







在使用一些chatgpt接口网站,发现有新建聊天页面的功能,于是我们也打算基于这个方向对我们的大模型进行拓展。
首先要解决的点是如何分别存储不同聊天的聊天记录。
我采用了使用 session_state 来达成存储不同聊天的聊天记录。
session_state 在 Streamlit 应用中用于在不同的运行之间保持状态
if 'chat_sessions' not in st.session_state:
st.session_state.chat_sessions = {"聊天1": []}
# 在边栏选择当前的聊天窗口
session_names = list(st.session_state.chat_sessions.keys())
current_session_name = st.sidebar.radio('选择聊天窗口', session_names)
# 当前聊天会话的历史记录
st.current_chat_history = st.session_state.chat_sessions[current_session_name]- 首先检查
st.session_state(它是一个类似于 Python 字典的对象)是否包含名为chat_sessions的键。如果不存在,则创建它,并以含有一个空列表的字典{"聊天1": []}初始化,这个列表将用来存储该聊天会话的历史记录。 - 接下来,从
st.session_state.chat_sessions获取所有聊天会话的名称,它们是字典的键。使用st.sidebar.radio在应用的侧边栏创建一个单选框,让用户可以从已经存在的聊天会话中选择一个。用户的选择会被存储在current_session_name变量中。 - 根据用户在侧边栏中选择的会话名称,从
st.session_state.chat_sessions字典中取出相应的历史记录列表,并将其赋值给st.current_chat_history。这样就可以在后续的代码中使用这个历史记录列表。
这种方式可以允许用户在同一个应用中同时进行多个聊天会话,并分别存储和管理每个会话的聊天记录,因为每个会话的历史记录都存储在一个命名的列表中,而所有这些列表又存储在 st.session_state.chat_sessions 字典中。当用户从侧边栏中选择一个聊天窗口时,应用将显示并更新对应窗口的聊天记录。
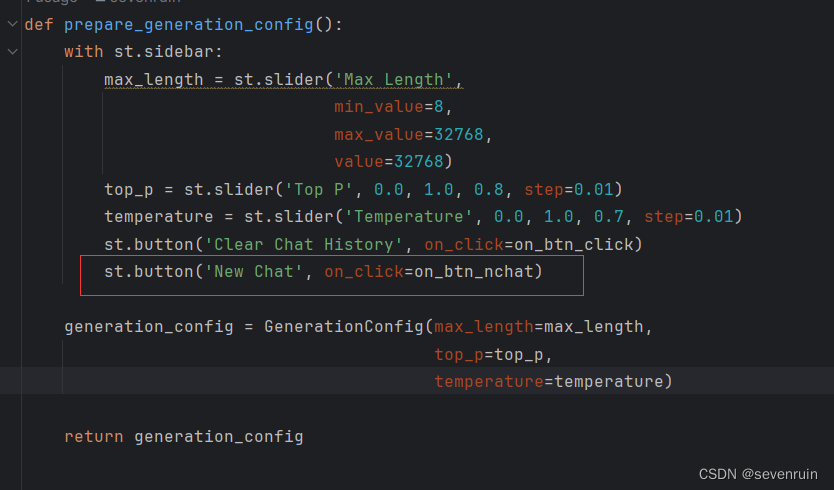
同时创建一个用于新建聊天的函数
def on_btn_nchat():
session_names = list(st.session_state.chat_sessions.keys())
session_count = len(st.session_state.chat_sessions)
new_session_name = f"聊天{session_count + 1}"
st.session_state.chat_sessions[new_session_name] = []
session_names.append(new_session_name) # Update the list with new session
把按钮添加到侧边栏
值得一提的是,由于现在使用的是
current_chat_history代替session_state.messages
来存储聊天历史,于是需要把之前用到session_state.messages的地方替换成current_chat_history
如下:


主要修改与main函数和combine_history函数。
修改后完整代码如下:
"""This script refers to the dialogue example of streamlit, the interactive
generation code of chatglm2 and transformers.
We mainly modified part of the code logic to adapt to the
generation of our model.
Please refer to these links below for more information:
1. streamlit chat example:
https://docs.streamlit.io/knowledge-base/tutorials/build-conversational-apps
2. chatglm2:
https://github.com/THUDM/ChatGLM2-6B
3. transformers:
https://github.com/huggingface/transformers
Please run with the command `streamlit run path/to/web_demo.py
--server.address=0.0.0.0 --server.port 7860`.
Using `python path/to/web_demo.py` may cause unknown problems.
"""
# isort: skip_file
import copy
import warnings
from dataclasses import asdict, dataclass
from typing import Callable, List, Optional
import streamlit as st
import torch
from torch import nn
from transformers.generation.utils import (LogitsProcessorList,
StoppingCriteriaList)
from transformers.utils import logging
from transformers import AutoTokenizer, AutoModelForCausalLM # isort: skip
logger = logging.get_logger(__name__)
@dataclass
class GenerationConfig:
# this config is used for chat to provide more diversity
max_length: int = 32768
top_p: float = 0.8
temperature: float = 0.8
do_sample: bool = True
repetition_penalty: float = 1.005
@torch.inference_mode()
def generate_interactive(
model,
tokenizer,
prompt,
generation_config: Optional[GenerationConfig] = None,
logits_processor: Optional[LogitsProcessorList] = None,
stopping_criteria: Optional[StoppingCriteriaList] = None,
prefix_allowed_tokens_fn: Optional[Callable[[int, torch.Tensor],
List[int]]] = None,
additional_eos_token_id: Optional[int] = None,
**kwargs,
):
inputs = tokenizer([prompt], padding=True, return_tensors='pt')
input_length = len(inputs['input_ids'][0])
for k, v in inputs.items():
inputs[k] = v.cuda()
input_ids = inputs['input_ids']
_, input_ids_seq_length = input_ids.shape[0], input_ids.shape[-1]
if generation_config is None:
generation_config = model.generation_config
generation_config = copy.deepcopy(generation_config)
model_kwargs = generation_config.update(**kwargs)
bos_token_id, eos_token_id = ( # noqa: F841 # pylint: disable=W0612
generation_config.bos_token_id,
generation_config.eos_token_id,
)
if isinstance(eos_token_id, int):
eos_token_id = [eos_token_id]
if additional_eos_token_id is not None:
eos_token_id.append(additional_eos_token_id)
has_default_max_length = kwargs.get(
'max_length') is None and generation_config.max_length is not None
if has_default_max_length and generation_config.max_new_tokens is None:
warnings.warn(
f"Using 'max_length''s default ({repr(generation_config.max_length)}) \
to control the generation length. "
'This behaviour is deprecated and will be removed from the \
config in v5 of Transformers -- we'
' recommend using `max_new_tokens` to control the maximum \
length of the generation.',
UserWarning,
)
elif generation_config.max_new_tokens is not None:
generation_config.max_length = generation_config.max_new_tokens + \
input_ids_seq_length
if not has_default_max_length:
logger.warn( # pylint: disable=W4902
f"Both 'max_new_tokens' (={generation_config.max_new_tokens}) "
f"and 'max_length'(={generation_config.max_length}) seem to "
"have been set. 'max_new_tokens' will take precedence. "
'Please refer to the documentation for more information. '
'(https://huggingface.co/docs/transformers/main/'
'en/main_classes/text_generation)',
UserWarning,
)
if input_ids_seq_length >= generation_config.max_length:
input_ids_string = 'input_ids'
logger.warning(
f"Input length of {input_ids_string} is {input_ids_seq_length}, "
f"but 'max_length' is set to {generation_config.max_length}. "
'This can lead to unexpected behavior. You should consider'
" increasing 'max_new_tokens'.")
# 2. Set generation parameters if not already defined
logits_processor = logits_processor if logits_processor is not None \
else LogitsProcessorList()
stopping_criteria = stopping_criteria if stopping_criteria is not None \
else StoppingCriteriaList()
logits_processor = model._get_logits_processor(
generation_config=generation_config,
input_ids_seq_length=input_ids_seq_length,
encoder_input_ids=input_ids,
prefix_allowed_tokens_fn=prefix_allowed_tokens_fn,
logits_processor=logits_processor,
)
stopping_criteria = model._get_stopping_criteria(
generation_config=generation_config,
stopping_criteria=stopping_criteria)
logits_warper = model._get_logits_warper(generation_config)
unfinished_sequences = input_ids.new(input_ids.shape[0]).fill_(1)
scores = None
while True:
model_inputs = model.prepare_inputs_for_generation(
input_ids, **model_kwargs)
# forward pass to get next token
outputs = model(
**model_inputs,
return_dict=True,
output_attentions=False,
output_hidden_states=False,
)
next_token_logits = outputs.logits[:, -1, :]
# pre-process distribution
next_token_scores = logits_processor(input_ids, next_token_logits)
next_token_scores = logits_warper(input_ids, next_token_scores)
# sample
probs = nn.functional.softmax(next_token_scores, dim=-1)
if generation_config.do_sample:
next_tokens = torch.multinomial(probs, num_samples=1).squeeze(1)
else:
next_tokens = torch.argmax(probs, dim=-1)
# update generated ids, model inputs, and length for next step
input_ids = torch.cat([input_ids, next_tokens[:, None]], dim=-1)
model_kwargs = model._update_model_kwargs_for_generation(
outputs, model_kwargs, is_encoder_decoder=False)
unfinished_sequences = unfinished_sequences.mul(
(min(next_tokens != i for i in eos_token_id)).long())
output_token_ids = input_ids[0].cpu().tolist()
output_token_ids = output_token_ids[input_length:]
for each_eos_token_id in eos_token_id:
if output_token_ids[-1] == each_eos_token_id:
output_token_ids = output_token_ids[:-1]
response = tokenizer.decode(output_token_ids)
yield response
# stop when each sentence is finished
# or if we exceed the maximum length
if unfinished_sequences.max() == 0 or stopping_criteria(
input_ids, scores):
break
def on_btn_click():
del st.session_state.messages
def on_btn_nchat():
session_names = list(st.session_state.chat_sessions.keys())
session_count = len(st.session_state.chat_sessions)
new_session_name = f"聊天{session_count + 1}"
st.session_state.chat_sessions[new_session_name] = []
session_names.append(new_session_name) # Update the list with new session
@st.cache_resource
def load_model():
model = (AutoModelForCausalLM.from_pretrained('./merged',
trust_remote_code=True).to(
torch.bfloat16).cuda())
tokenizer = AutoTokenizer.from_pretrained('./merged',
trust_remote_code=True)
return model, tokenizer
def prepare_generation_config():
with st.sidebar:
max_length = st.slider('Max Length',
min_value=8,
max_value=32768,
value=32768)
top_p = st.slider('Top P', 0.0, 1.0, 0.8, step=0.01)
temperature = st.slider('Temperature', 0.0, 1.0, 0.7, step=0.01)
st.button('Clear Chat History', on_click=on_btn_click)
st.button('New Chat', on_click=on_btn_nchat)
generation_config = GenerationConfig(max_length=max_length,
top_p=top_p,
temperature=temperature)
return generation_config
user_prompt = '<|im_start|>user\n{user}<|im_end|>\n'
robot_prompt = '<|im_start|>assistant\n{robot}<|im_end|>\n'
cur_query_prompt = '<|im_start|>user\n{user}<|im_end|>\n\
<|im_start|>assistant\n'
def combine_history(prompt):
messages = st.current_chat_history
meta_instruction = ('你是考研政治题库,内在是InternLM-7B大模型。你将对考研政治单选题,多选题以及综合题做详细、耐心、充分的解答,并给出解析。')
total_prompt = f"<s><|im_start|>system\n{meta_instruction}<|im_end|>\n"
for message in messages:
cur_content = message['content']
if message['role'] == 'user':
cur_prompt = user_prompt.format(user=cur_content)
elif message['role'] == 'robot':
cur_prompt = robot_prompt.format(robot=cur_content)
else:
raise RuntimeError
total_prompt += cur_prompt
total_prompt = total_prompt + cur_query_prompt.format(user=prompt)
return total_prompt
def main():
# torch.cuda.empty_cache()
print('load model begin.')
model, tokenizer = load_model()
print('load model end.')
user_avator = './user.png'
robot_avator = './robot.png'
st.title('我是你考研政治的助手,向我提问吧!')
generation_config = prepare_generation_config()
# Initialize chat history
if 'chat_sessions' not in st.session_state:
st.session_state.chat_sessions = {"聊天1": []}
# 在边栏选择当前的聊天窗口
session_names = list(st.session_state.chat_sessions.keys())
current_session_name = st.sidebar.radio('选择聊天窗口', session_names)
# 当前聊天会话的历史记录
st.current_chat_history = st.session_state.chat_sessions[current_session_name]
# 这是分界线
# Display chat messages from history on app rerun
for message in st.current_chat_history:
with st.chat_message(message['role'], avatar=message.get('avatar')):
st.markdown(message['content'])
# Accept user input
if prompt := st.chat_input('What is up?'):
# Display user message in chat message container
with st.chat_message('user', avatar=user_avator):
st.markdown(prompt)
real_prompt = combine_history(prompt)
# Add user message to chat history
st.current_chat_history.append({
'role': 'user',
'content': prompt,
'avatar': user_avator
})
with st.chat_message('robot', avatar=robot_avator):
message_placeholder = st.empty()
for cur_response in generate_interactive(
model=model,
tokenizer=tokenizer,
prompt=real_prompt,
additional_eos_token_id=92542,
**asdict(generation_config),
):
# Display robot response in chat message container
message_placeholder.markdown(cur_response + '▌')
message_placeholder.markdown(cur_response)
# Add robot response to chat history
st.current_chat_history.append({
'role': 'robot',
'content': cur_response, # pylint: disable=undefined-loop-variable
'avatar': robot_avator,
})
torch.cuda.empty_cache()
if __name__ == '__main__':
main()
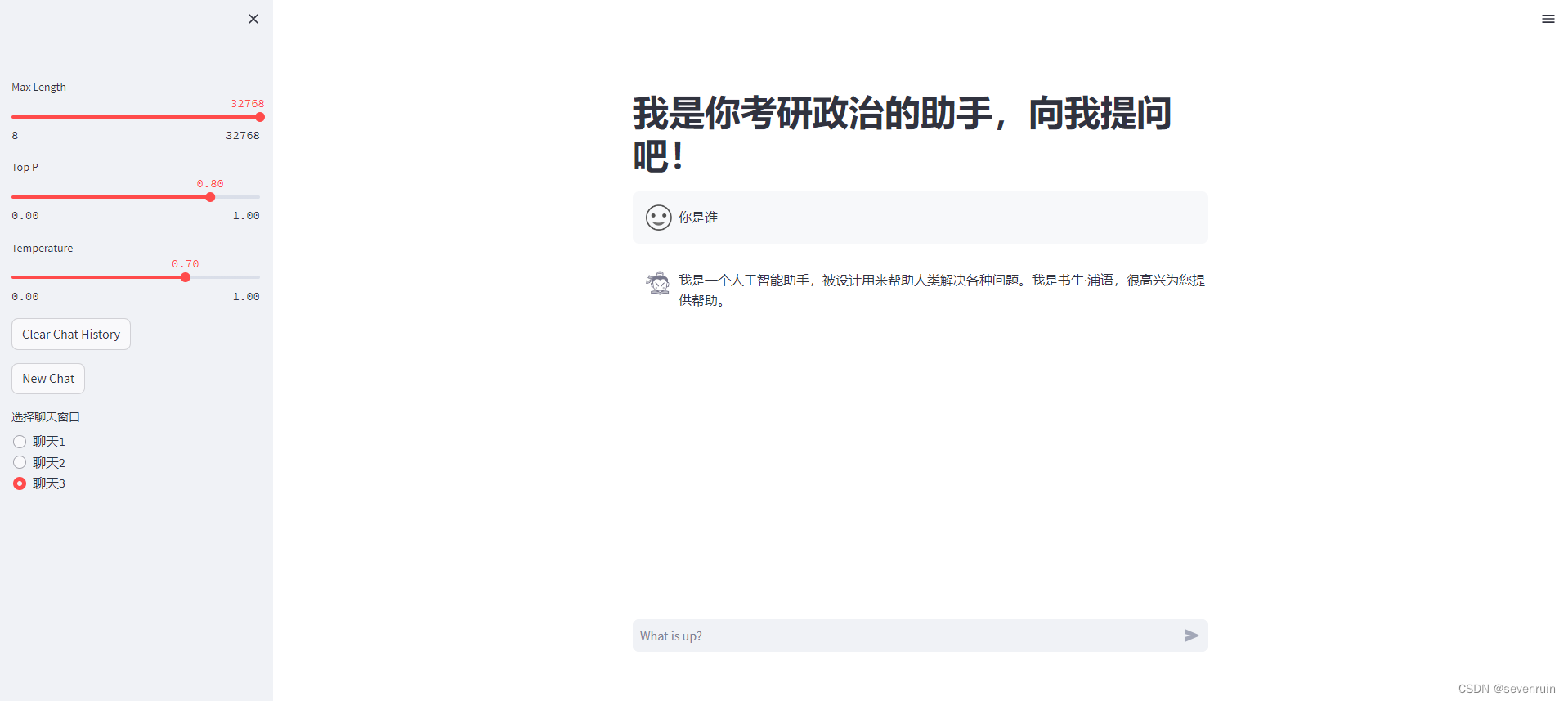
结果:
可以直接切换多个聊天,并且每个聊天记录都是独立的。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









