






目录
实验一 Apriori算法设计与应用

这个好像是ChatGPT帮我写的,但是生成的强关联规则这个块,它好像不了解最大频繁集写不出,然后这部分是我改的(反正就是强关联规则少了很多)(代码文件是AprioriAlgorithm1.js)
function isSubset(subset, superset) {
return subset.every(item => superset.includes(item));
//子函数都满足
}
function arraysEqual(arr1, arr2) {
//判断所有子集中,和当前子集是存在的就返回真
return arr1.length === arr2.length && arr1.every((value, index) => value === arr2[index]);
}
// console.log(this.frequentItemSets)
//一个有多少个频繁项目集
let n = this.frequentItemSets.length;
let maxFrequentItemSets = [...this.frequentItemSets];
//如果一下有包含关系,就剔除它
for (let i = 0; i <n; i++) {
let currentItemSet = this.frequentItemSets[i];
let isMaximal = true;
//console.log(this.frequentItemSets)
// 检查是否有真正的超集
for (let j = 0; j < n; j++) {
//不和本身相符就继续
if (i !== j) {
let otherItemSet = this.frequentItemSets[j];
// 检查当前项集是否是其他项集的子集
if (isSubset(currentItemSet, otherItemSet)) {
//不是最大子集
isMaximal = false;
//不是就退出这个循环并进行剔除
break;
}
}
}
if (!isMaximal) {
// 从最大频繁项集列表中移除当前项集,filter 函数会保留那些与 currentItemSet 不相等的项集
maxFrequentItemSets = maxFrequentItemSets.filter(itemSet => !arraysEqual(itemSet, currentItemSet));
}
} 实验二 Close算法设计与应用
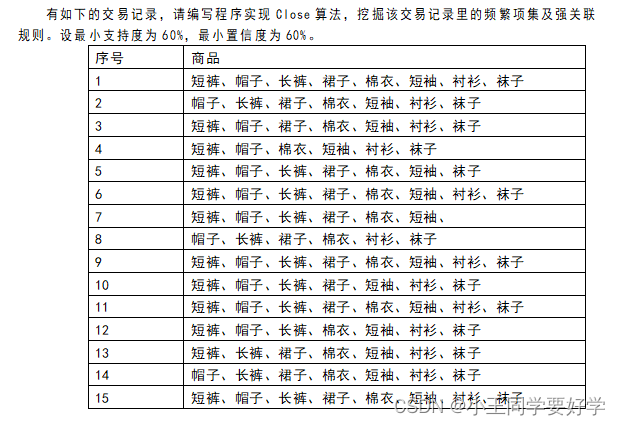
这个好像是我写的,因为ChatGPT写不出,它不理解什么意思,然后被迫上手,但是感觉结果有问题,我不知道怎么递归出来 (代码文件是close1.js)
实验三 FP-tree算法设计与应用

最后一天紧急之下ChatGPT终于写出了我想要的结果,因为树的基础不好不太会,修改了一下输出结果(代码文件是FP1.js)
实验四 EM算法设计与应用

理解
一个迭代的过程(三个函数)
1.E步处理函数(统计每一行最可能出现的是正面还是负面,用一维数组存储结果[ '正面', '反面', '反面', '正面', '反面' ])
2.M步处理函数(根据E步计算出的结果进行计算A和B的概率结果[A:0.4,B:0.9])
3.EM进行迭代
这个是根据一个B站up主(什么是EM最大期望算法_哔哩哔哩_bilibili)给的思路敲的,很简单(代码文件是em1.js)
实验五 KNN算法设计与应用

理解
两个函数
1.初始化以及循环(处理循环结束后,然后统计分组最多的等级,哪个等级多就是那个等级)
2.待分组和测试数据的处理(测试数据与分好组的数据找到差异最大的=>A,测试数据和带分组的数据之间的差异=>B,A>B就不替换,否则替换)
这个看书理解然后敲的(代码文件是knn1.js)
实验六 ID3算法设计与实现

有点忘是ChatGPT敲的还是自己敲的(代码文件是id31.js)
实验七 DBSCAN算法设计与应用

理解
四个函数
1.初始化(添加flag标志)
2.判断是不是可达点(统计这个点是不是满足阈值)
3.扩展簇的范围(距离公式满足就把点推进这个簇)
4.产生簇(如果是可达点且不在任何簇里 ====> 新建一个簇、推进这个簇并flag=1,然后扩展簇的范围)
这个看书理解然后敲的(代码文件是dbscan1.js)
实验八 K-mean算法设计与应用

理解
两个函数
1.初始化(把数组数据换成了键值的形式存储,拿到指定的初始数据的点,新建指定的几个簇map形式存储)
2.产生簇(双重for 遍历每个数据,让每个数据和指定的k个点去比较,距离最小就推进哪个2簇,直到结果)
3.迭代(对一次迭代产生的所有簇,进行中心点的统计,然后中心点不再变化就迭代结束)
这个看书理解然后敲的(代码文件是kmean1.js)
实验九 PageRank算法设计与应用
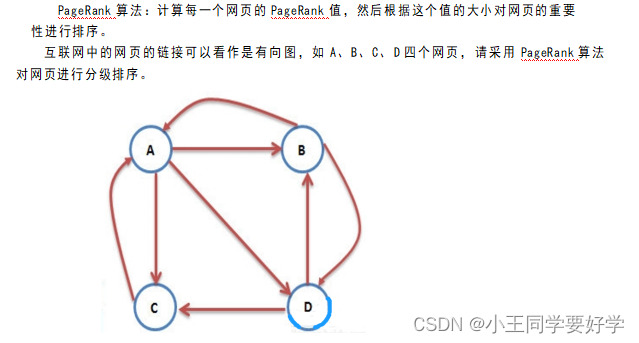
理解
这个和代数有关联,根据数学解题步骤去敲就行了
这个看书理解然后敲的(代码文件是pageRank1.js)
实验十 模型评估指标

理解
根据数学解题步骤去敲就行了
书上没有自己去找资源了解的,但是涉及的画图我就没搞了【使用python更好】,只搞了混淆矩阵,准确率,精确率等F1 Score (对于剩下的两个,我总感觉题目少了数据样本)(代码文件是mo1.js)
收获
反正就是建议自己去敲!!!
本来之前在写项目或学习项目时,不明白为什么API这么多的用处,然后敲完这个课设之后突然有点理解了,本来一开始不明白怎么处理数据的,接触之后就发现写算法还是蛮有意思,也明白了一些js数据处理的API,之前再写项目时一直用一种API,然后导致冗余度贼高。比如之前处理数据就经常使用foreach ,现在就是知道了map还有for of ,every,some 等在什么时候用更好了
仓库地址
https://gitee.com/Study_0112/dataming
运行
使用软件:Visual Studio Code,配置:node
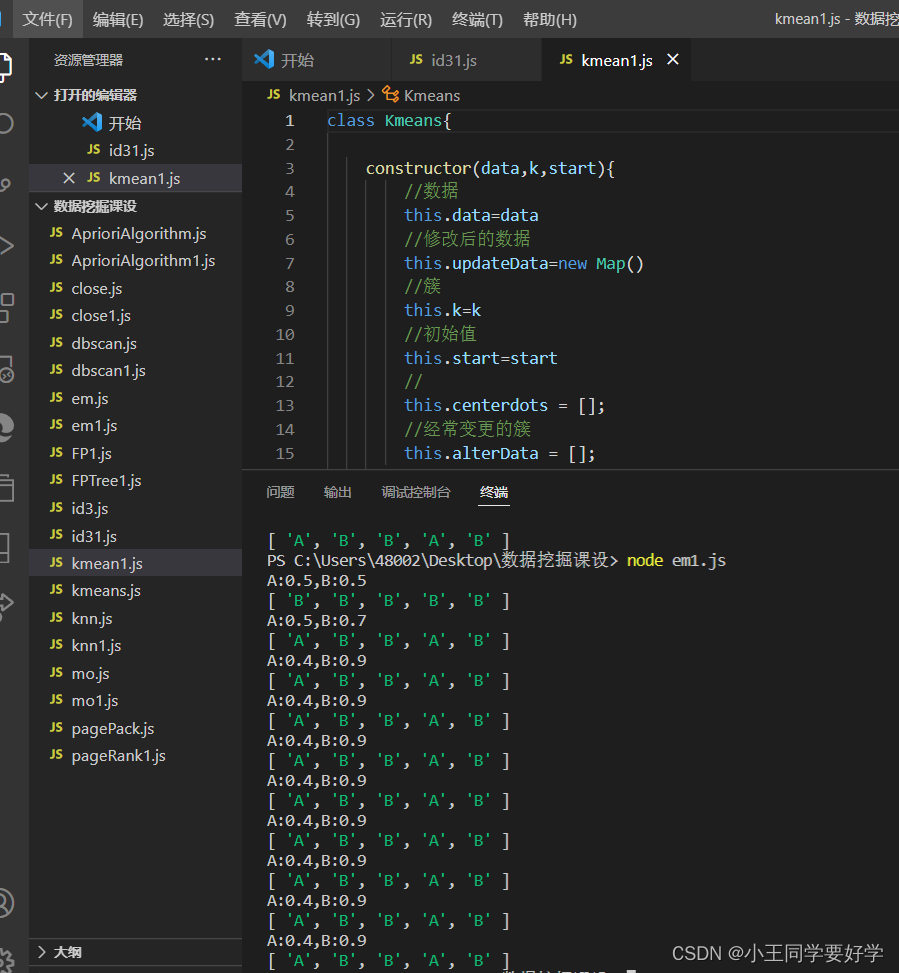
运行结果如下图:终端输入node 对应js 就可以了
声明
关于我是菜鸡的那件事
1.按理说我们应该只做5个题目,但是老师要求我们做10个,实际上我感觉应该有几个结果是错,有结果迭代有点糊涂特别是close,我们老师也没要求结果(意思就是能跑就行)。。。。
2.每个题目有两个代码文件,后面没有加1的可能是ChatGPT或自己写的半成品
3.emmm每个题目的代码都在一个文件,嫌调用文件的时候麻烦
5.从命名方式可以知道是不是我写的了(四级第一次擦边过,六级没报过名)
因为JavaScript基础好一点,所以果断用js(但是数据挖掘算法应该不建议用这个语言,本人算法很菜)















 980
980











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









