






一,首先需要安装虚拟环境(miniconda),方便管理:
如果不知到怎么安装虚拟环境可以点这:安装虚拟环境
安装好虚拟环境后创建虚拟环境:在命令提示符(CMD)输入:
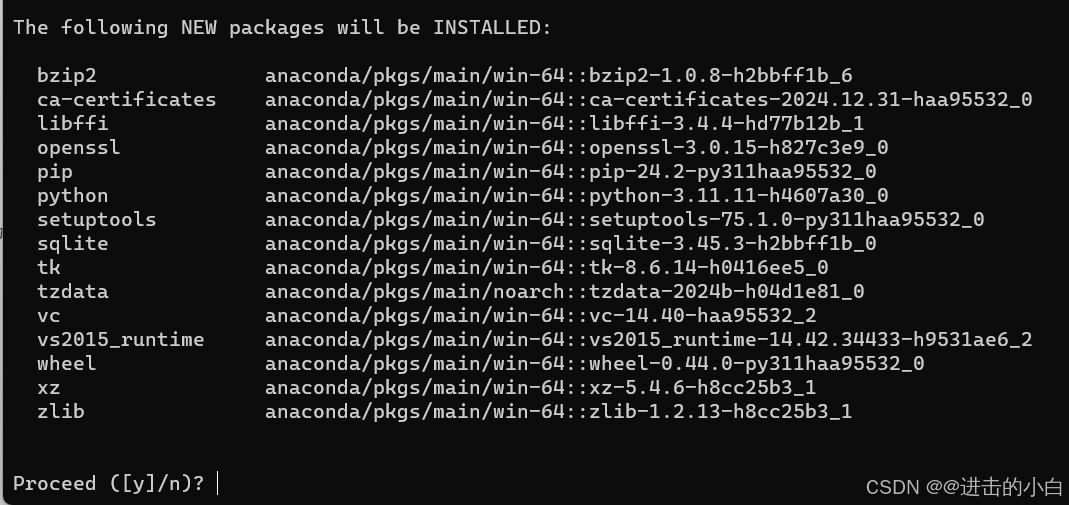
conda create -n Py310 python=3.10Py310是你的虚拟环境的名字,当让也可以换成你喜欢的,python版本也可以是其他的,我个人觉得3.10到3.12比较好。执行后输入"y"确认即可,如图:
二、下载 Intel® oneAPI Base Toolkit
访问 Intel® oneAPI 下载页面Get the Intel® oneAPI Base ToolkitIntel® oneAPI 下载页面,选择适合你操作系统的版本(Windows/Linux/macOS)。
-
运行安装程序,选择 Custom Install(自定义安装)。
-
在组件列表中,只勾选以下内容:
-
Intel® oneAPI DPC++/C++ Compiler
-
Intel® oneAPI Level Zero
-
Intel® oneAPI AI Analytics Toolkit
-
Intel® VTune Profiler(可选)
-
-
点击 Next,选择安装路径(例如
D:\intel\oneAPI)。 -
完成安装。
配置环境变量
安装完成后,确保正确配置环境变量:打开命令提示符或终端。运行以下命令加载 oneAPI 环境变量:
call "D:\intel\oneAPI\setvars.bat"三、安装Intel显卡驱动及extension for pytorch
1、打开Intel官方网址:https://pytorch-extension.intel.com/installation?platform=gpu&version=v2.5.10+xpu&os=windows&package=pip
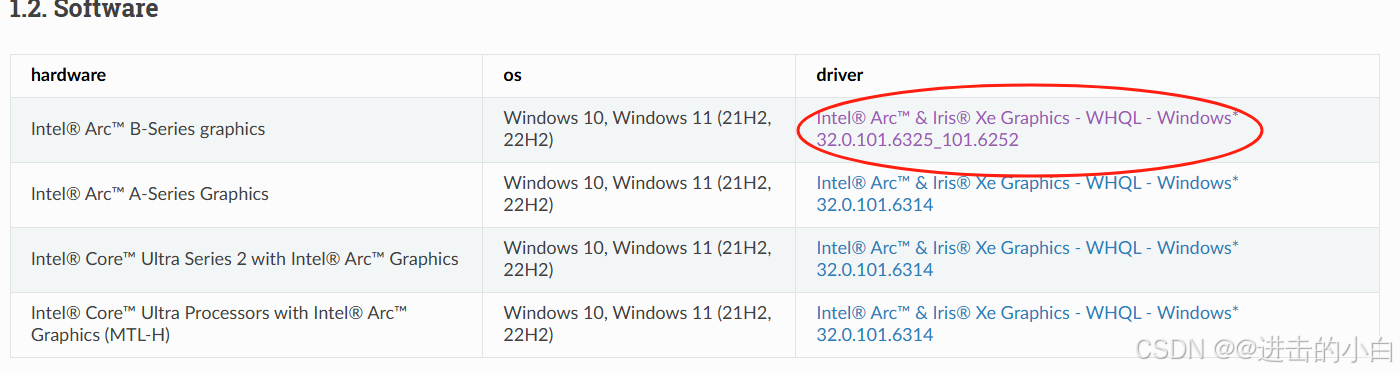
按照下图中选:

2、安装intel显卡驱动:
往下滑,我的显卡是Intel(R) iris(R) Xe Graphics,随便安装了第一个
3、安装extension for pytorch及其他依赖库
激活刚刚创建的虚拟环境:
conda activate Py310安装过程中我发现torch不支持numpy>=2,但是在安装完成后把numpy将为1.xx时出现以下错误:
OSError: [WinError 127] 找不到指定的程序。 Error loading "D:\ProgramData\miniconda3\envs\Py311\Lib\site-packages\torch\lib\aoti_custom_ops.dll" or one of its dependencies.(可能是链接出现错误),但是安装torch是系统自动检索numpy>=2的版本,所以为了解决这个问题,在创建完虚拟环境是第一步先安装numpy<2版本,我选择了numpy=1.26版本,因为matplotlib只支持1.23版本以上的。
pip install numpy==1.26为了防止以后安装其他库时numpy自动更新,需要做一下步骤:
使用 pip freeze 锁定版本:
pip freeze > requirements.txt
然后在未来的安装中,使用以下命令来安装与当前环境中相同的依赖版本:
pip install -r requirements.txt 你要安装的库
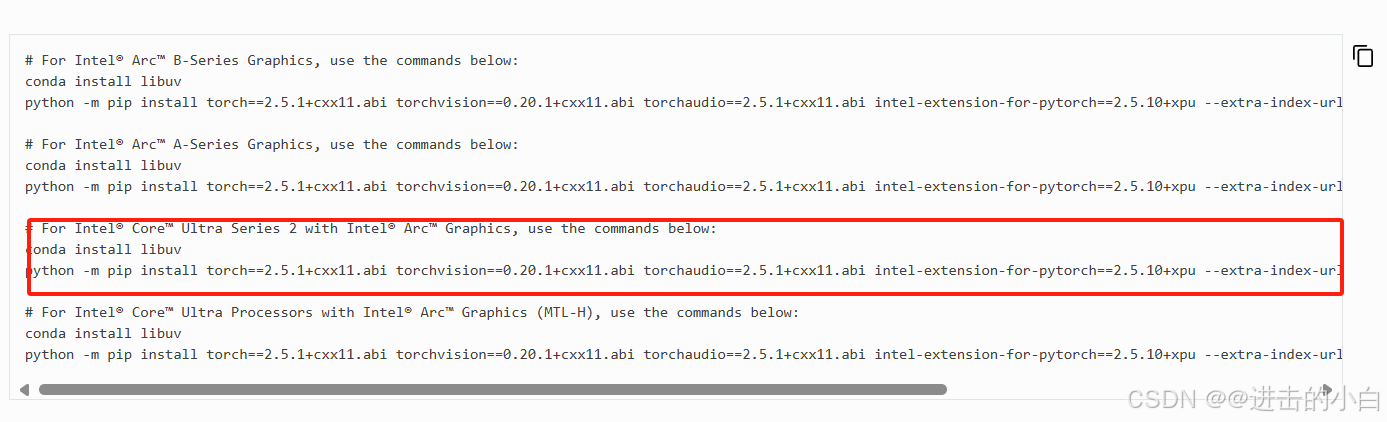
因为第三个是核显,核显与集显的区别是有无独立内存。两者都是集成在处理器中。所以我就选择了第三个。
conda install libuvpython -m pip install torch==2.5.1+cxx11.abi torchvision==0.20.1+cxx11.abi torchaudio==2.5.1+cxx11.abi intel-extension-for-pytorch==2.5.10+xpu --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/lnl/us/
等待安装完成,检验可用性:关掉命令窗口,从新激活虚拟环境,输入:
python -c "import torch; import intel_extension_for_pytorch; print(torch.xpu.is_available());"可能会有警告,可以忽略掉,结尾出现True即可。

当然可能也会出现报错,如依赖包不匹配,比如我遇到numpy不匹配,需要降到1.xx版本。
三、激动人心的时刻。在你的项目中切换到刚创建的虚拟环境中
添加以下代码即可用GPU加速,其实和使用CUDA的代码区别不到,无非是把cuda改成xpu
import torch
# 检查 GPU 是否可用
device = torch.device("xpu" if torch.xpu.is_available() else "cpu")
# 假设你有一个模型
model = MyModel().to(device)
# 假设你有一些输入数据
inputs = inputs.to(device)
# 训练时将模型和数据移到 GPU
outputs = model(inputs)最后,提醒一下,注意每次训练的batch_size不要太大,从小往大试,不让会把显存撑爆,导致闪屏(因为我试过,如果真的这样,建议关机重启,或者重装显卡驱动)
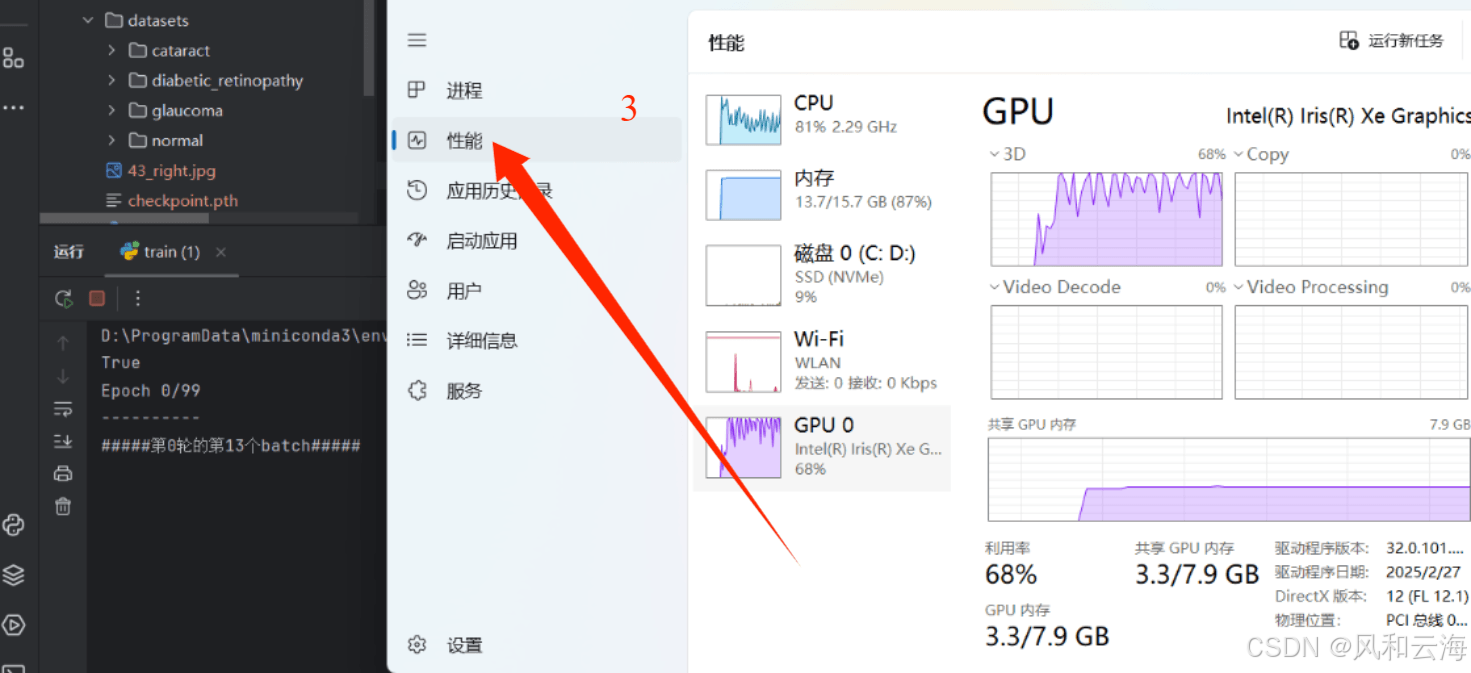
按照以下步骤可以查看显存占用情况:


















 3172
3172

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









