






目录
3 关联规则算法
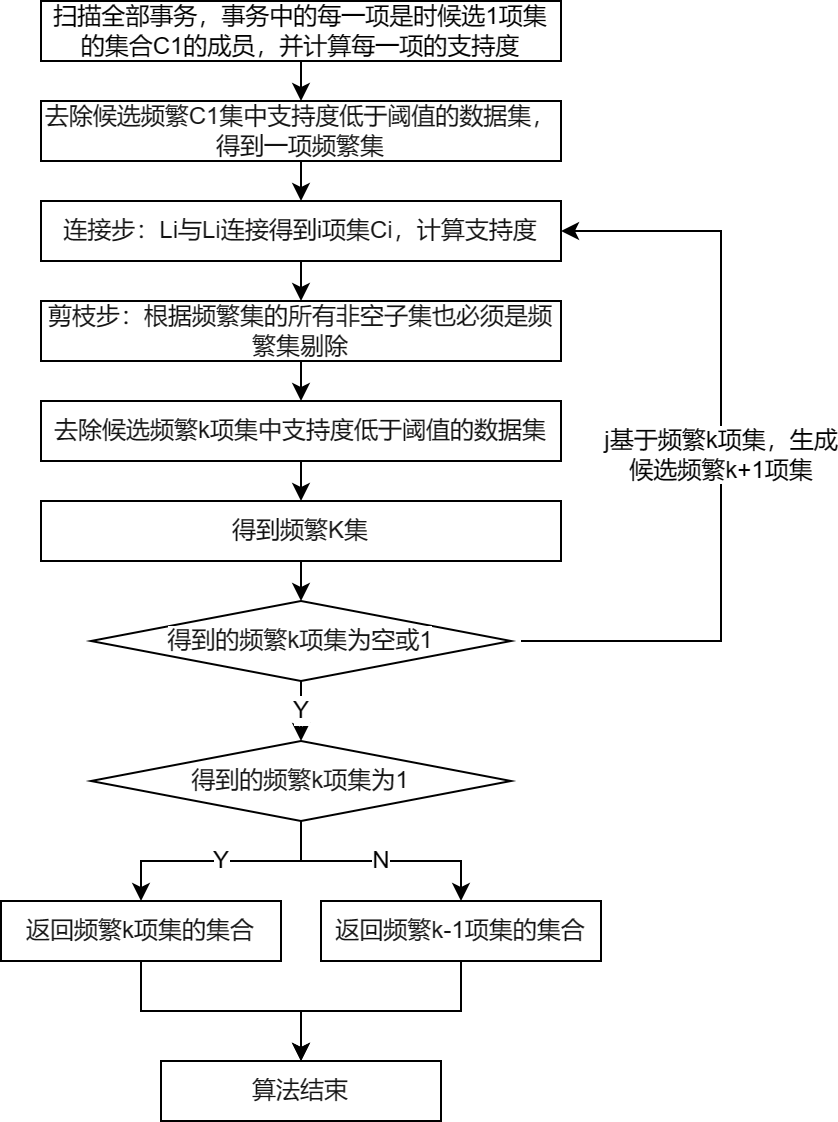
3.1 Apriori算法
算法
代码
# -*- coding: utf-8 -*-
from __future__ import print_function
import pandas as pd
from apriori import * # 导入自行编写的apriori函数
inputfile = '../data/menu_orders.xls'
outputfile = '../tmp/apriori_rules.xls' # 结果文件
data = pd.read_excel(inputfile, header = None)
#读入excel文件
print('\n转换原始数据至0-1矩阵...')
ct = lambda x : pd.Series(1, index = x[pd.notnull(x)]) # 转换0-1矩阵的过渡函数
b = map(ct, data.values) # 用map方式执行
data = pd.DataFrame(list(b)).fillna(0) # 实现矩阵转换,空值用0填充
print('\n转换完毕。')
del b # 删除中间变量b,节省内存
support = 0.2 # 最小支持度
confidence = 0.5 # 最小置信度
ms = '---' # 连接符,默认'--',用来区分不同元素,如A--B。需要保证原始表格中不含有该字符
find_rule(data, support, confidence, ms).to_excel(outputfile) # 保存结果结果为:
support confidence
e---a 0.3 1.000000
e---c 0.3 1.000000
c---e---a 0.3 1.000000
a---e---c 0.3 1.000000
c---a 0.5 0.714286
a---c 0.5 0.714286
a---b 0.5 0.714286
c---b 0.5 0.714286
b---a 0.5 0.625000
b---c 0.5 0.625000
a---c---e 0.3 0.600000
b---c---a 0.3 0.600000
a---c---b 0.3 0.600000
a---b---c 0.3 0.6000004 时序模式
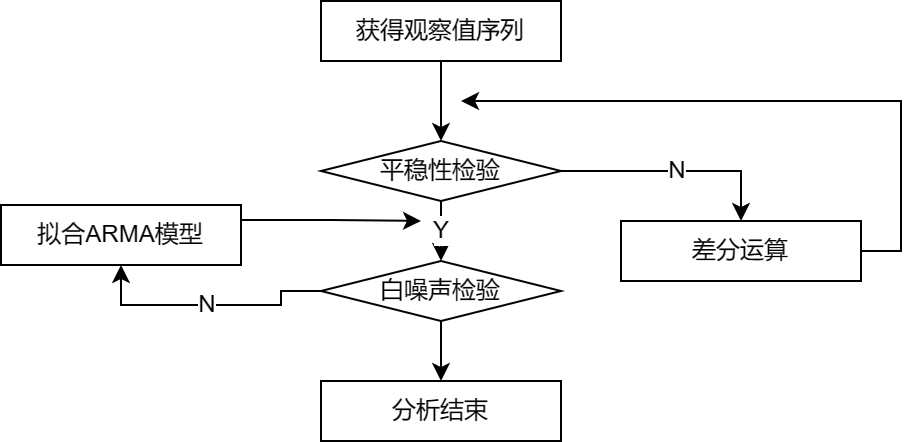
4.1 时间序列的预处理
纯随机序列(白噪声序列):序列的各项之间没有任何相关关系
平稳性检验:时序图检验,自相关图检验,单位根检验(常用)
纯随机性检验:一般用Q统计量和LB统计量,由样本各延迟期数的自相关系数可以计算得到的检验统计量,然后计算出对应的p值,如果p值大于显著性水平α,则表示该序列不能拒绝纯随机的原假设,可以停止对该序列进行分析。
4.2平稳时间序列分析
| 均值 | 方差 | 自相关系数ACF | 偏相关系数PACF | |
| AR | 常数均值 | 常数方差 | 拖尾 | p阶拖尾 |
| MA | 常数均值 | 常数方差 | q阶拖尾 | 拖尾 |
| ARMA | 常数均值 | 常数方差 | 拖尾 | 拖尾 |
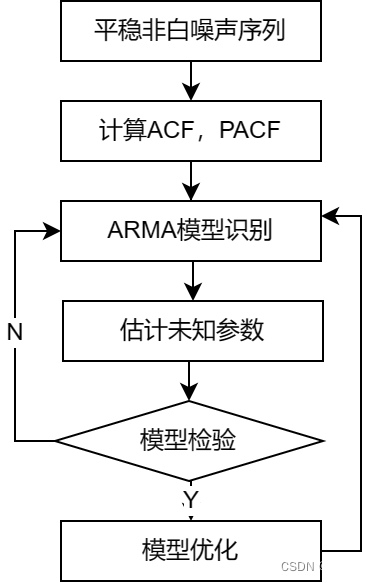
4.3非平稳时间序列分析
一般建立ARIMA模型,实际上就是差分运算与ARMA模型的组合
代码
# -*- coding: utf-8 -*-
import pandas as pd
# 参数初始化
discfile = '../data/arima_data.xls'
forecastnum = 5
# 读取数据,指定日期列为指标,pandas自动将“日期”列识别为Datetime格式
data = pd.read_excel(discfile, index_col = '日期')
# 时序图
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
data.plot()
plt.show()
# 自相关图
from statsmodels.graphics.tsaplots import plot_acf
plot_acf(data).show()
# 平稳性检测
from statsmodels.tsa.stattools import adfuller as ADF
print('原始序列的ADF检验结果为:', ADF(data['销量']))
# 返回值依次为adf、pvalue、usedlag、nobs、critical values、icbest、regresults、resstore
# 差分后的结果
D_data = data.diff().dropna()
D_data.columns = ['销量差分']
D_data.plot() # 时序图
plt.show()
plot_acf(D_data).show() # 自相关图
from statsmodels.graphics.tsaplots import plot_pacf
plot_pacf(D_data).show() # 偏自相关图
print('差分序列的ADF检验结果为:', ADF(D_data['销量差分'])) # 平稳性检测
# 白噪声检验
from statsmodels.stats.diagnostic import acorr_ljungbox
print('差分序列的白噪声检验结果为:', acorr_ljungbox(D_data, lags=1)) # 返回统计量和p值
from statsmodels.tsa.arima_model import ARIMA
# 定阶
data['销量'] = data['销量'].astype(float)
pmax = int(len(D_data)/10) # 一般阶数不超过length/10
qmax = int(len(D_data)/10) # 一般阶数不超过length/10
bic_matrix = [] # BIC矩阵
for p in range(pmax+1):
tmp = []
for q in range(qmax+1):
try: # 存在部分报错,所以用try来跳过报错。
tmp.append(ARIMA(data, (p,1,q)).fit().bic)
except:
tmp.append(None)
bic_matrix.append(tmp)
bic_matrix = pd.DataFrame(bic_matrix) # 从中可以找出最小值
p,q = bic_matrix.stack().idxmin() # 先用stack展平,然后用idxmin找出最小值位置。
print('BIC最小的p值和q值为:%s、%s' %(p,q))
model = ARIMA(data, (p,1,q)).fit() # 建立ARIMA(0, 1, 1)模型
print('模型报告为:\n', model.summary2())
print('预测未来5天,其预测结果、标准误差、置信区间如下:\n', model.forecast(5))
模型报告为:
Results: ARIMA
====================================================================
Model: ARIMA BIC: 422.5101
Dependent Variable: D.销量 Log-Likelihood: -205.88
Date: 2023-03-14 14:24 Scale: 1.0000
No. Observations: 36 Method: css-mle
Df Model: 2 Sample: 01-02-2015
Df Residuals: 34 02-06-2015
Converged: 1.0000 S.D. of innovations: 73.086
No. Iterations: 11.0000 HQIC: 419.418
AIC: 417.7595
----------------------------------------------------------------------
Coef. Std.Err. t P>|t| [0.025 0.975]
----------------------------------------------------------------------
const 49.9563 20.1390 2.4806 0.0131 10.4846 89.4280
ma.L1.D.销量 0.6710 0.1648 4.0712 0.0000 0.3480 0.9941
-----------------------------------------------------------------------------
Real Imaginary Modulus Frequency
-----------------------------------------------------------------------------
MA.1 -1.4902 0.0000 1.4902 0.5000
====================================================================
预测未来5天,其预测结果、标准误差、置信区间如下:
(array([4873.96669163, 4923.9229817 , 4973.87927177, 5023.83556184,
5073.79185191]), array([ 73.08574235, 142.32681277, 187.54284185, 223.80284499,
254.95707349]), array([[4730.72126884, 5017.21211442],
[4644.96755464, 5202.87840875],
[4606.30205618, 5341.45648735],
[4585.19004602, 5462.48107766],
[4574.08517026, 5573.49853355]]))
5.离群点检测
常用检测方法包括:基于统计,基于临近度,基于密度,基于聚类
5.1基于模型的离群点检测方法
一元正态分布
遵照3σ原则
混合模型的离群点检测
将数据看做从不同的概率分布得到的观测值集合
5.2基于聚类的离群点检测方法
丢弃原理其他簇的小簇
基于原型的聚类

基于原型的聚类的改进及代码

# -*- coding: utf-8 -*-
import numpy as np
import pandas as pd
# 参数初始化
inputfile = '../data/consumption_data.xls' # 销量及其他属性数据
k = 3 # 聚类的类别
threshold = 2 # 离散点阈值
iteration = 500 # 聚类最大循环次数
data = pd.read_excel(inputfile, index_col = 'Id') # 读取数据
data_zs = 1.0*(data - data.mean())/data.std() # 数据标准化
from sklearn.cluster import KMeans
model = KMeans(n_clusters = k, n_jobs = 4, max_iter = iteration) # 分为k类,并发数4
model.fit(data_zs) # 开始聚类
# 标准化数据及其类别
r = pd.concat([data_zs, pd.Series(model.labels_, index = data.index)], axis = 1) # 每个样本对应的类别
r.columns = list(data.columns) + ['聚类类别'] # 重命名表头
norm = []
for i in range(k): # 逐一处理
norm_tmp = r[['R', 'F', 'M']][r['聚类类别'] == i]-model.cluster_centers_[i]
norm_tmp = norm_tmp.apply(np.linalg.norm, axis = 1) # 求出绝对距离
norm.append(norm_tmp/norm_tmp.median()) # 求相对距离并添加
norm = pd.concat(norm) # 合并
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
norm[norm <= threshold].plot(style = 'go') # 正常点
discrete_points = norm[norm > threshold] # 离群点
discrete_points.plot(style = 'ro')
for i in range(len(discrete_points)): # 离群点做标记
id = discrete_points.index[i]
n = discrete_points.iloc[i]
plt.annotate('(%s, %0.2f)'%(id, n), xy = (id, n), xytext = (id, n))
plt.xlabel('编号')
plt.ylabel('相对距离')
plt.show()
















 1646
1646











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









