







文章目录
iGPU是什么?
首先,我们普及以下iGPU的概念, iGPU, 全称为集成图形处理单元(Integrated Graphics Processing Unit),是一种嵌入在中央处理器(CPU)内部的图像处理单元。
与独立显卡相比,iGPU通常性能较低,但它具有低功耗、低成本和便携性等优势。
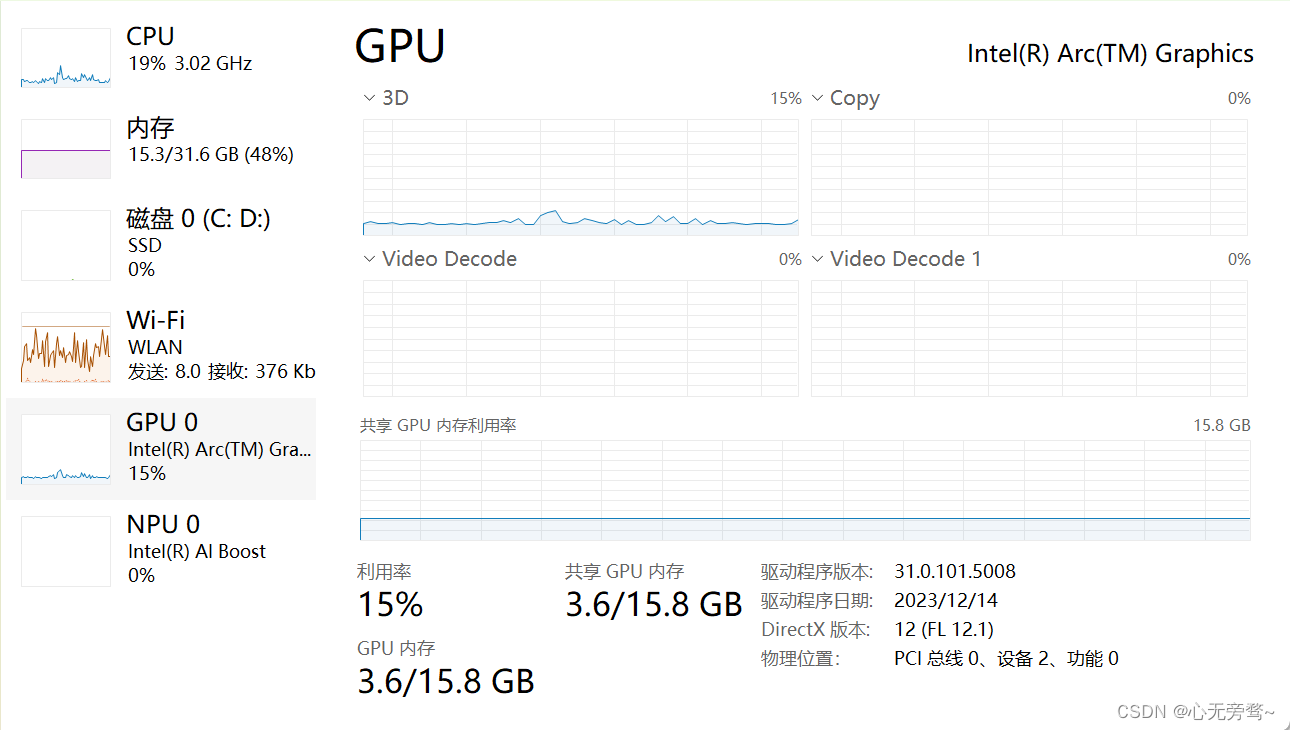
iGPU内存是指集成显卡(iGPU)使用的内存,通常嵌入在CPU或APU芯片中,与CPU共享内存,用于处理图形和视频等任务。iGPU内存可以是动态随机存储器(DRAM)或静态随机存储器(SRAM)类型,DRAM类型的iGPU内存可以被访问和修改,而SRAM类型的iGPU内存速度更快,但容量通常较小且不可修改。iGPU内存的容量通常取决于使用的处理器型号和制造商,例如英特尔的iGPU内存容量通常在1GB到2GB之间,而AMD的iGPU内存容量则较高,通常在2GB到8GB之间。这次博主使用的iGPU是联想最新推出的2024款联想小新Pro 16寸。
该电脑配置有32G的运行内存,共享GPU内存更是高达16G,甚至还配置有16G的NPU。
一、环境准备
1.1 Visual Studio 2022 Community 安装
安装点击此处👉:Visual Studio 2022 Community安装链接
安装的时候将使用C++的桌面开发选项选中。注意:如果C盘空间充足就直接安装到C盘,实在太少就安装到其他盘,但是还需配置一遍环境变量比较麻烦。
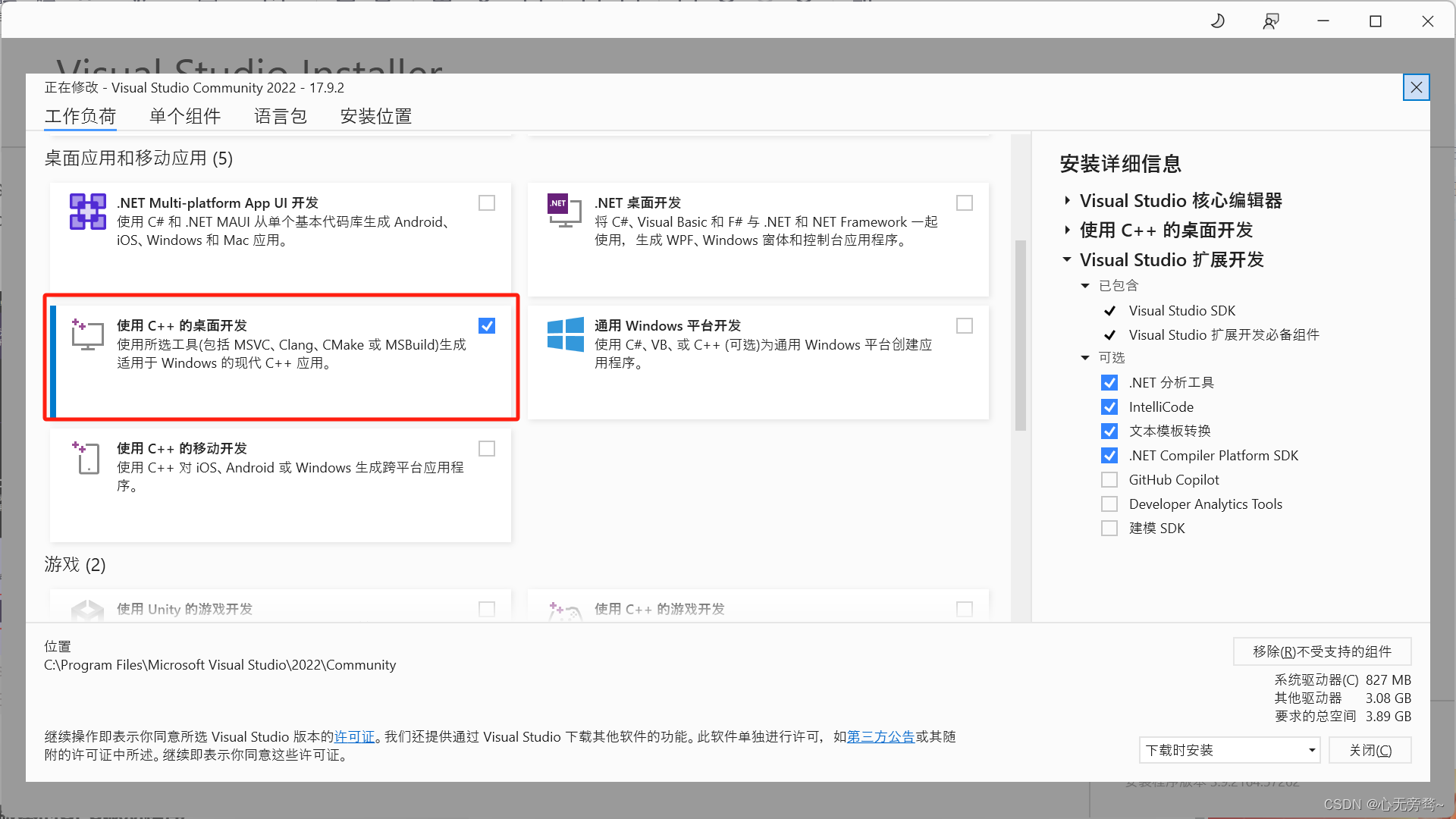
然后点击右下角的安装即可(这里我已经安装成功,所以没有安装选项)。
1.2 安装或更新最新版本的GPU驱动程序
这个操作一般都不需要,买的新电脑驱动应该是最新版的,详细可见:GPU和NPU驱动安装与配置说明
1.3 安装英特尔oneAPI工具包2024.0版本
安装点击此处👉:oneAPI工具包安装链接
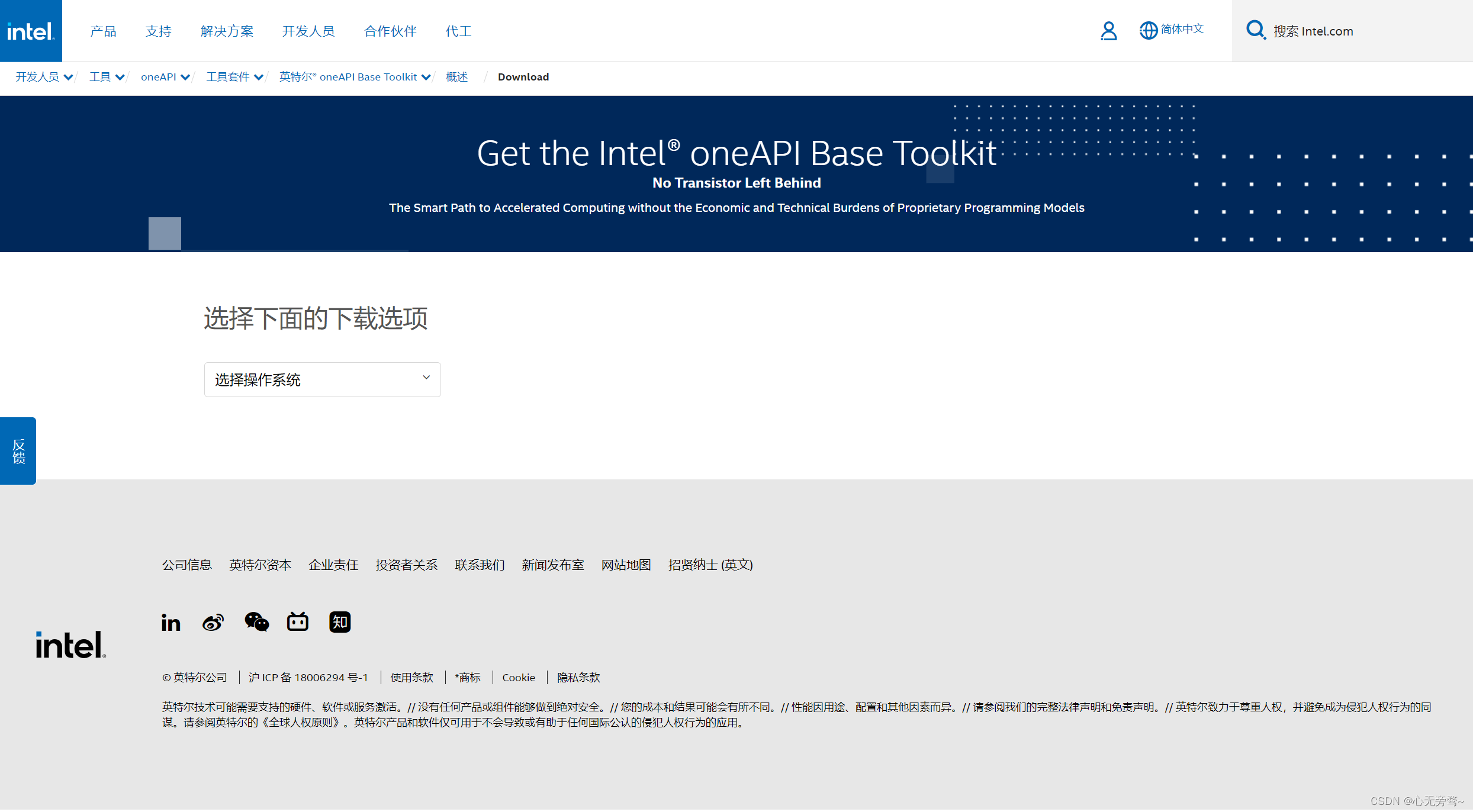
进来后选择操作系统,这里我们选Windows,以及Online install下载,也就是在线下载。
然后,翻到下面点击
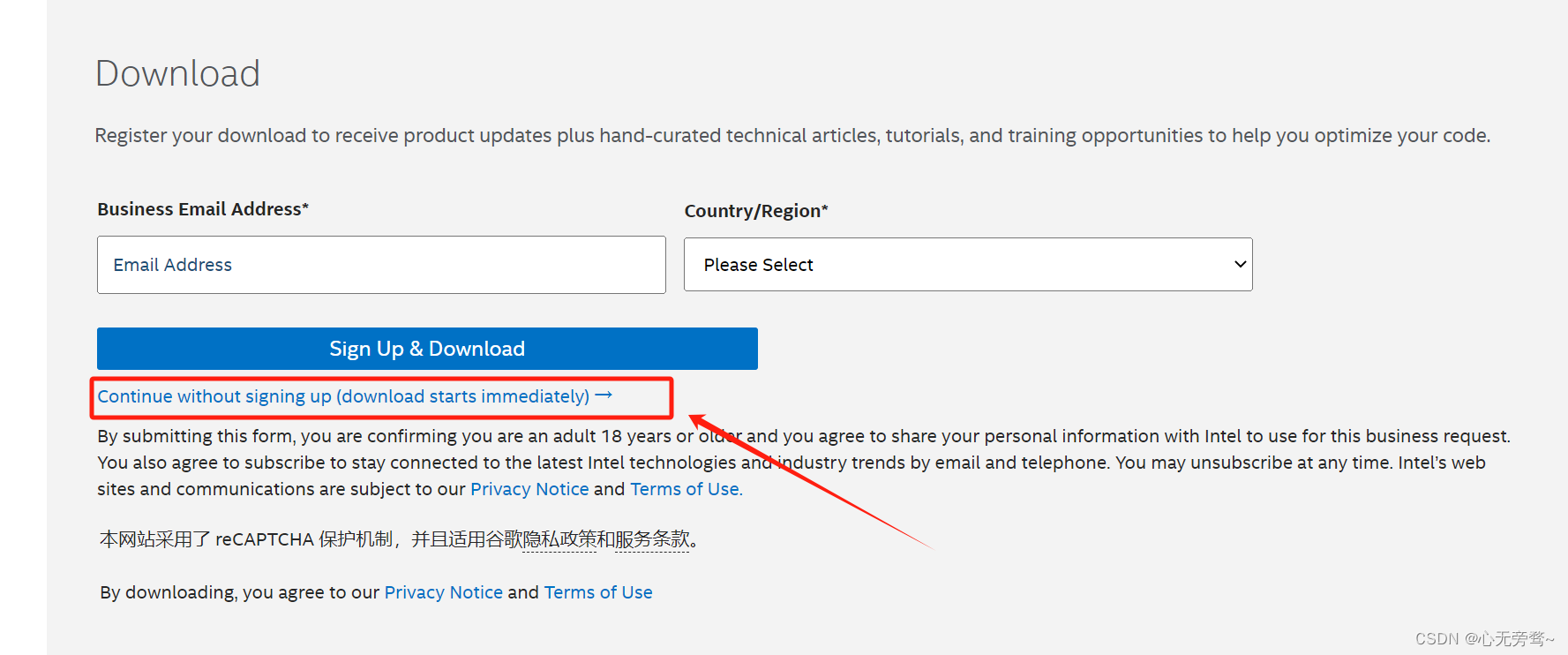
这里可能浏览器会阻止弹窗,那就不能下载成功,可以将弹窗阻止关闭。
1.4 安装Anaconda
安装点击此处👉:最新版本Anaconda安装地址
注意:如果电脑内存有限,建议安装miniconda,方法差不多,具体教程可以自行上网搜索,本篇博客就不再详细叙述。

如果嫌下载慢的话,也可以使用清华大学的软件镜像网站,点击此处👉清华大学软件镜像网站地址


下载完成后,我们点击安装包,开始进行安装。




这里可以换一下安装路径到D盘,默认的是C盘。


最新版本安装时间有点长,静静等待即可。


以上两个,取消勾选,不然会打开网站和Anaconda导航工具。
步骤如下:此电脑----->属性----->高级系统设置----->环境变量----->path----->编辑----->新建(好多软件都是这里配置环境变量,大家应该不陌生),懒得话直接按win键,搜索“环境变量”。




配置好环境以后,我们进行测试一下。

返回版本就说明已经配置成功。
二、BigDL -LLM 安装
首先,请先创建一个python 3.9环境,上面我们已经安装了Anaconda,这里直接使用。
请注意:bigdl-llm 支持python 3.9, 3.10以及3.11。为了最佳使用体验,建议使用 python 3.9版本。
2.1 创建虚拟环境
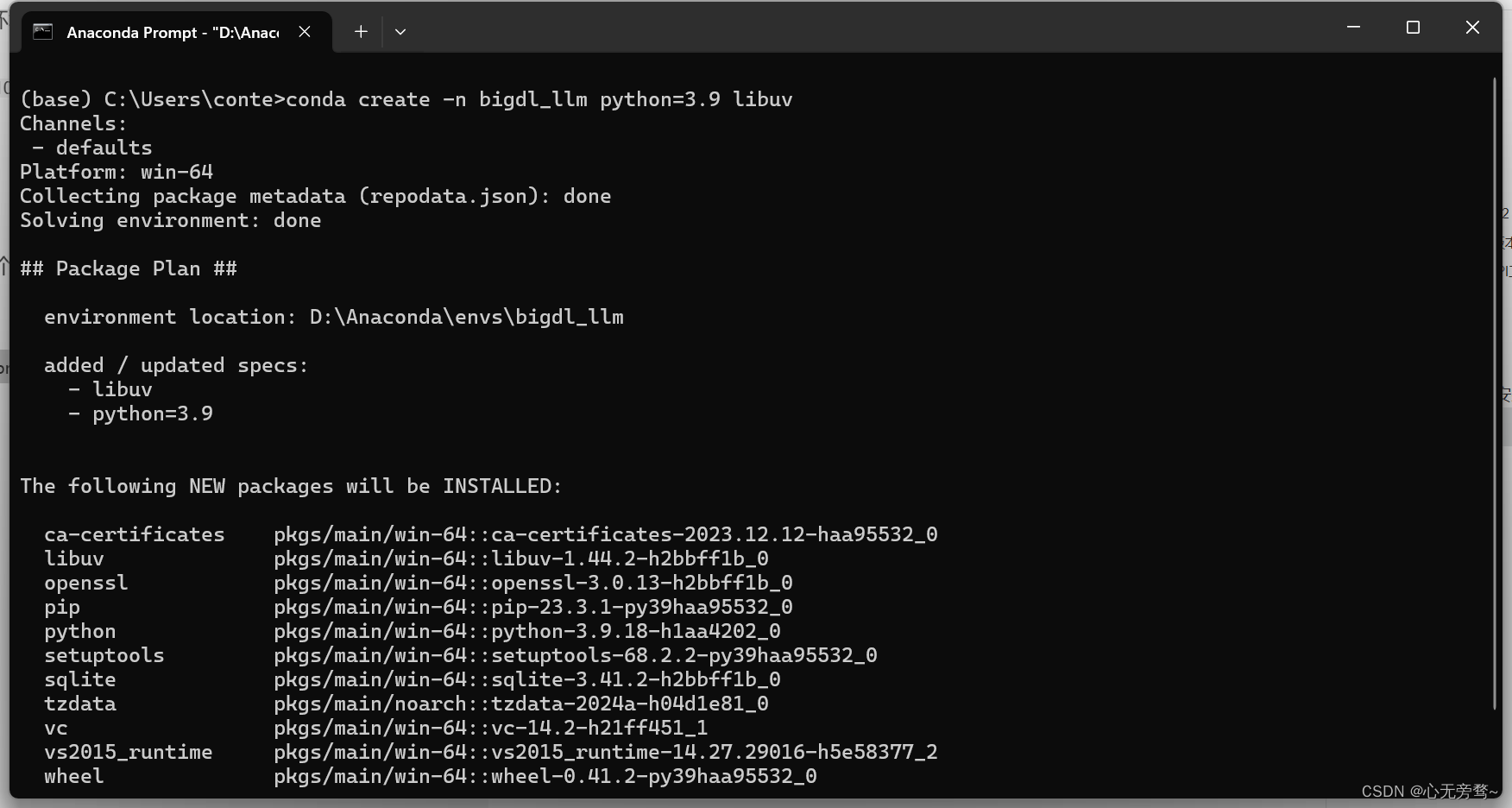
打开 Anaconda Prompt 先创建一个虚拟环境。
conda create -n bigdl_llm python=3.9 libuv
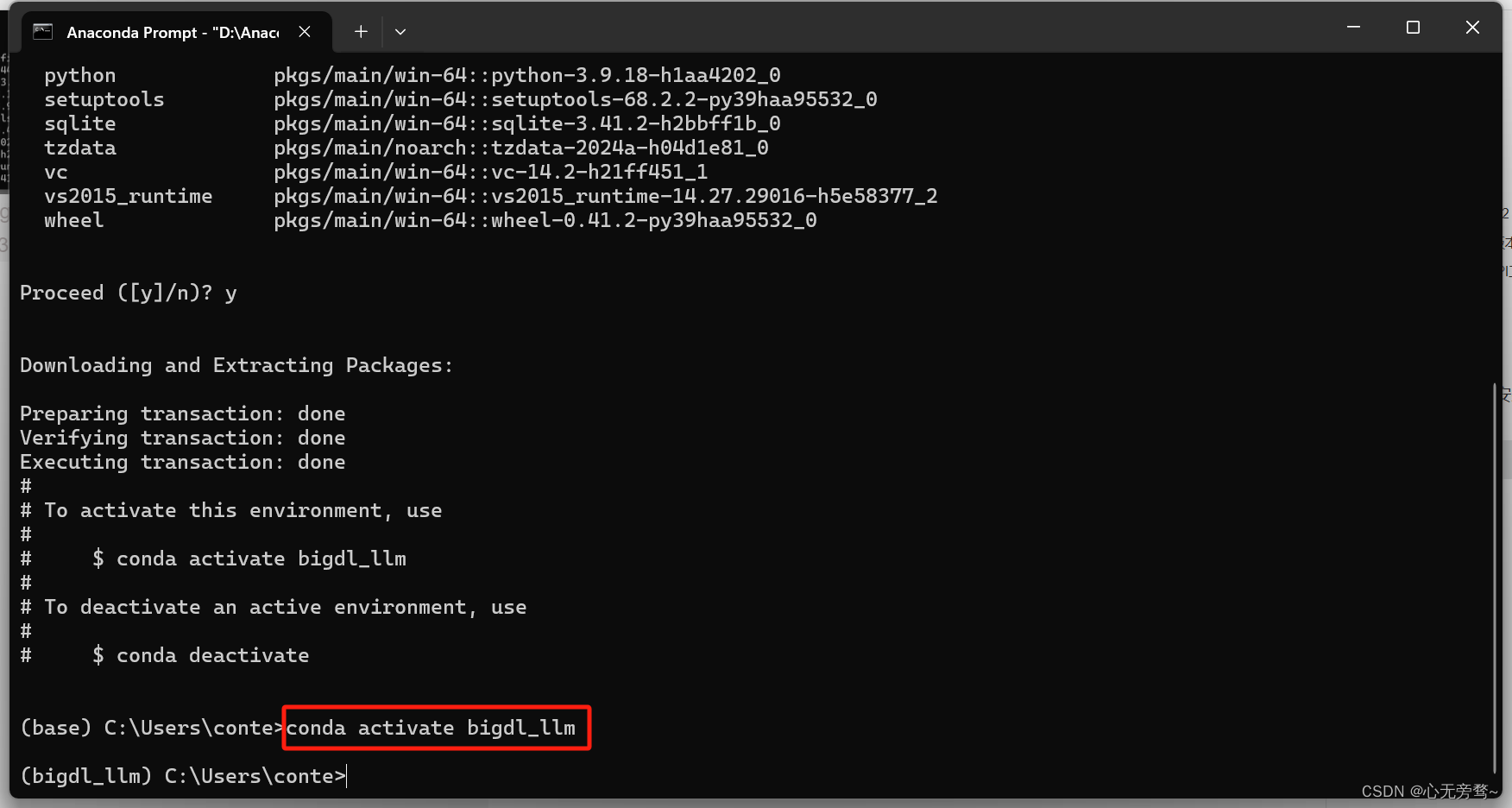
2.2 激活虚拟环境
conda activate bigdl_llm
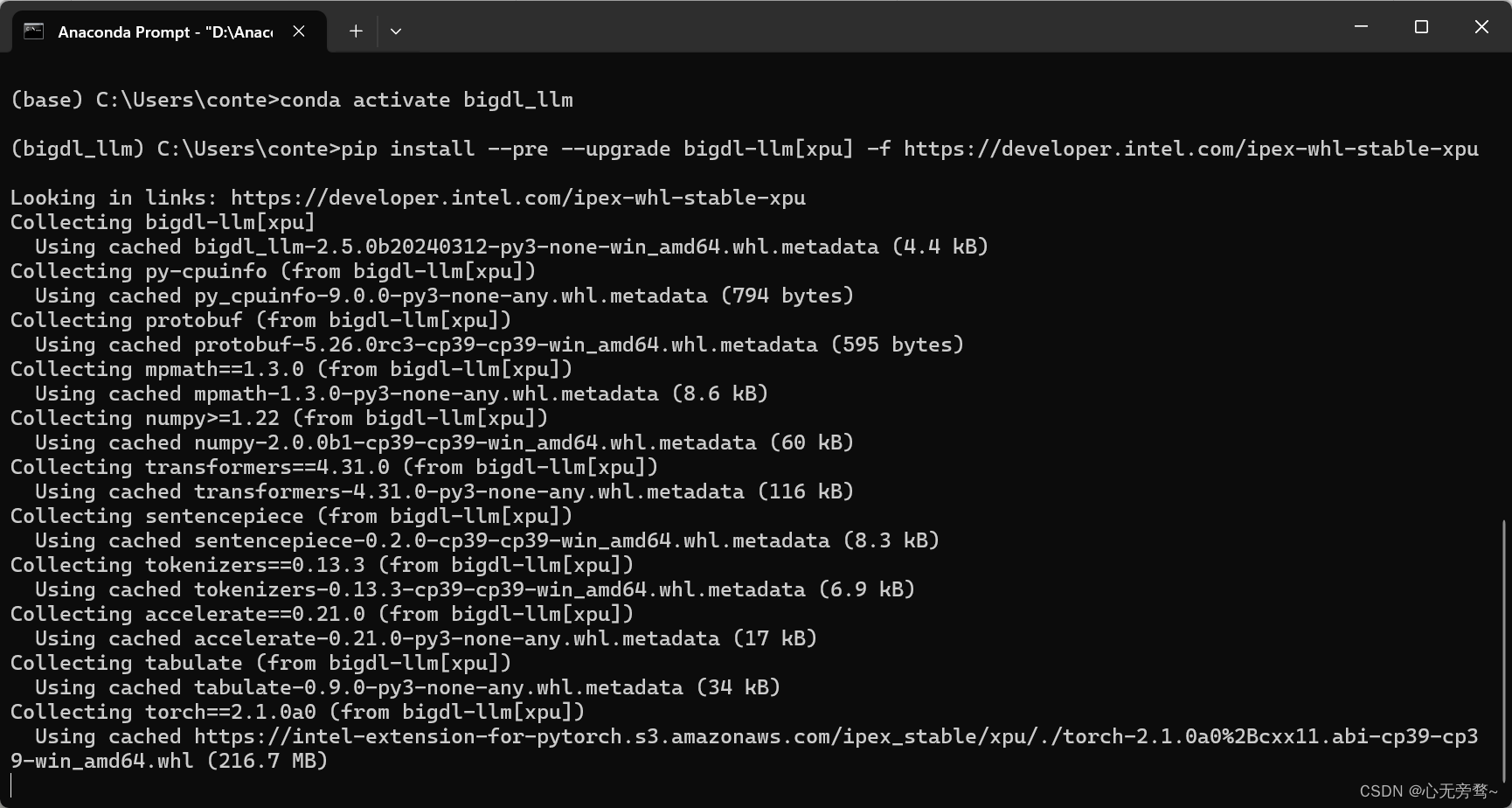
2.3 安装bigdl-llm[xpu]
pip install --pre --upgrade bigdl-llm[xpu] -f https://developer.intel.com/ipex-whl-stable-xpu
注意:如果在 pip install --pre --upgrade bigdl-llm[xpu] -f https://developer.intel.com/ipex-whl-stable-xpu 的过程中遇到 IPEX等相关库的安装问题,可以选择下面任意一种方式完成相关依赖的安装。
-
使用命令:
pip install --pre --upgrade bigdl-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/cn/ -
在安装bigdl-llm前,您需要先运行下面指令,下载
torch/torchvision/ intel-extension-for-pytorch的对应whl文件。
wget https://intel-extension-for-pytorch.s3.amazonaws.com/ipex_stable/xpu/torch-2.1.0a0%2Bcxx11.abi-cp39-cp39-win_amd64.whl
wget https://intel-extension-for-pytorch.s3.amazonaws.com/ipex_stable/xpu/torchvision-0.16.0a0%2Bcxx11.abi-cp39-cp39-win_amd64.whl
wget https://intel-extension-for-pytorch.s3.amazonaws.com/ipex_stable/xpu/intel_extension_for_pytorch-2.1.10%2Bxpu-cp39-cp39-win_amd64.whl
下载完成后,您可以直接通过whl文件安装相关依赖,并完成bigdl-llm的安装。
pip install torch-2.1.0a0+cxx11.abi-cp39-cp39-win_amd64.whl
pip install torchvision-0.16.0a0+cxx11.abi-cp39-cp39-win_amd64.whl
pip install intel_extension_for_pytorch-2.1.10+xpu-cp39-cp39-win_amd64.whl
pip install --pre --upgrade bigdl-llm[xpu]
请注意:以上提供的whl包下载链接是针对python 3.9环境的,如果您想使用python 3.10或python 3.11,请将whl包名字中的cp39改为cp310或cp311。
三、运行环境配置
为了在Core Ultra 平台上的 iGPU上运行BigDL-LLM,我们需要完成相关环境变量的配置。
请您在预备运行代码的CMD(PowerShell不支持以下命令)终端中运行以下命令:
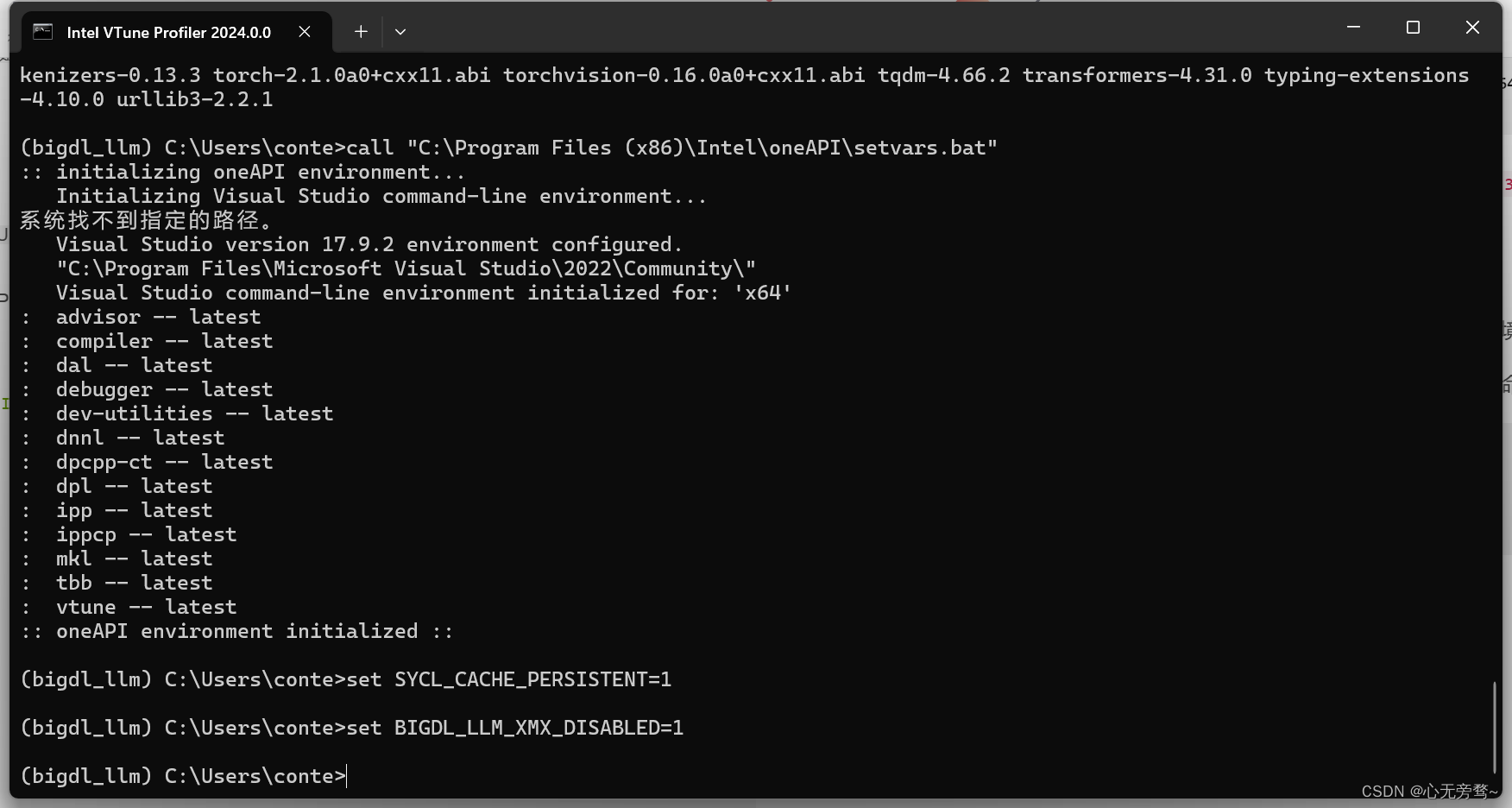
call "C:\Program Files (x86)\Intel\oneAPI\setvars.bat"
set SYCL_CACHE_PERSISTENT=1
set BIGDL_LLM_XMX_DISABLED=1
注意事项:
1.每次重新打开终端时,请重新运行上面命令
2.每个新模型在iGPU上首次运行时,可能需要花费几分钟时间完成编译。
四、安装验证
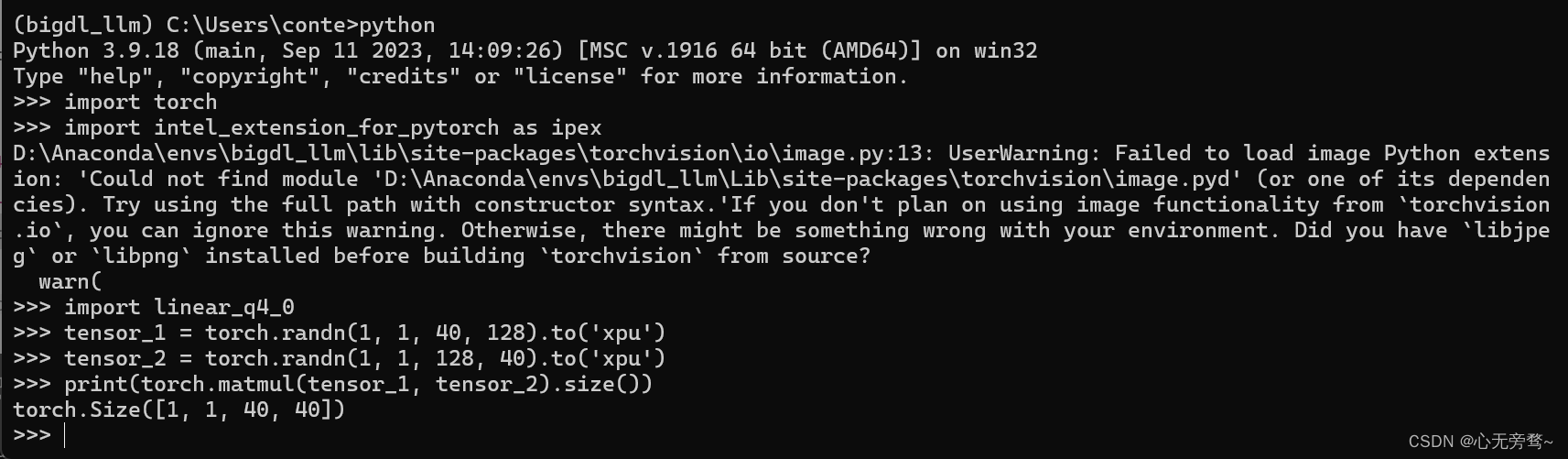
完成安装后可以运行如下Python代码,以确保您已成功安装bigdl-llm及相关依赖,并完成了运行环境配置。运行后您应当看到这样的输出:torch.Size([1, 1, 40,40])
import torch
import intel_extension_for_pytorch as ipex
import linear_q4_0
tensor_1 = torch.randn(1, 1, 40, 128).to('xpu')
tensor_2 = torch.randn(1, 1, 128, 40).to('xpu')
print(torch.matmul(tensor_1, tensor_2).size())
在python里面运行的时候,import torch 就会报以下的错误:
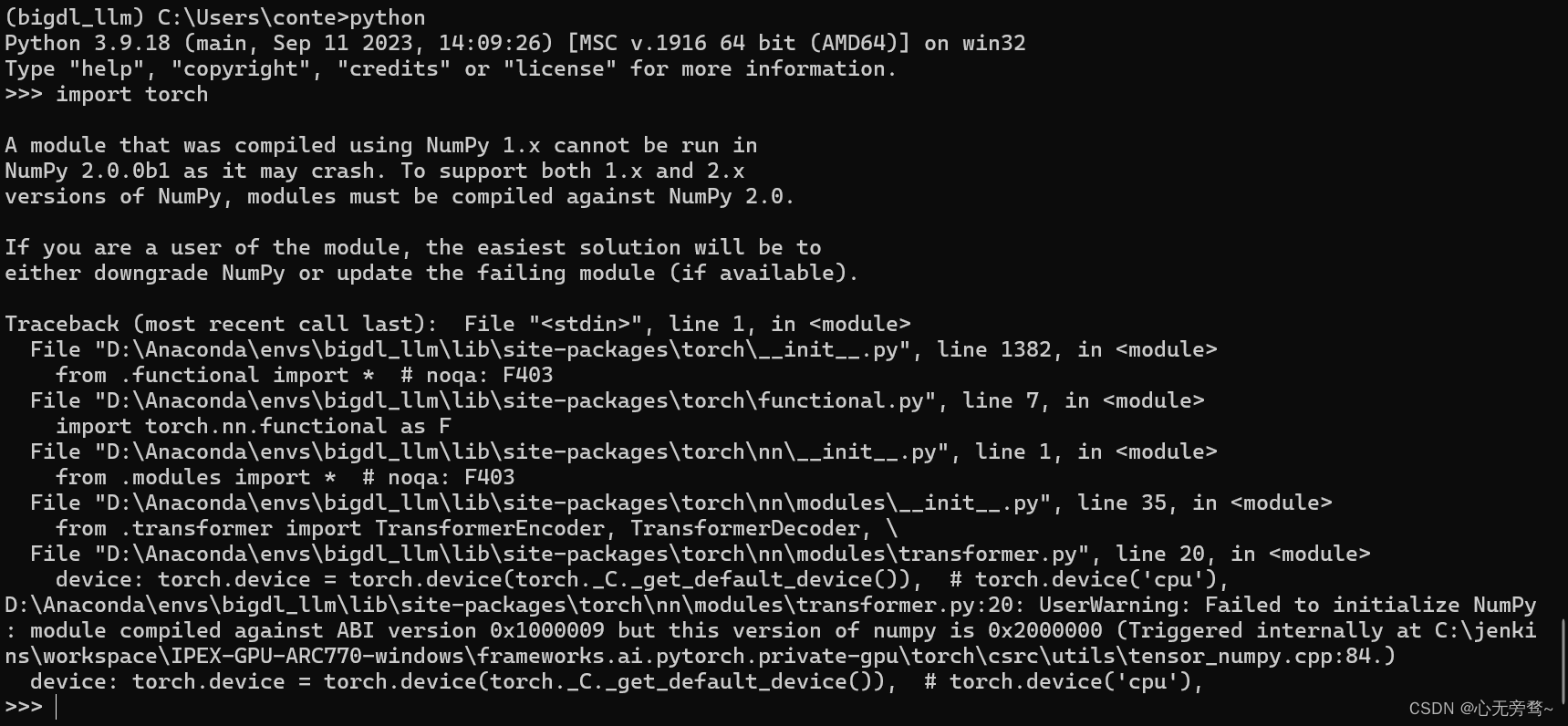
原因是numpy的版本太高了,我们可以使用quit()退出python,适当降低numpy的版本为1.26.4,即:
pip install numpy==1.26.4
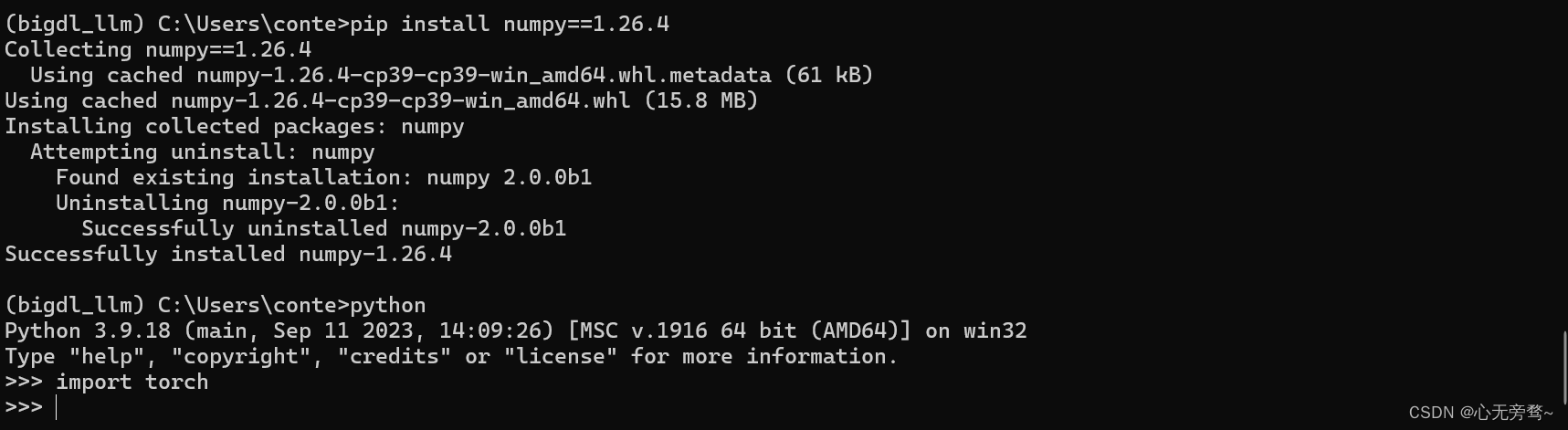
这时候看已经不报错了~
但是运行import intel_extension_for_pytorch as ipex的时候还是会出现警告,但是无伤大雅。
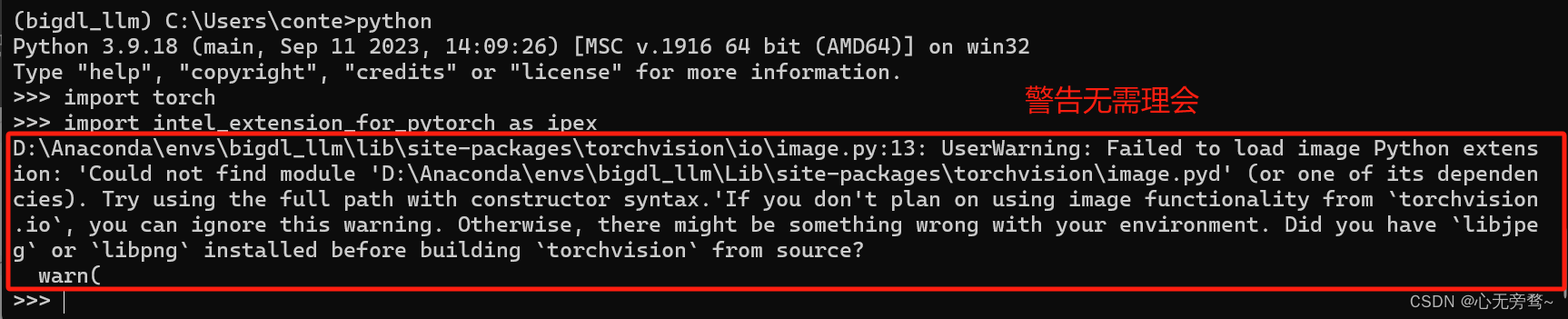
这时候再运行其它命令就不会出现错误内容了~
五、本地测试下BigDL-LLM大模型
首先下载BigDL-LLM代码,点击此处👉BigDL-LLM的Github链接。
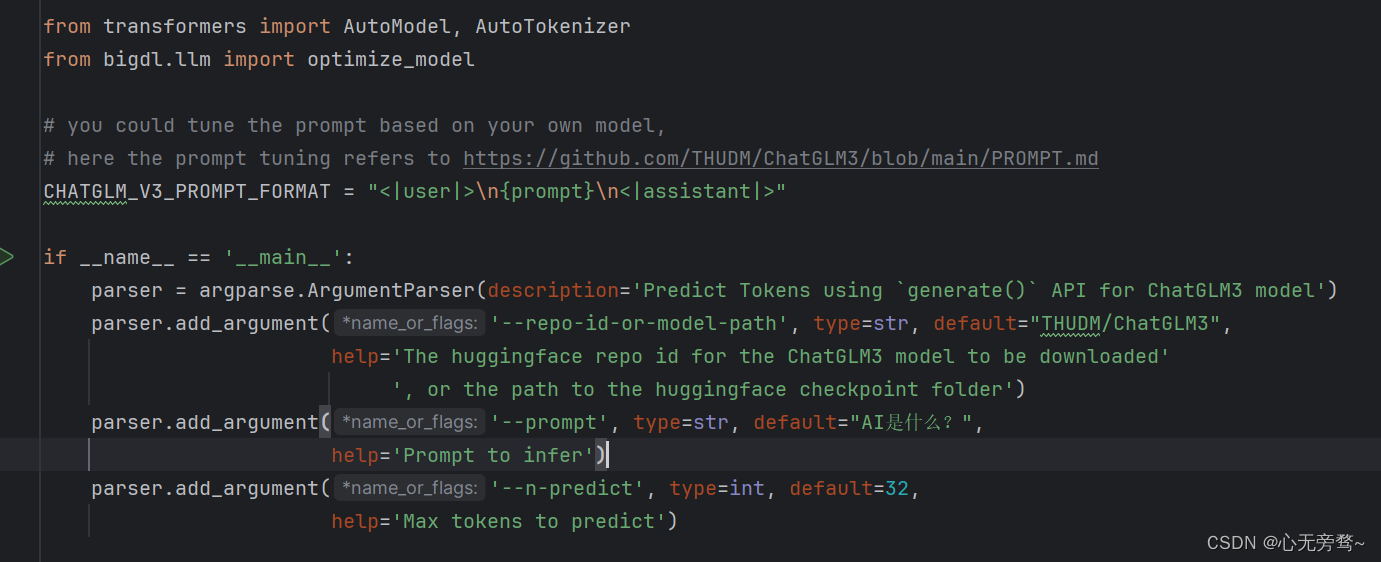
下载完代码以后,我们进入到BigDL-main/BigDL-main/python/llm/example/GPU/PyTorch-Models/Model/chatglm3/generate.py目录下,看下代码可以发现,这里调用的是github上的ChatGLM3模型权重,需要加载,但是很慢。
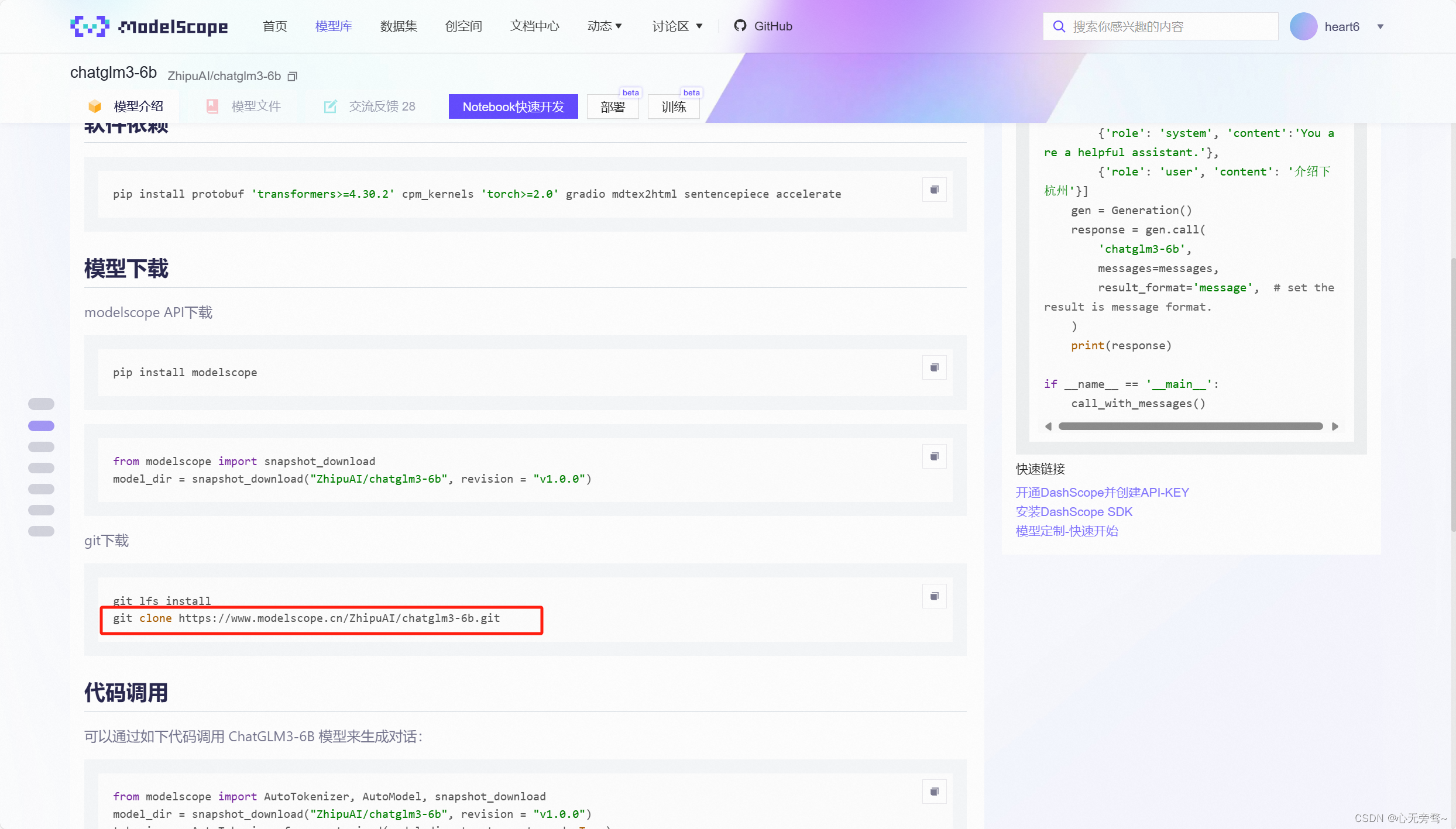
这里我推荐大家直接去我们国内的ModelScope魔搭社区,进行模型的下载,我们可以使用git命令,直接下载到本地,具体方法相信不需要我说大家都知道。
全部下载到本地以后,我们使用CMD命令行来进行大模型的运行,因为涉及到了下面三行CMD代码的执行,所以直接在CMD命令行里面运行。
call "C:\Program Files (x86)\Intel\oneAPI\setvars.bat"
set SYCL_CACHE_PERSISTENT=1
set BIGDL_LLM_XMX_DISABLED=1
如果不运行上面三行代码,那么直接运行会进行报错。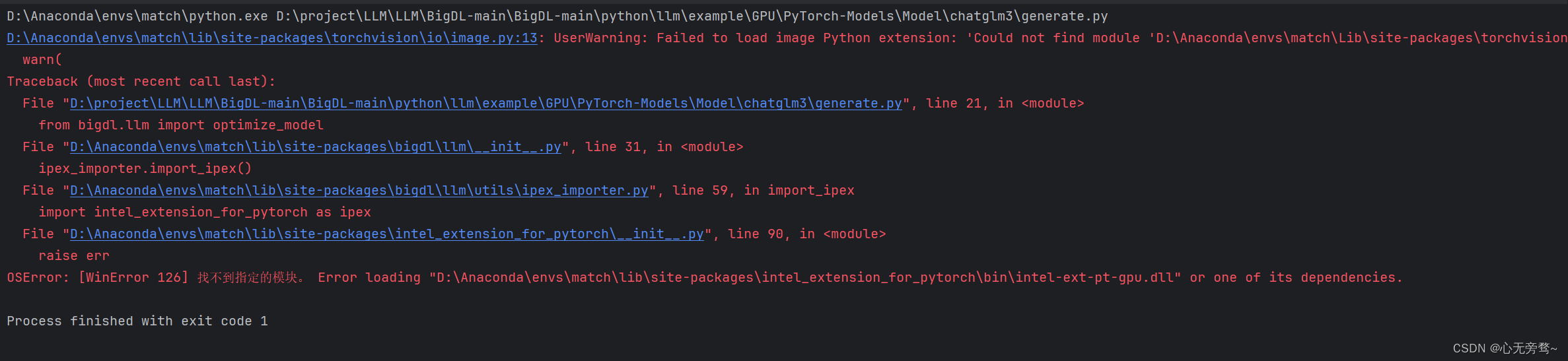
系统找不到该指定模块,但是我看我路径下确实有该文件,具体原因我上网尝试了很多方法都没解决(有大佬知道辛苦评论区指导~)。
我们直接进入到模型文件目录下,这次我用的是chatglm3b大模型。
然后输入cmd打开命令行。
记得每次打开新的命令行都需要重新输入以下三行命令:
call "C:\Program Files (x86)\Intel\oneAPI\setvars.bat"
set SYCL_CACHE_PERSISTENT=1
set BIGDL_LLM_XMX_DISABLED=1
然后输入conda activate bigdl_llm 激活虚拟环境,如果有人以前没有在cmd命令行里面激活过conda虚拟环境,可以输入conda init 初始化conda环境,将cmd名号了关闭后重新进入,再此输入激活虚拟环境命令进行激活。
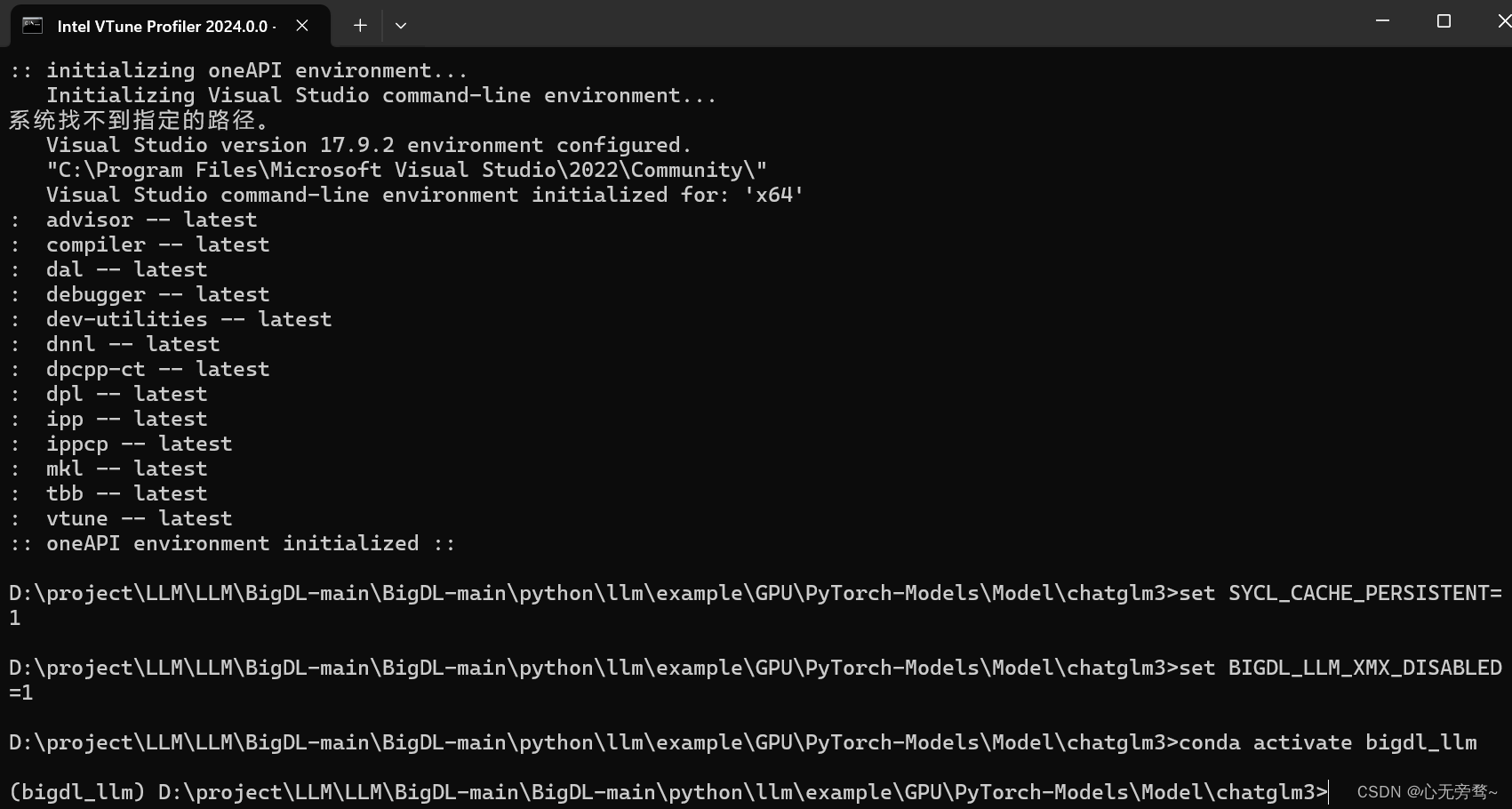
然后输入 python generate.py 运行代码:
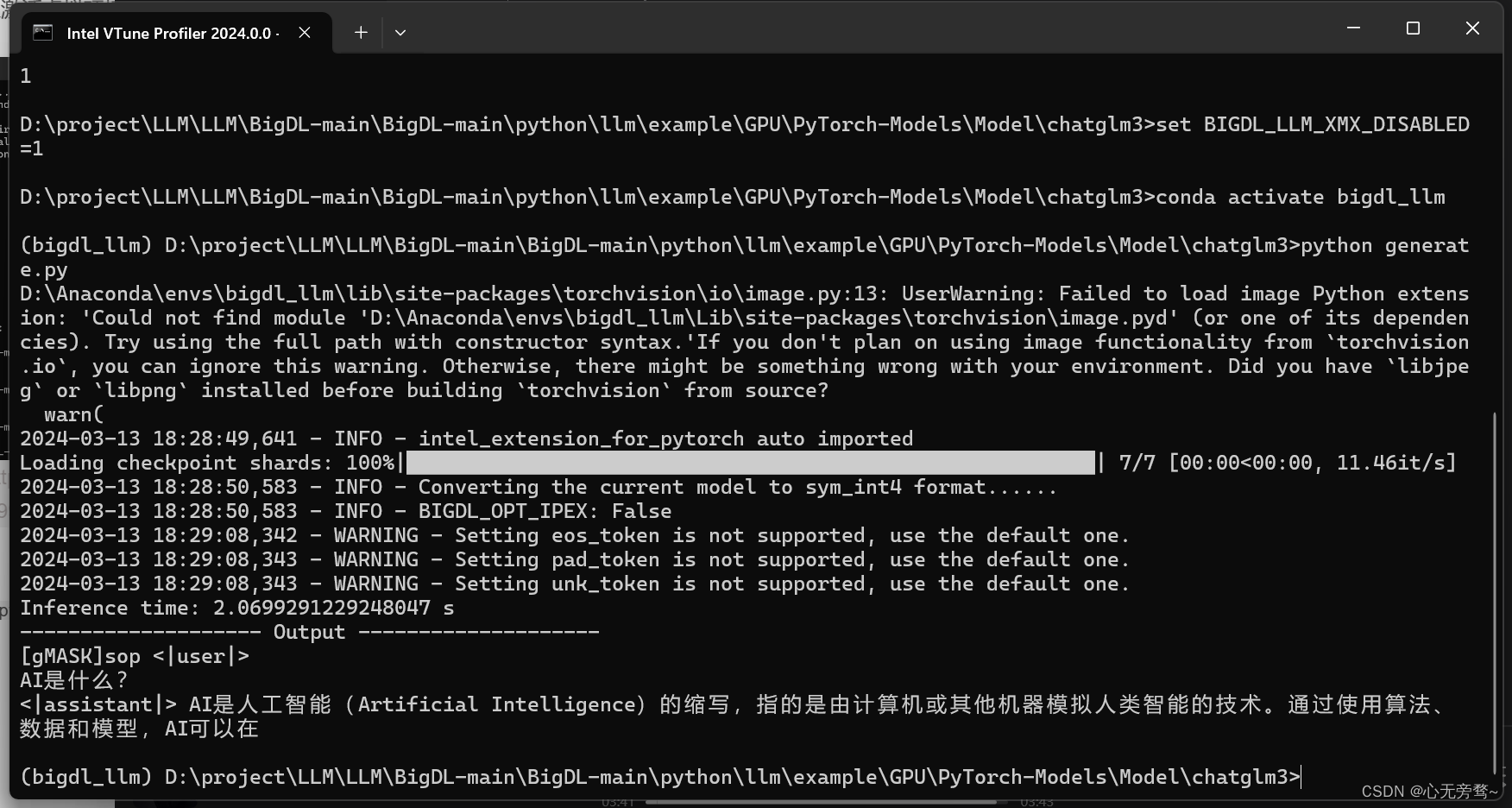
可以看到,推理时间只有短短2s左右,速度还是很快的。
以上是调用XPU的推理速度,下面我们看看CPU的推理速度。
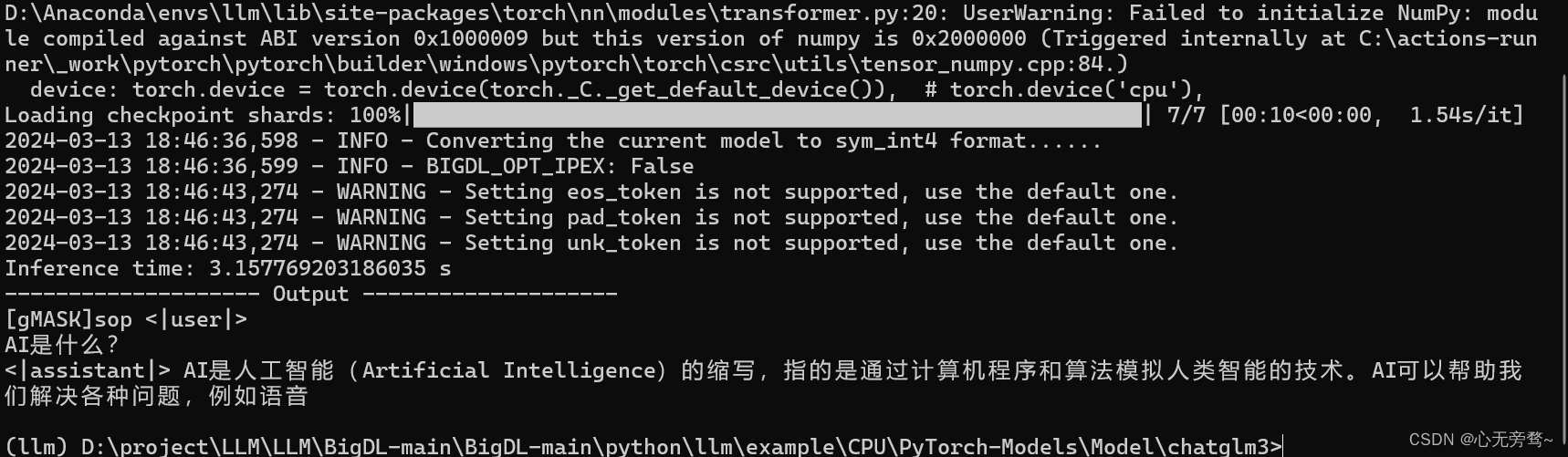
可以看到,借助了BigDL-LLM大模型加速库的情况下,cpu推理时间为3秒左右。
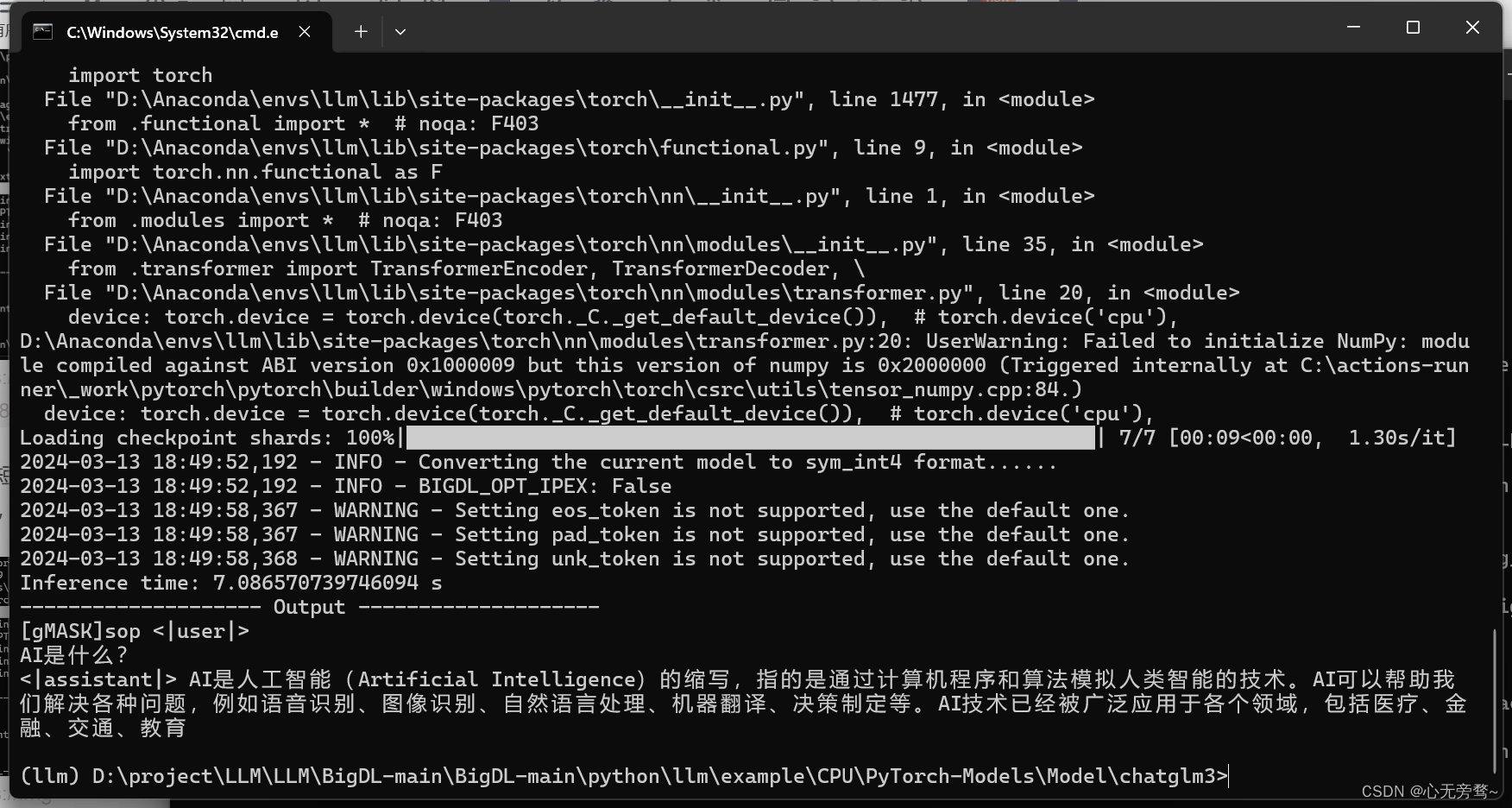
推理的结果,可以通过调整参数--n-predict来进行控制,默认值为32,我们调整到64以后可以看到下面回答的更加完整了一点。
参考资料
-
BigDL-LLM 代码仓库https://github.com/intel-analytics/BigDL/
-
BigDL-LLM 教程https://github.com/intel-analytics/bigdl-llm-tutorial
-
社区流行模型使用BigDL-LLM在Intel CPU和GPU上的使用实例https://github.com/intel-analytics/BigDL/tree/main/python/llm/example
-
BigDL-LLM 文档https://bigdl.readthedocs.io/en/latest/index.html
-
BigDL-LLM API文档https://bigdl.readthedocs.io/en/latest/doc/PythonAPI/LLM/index.html


















 358
358

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











