






1.最好用python3.9以上的版本
2.安装whisper库
pip install -U openai-whisper
 输入whisper查看是否安装成功
输入whisper查看是否安装成功
 3.下载ffmpeg并添加环境变量
3.下载ffmpeg并添加环境变量
Releases · BtbN/FFmpeg-Builds (github.com)
 下载成功后,配置环境变量,右键我的电脑->属性->高级系统设置->环境变量->系统变量->Path
下载成功后,配置环境变量,右键我的电脑->属性->高级系统设置->环境变量->系统变量->Path

将bin目录的地址添加进来
然后检查是否成功 win+R cmd,输入ffmpeg,显示如下,则安装成功

3.Whisper主要是基于Pytorch实现,所以需要在安装有pytorch的环境中使用。
安装pytorch
pip3 install torch torchvision torchaudio
4.安装zhconv,将繁体字转换为简体字
pip install zhconv5.测试
写一段代码
import whisper
import zhconv
model = whisper.load_model("base", "cpu")
mps_path = r"1.mp3"
result = model.transcribe(mps_path, fp16=False, language='Chinese')
s = result["text"]
s1 = zhconv.convert(s, 'zh-cn')
print(s1)
运行,报错,错误信息:
FileNotFoundError: [WinError 2] 系统找不到指定的文件。
参考https://blog.csdn.net/zdm_0301/article/details/133854913?spm=1001.2014.3001.5506
感谢这位博主,成功解决这个给问题,把参数改为true后,重启电脑,运行成功
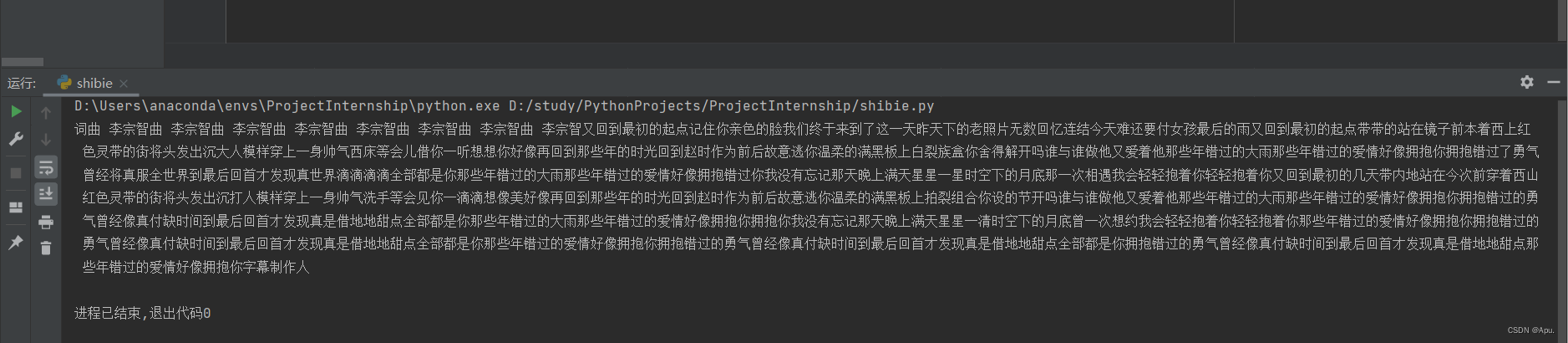 没有做分词操作,后续继续处理,总体识别还是不错的。
没有做分词操作,后续继续处理,总体识别还是不错的。















 679
679











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









