







flask安装
pip install flask
创建flask应用
app.py
from flask import Flask, request, jsonify, send_file
import torch
from PIL import Image
import io
import base64
import os
app = Flask(__name__)
# 加载模型
model = torch.hub.load('ultralytics/yolov5', 'custom', path='path_to_your_model.pt')
@app.route('/predict', methods=['POST'])
def predict():
if 'image' not in request.files:
return jsonify({'error': 'No image provided'}), 400
file = request.files['image']
img = Image.open(file.stream).convert('RGB')
# 推理
results = model(img)
# 保存结果图片
results.save(save_dir='results') # 在results目录下保存结果图片
# 获取推理结果信息
predictions = results.pandas().xyxy[0].to_dict(orient="records")
# 读取结果图片
result_image_path = os.path.join('results', os.path.basename(file.filename))
with open(result_image_path, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode('utf-8')
# 返回结果图片和推理信息
return jsonify({
'predictions': predictions,
'result_image': encoded_string
})
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)
报错:
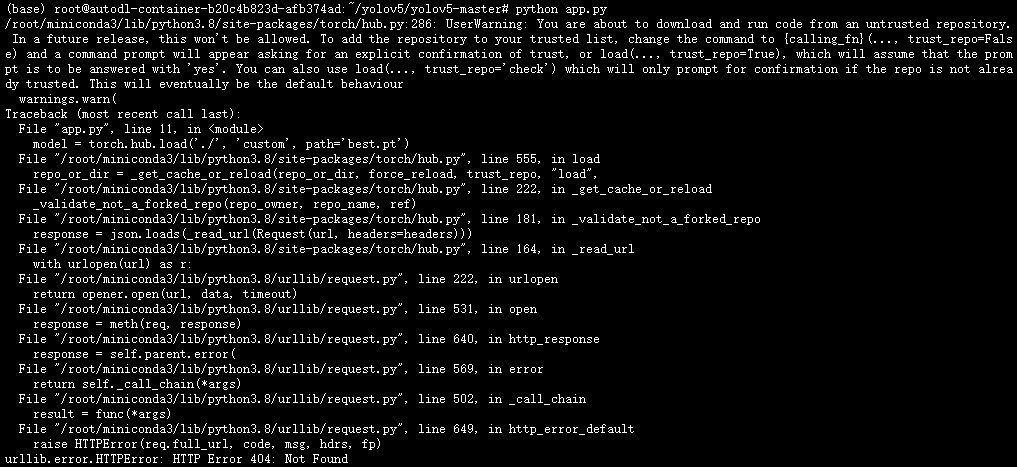
原因:
是因为torch.hub.load试图下载并运行一个外部仓库,但提供的路径是一个本地路径。因此,应该改用YOLOv5的本地加载方式,而不是通过torch.hub.load。
可以直接使用YOLOv5的官方API加载本地模型文件。
from flask import Flask, request, jsonify
import torch
from PIL import Image
import io
import base64
import os
app = Flask(__name__)
# 加载本地模型
model = torch.load('best.pt') # 直接加载模型
model.eval() # 设置模型为评估模式
@app.route('/predict', methods=['POST'])
def predict():
if 'image' not in request.files:
return jsonify({'error': 'No image provided'}), 400
file = request.files['image']
img = Image.open(file.stream).convert('RGB')
# 转换图像为Tensor
img_tensor = torch.from_numpy(np.array(img)).permute(2, 0, 1).float().div(255.0).unsqueeze(0)
# 推理
results = model(img_tensor)
# 处理结果
results = results.pandas().xyxy[0] # 结果转换为DataFrame
# 保存结果图片
results.render() # 在原图上绘制结果
result_img = Image.fromarray(results.imgs[0])
result_img.save('result.jpg')
# 获取推理结果信息
predictions = results.to_dict(orient="records")
# 读取结果图片
with open("result.jpg", "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode('utf-8')
# 返回结果图片和推理信息
return jsonify({
'predictions': predictions,
'result_image': encoded_string
})
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)
然后又报错:

原因是torch.load加载模型时,返回的是一个包含模型和其他信息的字典,而不是模型本身。需要从字典中提取实际的模型对象。通常,保存的模型字典包含模型参数和一些元数据,因此需要创建模型实例并加载这些参数。
在YOLOv5中,使用torch.load直接加载模型的权重,然后将其加载到一个YOLOv5模型实例中。
from flask import Flask, request, jsonify
import torch
from PIL import Image
import io
import base64
import os
import numpy as np
import sys
sys.path.append('./') # 添加当前目录到系统路径
from models.common import DetectMultiBackend # 导入YOLOv5模型
app = Flask(__name__)
# 加载本地模型
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = DetectMultiBackend('best.pt', device=device) # 加载模型并指定设备
model.eval() # 设置模型为评估模式
@app.route('/predict', methods=['POST'])
def predict():
if 'image' not in request.files:
return jsonify({'error': 'No image provided'}), 400
file = request.files['image']
img = Image.open(file.stream).convert('RGB')
# 转换图像为Tensor
img = np.array(img)
img_tensor = torch.from_numpy(img).permute(2, 0, 1).float().div(255.0).unsqueeze(0).to(device)
# 推理
results = model(img_tensor)
# 处理结果
results = results.pandas().xyxy[0] # 结果转换为DataFrame
# 保存结果图片
results.render() # 在原图上绘制结果
result_img = Image.fromarray(results.imgs[0])
result_img.save('result.jpg')
# 获取推理结果信息
predictions = results.to_dict(orient="records")
# 读取结果图片
with open("result.jpg", "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode('utf-8')
# 返回结果图片和推理信息
return jsonify({
'predictions': predictions,
'result_image': encoded_string
})
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)
然后又报错:
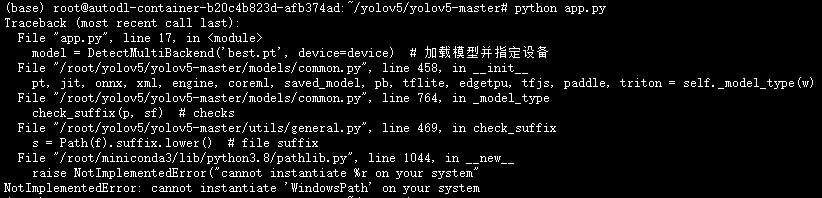
这个之前在windows的时候遇到过,只需要添加以下代码:
import pathlib
pathlib.WindowsPath = pathlib.PosixPath
然后总算能运行通了:

然后考虑暴露端口,

于是,将代码中的5000端口改成6006,然后
然后就会得到访问的网址:

然后来到apifox进行测试:


然后尝试发送,却报错:
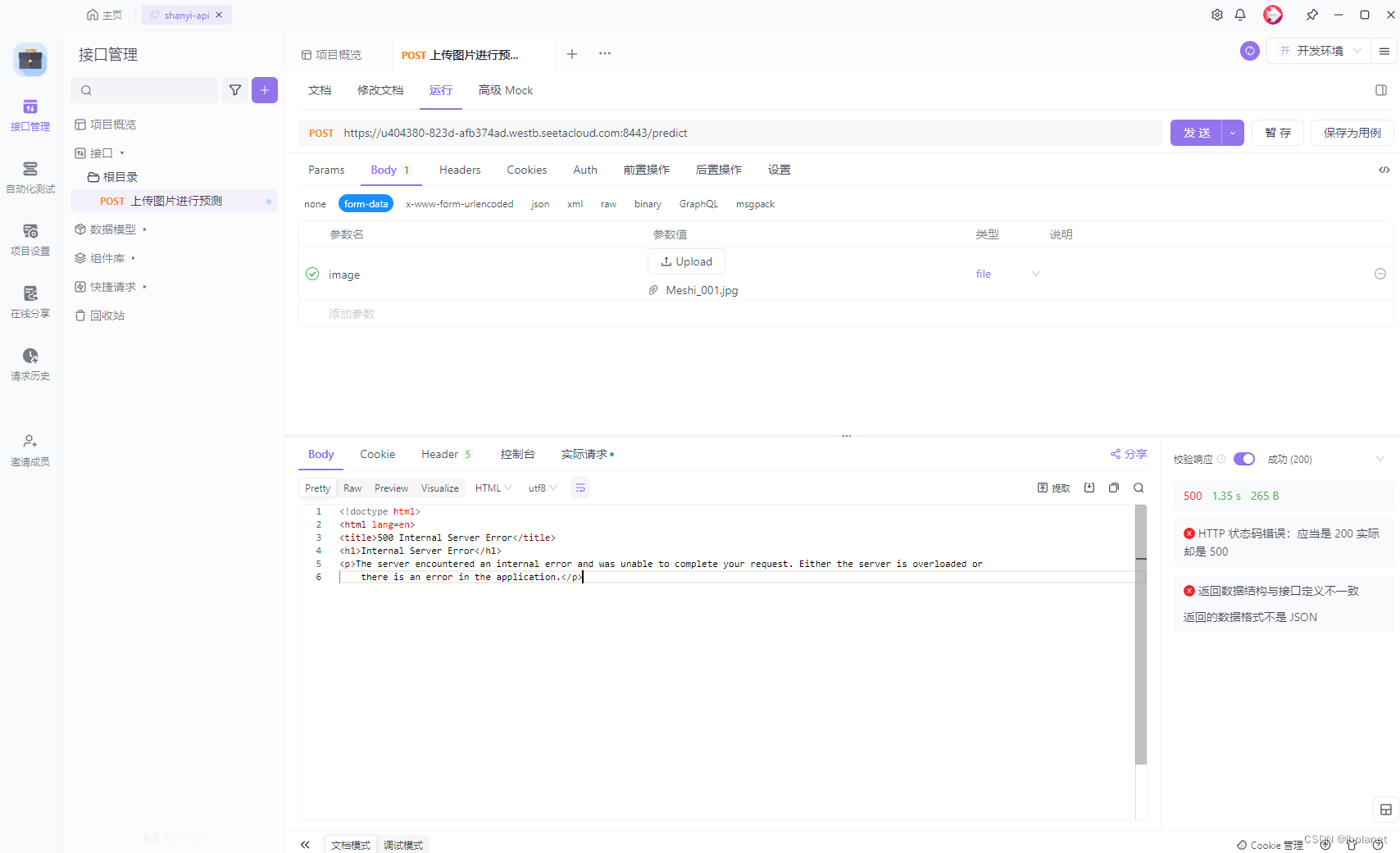
后端报错:
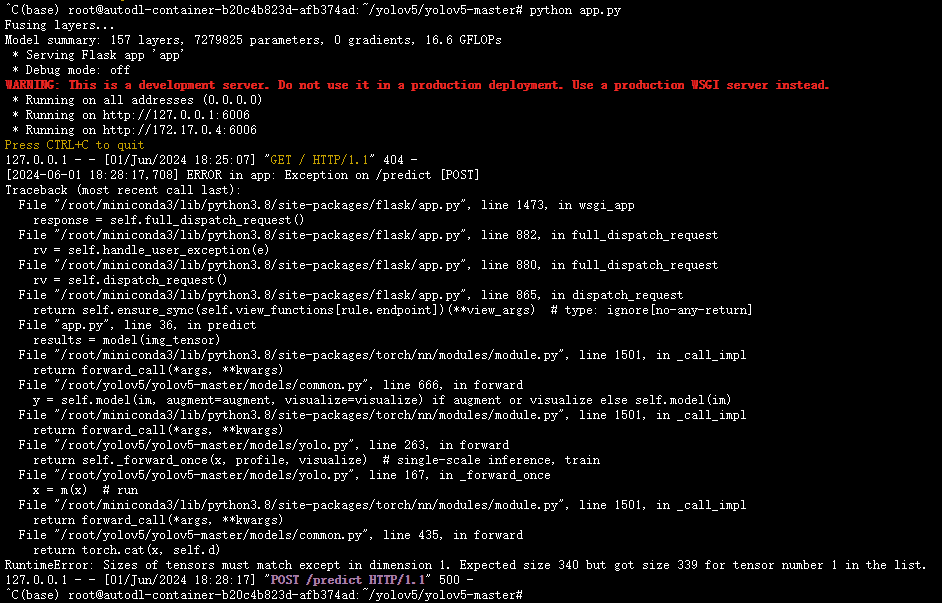
RuntimeError: Sizes of tensors must match except in dimension 1. Expected size 340 but got size 339 for tensor number 1 in the list.
这是因为在模型前向传播时,输入张量的大小不匹配。通常这是因为输入图像的尺寸在处理时出现问题。YOLOv5模型期望输入图像的尺寸是某些特定大小的倍数(例如32),否则可能会在处理过程中出错。
我们需要确保输入图像在推理之前进行预处理,以适应模型的输入要求。YOLOv5提供了一些内置的图像预处理工具,下面是修改后的代码,确保图像在推理之前进行适当的预处理。
from flask import Flask, request, jsonify
import torch
from PIL import Image
import io
import base64
import os
import numpy as np
import sys
import pathlib
pathlib.WindowsPath = pathlib.PosixPath
sys.path.append('./') # 添加当前目录到系统路径
from models.common import DetectMultiBackend # 导入YOLOv5模型
from utils.augmentations import letterbox # 导入letterbox函数进行图像预处理
app = Flask(__name__)
# 加载本地模型
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = DetectMultiBackend('best.pt', device=device) # 加载模型并指定设备
model.eval() # 设置模型为评估模式
@app.route('/predict', methods=['POST'])
def predict():
if 'image' not in request.files:
return jsonify({'error': 'No image provided'}), 400
file = request.files['image']
img = Image.open(file.stream).convert('RGB')
# 图像预处理
img = np.array(img)
img = letterbox(img, new_shape=(640, 640), auto=False)[0] # 调整图像大小
img_tensor = torch.from_numpy(img).permute(2, 0, 1).float().div(255.0).unsqueeze(0).to(device)
# 推理
results = model(img_tensor)
# 处理结果
results = results.pandas().xyxy[0] # 结果转换为DataFrame
# 保存结果图片
results.render() # 在原图上绘制结果
result_img = Image.fromarray(results.imgs[0])
result_img.save('result.jpg')
# 获取推理结果信息
predictions = results.to_dict(orient="records")
# 读取结果图片
with open("result.jpg", "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode('utf-8')
# 返回结果图片和推理信息
return jsonify({
'predictions': predictions,
'result_image': encoded_string
})
if __name__ == '__main__':
app.run(host='0.0.0.0', port=6006)
然后再次尝试,又报错:
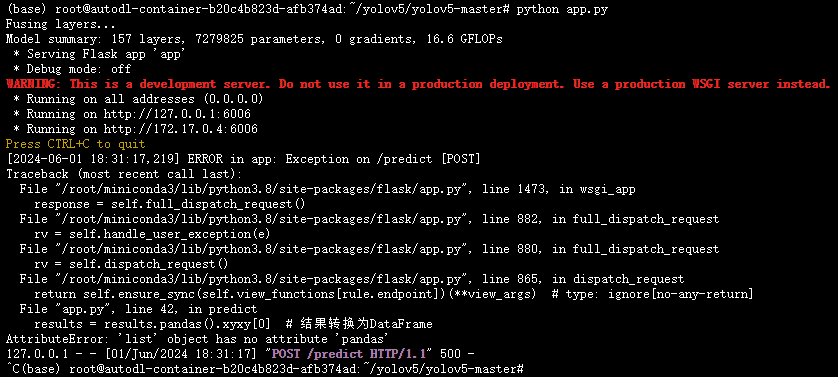
AttributeError: 'list' object has no attribute 'pandas'
这是因为推理结果results是一个列表而不是期望的Dataset对象。这可能是因为YOLOv5模型返回的结果格式不同于预期。要解决这个问题,我们需要确保results是一个Dataset对象,然后才能调用pandas()方法将其转换为DataFrame。
我们需要确保results是一个Dataset对象,如果不是,我们可以手动将其转换为Dataset对象。
from flask import Flask, request, jsonify
import torch
from PIL import Image
import io
import base64
import os
import numpy as np
import sys
import pathlib
pathlib.WindowsPath = pathlib.PosixPath
sys.path.append('./') # 添加当前目录到系统路径
from models.common import DetectMultiBackend # 导入YOLOv5模型
from utils.augmentations import letterbox # 导入letterbox函数进行图像预处理
app = Flask(__name__)
# 加载本地模型
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = DetectMultiBackend('best.pt', device=device) # 加载模型并指定设备
model.eval() # 设置模型为评估模式
@app.route('/predict', methods=['POST'])
def predict():
if 'image' not in request.files:
return jsonify({'error': 'No image provided'}), 400
file = request.files['image']
img = Image.open(file.stream).convert('RGB')
# 图像预处理
img = np.array(img)
img = letterbox(img, new_shape=(640, 640), auto=False)[0] # 调整图像大小
img_tensor = torch.from_numpy(img).permute(2, 0, 1).float().div(255.0).unsqueeze(0).to(device)
# 推理
results = model(img_tensor)
# 如果结果是列表而不是Dataset对象,则手动转换
if isinstance(results, list):
from utils.general import non_max_suppression
results = non_max_suppression(results, conf_thres=0.5, iou_thres=0.5)
# 处理结果
results = results[0] # 获取第一个元素
if results is not None:
# 保存结果图片
results.render() # 在原图上绘制结果
result_img = Image.fromarray(results.imgs[0])
result_img.save('result.jpg')
# 获取推理结果信息
predictions = results.to_dict(orient="records")
# 读取结果图片
with open("result.jpg", "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode('utf-8')
# 返回结果图片和推理信息
return jsonify({
'predictions': predictions,
'result_image': encoded_string
})
else:
return jsonify({'predictions': [], 'result_image': None})
if __name__ == '__main__':
app.run(host='0.0.0.0', port=6006)
但是,最终没搞定,换方案!
import pathlib
pathlib.WindowsPath = pathlib.PosixPath
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
"""Run a Flask REST API exposing one or more YOLOv5s models."""
import argparse
import io
import torch
from flask import Flask, request
from PIL import Image
import numpy as np
import base64
from flask import jsonify
app = Flask(__name__)
models = {}
DETECTION_URL = "/v1/object-detection/<model>"
@app.route(DETECTION_URL, methods=["POST"])
def predict(model):
"""Predict and return object detections in JSON format given an image and model name via a Flask REST API POST
request.
"""
if request.method != "POST":
return
if request.files.get("image"):
# Method 1
# with request.files["image"] as f:
# im = Image.open(io.BytesIO(f.read()))
# Method 2
im_file = request.files["image"]
im_bytes = im_file.read()
im = Image.open(io.BytesIO(im_bytes))
if model in models:
results = models[model](im, size=640) # reduce size=320 for faster inference
# return results.pandas().xyxy[0].to_json(orient="records")
results.render()
# Convert detections to JSON
detections_json = results.pandas().xyxy[0].to_json(orient="records")
# Convert rendered image to base64
buffered = io.BytesIO()
Image.fromarray(results.render()[0]).save(buffered, format="JPEG")
image_base64 = base64.b64encode(buffered.getvalue()).decode("utf-8")
# Return both detections and image as a JSON object
return jsonify(detections=detections_json, image=image_base64)
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Flask API exposing YOLOv5 model")
parser.add_argument("--port", default=6006, type=int, help="port number")
parser.add_argument("--model", default=["custom"], help="model(s) to run, i.e. --model yolov5n yolov5s")
opt = parser.parse_args()
for m in opt.model:
models[m] = torch.hub.load("./", m, path="best.pt", source="local")
app.run(host="0.0.0.0", port=opt.port) # debug=True causes Restarting with stat
这里也踩了很多雷。
路径问题
这两句是解决路径问题。
import pathlib
pathlib.WindowsPath = pathlib.PosixPath
选择模型并加载
这里要详细讲一下:
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Flask API exposing YOLOv5 model")
parser.add_argument("--port", default=6006, type=int, help="port number")
parser.add_argument("--model", default=["custom"], help="model(s) to run, i.e. --model yolov5n yolov5s")
opt = parser.parse_args()
for m in opt.model:
models[m] = torch.hub.load("./", m, path="best.pt", source="local")
app.run(host="0.0.0.0", port=opt.port) # debug=True causes Restarting with stat
-
models[m] = torch.hub.load("./", m, path="best.pt", source="local")- 这里的
path写best.pt表示使用模型路径,使用自己的模型。并且一定要加上source="local"表示使用本地的模型。
- 这里的
-
parser.add_argument("--model", default=["custom"], help="model(s) to run, i.e. --model yolov5n yolov5s")default要写custom表示使用哪个模型- 这里会去找
hubconf.py中有什么模型,使用custom模型,指定path为该路径下best.pt。 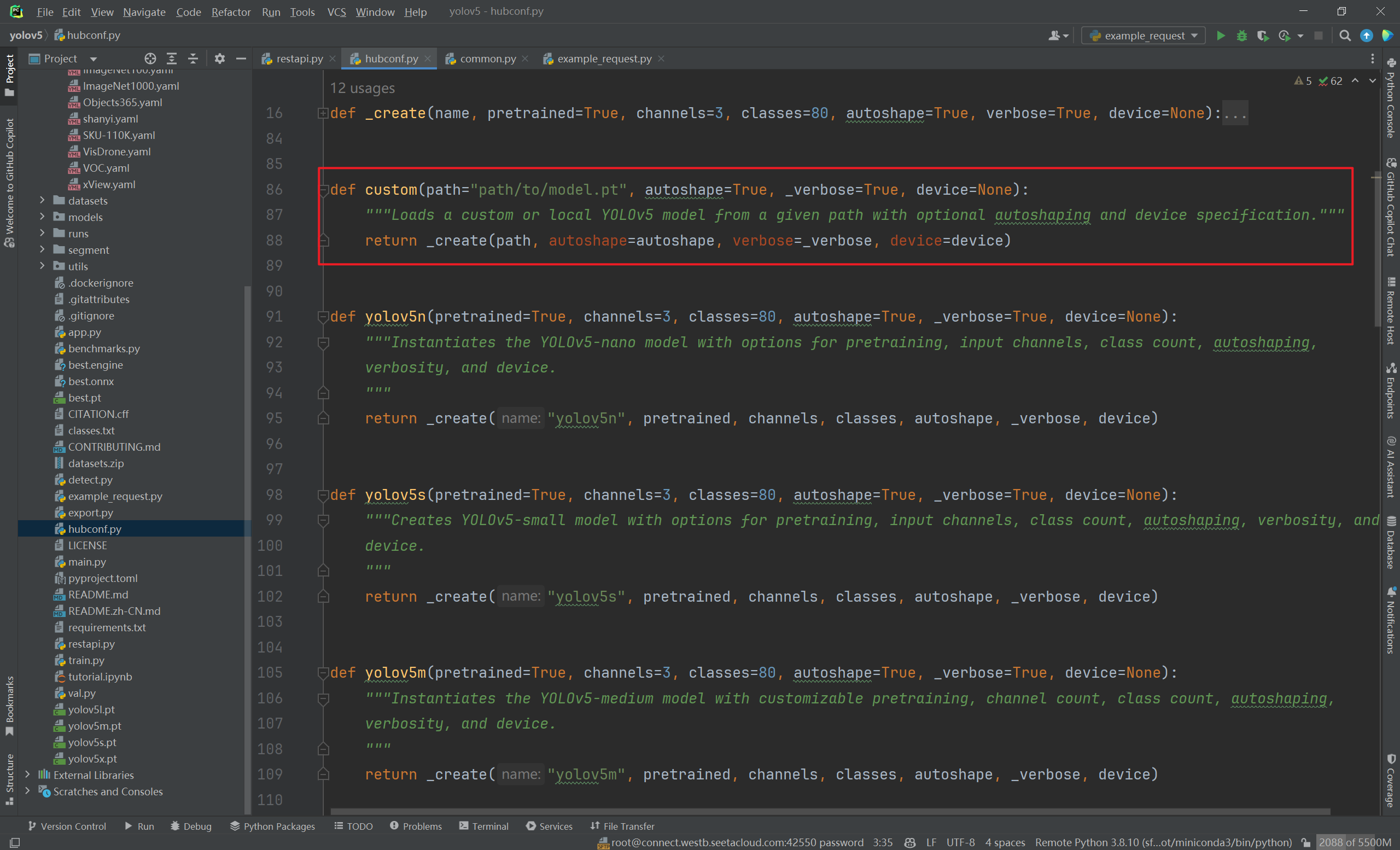
- 这里会去找
- 然后对应请求的路径也要写
/v1/object-detection/custom 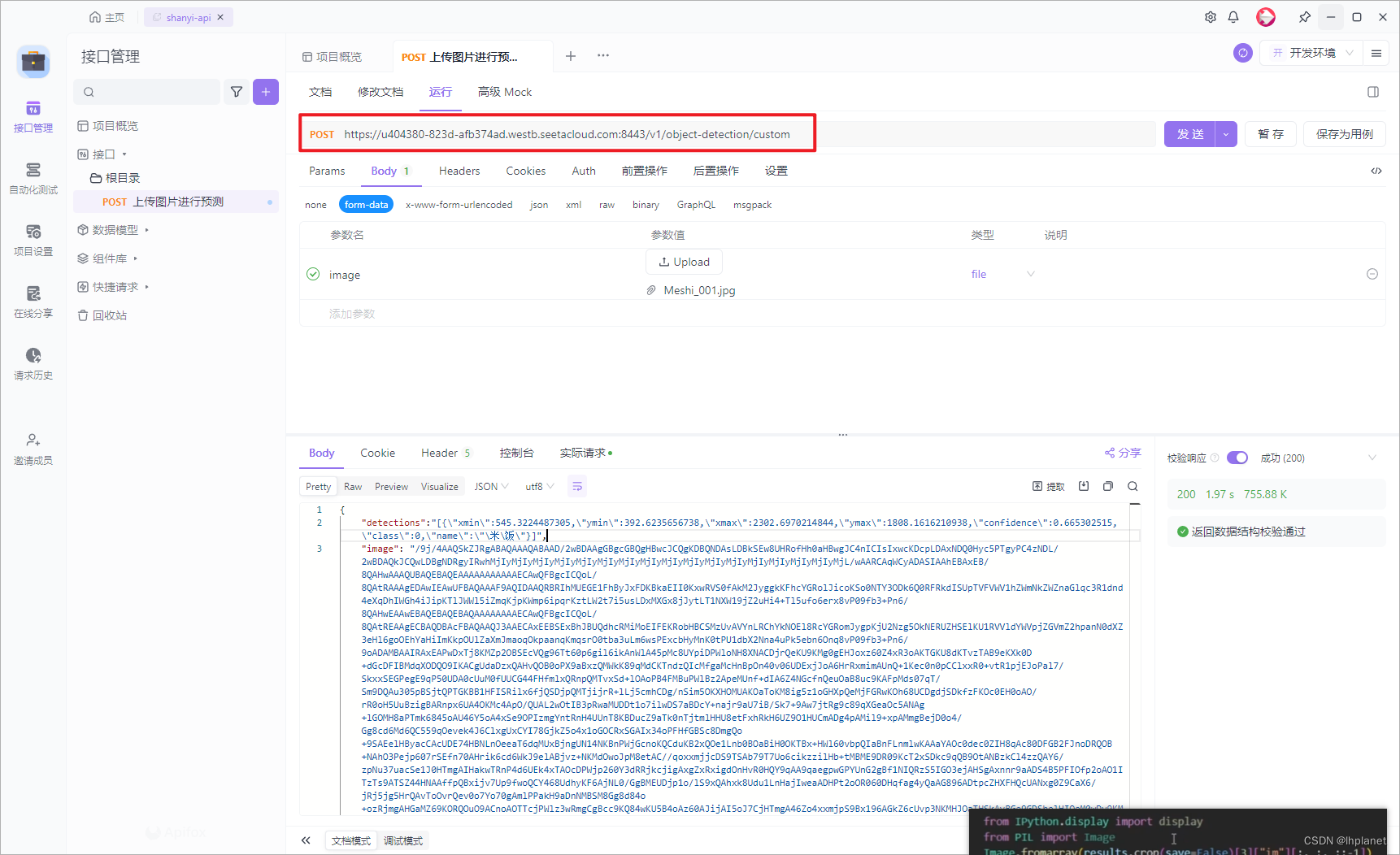
-
parser.add_argument("--port", default=6006, type=int, help="port number")- 端口号
6006,之前讲过原因了,AutoDL只给开放了这个端口。
- 端口号
接收请求参数
这里的image对应前端发来请求的key:
if request.files.get("image"):
处理推理结果
if model in models:
results = models[model](im, size=640) # reduce size=320 for faster inference
detections_json = results.pandas().xyxy[0].to_json(orient="records")
# return results.pandas().xyxy[0].to_json(orient="records")
# Convert rendered image to base64
buffered = io.BytesIO()
Image.fromarray(results.render()[0]).save(buffered, format="JPEG")
image_base64 = base64.b64encode(buffered.getvalue()).decode("utf-8")
# Return both detections and image as a JSON object
return jsonify(detections=detections_json, image=image_base64)
results = models[model](im, size=640)- 这里就拿到了推理结果。
detections_json = results.pandas().xyxy[0].to_json(orient="records")- 这句话可以拿到推理后的框的
xmin、ymin、xmax、ymax。然后转成json格式。 - 还可以调用:
- xyxyn:xyxy的归一化版本。
- xywh:返回中点坐标和宽高。
- xywhn:xywh的归一化版本。
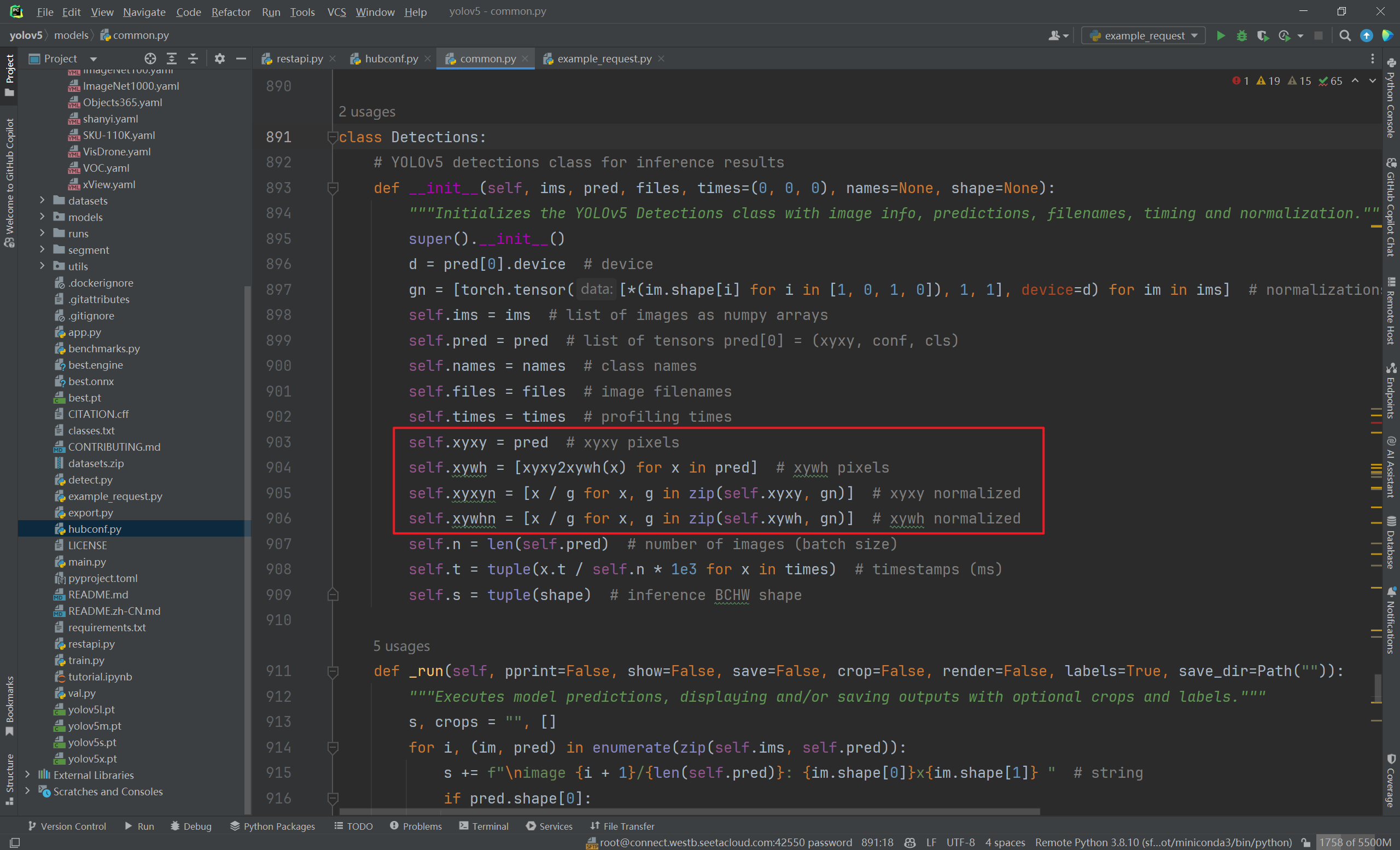
- 这句话可以拿到推理后的框的
- 下面三句是将推理后的图片以base64的格式返回。
- 这里我先使用的Apifox,所以先用在线网站查看效果。后期前端将其转换成图片展示即可。
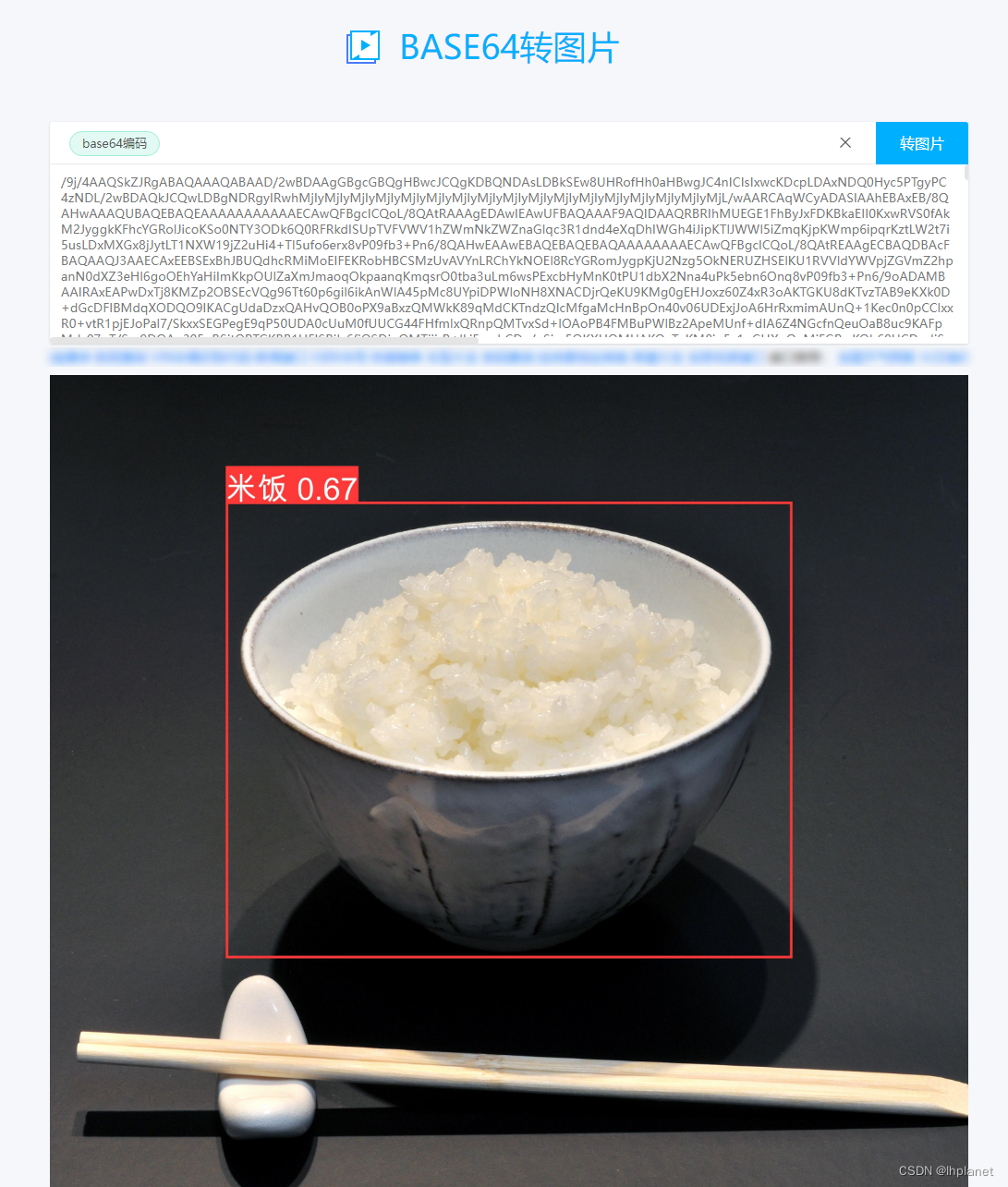
返回参数
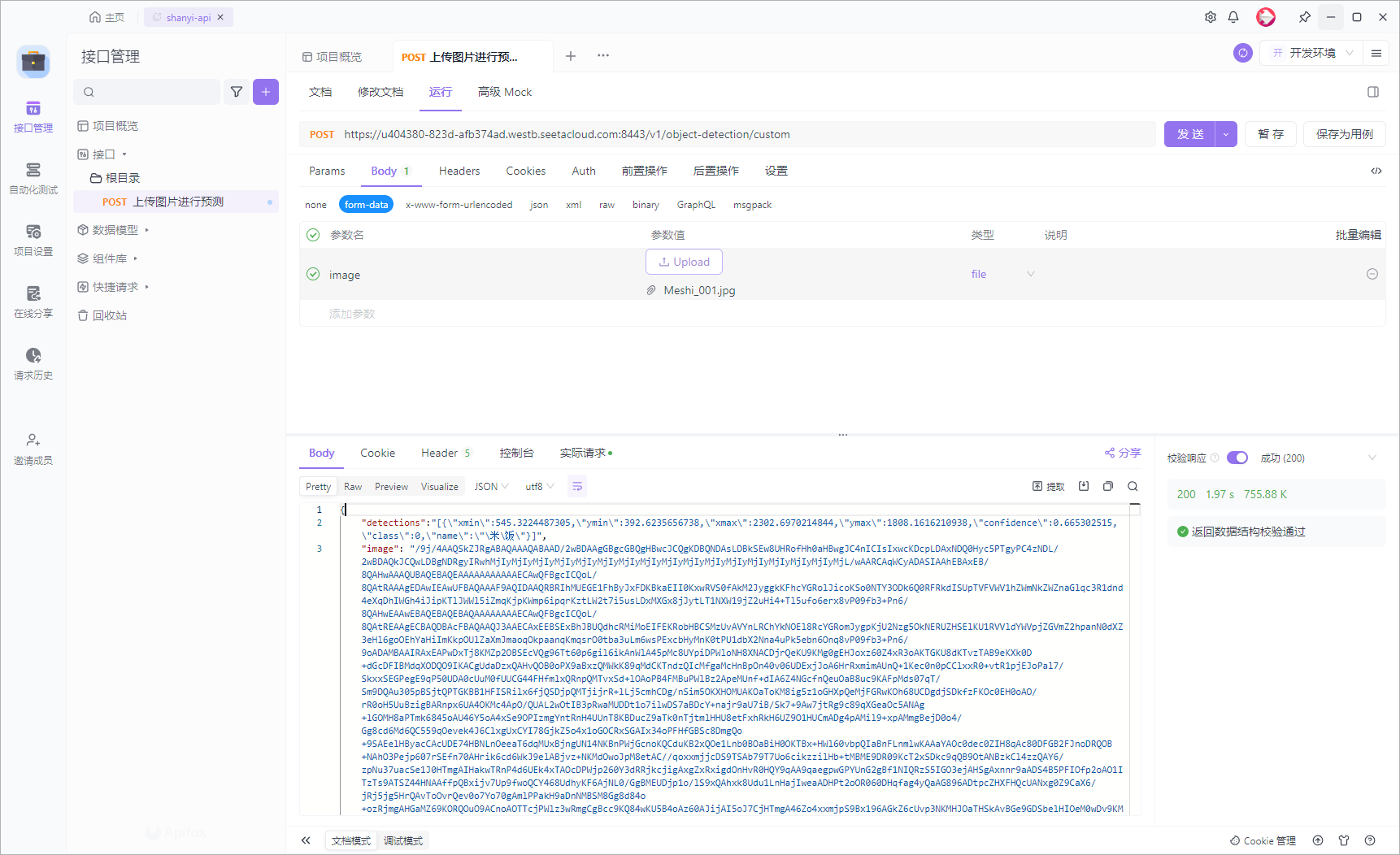
可以看到返回了框的xyxy位置,以及检测出的类别、置信度,还有图片的base64格式。
















 1070
1070

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











