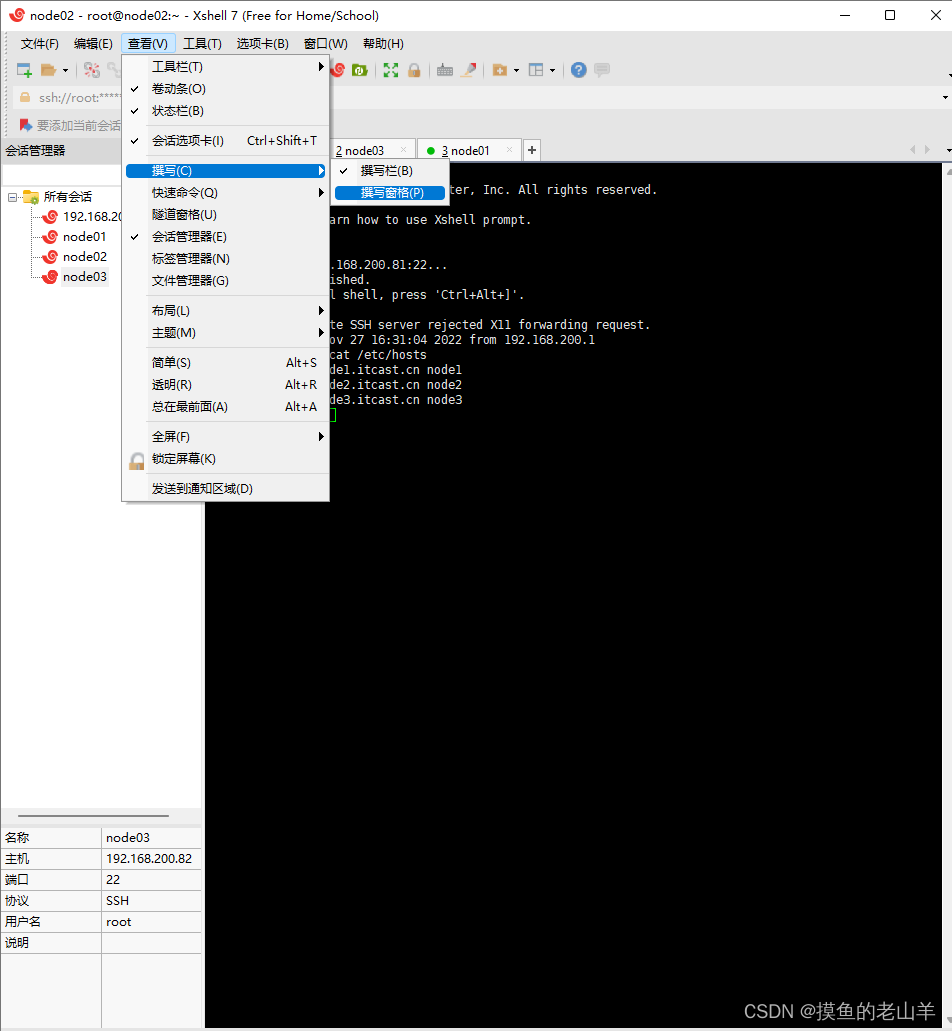
在查看中把撰写窗口打开,这样可以同时给三台机器发命令
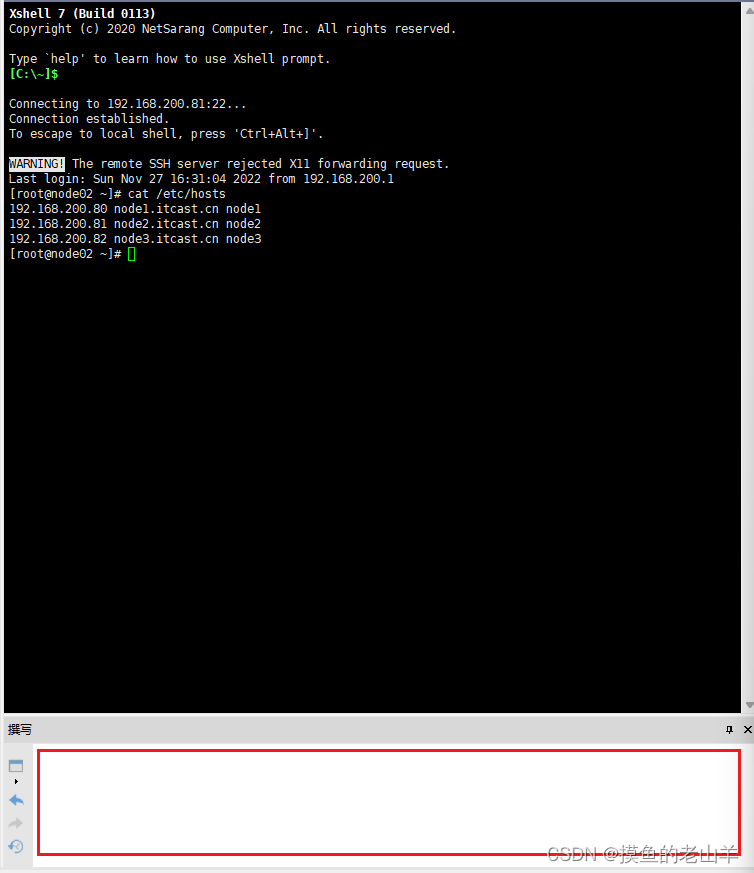
-
在撰写窗口中输入以下命令
-
ssh-keygen #连续按4个回车 生成公钥、私钥 ssh-copy-id node1、ssh-copy-id node2、ssh-copy-id node3
-
然后连按四个回车

-
给node1的机器传输公钥

-
给node2的机器传输公钥
-
给node3的机器传输公钥
4.格式化操作
-
首次启动HDFS,必须格式化(初始化)
命令
hdfs namenode -format
-
代表格式化成功,也就代表集群创建成功

总结
-
如果觉得本篇文章,有帮助到你麻烦点个收藏加关注
-
如果觉得文章看起来难懂,推荐你看一下视频教学1.集群规划哔哩哔哩bilibili
















 1949
1949











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









