







文章目录
C++入门第一课
1. C++发展简史
C/C++语言的产生都是从大名顶顶的贝尔实验室里被研发出来的,最早期C语言被广泛应用做操作系统软件和设备驱动程序设计的首选语言,UNIX操作系统就是使用C语言开发的第一个大型软件系统。并且实际上,现在的大多数操作系统都是用C/C++语言实现的。
但是随着C语言的广泛使用,出现了许多不兼容的版本,这对于C的可移植性来说是一个非常严重的问题,后来C语言又诞生了C99版本。
但是C/C++之父,就是我们的祖师爷Bjarne Stroustrup,也就是本贾尼博士对C语言进行了扩展,所以C++就横空出世啦。
关于C++的设计和演化,本贾尼博士的著作《The Design and Evolution of C++》中有详细的叙述,其中总结了C++的一些设计原则:
-
C++的每一步演化和发展必须是由于实际问题所引起的。
-
C++是一门编程语言,而不是一个完整的系统
-
不能无休止地一味追求完美
-
C++再其存在的“当时”必须是有用处的
-
每一种语言特性必须有明确的实现方案
-
总能提供一种变通的方法
…
所以说在C++的演化过程中,来自客户的反馈的语言实现者们积累的经验是最为重要的。
2.C++关键字
C++(C++98版本)共有63个关键字,是在C语言32个关键字的基础上进行了扩充。
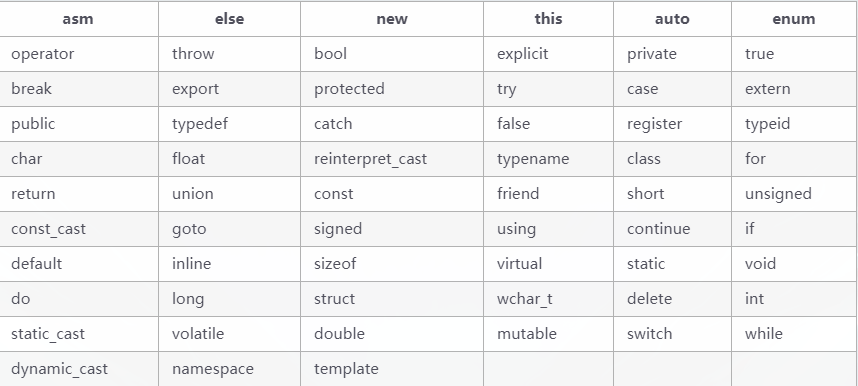
如果你想了解这些关键字,可以点这里-》传送门
3.C++运行环境
在windows系统中,我们大多都使用一些编译器软件来进行代码编写,比如vs201x编译器,vscode等。
而在linux系统中,则是使用安装g++的编译器进行编译,因为linux系统是才用命令行的形式,比较难上手,所以新手还是先采用熟悉的系统进行代码编写比较好。
我们知道在vs中,如何切换C和C++俩种运行环境,是利用文件名的后缀来进行选择哪个一种语言环境。
例如: Test.c -----C编译器
Test.cpp-------C++编译器
而在linux系统中,也是利用文件名后缀来使用对应的编译器。
- gcc ------C编译器
- g++ -------C++编译器
4.C++头文件以及输入输出
4.1 头文件
按照上面所说的,我们要使用c++,就是必须创建.cpp后缀的源文件。
在学习C语言的时候,我们会引入 #include <stdio.h>的头文件
这是C语言标准输入输出的库。
而在C++也有自己标准输入输出流的库,也就是 < iostream > 的头文件
在后面C++的学习,也会学到io流的知识,涉及到这个头文件
引入#include < iostream > ,我们可以正常输入输出了
4.2输入输出
在C语言中,我们会运用scanf语句和print语句来进行输入输出
而在C++中,也有自己的语句来进行输入输出
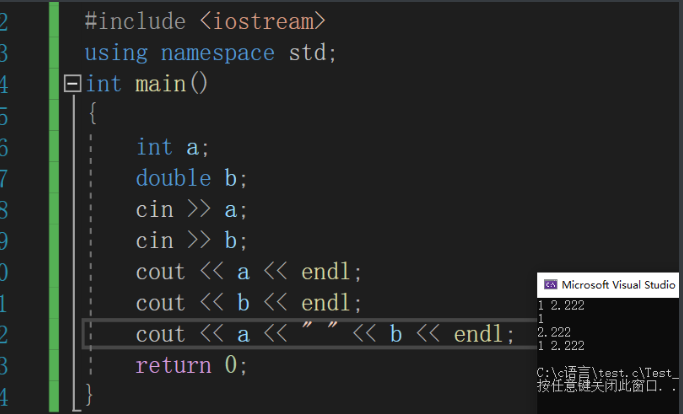
从以上的例子我们可以对比一下C语言的语法
cin>>a; 就相当于 scanf("%d",&a);
cout<<a<<endl; 就相当于 printf("%d",a);
我们可以看到 >>和<<这个俩个操作符很熟悉,是我们C语言所学的位操作符
但在C++中,也有另一种含义,一词俩用,分别是
>>流提取运算符
<<流插入运算符
而 cin 是输入 cout 是输出 endl (end of line)是换行
使用 cout 标准输出 ( 控制台 ) 和 cin 标准输入 ( 键盘 ) 时,必须 包含 < iostream > 头文件 以及 std 标准命名空间。
注意:早期标准库将所有功能在全局域中实现,声明在 .h 后缀的头文件中,使用时只需包含对应头文件即可,后来将其实现在std 命名空间下,为了和 C 头文件区分,也为了正确使用命名空间,规定 C++ 头文件不带.h ;旧编译器 (vc 6.0) 中还支持 <iostream.h> 格式,后续编译器已不支持,因此 推荐 使用 +std 的方式。
对于命名空间的学习,我们放在下面学习跳转
我们可以看到 a和b都是不同的数据类型,而我们不用在像C语言那样,增加格式控制符(%s,%d,%f)来控制输入输出,
-
编译器会自己判断它们的类型
同样的我们也可以通过多次使用<< 或者>>来进行输入输出多个数据
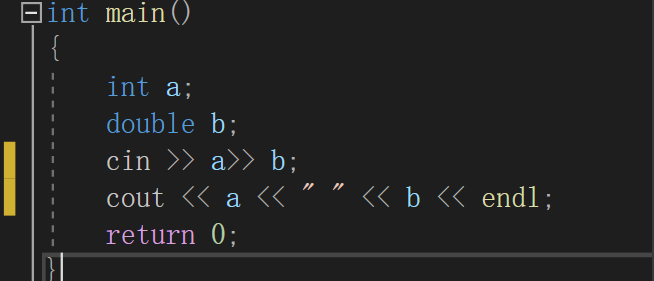
而如果你想控制输出格式,C++控制格式的方式比较复杂
我们也可以直接调用printf语句,毕竟C++是兼容C的
还有endl 我们也可以换成 ’\n ’
5.命名空间(namespace)
在上面使用C++的输入输出的时候,我们使用的是使用 +std 的方式
即是包含 < iostream > 头文件 以及 std 标准命名空间。
#include <iostream>
using namespace std;
这里的std标准命名空间就是C++的一个库,里面定义着C++的****变量,函数,类型****
那命名空间究竟是什么呢?
我们可以知道在我们的main函数里面,如果存在中同名的变量,函数,或者结构,编译器是会报错的。
我们可以举个例子,假如在班上,我们有俩位同学是同名的,但是我们可以通过俩人的附加属性来区别这两人,比如外貌,家庭住址等等
而在C++中,为了对标识符的名称进行本地化,以避免命名冲突或名字****污染,
就使用了命名空间(namespace)这个关键字来进行区分
在项目开发里,很多的都是团队开发,如果包含的头文件的库函数,
和自己定义的变量命名相同,会产生冲突(c语言里面没有很好解决这个问题,
只有一方让步)
c++中,cpp引入namespace 解决这个问题
5.1命名空间的定义
定义命名空间,则使用
namespace 关键字 +命名空间的名字
{
命名空间的成员(\变量,函数,结构)
}
5.2解决命名冲突
我们可以知道,同个域内是不能出现同名的参数的
而namespace相当于隔离了参数,不会出现冲突
冲突是因为同个作用域里,不能同时存在
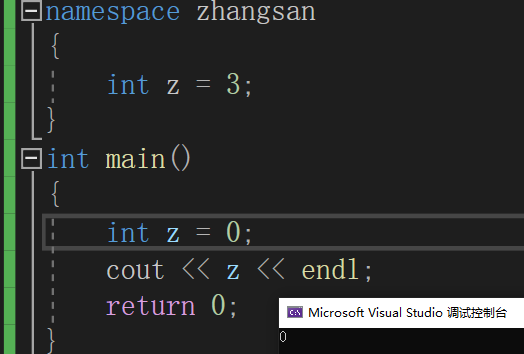
我们可以看到程序正常运行,并没有发生命名冲突
但是我们访问的是main域内的变量,那我们要怎么访问到全局域中命名空间里面的同名变量呢?
这时候就使用在C语言中学习的 ::域作用限定符
域名(空白默认全局域)::访问的变量
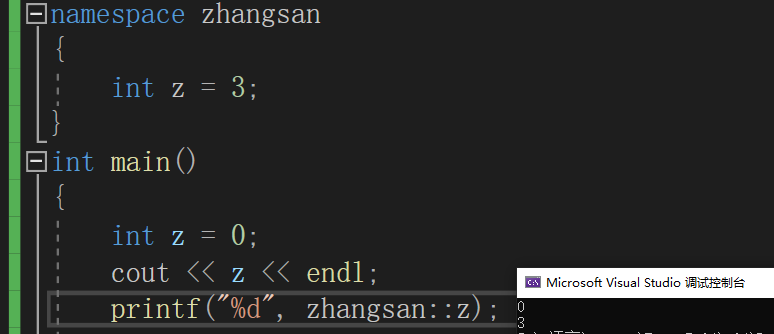
同样的,除了定义变量外我们也可以定义同样的结构体在不同的命名空间里,不会产生命名冲突
namespace zhangsan
{
struct ListNode
{
int val;
struct ListNode* next;
};
}
namespace lisi
{
struct ListNode
{
int val;
struct ListNode* next;
};
}
int main()
{
zhangsan::ListNode* n1 = NULL;
lisi::ListNode* n2 = NULL;
}
5.3命名空间的特点
1.同一个工程中允许存在多个相同名称的命名空间,编译器最后会合成同一个命名空间中。
namespace zhangsan
{
int a;
}
namespace zhangsan
{
int b;
}
但是我们如果命名空间内如果是定义同样的变量或者结构体,都是会命名冲突的,因为编译器
会合成同一个命名空间中,产生冲突,而且同个命名空间域在不同文件也会冲突
这里我们就可以利用命名空间的第二个特点了
- 俩个同名命名空间域可以嵌套,可以访问嵌套内的命名空间域
namespace zhangsan
{
namespace data
{
struct ListNode
{
int val;
struct ListNode* next;
};
}
}
namespace zhangsan
{
namespace cache
{
struct ListNode
{
int val;
struct ListNode* next;
};
}
}
int main()
{
zhangsan::data::ListNode* n1 = NULL;
zhangsan::cache::ListNode* n2 = NULL;
}
严格按C语言要在结构前面加上struct,上面是以c++方式,已经升级成了类,不用加
struct zhangsan::data::ListNode* n1 = NULL; //C
zhangsan::data::ListNode* n1 = NULL; //C++
5.4命名空间的使用
namespace zhangsan
{
int a;
int b;
struct ListNode
{
int val;
struct ListNode* next;
};
}
int main()
{
printf("%d",a); //该语句编译出错,无法识别a
}
我们可以通过三种方式来使用这个命名空间进行访问
-
加命名空间名称及作用域限定符
int main() { printf("%d",zhangsan::a); }- 使用using将命名空间中成员引入(using的使用下面会提到)
using zhangsan::b; int main() { printf("%d",zhangsan::a); printf("%d",b); } -
使用using namespace 命名空间名称引入
using namespace zhangsan //成员都可以使用 int main() { printf("%d",a); printf("%d",b); ListNode* n1 = NULL; }
6.using的使用
6.1使用using释放命名空间
using 就是把命名空间的内容展开,就相当于把里面的变量或者类型放出来,但是注意命名空间里面的都是全局的。
我们上面所提到的std方式,
using namespace std;//std 封c++库的命名空间
也是运用using 将std的c++标准库放出来,让我们访问使用
6.2如果不使用using
所以我们在用cout输出的时候就不用在前面加上std : :
如果没有使用using的话
我们平时使用使用输出函数就只能打出
std::cout<<"hello world "<<std ::endL;
但是放出来就会存在冲突风险
6.3释放特定命名空间
我们也可以只放出来一个
using std::cout;
int main()
{
cout<<"hello world<<std ::endL;
return 0;
}
7.缺省参数
缺省参数是声明或定义函数时为函数的参数指定一个默认值。在调用该函数时,如果没有指定实参则采用该默认值,否则使用指定的实参
用通俗易懂的话来说,缺省函数就是一个备胎,在没有指定实参(正房)的时候,缺省函数(备胎)就派上用场了。
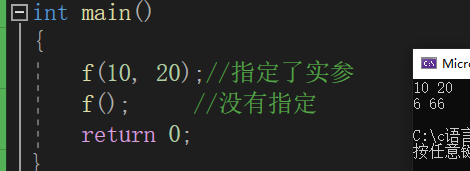
void f(int a=6,int b=66)
{
cout<<a<<" "<<b<<endl;
}
int main()
{
f(10,20);//指定了实参
f(); //没有指定
return 0;
}
7.1全缺省和半缺省
-
像上面这种,函数中的所有形参都设定了缺省值的,叫做全缺省
-
函数中只有一部分设置了缺省值的,叫做半缺省,
注意:并不是缺少一半的参数才叫半缺省,一部分也算。
设置缺省参数的时候,必须从右往左设置,传实参的时候,都是不能出现中间空一个的情况
7.1.1 全缺省
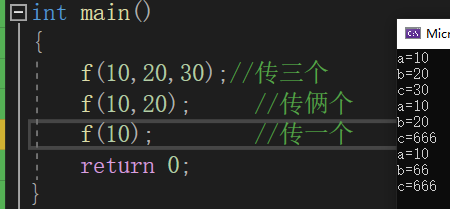
void f(int a=6,int b=66,int c=666)
{
cout<<"a=" <<a <<endl;
cout<<"b=" <<b <<endl;
cout<<"c=" <<c <<endl;
}
像这个函数我们可以传三个参数,也可以传俩个,也可以传一个
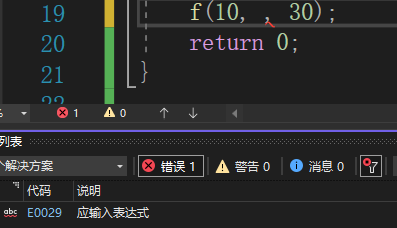
但是中间空了一个参数就是不行的
7.1.2半缺省
半缺省函数至少有一个缺省参数
void f(int a=6,int b=66,int c=666);
void f(int a,int b=66,int c=666);
void f(int a,int b,int c=666);
这些都是半缺省的正常形式
- 半缺省参数必须从右往左依次来给出,不能间隔着给
void f(int a=6,int b,int c=666);//这样是错误的
这里给的是函数声明,这里要特别注意的是
- 缺省参数 声明和定义不能同时出现(因为怕出现不一样的) 而且只能声明给,定义不给(不能反过来),会产生歧义,因为在编译的时候,先打开头文件,然后遇到函数调用,如果声明中没有缺省参数,拿不到定义,函数定义的出现是在链接,编译器就认为出错了。
7.2缺省参数的注意事项总结
- 半缺省参数必须 从右往左依次 来给出,并且是连续的,不能隔着给。
- 缺省参数不能在函数声明和定义中同时出现
- 缺省值必须是常量或者全局变量
- C 语言不支持(c语言 编译器不支持)
7.3缺省参数的应用
在我们之前学习顺序表的时候,我们会遇到创建顺序表连续多次扩容的问题,
这样会导致单一默认长度导致的多次扩容(realloc扩容会导致性能浪费)
如果有了缺省参数,我们就可以利用缺省参数来设置设置默认长度
typedef struct SeqList
{
int * a;
int size;
}SL;
void SeqListInit(SL* psl,int n =10)
{
psl->a = (int*)malloc(sizeof(int)*n);//默认值为10
psl->size = n;
}
当我们需要一个很长的顺序表时,就可以直接改默认长度,避免连续多次扩容,造成性能损耗
缺省参数在C语言里面是不支持的
这也算是C++对C语言的优化
8.结语
以上是对C++入门第一课的总结。
希望能帮到大家,谢谢~!
















 404
404











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











