






在讲解这三个I/O操作之前先普及一下I/O的基础知识,不然听后面的点会产生困惑,有基础的朋友可以从BIO开始阅读
什么是I/O操作?
I/O(Input/Output)操作指的是计算机系统与外部设备或程序之间的数据传输。I/O 操作包括读取和写入数据,用于在计算机系统和外部环境之间进行信息交换。
I/O 操作可以分为两大类:
- 输入操作(Input):
- 从外部设备或其他程序读取数据到计算机系统中。
- 例子:
- 从键盘输入数据。
- 从磁盘读取文件内容。
- 从网络接收数据。
- 输出操作(Output):
- 将计算机系统中的数据发送到外部设备或其他程序。
- 例子:
- 向屏幕打印输出信息。
- 将数据写入磁盘文件。
- 向网络发送数据。
I/O 操作是计算机系统中非常重要的一部分,因为计算机系统通常需要与外部世界进行交互。外部设备包括键盘、鼠标、磁盘驱动器、网络接口等,而程序之间的数据传输也属于 I/O 操作。
在计算机中,I/O 操作的速度相对较慢,因此在编程中,优化和有效地管理 I/O 操作对于提高系统性能和响应速度至关重要。对于高效的 I/O 操作,涉及到使用适当的 I/O 模型、缓冲、异步操作等技术。
用户空间与内核空间
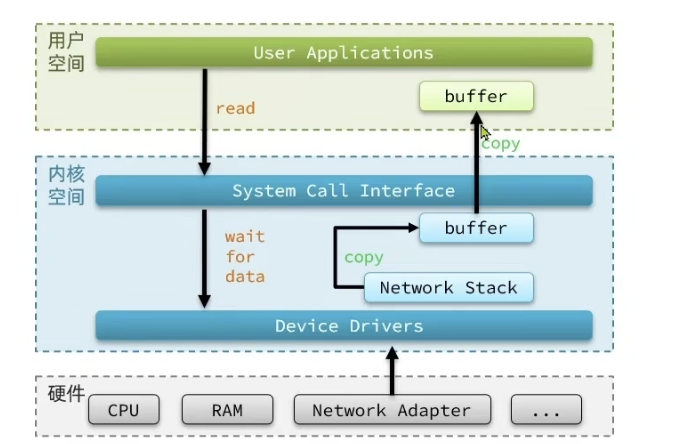
操作系统的核心是内核,独立于普通的应用程序,可以访问受保护的内存空间,也有访问底层硬件设备的所有权限。为了保证用户进程不能直接操作内核(kernel),保证内核的安全,操心系统将虚拟空间划分为两部分,一部分为内核空间,一部分为用户空间。
进程不能直接访问硬件设备,当进程需要访问硬件设备(比如读取磁盘文件,接收网络数据等等)时,必须由用户态模式切换至内核态模式,通过系统调用访问硬件设备。
文件描述符fd
文件描述符(File descriptor)是计算机科学中的一个术语,是一个用于表述指向文件的引用的抽象化概念。
文件描述符在形式上是一个非负整数。实际上,它是一个索引值,指向内核为每一个进程所维护的该进程打开文件的记录表。当程序打开一个现有文件或者创建一个新文件时,内核向进程返回一个文件描述符。在程序设计中,一些涉及底层的程序编写往往会围绕着文件描述符展开。但是文件描述符这一概念往往只适用于UNIX、Linux这样的操作系统。
应用程序中如何进行I/O操作?
我们程序中的IO读写其实调用的是操作系统内核中的read&write两大系统调用
例如使用Java通过socket进行网络I/O,也必须依赖系统内核
具体步骤:
- 网卡收到网线传来的网络数据,并将数据写入内存
- 数据写入内存后,网卡向cpu发送中断信号(通知发生特定事件的一种机制),操作系统遍能得知有新数据到来,再通过网卡中断程序去处理数据
- 将内存中的数据写入到对应的socket的接收缓冲区中
- 当接收缓冲区的数据写好后,应用程序开始进行数据处理
public class SocketServer {
public static void main(String[] args) throws Exception {
// 监听指定的端口
int port = 8080;
ServerSocket server = new ServerSocket(port);
// server将一直等待连接的到来
Socket socket = server.accept();
// 建立好连接后,从socket中获取输入流,并建立缓冲区进行读取
InputStream inputStream = socket.getInputStream();
byte[] bytes = new byte[1024];
int len;
// 此处的read操作是阻塞操作
while ((len = inputStream.read(bytes)) != -1) {
//获取数据进行处理
String message = new String(bytes, 0, len,"UTF-8");
}
// socket、server,流关闭操作,省略不表
}
}
⚠️ 以下几种IO模型的区分点在于:
- 数据等待阶段
- 将数据从内核空间的buffer拷贝到用户空间进程的buffer
阻塞IO(blocking IO)
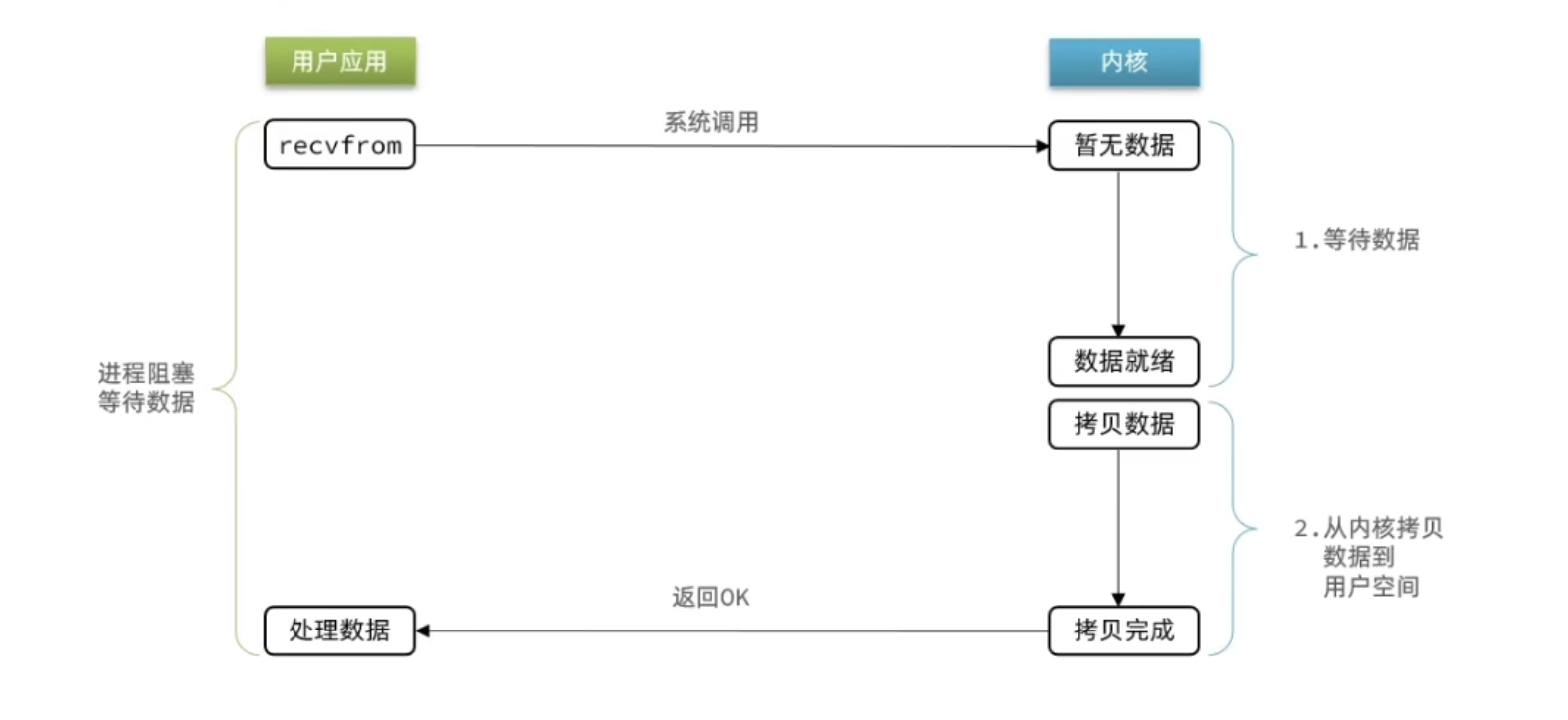
特点:在IO执行的两个阶段都被block了
造成的影响
意味着如果在等待客户端的连接或者处理读写请求时,服务端不能去做任何事情,当前操作完成,假如服务端在等待客户端的写操作,而客户端一直没响应,那么服务端就“卡死了”(不能处理其他客户端的请求)
解决方法
使用多线程,每当一个客户端连接上服务端,就专门开启一个线程处理这个客户端的请求,服务端能够正常处理每一个客户端的请求,主线程不会被阻塞
缺点:假如同时有1000个客户端同时访问服务端,就需要开启1000个线程去处理,并且这1000个线程同时阻塞等待客户端的I/O操作,严重浪费了CPU和内存的资源
总结
-
优点
- 编程模型简单,易于理解
- 适用于低并发,低负载的场景
-
缺点
- 阻塞 I/O 会导致线程被阻塞,无法应对高并发场景
- 在高并发环境下,阻塞 I/O 可能导致大量线程被创建,增加系统开销
非阻塞IO(nonblocking IO)
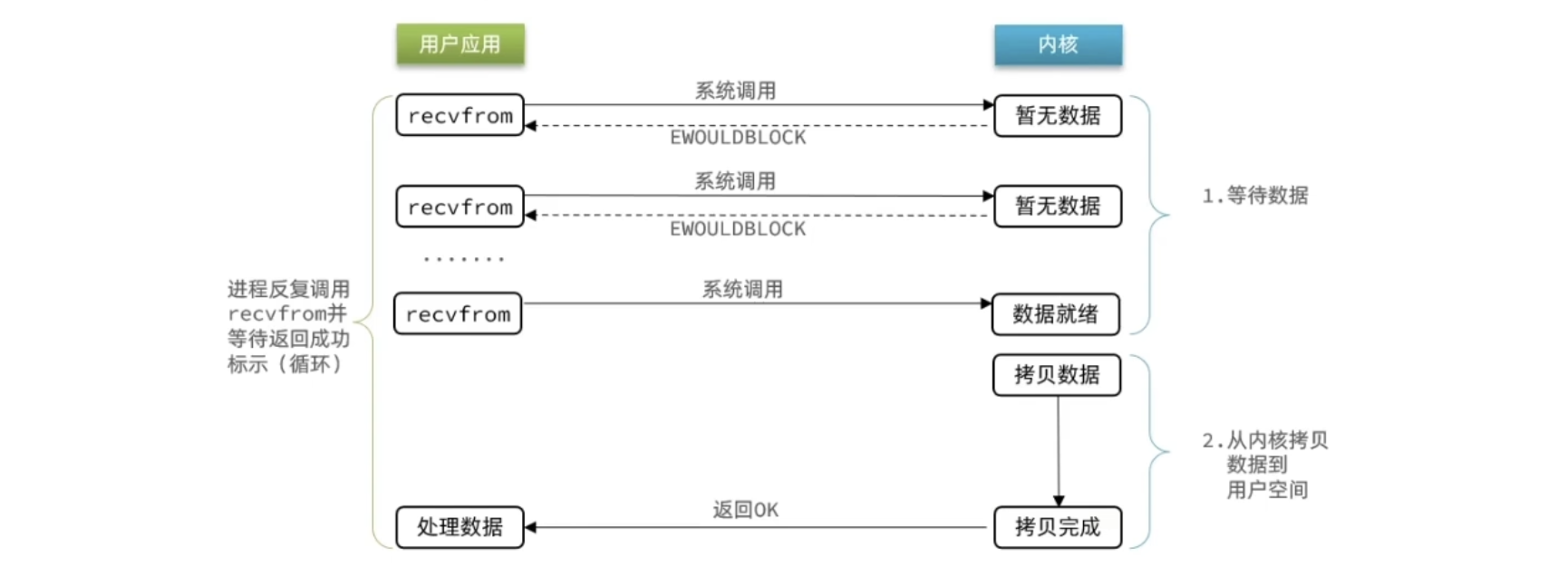
特点:如果数据尚未准备好,不会一直等待,而是一边向下执行任务一边向内核询问数据准备好了没
举个栗子
现在你是一个服务员(服务端)。当一个顾客坐下后点菜,然后开始等待他的菜做好。在这个等待的过程中,你可以去做其他事情,不需要一直等在那里,但是你需要隔一段时间就去问厨师起先顾客的菜好了吗。
优点:解决了BIO的阻塞问题,在没有I/O操作时,不会发生阻塞,会继续处理其他任务,提高并发能力
缺点:一直去轮询I/O操作是否完成,会造成CPU资源的浪费。就像是一个顾客刚点完菜,服务员就一直问菜煮好了吗?🧑🍳(内心:又不是预制菜🙄,哪有那么快),菜准备的越久,越浪费服务员的精力。
I/O多路复用
无论是阻塞I0还是非阻塞I0,用户应用在一阶段都需要调用recvfrom来获取数据,差别在于无数据时的处理方案:
- 如果调用recvfrom时,恰好没有数据,阻塞I0会使进程阻塞,非阻塞I0使CPU空转,都不能充分发挥CPU的作用。
- 如果调用recvfrom时,恰好有数据,则用户进程可以直接进入第二阶段,读取并处理数据
比如服务端处理客户端Socket请求时,在单线程情况下,只能依次处理每一个socket,如果正在处理的socket恰好未就绪(数据不可读或不可写),线程就会被阻塞,所有其它客户端socket都必须等待,性能自然会很差。
这就像服务员给顾客点餐,分两步:
- 顾客思考要吃什么(等待数据就绪)
- 顾客想好了,开始点餐(读取数据)要提高效率有几种办法?
-
方案一:增加更多服务员(多线程)
-
方案二:不排队,谁想好了吃什么(数据就绪了),服务员就给谁点餐(用户应用就去读取数据)
那么问题来了:用户进程如何知道内核中数据是否准备好了?这就需要使用上面开头说的文件描述符fd
I/O多路复用:是利用单个线程来同时监听多个FD,并在某个FD可读、可写时得到通知,从而避免无效的等待,充分利用CPU资源。
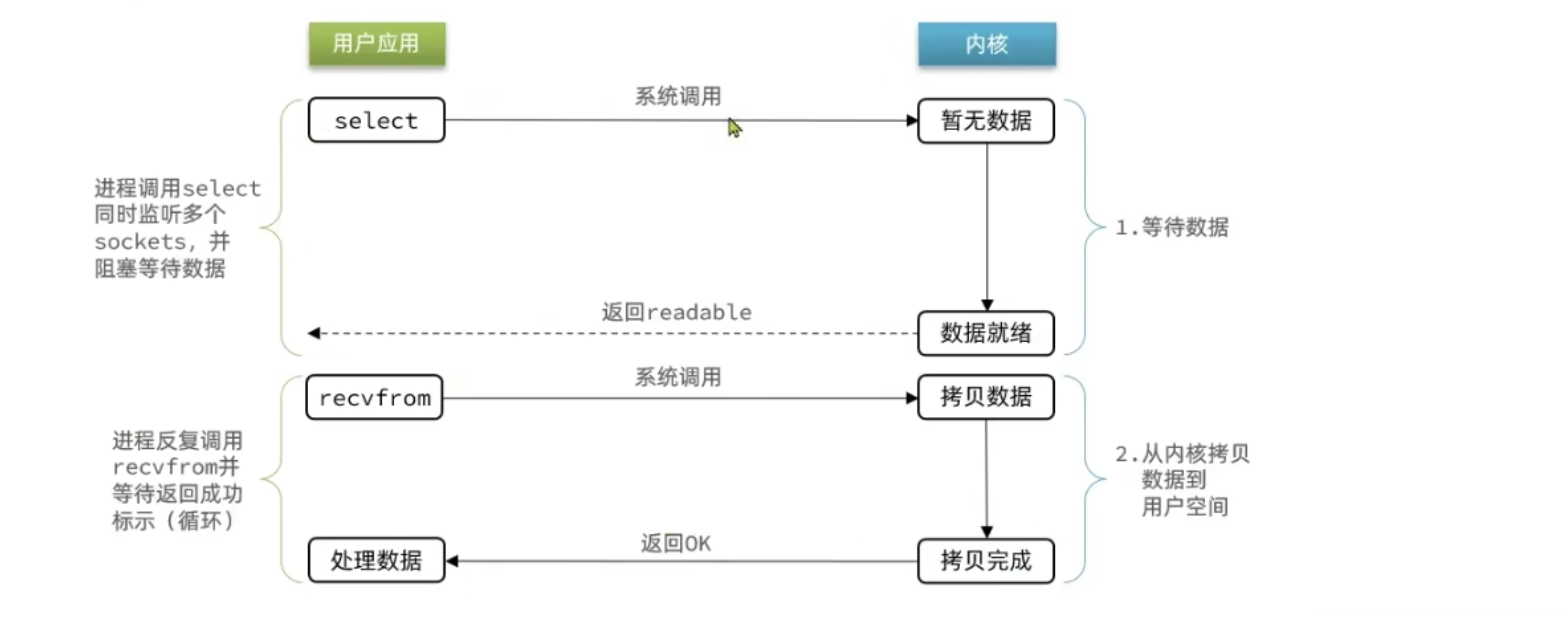
问题:
在IO多路复用的时候,处理数据的两个阶段都需要阻塞等待,那与非阻塞又有什么区别呢?
答:非阻塞的痛点在于什么?虽然解决了单个线程在进行I/O时会被阻塞的问题,但是依然没有解决单线程下无法处理多个socket的问题。但是I/O多路复用可以同时处理多个socket。
I/O多路复用模型的实现
select
//定义类型别名_-fd_mask,本质是longint
typedef long int __fd_mask;
/*fd_set记录要监听的fd集合,及其对应状态*/
typedef struct {
//fds_bits是long类型数组,长度为1024/32=32
//共1024个bit位,每个bit位代表一个fd,0代表未就绪,1代表就绪
__fd_mask fds_bits[__FD_SETSIZE / __NFDBITS] ;
//...
}fd_set;
//select函数,用于监听多个fd的集合
int select(
intnfds,//要监视的fd_set的最大fd+1
fd_set*readfds,//要监听读事件的fd集合
fd_set*writefds,//要监听写事件的fd集合
fd_set*exceptfds,// 要监听异常事件的fd集合
//超时时间,null-永不超时;0-不阻塞等待;大于0-固定等待时间
struct timeval *timeout
);
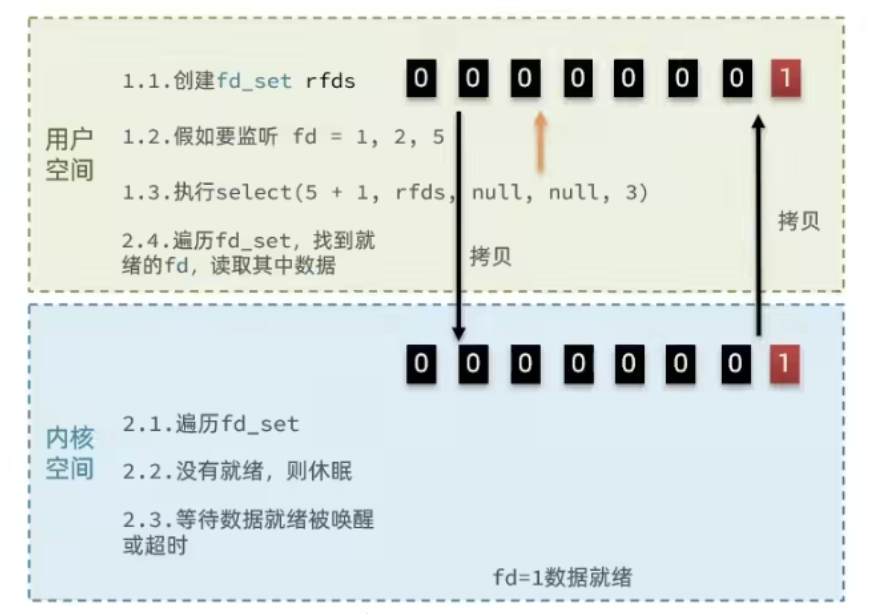
select存在的问题:
- 需要将整个fd_set从用户空间拷贝到内核空间,select结束还要再次拷贝回用户空间
- select无法得知具体是哪个fd就绪,需要遍历整个fd_set
- fd_set监听的fd数量不能超过1024
当用户调用了select,那么整个进程会被block,而同时,系统会监视所有select负责的socket,当任何一个socket的数据准备好了,select就会返回。
poll
//pollfd中的事件类型
#define POLLIN //可读事件
#define POLLOUT //可写事件
#define POLLERR //错误事件
#define POLLNVAL //fd未打开
//pollfd结构
struct pollfd{
/*要监听的fd*/
short int events;/*要监听事件类型:读、写、异常*/
short int revents;/*实际发生的事件类型*/
};
//Poll函数
int poll (
struct pollfd* fds,//pollfd数组,可以自定义大小
nfds_t nfds,//数组元素个数
int timeout//超时时间
);
I0流程:
- 创建pollfd数组,向其中添加关注的fd信息,数组大小自定义
- 调用poll函数,将pollfd数组拷贝到内核空间,转链表存储,无上限
- 内核遍历fd,判断是否就绪
- 数据就绪或超时后,拷贝polfd数组到用户空间,返回就绪fd数量n
- 用户进程判断n是否大于0
- 大于0则遍历pollfd数组,找到就绪的fd
与select对比:
- 优点:select模式中的fd_set大小固定为1024,而pollfd在内核中采用
链表,理论上无上限 - 缺点:监听FD越多,每次遍历消耗时间也越久
epoll
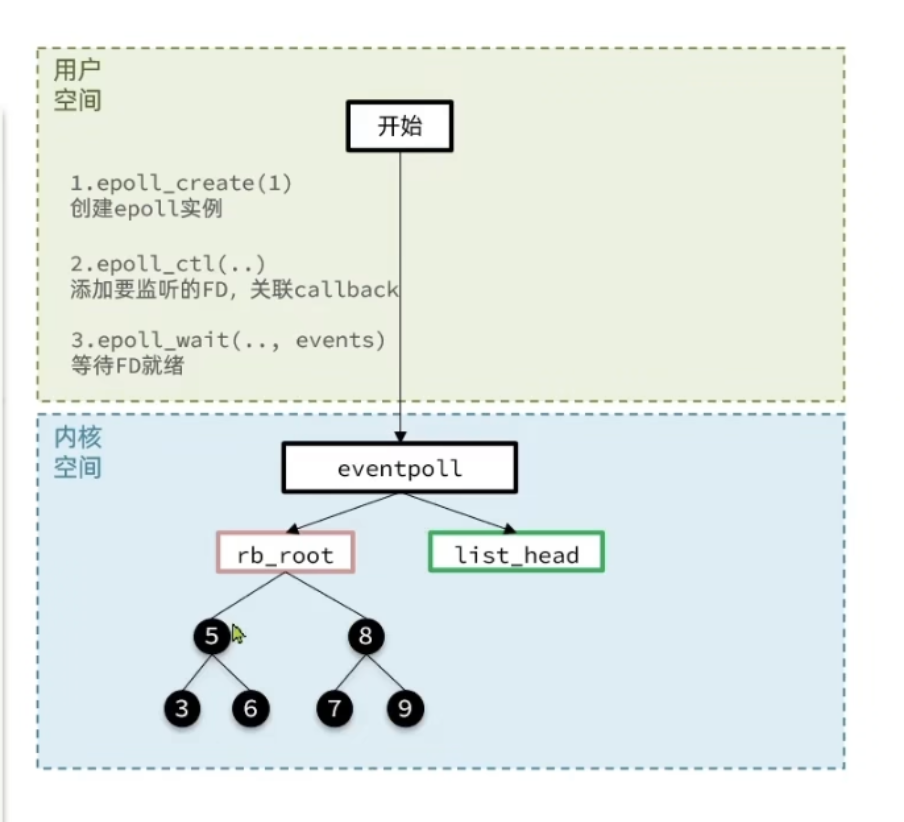

步骤
- 创建epoll实例
- 添加要监听的FD到红黑树,关联callback
- epoll_wait等待FD就绪,如果有FD就绪后,会将FD添加到list_head中,在用户调用epoll_wait后就会将这些就绪的FD拷贝到event数组中,相比于前两种监听模式,epoll不需要遍历所有的FD集合就知道哪些FD就绪
总结
select模式存在的三个问题:
- 能监听的FD最大不超过1024
- 每次select都需要把所有要监听的FD都拷贝到内核空间
- 每次都要遍历所有的FD来判断就绪状态
poll存在的问题:
- poll虽然解决了select监听FD上限的问题,但是随着监听FD数量的上升,性能反而会下降
epoll如何解决这些问题:
解决FD上限问题:基于epoll实例中的红黑数保存要监听的FD,理论上无上限,而增删改查销量都非常高,性能不会随着FD数量增多反而下降
FD拷贝问题:每一个FD只需要执行一次epoll_ctl添加到红黑树,以后每次epoll_wait无需传递任何参数,无需重复拷贝FD到内核空间
查找FD效率低问题:内核会将就绪的FD直接拷贝到用户空间的指定位置,用户进程无需遍历所有FD就能知道就绪的FD是谁
异步IO(async IO)
上面三种IO模型都有一个共同的缺点:当系统中数据准备好的时候,recvfrom会将数据从内核空间拷贝到用户内存中,在这段时间内,进程是被阻塞的
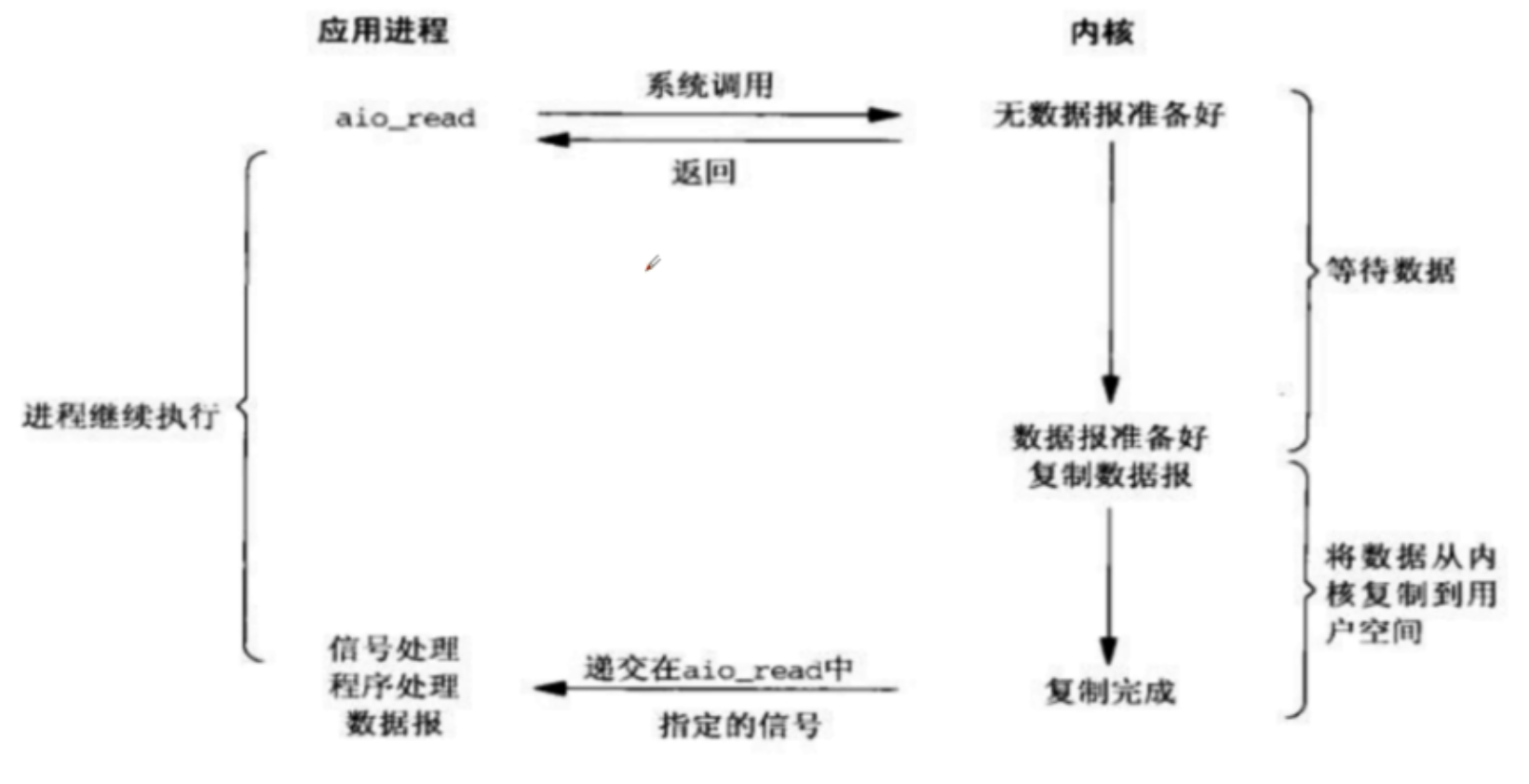
AIO 就是用来解决数据拷贝阶段的阻塞问题
- 同步意味着,在进行读写操作时,线程需要等待结果,还是相当于闲置
- 异步意味着,在进行读写操作时,线程不必等待结果,而是将来由操作系统来通过回调方式由另外的线程来获得结果
异步模型需要底层操作系统(Kernel)提供支持
- Windows 系统通过 IOCP 实现了真正的异步 IO
- Linux 系统异步 IO 在 2.6 版本引入,但其底层实现还是用多路复用模拟了异步 IO,性能没有优势
异步IO整个操作都是非阻塞的,用户进程调用完异步API后就可以去做其它事情,内核等待数据就绪并拷贝到用户空间后才会递交信号,通知用户进程















 2692
2692











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









