







目录
第一部分 概述
实验要求:
实验题目
题目一:蔬菜统计
根据“蔬菜.txt”的数据,利用Hadoop平台,实现价格统计与可视化显示。
要求:通过MapReduce分析列表中的蔬菜数据。
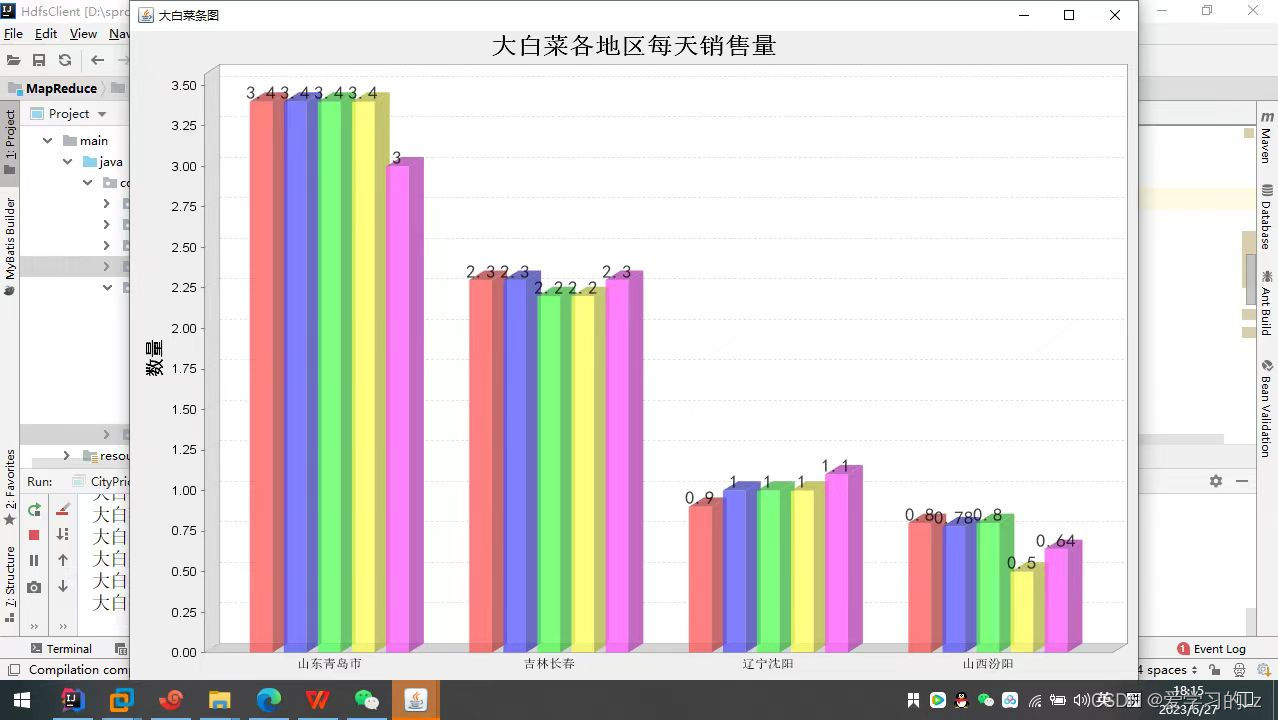
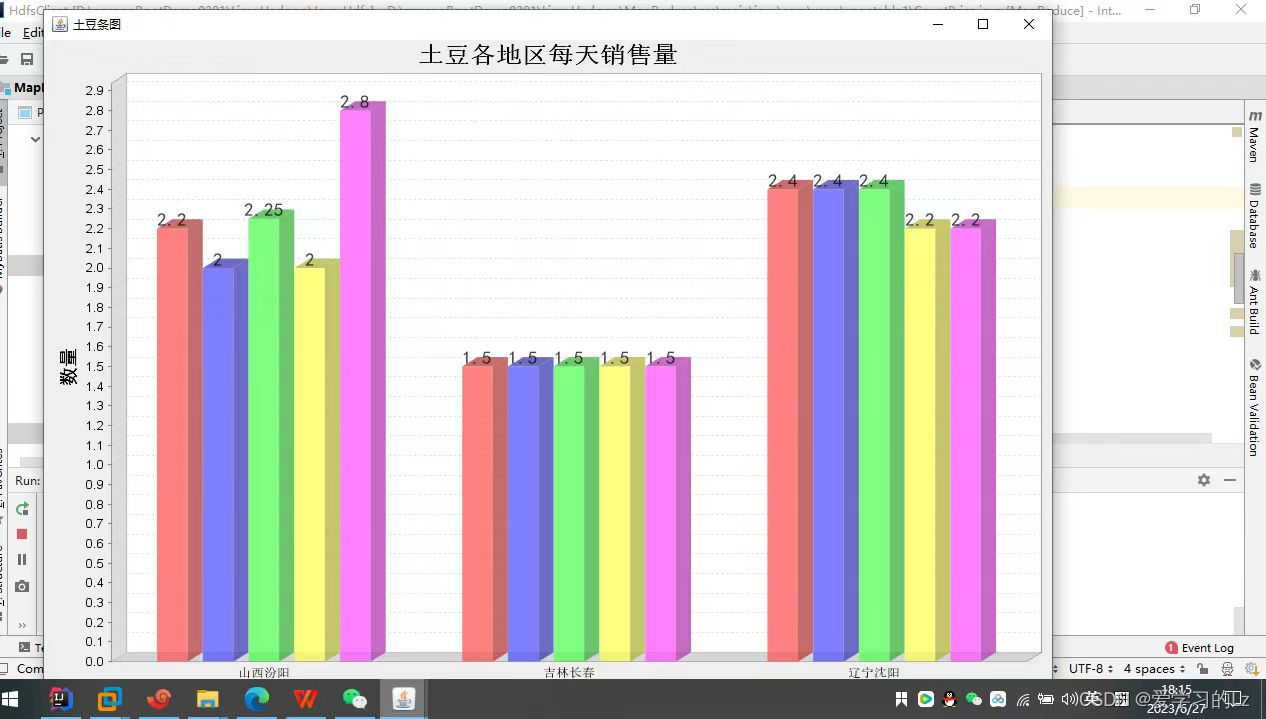
(1)统计各地区每一天大白菜、土豆的价格(柱状图)
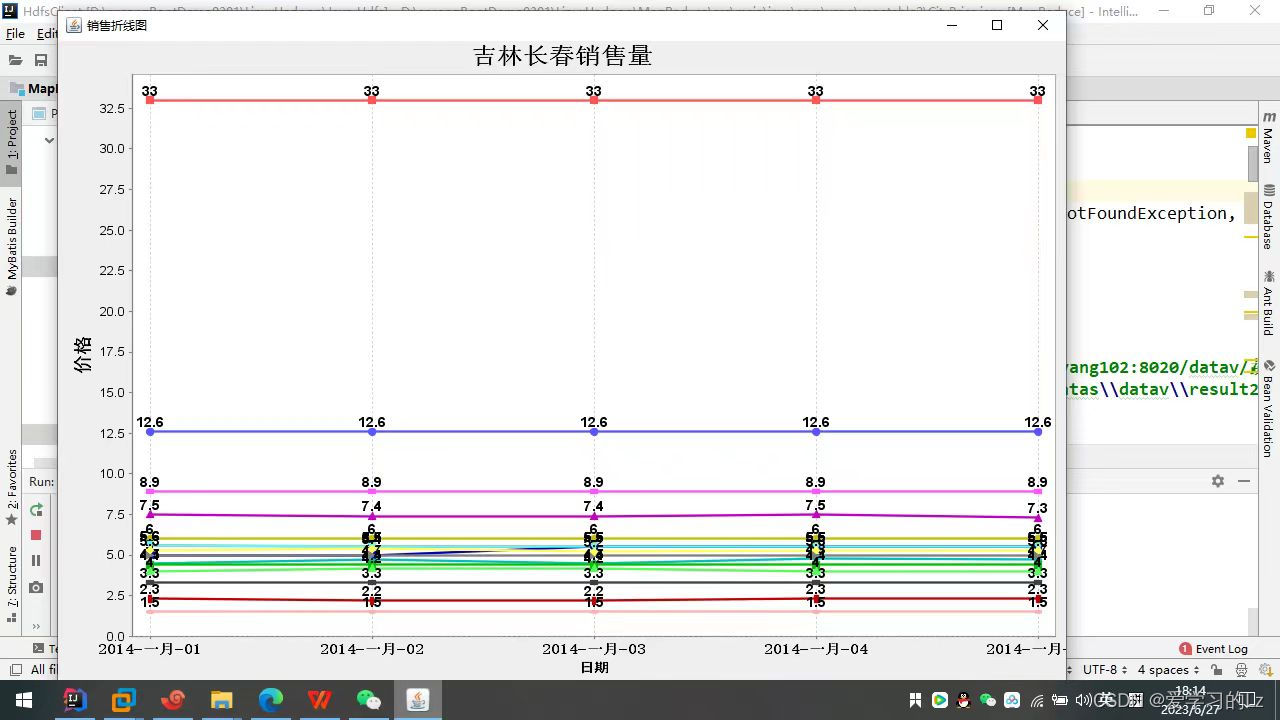
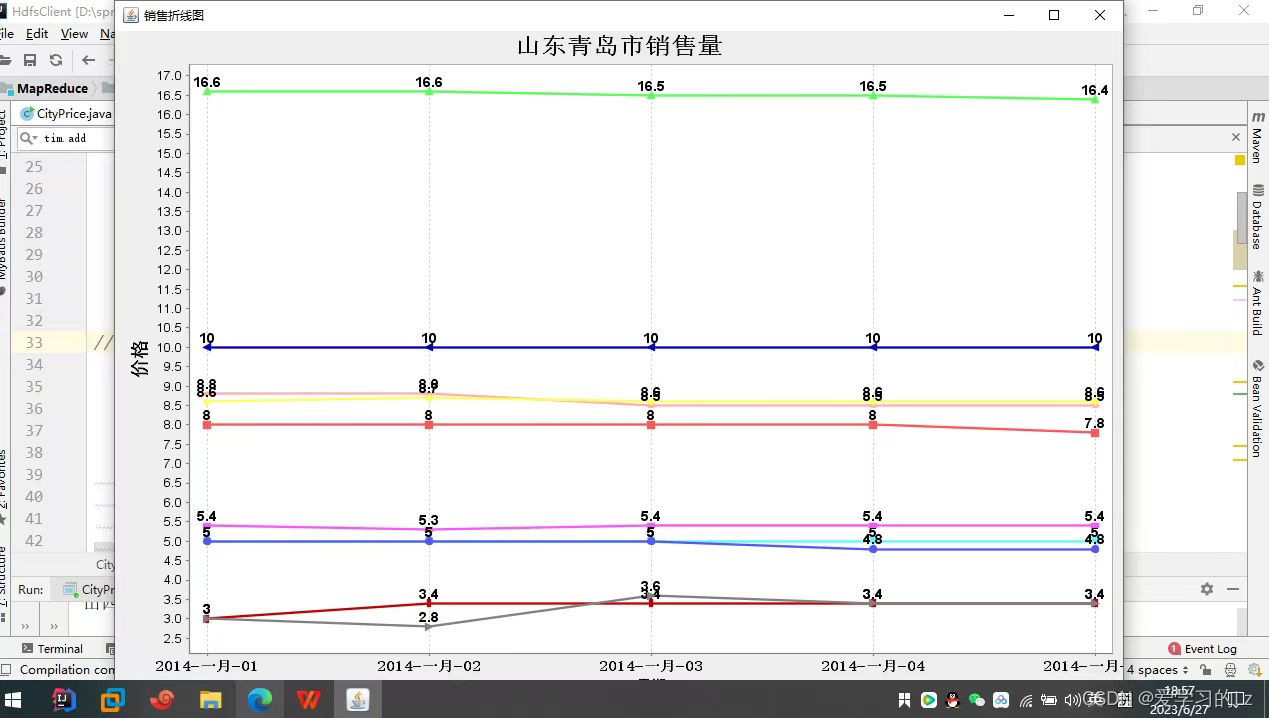
(2)选取一个城市,统计各个蔬菜价格变化曲线(折线图)
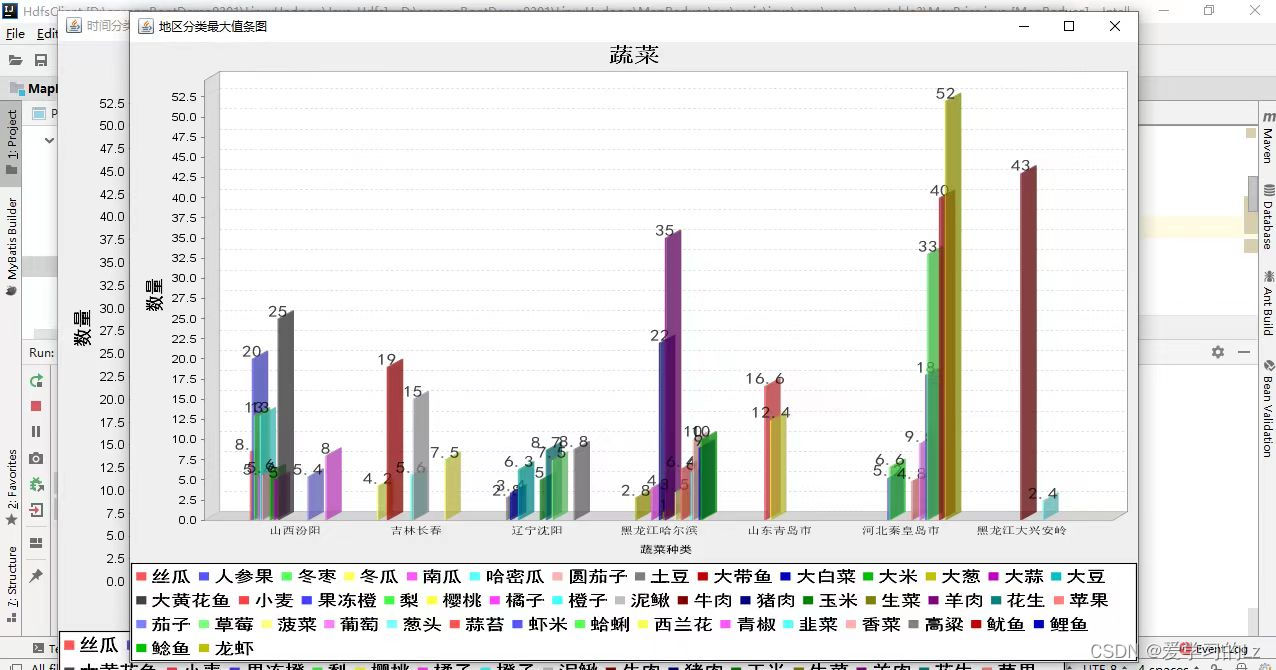
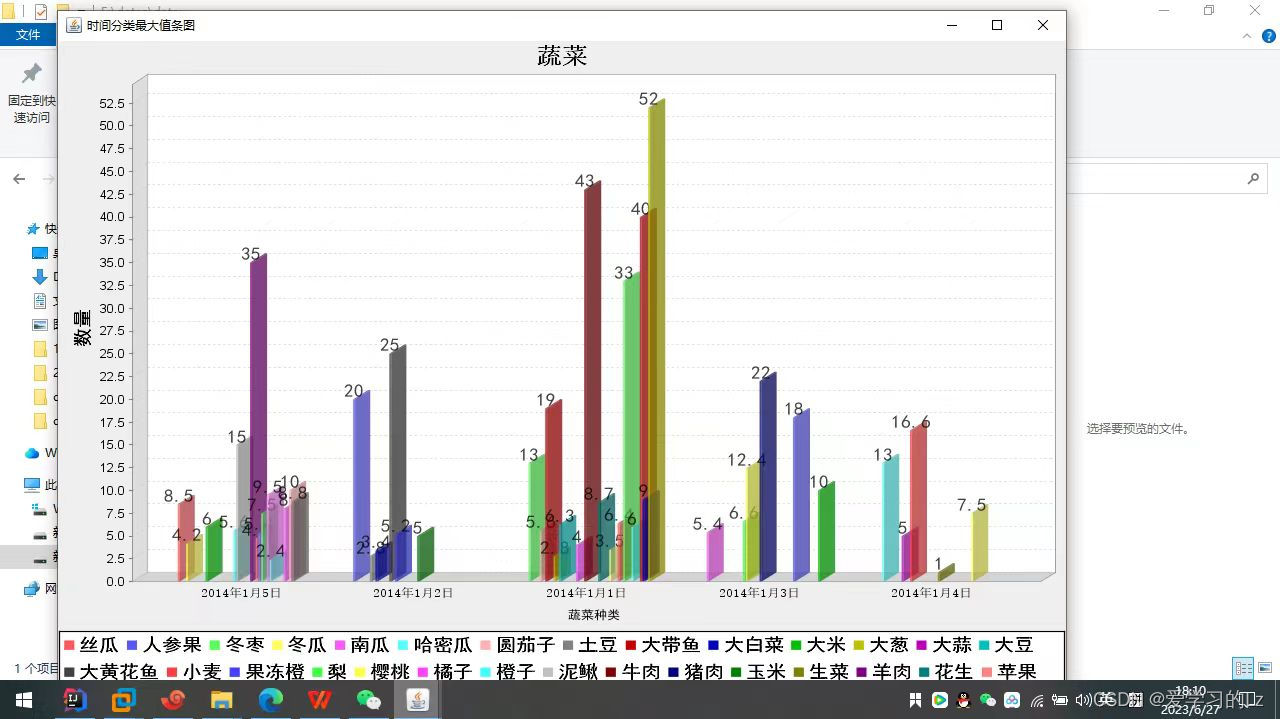
(3)统计每种蔬菜价格最高的地区和日期 (柱状图)
(4)加载Hbase、Hive等软件,并说明API
(1)map:按列表进行分片分区
(2)reduce:按照要求进行统计
实验目的
1.理解mapreduce执行原理
2.理解map,reduce阶段
3.了解排序的原理
第二部分 内容
实验思路
打开虚拟机,启动Hadoop伪分布式集群,将文本数据上传到hdfs。
题目一
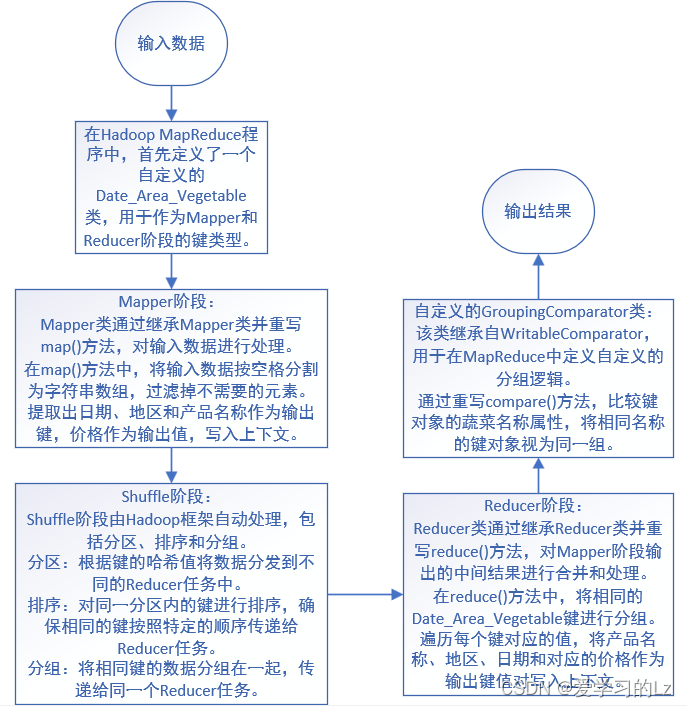
Mapper阶段:首先定义了一个自定义的Date_Area_Vegetable类作为Mapper阶段输出键的类型。然后,在Mapper类中,通过继承Mapper类并重写map()方法,对输入数据进行处理。在map()方法中,将输入数据按空格分割为字符串数组,过滤掉不需要的元素,并提取出日期、地区和产品名称作为输出键,价格作为输出值,写入上下文。Reducer阶段:在Reducer类中,通过继承Reducer类并重写reduce()方法,对Mapper阶段输出的中间结果进行合并和处理。在`reduce()`方法中,将相同的Date_Area_Vegetable键进行分组,并遍历每个键对应的值,将产品名称、地区、日期和对应的价格作为输出键值对写入上下文。自定义的Date_Area_Vegetable类:该类实现了WritableComparable接口,用于在MapReduce中作为键类型传递和比较。该类包含了地区、日期和蔬菜名称等属性,提供了构造函数和相关的getter和setter方法,以及实现了比较和序列化的方法。
自定义的GroupingComparator类:该类继承自WritableComparator,用于在MapReduce中定义自定义的分组逻辑。通过重写compare()方法,比较键对象的蔬菜名称属性,将相同名称的键对象视为同一组。整体思路是通过Mapper阶段将输入数据处理为键值对形式的中间结果,然后经过Shuffle阶段按照键进行分组和排序,最后在Reducer阶段对分组后的数据进行合并和处理,输出最终的结果。
题目二
定义了一个自定义的WritableComparable类Date_Area_Vegetable。它是用来表示日期、地区和蔬菜名称的组合的对象。重写了compareTo、write和readFields方法,实现了对象的比较和序列化操作。定义了一个自定义的分组比较器GroupingComparator类,继承自WritableComparator。它重写了compare方法,用于对相同蔬菜名称的数据进行分组。通过比较蔬菜名称的大小,将具有相同名称的数据分到同一个Reducer中进行处理。引入了JFreeChart库,并定义了一个LineChart类。该类用于绘制折线图。它包含了一个TimeSeriesCollection对象lineDataset,用于存储折线图的数据集。首先定义了Date_Area_Vegetable类和GroupingComparator类,用于MapReduce作业的数据处理。然后引入JFreeChart库,并定义了LineChart类,用于绘制折线图。在LineChart类中,plot方法用于绘制折线图,辅助方法用于获取图表对象和修改标题、添加数据系列。通过调用这些方法,可以实现绘制折线图的功能。
题目三
首先通过MapReduce任务计算蔬菜价格的最大值,并将结果写入输出文件。然后,通过读取输出文件,将统计结果添加到BarChart对象中,并使用JFreeChart库绘制相应的条形图。最后,将条形图展示在图形界面中。
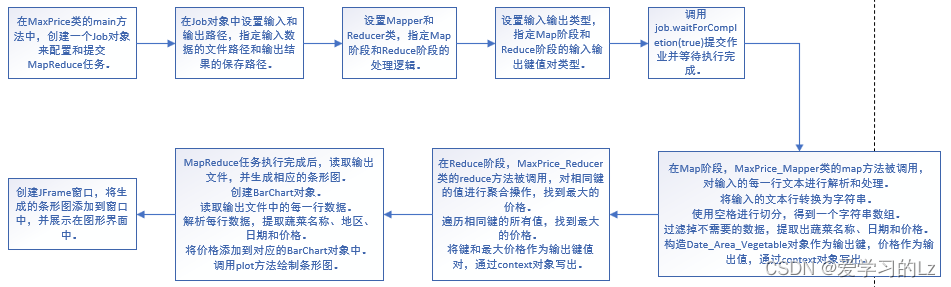
MaxPrice类的main方法的功能:创建一个Job对象来配置和提交MapReduce任务。指定输入和输出路径。设置Mapper和Reducer类。设置输入输出类型。提交作业并等待执行完成。读取输出文件,生成相应的条形图并展示。
MaxPrice_Mapper类:继承Mapper类,实现map方法。将输入数据按空格切分为字符串数组。通过迭代器遍历数组,过滤掉不需要的数据,获取蔬菜名称、日期和价格。构造Date_Area_Vegetable对象作为输出键,价格作为输出值,通过context对象写出。
MaxPrice_Reducer类:继承Reducer类,实现reduce方法。对相同键的值进行聚合操作,找到最大的价格。将键和最大价格作为输出键值对,通过context对象写出。
Date_Area_Vegetable类:实现WritableComparable接口,用于在Hadoop中进行数据的序列化和比较。定义了蔬菜的地区、日期和名称属性,提供了相应的getter和setter方法。
BarChart类:使用JFreeChart库进行条形图的绘制。定义了数据集和图表对象。提供了添加数据和绘制图表的方法。
GroupingComparator类:继承WritableComparator类,用于自定义分组逻辑。重写compare方法,按照蔬菜名称进行分组。
实验代码
题目一
//使用这种方法创建一个job对象
Job job = Job.getInstance();
job.setJarByClass(CountPrice.class);
job.setJobName("Get some Max Price");
//指定输入输出路径
FileInputFormat.addInputPath(job,new Path("hdfs://yang102:8020/datav/蔬菜.txt"));
FileOutputFormat.setOutputPath(job,new Path("E:\\datas\\datav\\result1"));
job.setInputFormatClass(TextInputFormat.class);//采用默认切片类型
job.setPartitionerClass(HashPartitioner.class);//采用Hash分区函数
//确定map类型和reduce类型
job.setMapperClass(CountPrice_Mapper.class);
job.setReducerClass(CountPrice_Reducer.class);
job.setGroupingComparatorClass(GroupingComparator.class);
//设置map输出类型
job.setMapOutputKeyClass(Date_Area_Vegetable.class);
job.setMapOutputValueClass(FloatWritable.class);
//控制reduce类型的输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FloatWritable.class);
//waitForCompletion()方法提交作业并等待执行完成
job.waitForCompletion(true);
Configuration conf = new Configuration();
Path inFile = new Path("E:\\datas\\datav\\result1\\part-r-00000");
FileSystem hdfs = FileSystem.get(conf);
FSDataInputStream inputStream = hdfs.open(inFile);
BufferedReader reader= new BufferedReader(new InputStreamReader(inputStream));
String str = reader.readLine();
BarChart chart_cabbage = new BarChart();
BarChart chart_potato = new BarChart();
while (str != null) {
System.out.println(str);
String[] values = str.split("\\s+");//以空格分隔出所有的value
String veg = values[0];
if (veg.equals("大白菜")){
String area = values[1];
String time = values[2];
float price = Float.parseFloat(values[3]);
chart_cabbage.addItem(price,time,area);
}else if(veg.equals("土豆")){
String area = values[1];
String time = values[2];
float price = Float.parseFloat(values[3]);
chart_potato.addItem(price,time,area);
}
str = reader.readLine();
}
chart_cabbage.plot();
chart_potato.plot();
chart_cabbage.changeMain("大白菜各地区每天销售量");
chart_potato.changeMain("土豆各地区每天销售量");
JFrame cabbage_frame=new JFrame("大白菜条图");
cabbage_frame.add(chart_cabbage.getChartPanel());
cabbage_frame.setBounds(50, 10, 1024, 768);
cabbage_frame.setVisible(true);
JFrame potato_frame=new JFrame("土豆条图");
potato_frame.add(chart_potato.getChartPanel());
potato_frame.setBounds(50, 10, 1024, 768);
potato_frame.setVisible(true);
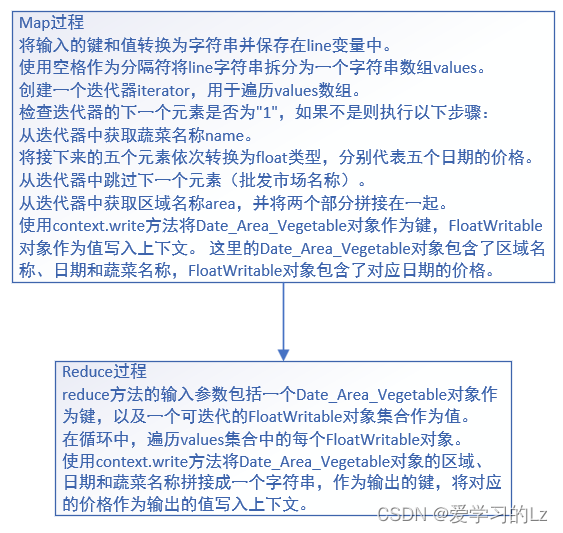
map过程
String line = value.toString();
String[] values = line.split("\\s+");//以空格分隔出所有的value
Iterator<String> iterator = Arrays.asList(values).iterator();//获得数组构造器
//过滤掉产品序号和第一行
if(!iterator.next().equals("1")){
String name = iterator.next();
if(name.equals("大白菜") || name.equals("土豆")){
float date1 = Float.parseFloat(iterator.next());
float date2 = Float.parseFloat(iterator.next());;
float date3 = Float.parseFloat(iterator.next());;
float date4 = Float.parseFloat(iterator.next());;
float date5 = Float.parseFloat(iterator.next());;
//过滤掉批发市场名称
iterator.next();
String area = iterator.next()+iterator.next();
}
题目二
//Job job = new Job(); 这种对象创建方法已弃用
Job job = Job.getInstance();//使用这种方法创建一个job对象
job.setJarByClass(CityPrice.class);
job.setJobName("Get some Max Price");
//指定输入输出路径
FileInputFormat.addInputPath(job,new Path("hdfs://yang102:8020/datav/蔬菜.txt"));
FileOutputFormat.setOutputPath(job,new Path("E:\\datas\\datav\\result2"));
//确定map类型和reduce类型
job.setMapperClass(CityPrice_Mapper.class);
job.setReducerClass(CityPrice_Reducer.class);
//设置map输出类型
job.setMapOutputKeyClass(Date_Area_Vegetable.class);
job.setMapOutputValueClass(FloatWritable.class);
//控制reduce类型的输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FloatWritable.class);
//waitForCompletion()方法提交作业并等待执行完成
job.waitForCompletion(true);
Configuration conf = new Configuration();
Path inFile = new Path("E:\\datas\\datav\\result2\\part-r-00000");
FileSystem hdfs = FileSystem.get(conf);
FSDataInputStream inputStream = hdfs.open(inFile);
BufferedReader reader= new BufferedReader(new InputStreamReader(inputStream));
String str = reader.readLine();
LineChart city_Line = new LineChart();
HashSet<String> n_set = new HashSet<>();
HashSet<TimeSeries> tn_set = new HashSet<>();
HashSet<String> c_set = new HashSet<>();
c_set.add("山东青岛");
String before = "山东青岛";
while (str != null) {
System.out.println(str);
String[] values = str.split("\\s+");//以空格分隔出所有的value
题目三
Job job = Job.getInstance();//使用这种方法创建一个job对象
job.setJarByClass(MaxPrice.class);
job.setJobName("Get some Max Price");
//指定输入输出路径
FileInputFormat.addInputPath(job,new Path("hdfs://yang102:8020/datav/蔬菜.txt"));
FileOutputFormat.setOutputPath(job,new Path("E:\\datas\\datav\\result3"));
//确定map类型和reduce类型
job.setMapperClass(MaxPrice_Mapper.class);
job.setReducerClass(MaxPrice_Reducer.class);
//设置map输出类型
job.setMapOutputKeyClass(Date_Area_Vegetable.class);
job.setMapOutputValueClass(FloatWritable.class);
//控制reduce类型的输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FloatWritable.class);
//waitForCompletion()方法提交作业并等待执行完成
job.waitForCompletion(true);
Configuration conf = new Configuration();
Path inFile = new Path("E:\\datas\\datav\\result3\\part-r-00000");
FileSystem hdfs = FileSystem.get(conf);
FSDataInputStream inputStream = hdfs.open(inFile);
BufferedReader reader = new BufferedReader(new InputStreamReader(inputStream));
第三部分 实验结果
第四部分 总结
在开发期间,有目的去用学习到的一些东西,仔细的考虑工作流程的规律和步骤,充分的利用手中的开发工具,使自己的开发精确,让用户能够尽量简单的进行操作。但还有很多不足之处,这些都要在今后的设计工作中要努力改进和完善的。
通过实际的开发项目,我学习并掌握各种技术知识和技能。深入了解Hadoop生态系统的各个组件和工具,学习使用Hadoop分布式文件系统HDFS、MapReduce编程模型等。学习到了数据清洗、处理大规模数据、优化性能等相关技能。通过蔬菜统计项目,学会了如何处理和分析大规模的数据集。使用MapReduce编程模型进行数据处理、使用适当的算法和技术进行数据分析和统计。提高了我的数据处理和分析能力,对数据驱动的决策和解决问题具有更深入的理解。在遇到问题时,我能良好的利用手中的工具进行问题的原因的查找,并自主解决问题,提高了我自我进行问题分析的能力。
在开发过程中遇到的第一个问题就是Hadoop虚拟机的配置问题,自己通过在网上查找解决办法,最终解决了Hadoop的环境问题。在开发过程中,出现了各种错误和异常情况。需要具备良好的调试能力,迅速定位和解决问题。同时对于可能发生的错误情况,还需要考虑合适的错误处理机制,以提高系统的健壮性和可靠性。
项目开发是一个不断改进和学习的过程。通过反思和总结项目经验,找到改进的空间,并在下一次项目中应用这些经验。持续改进和学习提高自己的工作质量和效率。无论在项目中遇到了哪些困难和挑战,重要的是从中学习并持续进步。将这些心得应用于将来的项目中,并继续发展和提升自己,这样我将能够成为一个更优秀的开发者。















 1537
1537

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









