







处理数据样式如下:
01 reuturn_periods函数说明
def return_periods(data, years=[10, 20, 30, 50, 80, 100]):
data = np.array(data) # data为ndarray格式
# Fit the generalized extreme value distribution to the data.
shape, loc, scale = genextreme.fit(data)
print("Fit parameters:")
print(f" shape: {shape:.4f}")
print(f" loc: {loc:.4f}")
print(f" scale: {scale:.4f}")
# Compute the return levels for several return periods.
P_years = np.array(years)
return_levels = genextreme.isf(1 / P_years, shape, loc, scale)
print("P_years:")
print("Period Level")
for period, level in zip(P_years, return_levels):
print(f'{period:4.0f} {level:9.2f}')
return return_levels
这个函数实际上是基于给定数据(单列数据),利用scipy.stats.genextreme对数据进行拟合,找到最适合数据的GEV分布参数:形状参数(shape)、位置参数(loc)和尺度参数(scale),这三个参数共同定义了一个GEV分布,它可以描述极值事件的概率分布特征。(值得注意的是,形状参数shape对分布类型的影响很大:shape > 0 对应Frechet分布,shape = 0 对应Gumbel分布,shape < 0 对应Weibull分布。不同类型的分布适用于不同的极端事件类型。),接着基于拟合得到的GEV分布确定特定返回周期下的极值水平。
那么这个函数到底在干什么?说人话就是:
我给你一部分时间序列数据,那么你可以依据这个部分时间序列找出一些规律和分布,并告诉我假定有这么一场极端事件或者灾难,那么它的强度将达到多少呢?
科学一点就是:
基于提供的时间序列数据,我们将采用统计学方法分析其规律和分布特性。通过拟合广义极值分布(GEV),我们可以估计特定返回周期下极端事件的强度。这一分析将帮助我们理解在给定的时间跨度内,极端事件发生时可能达到的最大强度。
那么运行结果将类似下方:
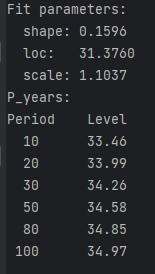
他输出的是当前循环列数据下基于GEV拟合得到10年一遇、20年一遇、30年一遇···的极端事件该数据值(例如降水值、温度值)达到的强度值、以及基于该数据拟合得到的GEV分布的分布特征:shape、loc、scale值。
Note:此处的10年一遇并非准确描述,它实际上是一个通俗的理解,但未必准确,应该说是如果有一个极端事件,这个极端事件每年有10%的概率(超越概率)会发生,那么这个极端事件的强度水平有多大?所以前面的P_years 实际上是指的是给定返回周期的超越概率。
02 GEV/GEV_Gumbel函数说明
def GEV_Gumbel(data):
# sigma0 = np.std(data)
# avr0 = np.mean(data)
# Cv0 = sigma0 / avr0
# print("avr:", avr0,"Cv:", Cv0)
shape, loc, scale = genextreme.fit(data)
c = 0
GEV_f = (1 - genextreme.cdf(data, c, loc=loc, scale=scale)) * 100
# shape = 0, GEV1, Gumbel distribution
# shape > 0, GEV2, Fréchet distribution
# shape < 0, GEV3, Weibull distribution
return GEV_f
GEV函数与上述GEV_Gumbel函数区别仅在于c = shape,c=0即将其视为标准的Gumbel分布。
那么这个函数在进行何种处理呢?genextreme.fit在对单列数据进行GEV分布拟合,得到该分布的分布特征,然后使用genextreme.cdf累积分布函数基于得到的GEV分布特征,对传入的单列数据的每一值进行计算,给出对于当前数据值的非超越概率(*100 百分化),再用1减去意为超越概率,也就是说,当前值发生的概率有多大。
例如,某个站点的在某天发生了降水事件,日降水值是300mm,那么我们通过GEV分布得知它的非超越概率是95%,那么超越概率就是5%,也就是说,这次降水事件发生的概率是5%,换言之,在所有降水事件,几乎有95%的降水事件的强度都小于此次降水的强度。
03 主程序说明
if __name__ == '__main__':
out_path = r'I:\ObjectRS\软著_绘姐\SC2_ReturnPeriod'
data = pd.read_csv(r'I:\ObjectRS\软著_绘姐\SC2_ReturnPeriod\TJ2st_TEM_WIN_WO_snow.csv')
# data为ndarray格式
Years = pd.DataFrame([10, 20, 30, 50, 80, 100])
Return = Years
data_f = data
for i in range(1, 13):
print(i)
var = data.iloc[:, i].dropna(axis=0)
bd = pd.DataFrame(return_periods(var))
Return = pd.concat([Return, bd], axis=1)
Return.to_csv('I:\ObjectRS\软著_绘姐\SC2_ReturnPeriod\Return_TEM_WIN_snow_P.csv')
var = data.iloc[:, 1].dropna(axis=0)
sigma = np.std(var)
avr = np.mean(var)
Cv = sigma / avr
# f0 = GEV(var)
f0 = GEV_Gumbel(var)
fig, ax = plt.subplots(figsize=(8, 8))
ax.scatter(f0, var)
# add a grid(only horizontal lines)
# ax.grid(axis='y', alpha=0.8, linestyle='--')
ax.grid(alpha=0.8, linestyle='--')
# # add scale
ax.axis([0,100,28,38])
ax.set_xticks(range(0, 110, 10))
ax.set_yticks(range(28, 39, 1)) #useless!
ax.tick_params(labelsize=18)
ax.set_xlabel('P频率(%)', fontsize=18)
ax.set_ylabel('气温(℃)', fontsize=18)
z = np.polyfit(f0, var,1)
p = np.poly1d(z)
ax.plot(f0, p(f0), "k-")
ax.text(50, 37, f"均值={round(avr, 2)}, Cv = {round(Cv,2)}", fontsize=18)
# plt.show()
# save fig
fig.savefig(out_path + r'\JH_TEMmax.png', dpi=300)
3.1 计算特定返回周期的返回水平
out_path = r'I:\ObjectRS\软著_绘姐\SC2_ReturnPeriod'
data = pd.read_csv(r'I:\ObjectRS\软著_绘姐\SC2_ReturnPeriod\TJ2st_TEM_WIN_WO_snow.csv')
# data为ndarray格式
Years = pd.DataFrame([10, 20, 30, 50, 80, 100])
Return = Years
data_f = data
for i in range(1, 13):
print(i)
var = data.iloc[:, i].dropna(axis=0)
bd = pd.DataFrame(return_periods(var))
Return = pd.concat([Return, bd], axis=1)
Return.to_csv('I:\ObjectRS\软著_绘姐\SC2_ReturnPeriod\Return_TEM_WIN_snow_P.csv')
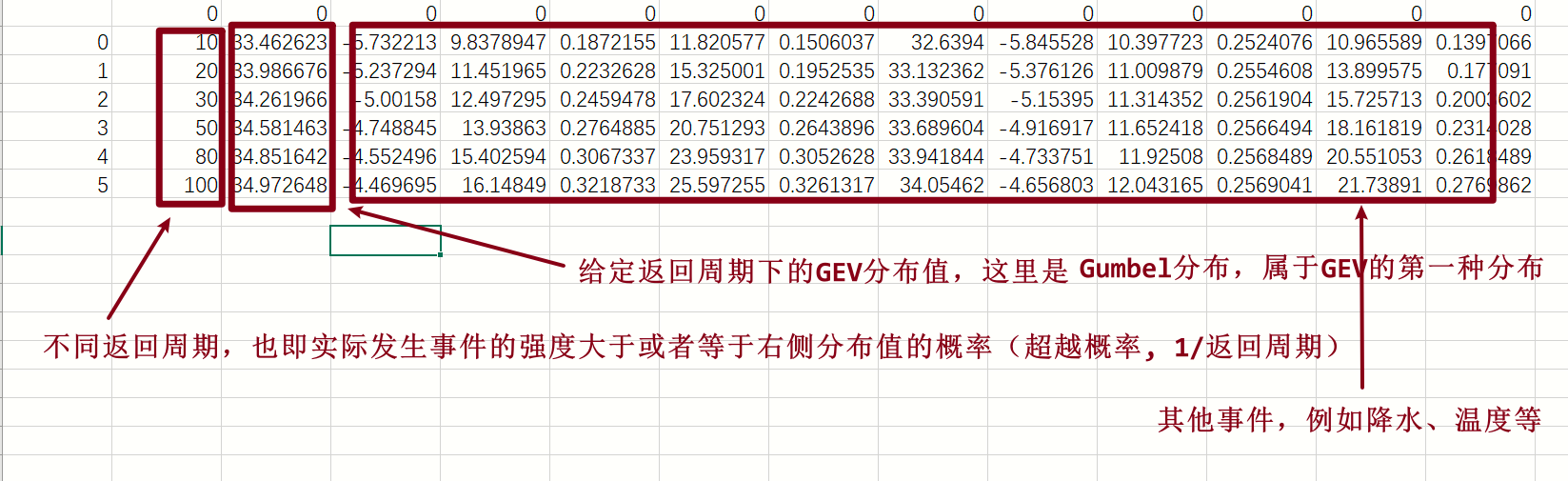
上述代码,思路非常清晰,就是计算各个列标签(不同标签指示不同观测值例如温度、降水等)下各个返回周期的返回水平(或者说在1/返回周期这个超越概率下的GEV分布值,例如返回周期是10,那么将得到有10%的超越概率给定测量值会超越这个极值水平)。
输出结果如下:
3.2 计算变异系数、均值以及绘制气温和超越概率关系图
var = data.iloc[:, 1].dropna(axis=0)
sigma = np.std(var)
avr = np.mean(var)
Cv = sigma / avr
# f0 = GEV(var)
f0 = GEV_Gumbel(var)
fig, ax = plt.subplots(figsize=(8, 8))
ax.scatter(f0, var)
# add a grid(only horizontal lines)
# ax.grid(axis='y', alpha=0.8, linestyle='--')
ax.grid(alpha=0.8, linestyle='--')
# # add scale
ax.axis([0,100,28,38])
ax.set_xticks(range(0, 110, 10))
ax.set_yticks(range(28, 39, 1)) #useless!
ax.tick_params(labelsize=18)
ax.set_xlabel('P频率(%)', fontsize=18)
ax.set_ylabel('气温(℃)', fontsize=18)
z = np.polyfit(f0, var,1)
p = np.poly1d(z)
ax.plot(f0, p(f0), "k-")
ax.text(50, 37, f"均值={round(avr, 2)}, Cv = {round(Cv,2)}", fontsize=18)
# plt.show()
# save fig
fig.savefig(out_path + r'\JH_TEMmax.png', dpi=300)
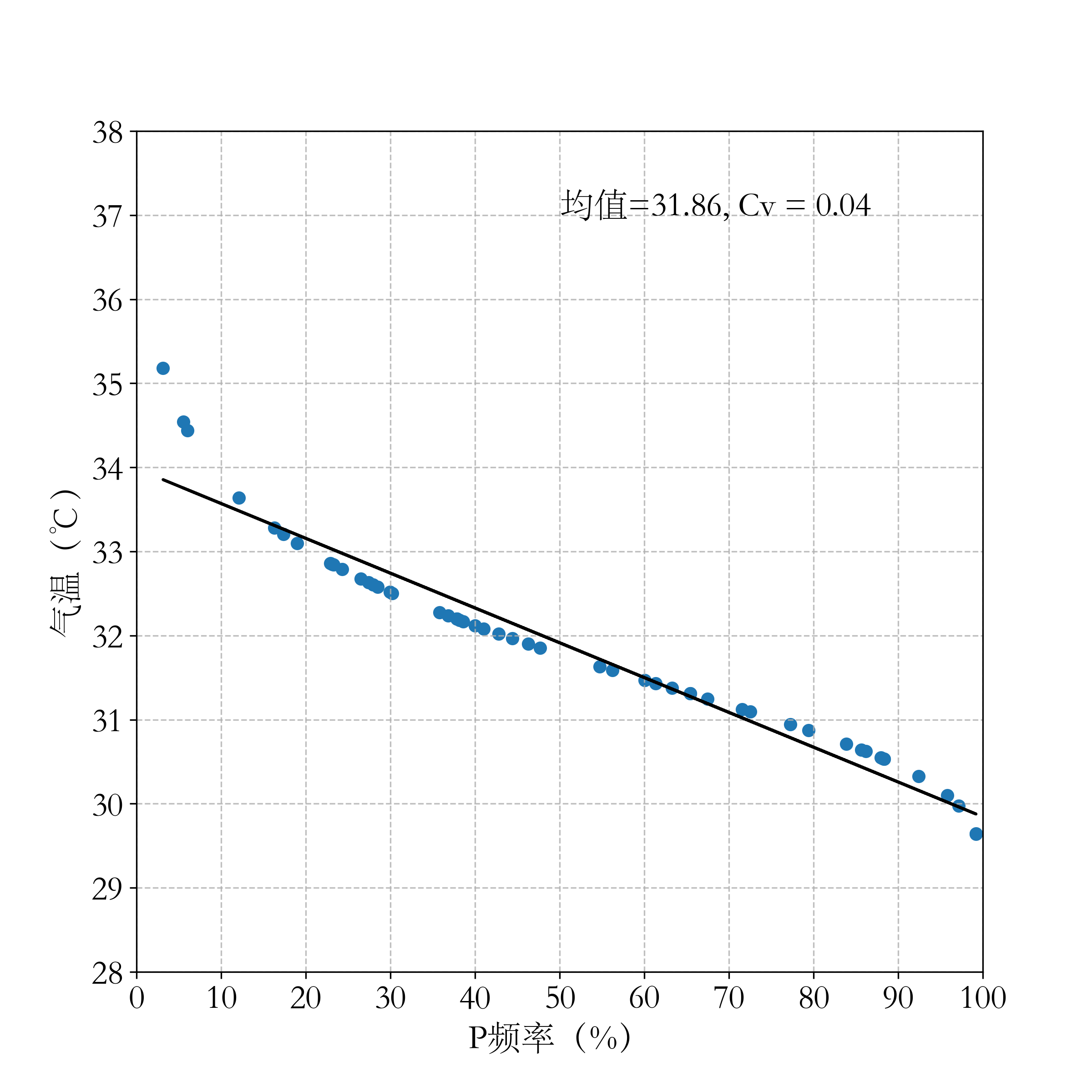
这部分代码就是计算个均值、然后变异系数(标准差/均值,表示单列数据相对于平均值的差异程度,即数据的离散程度),接着计算各个数据点的超越概率即发生的概率与该数据点的散点图,并进行线性拟合。
输出结果如下:
















 4878
4878











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











