






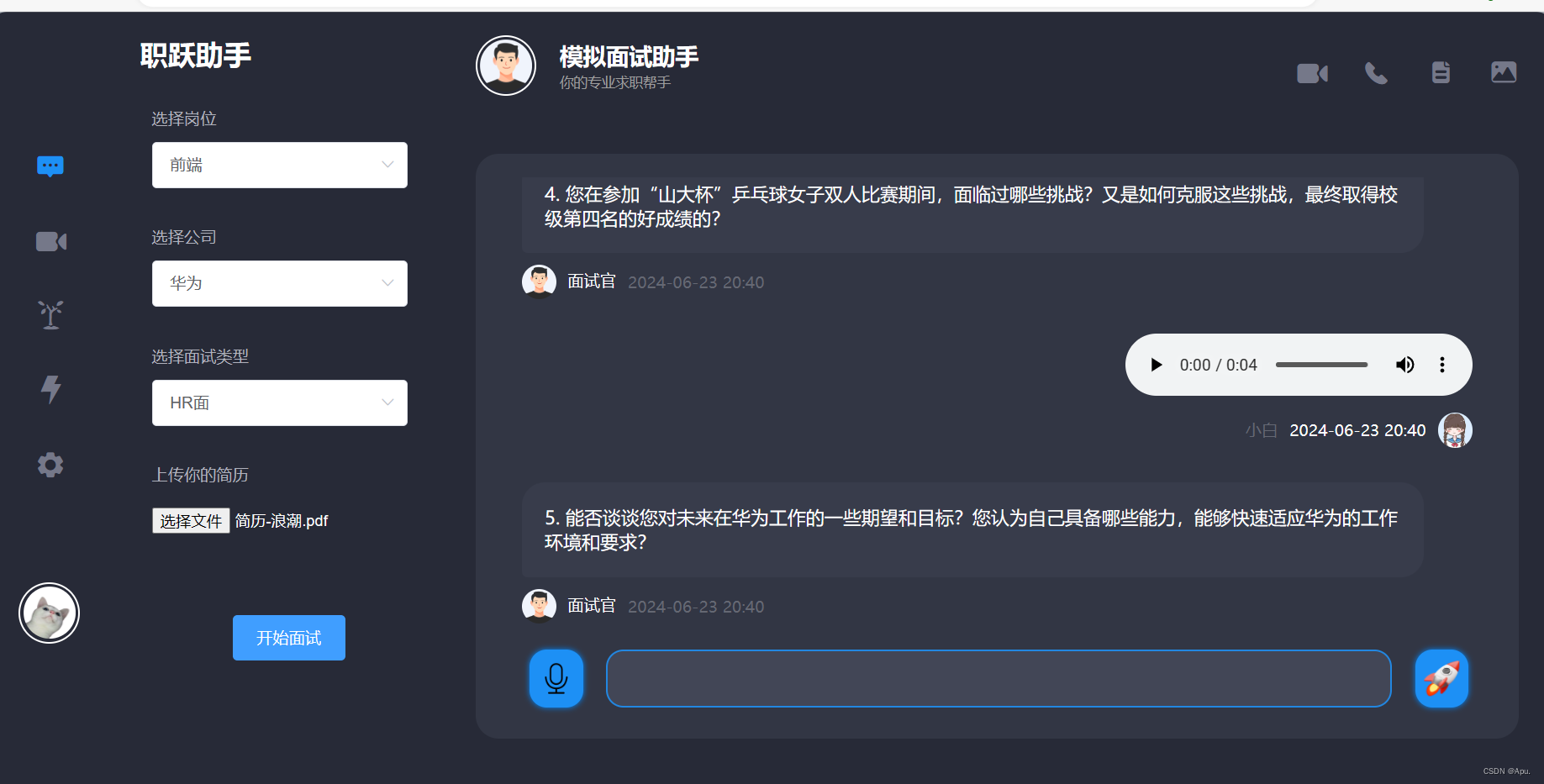
效果展示
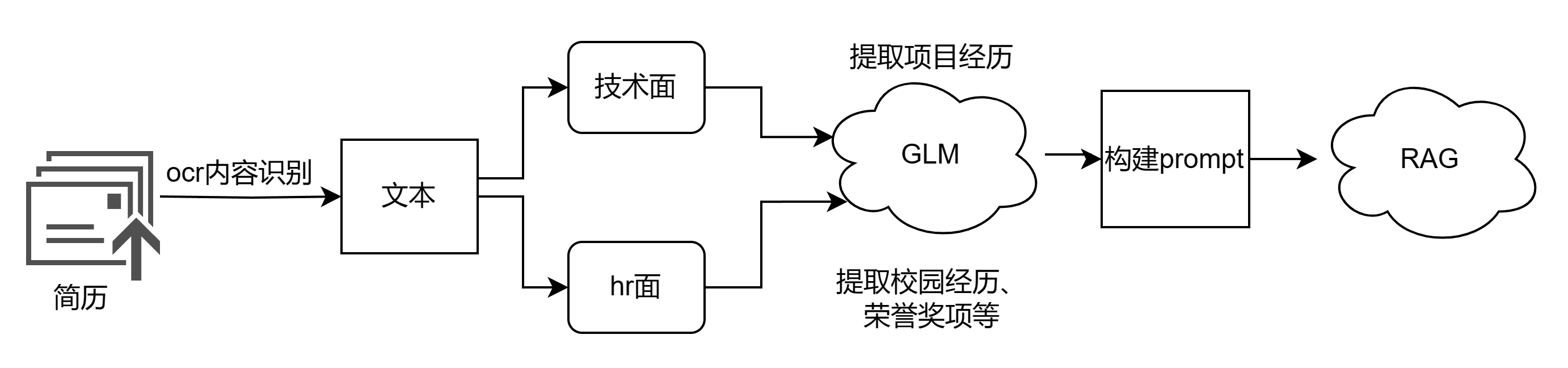
完整流程
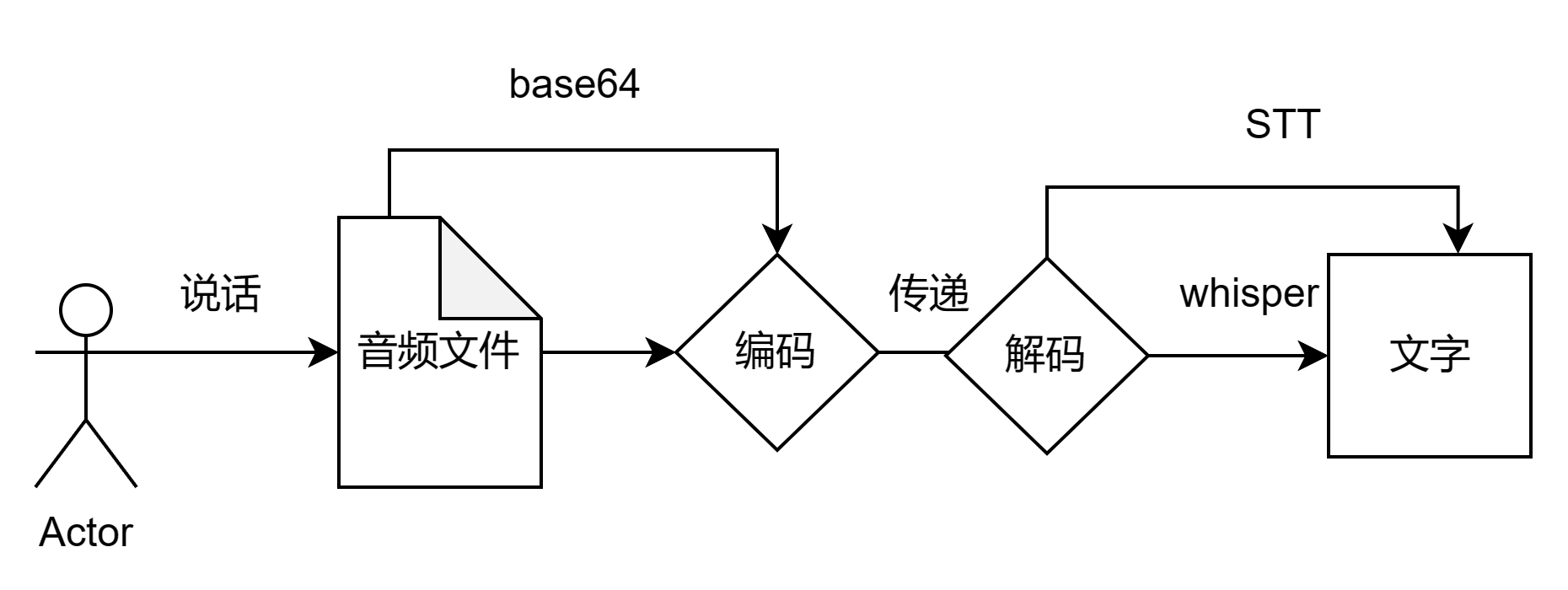
语音上传逻辑
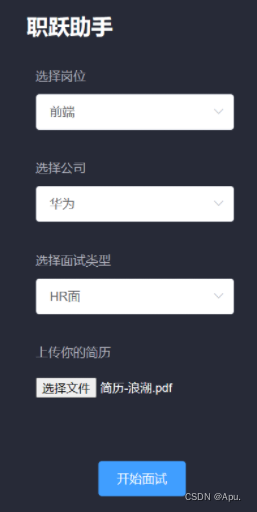
具体实现
1.上传面试相关信息,简历,公司,岗位,并上传简历
前端:
<template>
<div class="chatHome">
<div class="chatLeft">
<div class="title">
<h1>职跃助手</h1>
</div>
<el-form class="user-settings" ref="form" :model="form" label-width="80px" label-position="top">
<el-form-item class="settings-unit">
<span class="settings-text">选择岗位</span>
<el-select class="my-selector" v-model="form.job" placeholder="请选择岗位">
<el-option
v-for="item in jobOptions"
:key="item.value"
:label="item.label"
:value="item.value"
/>
</el-select>
</el-form-item>
<el-form-item class="settings-unit">
<span class="settings-text">选择公司</span>
<el-select class="my-selector" v-model="form.company" placeholder="请选择公司">
<el-option
v-for="item in companyOptions"
:key="item.value"
:label="item.label"
:value="item.value"
/>
</el-select>
</el-form-item>
<el-form-item class="settings-unit">
<span class="settings-text">选择面试类型</span>
<el-select class="my-selector" v-model="form.interview" placeholder="请选择面试类型">
<el-option
v-for="item in interviewOptions"
:key="item.value"
:label="item.label"
:value="item.value"
/>
</el-select>
</el-form-item>
<el-form-item class="settings-unit">
<div class="flex-container">
<span class="settings-text">上传你的简历</span>
<div class="my-selector">
<input type="file" style="color: white" @change="onFileChange" />
</div>
</div>
</el-form-item>
</el-form>
<el-button type="primary" style="margin-left: 90px; margin-top: 40px" @click="onSubmit">开始面试</el-button>
表单上传
onSubmit() {
const formData = new FormData();
// 添加文本字段
for (let key in this.form) {
formData.append(key, this.form[key]);
}
// 添加文件
console.log(this.file)
if (this.file) {
formData.append('file', this.file);
}
// 使用axios或fetch发送POST请求
// 假设你的Flask后端API地址是 '/upload'
// delete formData.headers['Content-Type'];
request.post('/upload_file', formData, {
headers: {
// 注意:当使用 FormData 时,不需要手动设置 Content-Type
// axios 会自动处理
},
})
.then(response => {
if (response.code == 200){
this.$message("上传成功~🥳");
console.log(response.result)
this.question = response.result
}
})
.catch(error => {
console.error(error);
// 处理错误
});
},后端接收相关信息。
# 侧边栏表单上传文件上传:包含工作+公司+简历
@app.route('/upload_file', methods=['POST'])
def upload_file():
job = request.form.get('job')
company = request.form.get('company')
interview = request.form.get('interview')
f = request.files.get('file')
# 如果文件不存在
if f is None or f.filename == '':
return jsonify({'code': 400, 'message': 'No file part in the request'}), 400
# 保存文件
fname = secure_filename(f.filename) # 使用secure_filename来避免安全问题
file_path = fname # 这不是一个完整的路径,只是一个文件名
try:
f.save(file_path) # 使用f.save而不是手动打开和写入文件
except Exception as e:
return jsonify({'code': 500, 'message': f'Failed to save file: {str(e)}'}), 500
# 项目经历
text = pyMuPDF_fitz(file_path, './img_tmp')
if interview == "技术面":
prompt = f"这是我的简历{text},请提取出我的软件项目经历,字数不超过600字"
else:
prompt = f"这是我的简历{text},请提取出我的荣誉奖项,校园经历,个人评价,字数不超过600字"
extracted = Turing2(prompt)
question = f"你是{company}公司的面试官,我要面试{job}岗位,现在要进行{interview},这是我的简历相关信息{extracted},请你现在问5个面试问题,每个问题以问号结尾,确保每个问题一行"
result = Turing(question)
return jsonify({
'code': 200,
'result': result
})2.返回面试问题逻辑
1.接受前端的表单信息,并保存解析文件,因为文件可能不能直接读,这里采用ocr技术,提取简历中的信息,
2.识别出的简历信息传给大模型GLM,调用该接口,返回与该面试有关的信息,比如技术面返回项目经历,hr面返回冗余奖项,校园经历等(此处大模型制作信息提取)
# GLM3对话
def Turing2(text_words=""):
# 准备请求体(JSON格式)
payload = {
"query": text_words,
"conversation_id": "", # 你可以根据需要设置此ID
"history_len": -1,
"history": [
],
"stream": False,
"model_name": "chatglm3-6b",
"temperature": 0.7,
"max_tokens": 0, # 注意:max_tokens为0可能表示无限制,但具体取决于API的实现
"prompt_name": "default"
}
# 发送POST请求,并设置Content-Type为application/json
headers = {'Content-Type': 'application/json'}
response = requests.post(url2, json=payload, headers=headers)
# 检查响应状态码并打印响应内容
if response.status_code == 200:
print('请求成功')
json_str = response.text.split(': ', 1)[1] # 使用split分割字符串,只取第二个部分(索引为1)
try:
# 解析JSON字符串
data = json.loads(json_str)
# 提取text字段的值
text = data['text']
print('文本内容:', text)
return text
except (json.JSONDecodeError, KeyError) as e:
print('解析JSON或访问字段时出错:', e)
else:
print(f'请求失败,状态码:{response.status_code}')
3.构建prompt
question = f"你是{company}公司的面试官,我要面试{job}岗位,
现在要进行{interview},这是我的简历相关信息{extracted},
请你现在问5个面试问题,每个问题以问号结尾,确保每个问题一行"
4.返回面试问题。根据prompt检索知识库中相关的面试问题,公司信息,最后在交给GLM,返回最终面试问题。(此处为RAG技术)
# 与知识库对话
def Turing(text_words=""):
# 准备请求体(JSON格式)
payload = {
"query": text_words,
"knowledge_id": "tmpyr9658rr",
"top_k": 3,
"score_threshold": 0.6,
"history": [
],
"stream": False,
"model_name": "chatglm3-6b",
"temperature": 0.7,
"max_tokens": 0,
"prompt_name": "default"
}
# 发送POST请求,并设置Content-Type为application/json
headers = {'Content-Type': 'application/json'}
response = requests.post(url, json=payload, headers=headers)
# 检查响应状态码并打印响应内容
if response.status_code == 200:
json_str = response.text.split(': ', 1)[1] # 使用split分割字符串,只取第二个部分(索引为1)
try:
# 解析JSON字符串
data = json.loads(json_str)
# 提取text字段的值
text = data['answer']
result = text.split('\n')
# 输出分割后的数组(列表)
print(result)
return result
except (json.JSONDecodeError, KeyError) as e:
print('解析JSON或访问字段时出错:', e)
else:
print(f'请求失败,状态码:{response.status_code}')返回的结果

5.前端展示,面试官提问。















 1011
1011











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









