






一.本案例简介:最近在跟着崔大的书学习playwright自动化爬虫库,这是一个支持异步操作的开源第三方库。在本文中,我将利用这个库,结合其他库编写一个自动化爬虫。也可视为学习完这个库之后的学习成果的检验。目标网站: https://spa6.scrape.center/ 。
二.本次爬虫脚本的实现:
1.需要准备的库:playwright(请按照相关文档正确配置),redis,asyncio,json库。
2.编写思路:使用playwright连接网站接口,用css选择器提取电影标签(这里只提取第一页的十部电影,如需提取更多,读者可自己扩展程序);跳转到子网页,再用playwright封装的回调函数捕捉到目标数据;最后存储到本地redis数据库。
3.源代码:
import asyncio
from playwright.async_api import async_playwright
from redis import StrictRedis
import json
class SaveData:
'''定义此类方便利用PlayWright封装的回调函数'''
def __init__(self,movie_id):
self.movie_id = movie_id
self.redis = StrictRedis(host='localhost',port=6379,db=1)
def __savedata(self,json_data):
self.redis.set(self.movie_id,json_data)
print(f'电影{self.movie_id}数据保存完毕!')
async def callback(self,response):
# 筛选出带有json目标数据的url的response
if 'api/movie' in response.url and response.status == 200:
json_data = json.dumps(await response.json())
self.__savedata(json_data)
async def one_movie_handle(page, url,movie_id):
# 实例化SaveData类
savedata = SaveData(movie_id)
# 开启事件监听
page.on('response',savedata.callback)
# 进入子页面
await page.goto(url)
# 等待子页面加载完毕
await page.wait_for_load_state('networkidle')
# 关闭子页面
await page.close()
async def main():
# 使用chromium作为浏览器驱动
playwright = await async_playwright().start()
browser = await playwright.chromium.launch()
# 新建上下文
context = await browser.new_context()
# 新建选项卡
page_1 = await context.new_page()
# 接入目标网站
await page_1.goto('https://spa6.scrape.center/')
# 等待网页加载完毕
await page_1.wait_for_load_state('networkidle')
# 使用css选择器定位到目标(抓取第一页十部电影)
elements = await page_1.query_selector_all('div.el-card.item.m-t.is-hover-shadow')
# 封装异步任务
tasks = []
for element in elements:
# 获得子页面网址
tag_a = await element.query_selector('a')
url = 'https://spa6.scrape.center' + await tag_a.get_attribute('href')
# 获得电影名称
tag_h2 = await element.query_selector('a > h2')
movie_id = await tag_h2.text_content()
# 新建子页面选项卡
page_2 = await context.new_page()
tasks.append(asyncio.create_task(one_movie_handle(page_2, url,movie_id)))
await asyncio.wait(tasks)
# 关闭浏览器驱动
await browser.close()
if __name__ == '__main__':
asyncio.get_event_loop().run_until_complete(main())
4.补充:在这个程序中,我定义了一个类,这个类的作用是利用上回调函数提取数据。
四.成果展示:
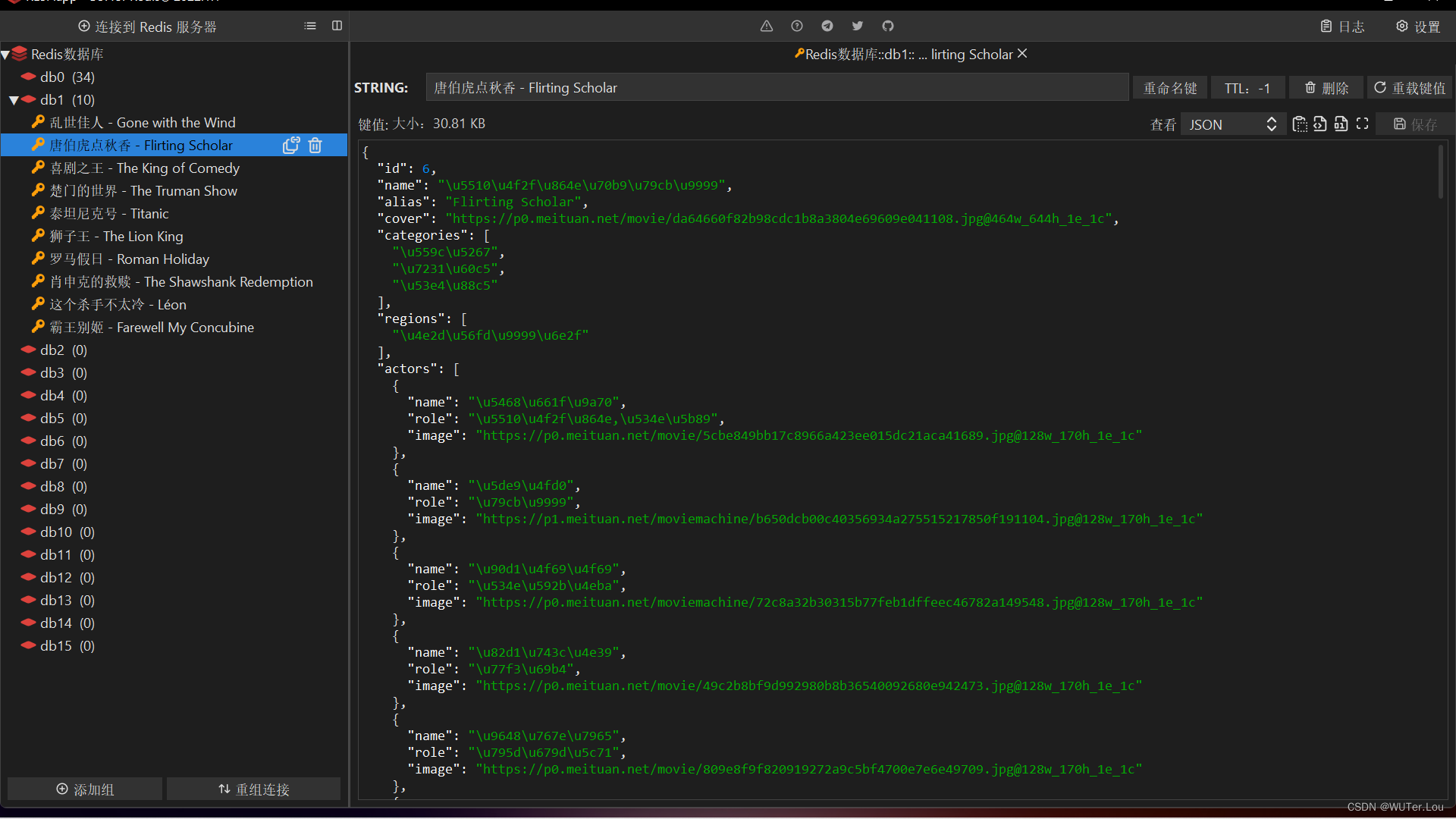















 2362
2362











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









