






Filter
一、作用
拦截请求
可完成的操作例如:登录校验配合JWT,统一的编码管理以及敏感词处理
代码如下:
在方法前@webfilter 且在启动类加入@ServletCompenentScan,主要是重写两类方法init()初始化以及dofilter()拦截或放行操作
@webfilter(urlPatterns=”/*”)可以拦截所有请求,并检测
public static String filter(String text) {
if (StringUtils.isBlank(text)) {
return null;
}
// 指针1
TrieNode tempNode = ROOT_NODE;
// 指针2
int begin = 0;
// 指针3
int position = 0;
// 结果
StringBuilder sb = new StringBuilder();
while (position < text.length()) {
char c = text.charAt(position);
// 跳过符号
if (isSymbol(c)) {
// 若指针1处于根节点,将此符号计入结果,让指针2向下走一步
if (tempNode == ROOT_NODE) {
sb.append(c);
begin++;
}
// 无论符号在开头或中间,指针3都向下走一步
position++;
continue;
}
// 检查下级节点
tempNode = tempNode.getSubNode(c);
if (tempNode == null) {
// 以begin开头的字符串不是敏感词
sb.append(text.charAt(begin));
// 进入下一个位置
position = ++begin;
// 重新指向根节点
tempNode = ROOT_NODE;
} else if (tempNode.isKeywordEnd()) {
// 发现敏感词,将begin~position字符串替换掉
sb.append(REPLACEMENT);
// 进入下一个位置
begin = ++position;
// 重新指向根节点
tempNode = ROOT_NODE;
} else {
// 检查下一个字符
position++;
}
}
// 将最后一批字符计入结果
sb.append(text.substring(begin));
return sb.toString();
}
拦截放行操作:
chain.doFilter(request,response);
二、原理:在请求接受到的时候由于启动类中具备了一层网络服务,先调用网络层服务在进行客户端服务,协议决定在业务层之前执行
过滤器链:
串行执行过滤器(多个),优先级根据字符串字典序来排序的
登录校验:
Interceptor
1.拦截器,与过滤器非常类似,作用:拦截请求
2.顺序:定义拦截器,并重写其三个方法:preHandle()、postHandle()、afterCompletion(),且配置@Configuration,并指定其拦截请求
Pre方法返回true就放行,否则就不放行,是在访问controller之前调用的
Post是在controller方法运行完后执行的
After是最后执行的
注册拦截器基本代码如下:
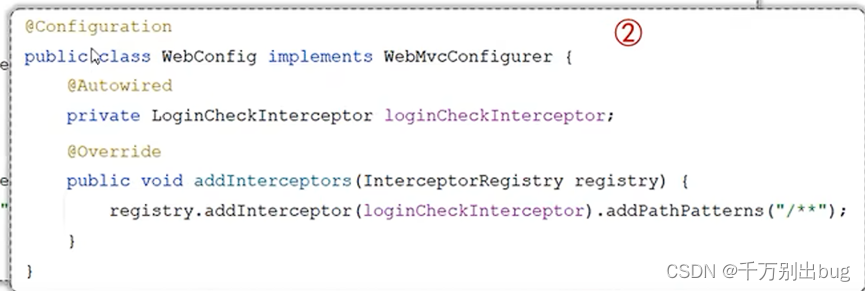
在项目中,使用preHandle方式去检验用户的登录状态,抛出异常就寄,不抛出就放行,验证的是token,以及他的账号密码。
总结:不管是拦截器还是过滤器,他的基本原理都是在网络层去服务的,是要在controller之前或者说是和controller同理的一种类型,会抓取指定的请求去处理代码,他的处理和controller类似,都会去调用service层再去调用dao层,也是层层递进的,简化了service层,并给出了宏观的解决方案。
SpringSecurity(权限验证框架)
主要作用:
一、认证(用户登录)
二、授权(此用户能做哪些事情)
三、攻击防护(防止伪造身份攻击)
防CSRF跨站请求攻击
SFA会话固定攻击
这种攻击主要针对的是会话层的session,黑客给了一个正确的session,会话层就会给他分配一个ID,用这个ID他就可以操作某位用户的一切内容,所以需要在验证session正确之后给出一个新的session才可以,这个SpringSecurity自动做好了。
认证
SFA固定会话攻击,退出登录后只能选择重新登陆才可以实现访问,在Sceurity当中不需要自己去写登录模块了,直接被Sceurity接管了。
认证以及检验方面关键点:
需要在构建的实体类当中是去实现UserDetails的接口
在业务层的实体类需要集成UserDetailsService这个接口的
部分二:内部流程机制
本质上是通过N个Filter实现的,可以通过addFilterAt()或者addFilterBefore()或者addFilterAfter()方法向其中加入自己的filter,但自定义的filter是要继承OncePerRequestFilter的,这样就可以加在了自己想要他在的地方。
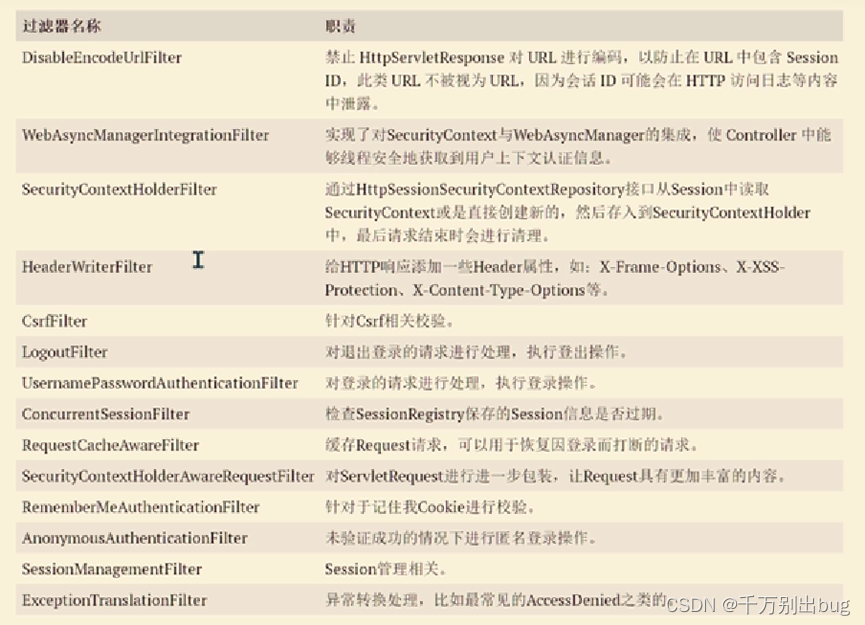
http.addFilterAt(loginFilter(),UsernamePasswordAuthenticationFilter.class)
.addFilterAt(new ConcurrentSessionFilter(sessionRegistry()),ConcurrentSessionFilter.class);
实现流程(使用@EnableWebSecurity注解链接到Security上):
1.SecurityConfig创建一个bean,然后将bean注入进去,返回类型SecurityFilterChain Security的固定过滤序列.
2.在数据库存储加密后的密码。
3.在实体中创建对应User(最后不用User起名字)对象,在里面实现UserDetails接口,里面一共有七种方法(权限验证、get密码和名字、判断是否过期),然后去实现七种方法,为了能够对应到数据库。
4.业务层实现UserDetailsService接口实现唯一loadUserByUserName()方法,就是去调用数据库查询(需要把dao层注入),然后在业务层返回UserDetails类即可,Security会根据返回的UserDetails去验证是否成功登录。
5.添加·JWT过滤器装置
要在Security的过滤链中去添加,注意要在登录校验之前,后面的所有操作都是解析token,这里在loginSccessHandler中颁布令牌给到token,在loginFailHandler()方法中去捕获异常,到这所有的安全认证全部结束,后面的内容全部在服务端认证,是安全的。
SpringCloud(分布式架构微服务)
涉及到多个Web应用的话,单体交付,逻辑复杂,所有的接口、业务逻辑、持久层都在一个web应用中在团队开发时会带来大量不便和成本的提高,所以需要能持续交付的微服务分布式架构。
一、分布式、集群:
集群:
物理层面:一台服务器无法负荷高并发的数据访问量,那么就要有多台服务器一起分担压力。
分布式:
设计层面:讲一个复杂问题拆分成多个简单的小问题,将一个大型的项目架构拆分成若干个微服务协同完成。
串行执行改并步执行。
二、微服务的基本架构
用设备通过API Getway(网关)通过不同的REST API映射到不同的微服务
三、微服务的难点
如何拆分一个大项目变成微服务?
如何沟通确定微服务需求?
如何保证数据的独立性的同时保证数据的一致性?
四、关键组件
EurekaServer(服务治理):注册中心管理微服务
服务提供者:单体微服务进行注册。
服务消费者:其他微服务在服务中心找到对应服务并调用。
注册中心
ZuulProxy(服务网关)
FeinClient(服务通信)
Ribbon(服务通信)
Hystrix(服务容错)
Config(服务配置)
Actuator(服务监控)
Zipkin(服务跟踪)
Spring Cloud Eureka
EurekaServer注册中心
EurekaClient,注册中心客户端,都要通过这个组件链接EurekaServer进行注册
一、操作步骤:
1.在总的maven工程仓库下引入依赖如下:
<dependencyManagement>
<dependencies>
<!-- <dependency>-->
<!-- <groupId>org.springframework</groupId>-->
<!-- <artifactId>spring-framework-bom</artifactId>-->
<!-- <version>${spring.version}</version>-->
<!-- <type>pom</type>-->
<!-- <scope>import</scope>-->
<!-- </dependency>-->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-framework-bom</artifactId>
<version>5.3.5</version>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Hoxton.SR5</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
2.在里面新建子工程命名为Eureka
如下:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
这样就成为了注册中心、
3.在Eureka的application.yml文件中加入配置信息
server:
port: 8686
eureka:
client:
register-with-eureka: false #是否将自己注册到eureka中
fetch-registry: false #是否从eureka中获取信息
service-url:
defaultZone: http://127.0.0.1:${server.port}/eureka/
属性说明:

4.添加启动类
加入两个注解:
@SpringBootApplication
@EnableEurekaServer
第一个是让他启动,第二个是让他成为一个EurekaServer
5.提供注册,需要再其他模块的xml文件中添加
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
然后在application.yml文件中添加注册时候的信息:
spring:
profiles:
active: dev
application:
name: blog-server #指定服务名
以及哪一个注册中心
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:8686/eureka/
instance:
prefer-ip-address: true
二、RestTemplate组件的使用
RestTemplate是Spring框架提供的基于REST的服务组件,底层是对HTTP请求及响应进行了封装,提供了很多访问REST的方法。调用服务也需RestTemplate提供的API。
一、使用方式
1.创建maven工程,pom文件引入依赖(boot的就可以)
2.在启动类中添加rest方法
@Bean
public RestTemplate restTemplate() {
return new RestTemplate();
}
3.创建对应实体类
4.跨服务调用其他服务
return restTemplate.getForEntity(String url,type.class).getBody;
三、服务消费者Consumer
1.在pom里添加相关依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifact
2.创建配置文件
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:8686/eureka/
instance:
prefer-ip-address: true
3.创建启动类
4.使用RestTemplate
心跳机制
1.心跳是从什么时候开始的
在每一个Eureka Client启动的时候,都会有一个HeartbeatThread的心跳线程,这个就是一个后跳线程,保证默认30秒的时候向Eureka Server发送一个信息的请求,告诉Eureka Server当前的Eureka Client还存活着。eureka.instance.lease-renewal-interval-in-seconds,这个参数可以来配置对应的心跳间隔时间。
Eureka Server在接收到请求之后,肯定是先去自己的注册表中去,找到请求的对应的服务信息,在这个服务信息里面有个Lease的对象,这个里面就是可以进行心跳续约操作的,更新Lease对象里面的LastUpdateTimestamp时间戳,每一次接收到都会更新这个时间戳的。
3.Eureka Server在什么情况下会摘除Eureka Client的信息
有了心跳,也有了接受,那么怎么来判断在什么情况下,Eureka Server在什么情况下才会摘除对应没有心跳的Eureka Client的呢?
Eureka Server在启动的时候会每60秒遍历一次注册表中的信息,然后查看注册表中的信息是否有过期的,如果过期会加入到一个列表里面单独处理。
eureka.server.evictionIntervalTimerInMs可以配置心跳检测的时间间隔,单位是毫秒。那么接下来就是多长时间没有心跳才会剔除这个服务呢?默认情况下,如果90秒还没有更新对应的LastUpdateTimestamp就表示这个服务可能故障了,我们需要给他做摘除的操作了。
服务网关
SpringCloud集成了Zuul,实现了网关
Zuul将所有请求导入统一的入口,屏蔽了服务端的具体实现流程,Zuul可以实现反向代理的功能,在网关内部实现动态路由、身份认证、IP过滤、数据监控等功能。
解决token丢失的问题,问题描述:原本代码中sensitiveHeaders拼写错误
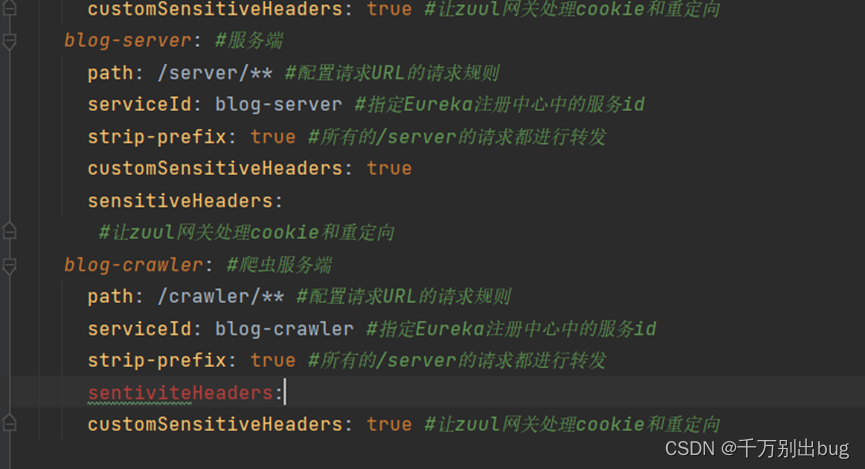
网关实现
一、在pom文件中加入依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-zuul</artifactId>
</dependency>
二、在配置文件中加入信息
server:
port: 9001
spring:
profiles:
active: dev
application:
name: blog-encrypt
zuul:
host:
connect-timeout-millis: 60000000
socket-timeout-millis: 60000000
routes:
blog-extension: #博客的拓展服务端
path: /extension/** #配置请求URL的请求规则 **表示任意数量以及所有子路径
serviceId: blog-extension #指定Eureka注册中心中的服务id
strip-prefix: true #所有的/extension的请求都进行转发
sentiviteHeaders:
customSensitiveHeaders: true #让zuul网关处理cookie和重定向
blog-server: #服务端
path: /server/** #配置请求URL的请求规则
serviceId: blog-server #指定Eureka注册中心中的服务id
strip-prefix: true #所有的/server的请求都进行转发
sentiviteHeaders:
customSensitiveHeaders: true #让zuul网关处理cookie和重定向
blog‐crawler: #爬虫服务端
path: /crawler/** #配置请求URL的请求规则
serviceId: blog‐crawler #指定Eureka注册中心中的服务id
strip-prefix: true #所有的/server的请求都进行转发
sentiviteHeaders:
customSensitiveHeaders: true #让zuul网关处理cookie和重定向
三、启动类
加入注解:
@EnableZuulProxy//开启网关代理
@EnableAutoConfiguration或者@SpringBootApplication
四、zuul自带了负载均衡的功能,当一个服务有多个启动类(实例)可以动态分配
Ribbon负载均衡
在注册中心对Ribbon进行注册之后,Ribbon就可以基于某种负载均衡算法,如轮询、随机、加权轮询、加权随机等算法自动调用不同的接口。
一、使用方式
1.在pom文件中加入依赖项,使其加入到注册中心中
2.在yml文件中设置端口以及eureka的基础信息
mybatis:
type-aliases-package: mydemo.mybatis.entity
mapper-locations: classpath:mappers/*xml
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/blog
username: root
password: 1007585047
application:
name: ribbon
server:
port: 8731
eureka:
client:
service-url:
defaultZone: http://localhost:8686/eureka
instance:
prefer-ip-address: true
3.添加启动类
通过@loadblance生成负载均衡
@Bean
@LoadBalanced
public RestTemplate restTemplate(){
return new RestTemplate();
}
4.用RestTemplate调用服务
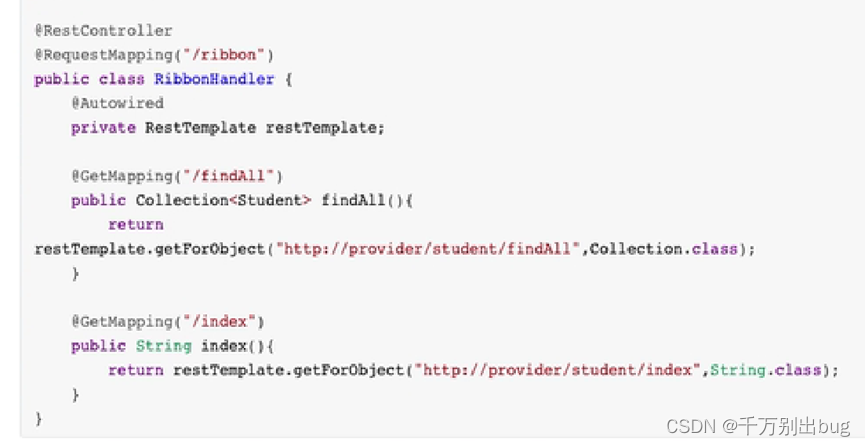
二、简化方式 ——Feign声明式接口调用
什么是Feign,Feign也实现了负载均衡,是对Ribbon的封装,可以通过调用接口的方式去实现负载均衡
相比较于Ribbon+RestTemplate的机制这种方式的负载均衡,Feign可以大大简化代码开发。
三、Feign的使用
1.在pom文件中添加dependency且添加注册中心的依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
2.添加feign相关的配置,注册中心的地址一些内容
3.创建启动类并加入Feign注解
@EnableFeignClients
public class MydemoApplication
4.创建接口文件只需写出接口(不去实现)然后用@FeignClient(value=“<注册中心name>”)注解在接口上即可使用,使用时注入接口对象.
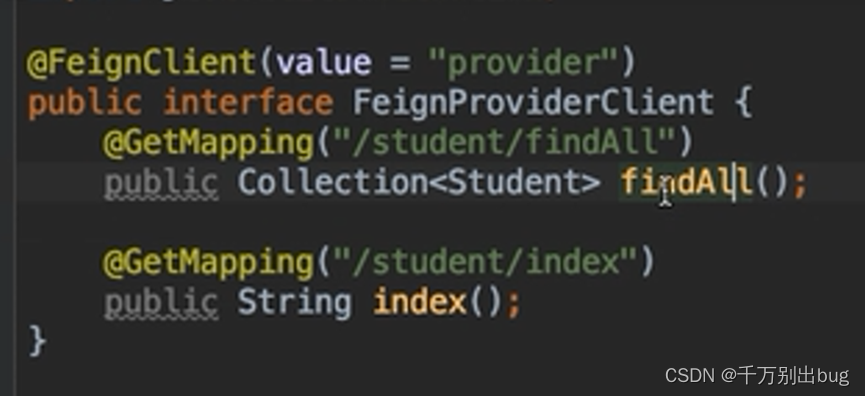
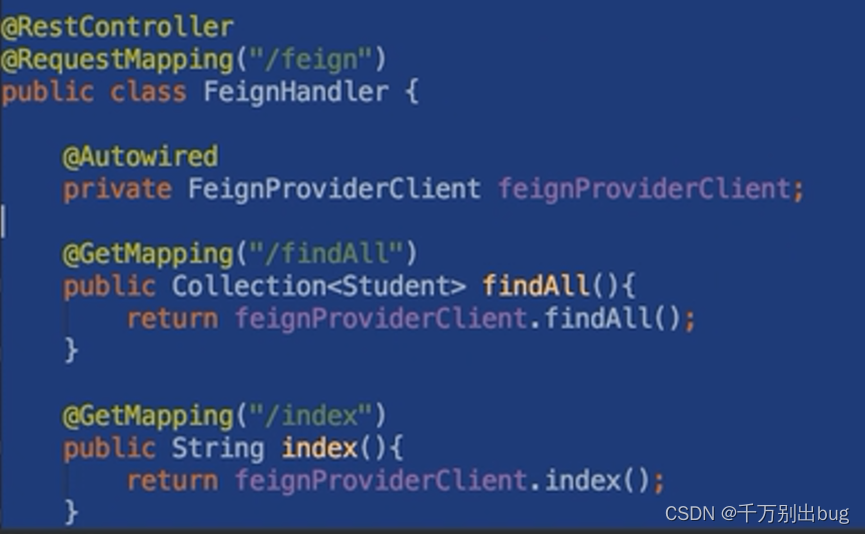
感觉有点像啥呢,有点像手动重定向。
熔断
Feign集成了Hystrix熔断机制
熔断类似于保险丝,当某一服务出现问题的时候进行应急处理,防止整个服务崩溃
一、简单使用
在yml文件中开启熔断机制
feign:
hystrix:
enabled: true
二、如开启熔断则去实现上面Feign接口类的实现类FeignError,并通过@Conponent注解注入到IOC容器中去。
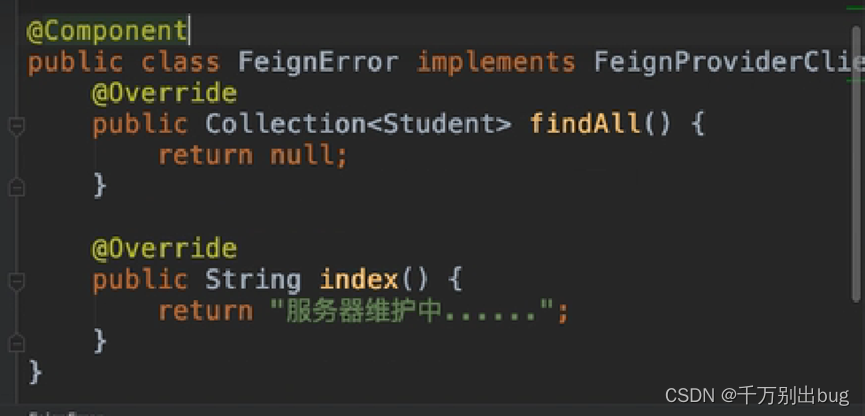
自我理解,如果这个服务在开启状态那么跨域过后就已经返回了,而不去调用最后的return,若没有开启则会return自定义内容.
然后我们再进行降级处理,这里把之前负载均衡的部分拿过来,在注解内加入降级处理的指定实现类即可。
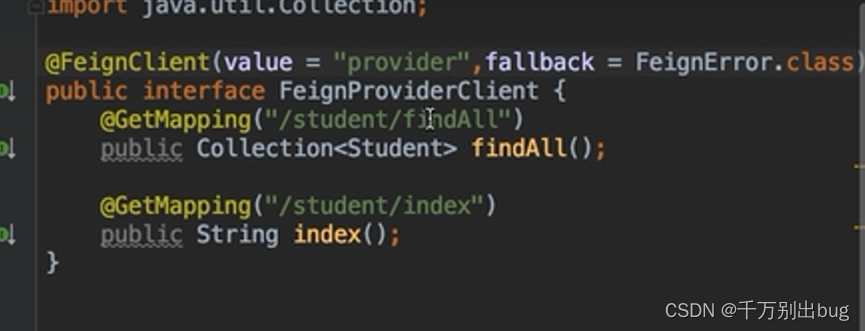
Hystrix容错
在不改变各个微服务互相调用的前提下,针对错误情况进行预先处理。
一、设计原则
1、服务隔离机制
2、服务降级机制
3、熔断机制
4、提供实时监控和报警功能
5、提供实时的配置修改功能
Hystrix数据监控需要结合Spring Boot Acuator组件去使用,Acuator提供了对服务的健康监控、以及数据统计功能,可以通过Hystrix-stream获取监控的请求数据,同时提供了可视化的监控界面
1. 隔离:
Hystrix隔离方式采用线程/信号的方式,通过隔离限制依赖的并发量和阻塞扩散
1)线程隔离
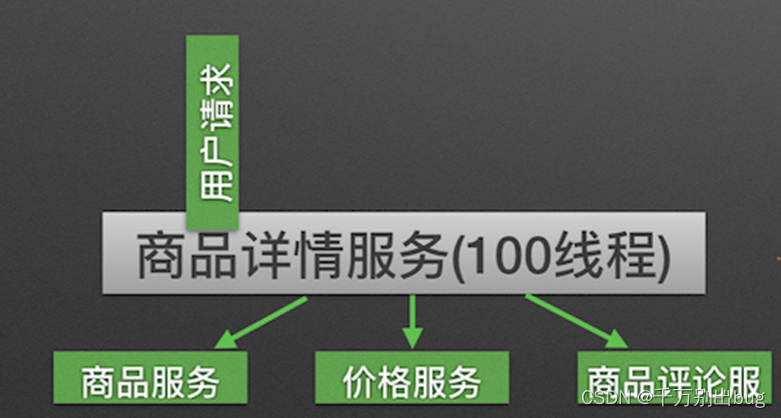
Hystrix在用户请求和服务之间加入了线程池。
Hystrix为每个依赖调用分配一个小的线程池,如果线程池已满调用将被立即拒绝,默认不采用排队.加速失败判定时间。线程数是可以被设定的。
原理:用户的请求将不再直接访问服务,而是通过线程池中的空闲线程来访问服务,如果线程池已满,则会进行降级处理,用户的请求不会被阻塞,至少可以看到一个执行结果(例如返回友好的提示信息),而不是无休止的等待或者看到系统崩溃。
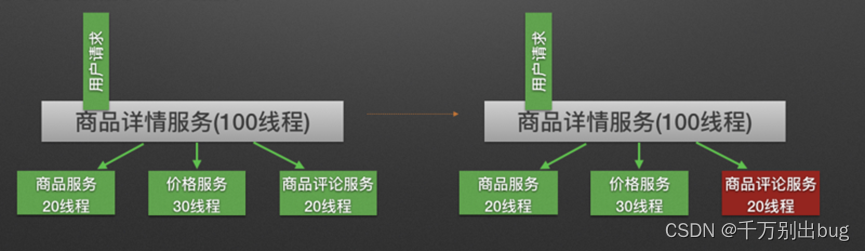
隔离前:

隔离后:
b)信号隔离:
信号隔离也可以用于限制并发访问,防止阻塞扩散, 与线程隔离最大不同在于执行依赖代码的线程依然是请求线程(该线程需要通过信号申请, 如果客户端是可信的且可以快速返回,可以使用信号隔离替换线程隔离,降低开销。信号量的大小可以动态调整, 线程池大小不可以。(参考文章2)
熔断:
如果某个目标服务调用慢或者有大量超时,此时,熔断该服务的调用,对于后续调用请求,不在继续调用目标服务,直接返回,快速释放资源。如果目标服务情况好转则恢复调用。
熔断器:Circuit Breaker
熔断器是位于线程池之前的组件。用户请求某一服务之后,Hystrix会先经过熔断器,此时如果熔断器的状态是打开(跳起),则说明已经熔断,这时将直接进行降级处理,不会继续将请求发到线程池。熔断器相当于在线程池之前的一层屏障。每个熔断器默认维护10个bucket ,每秒创建一个bucket ,每个blucket记录成功,失败,超时,拒绝的次数。当有新的bucket被创建时,最旧的bucket会被抛弃。
熔断器的状态机:
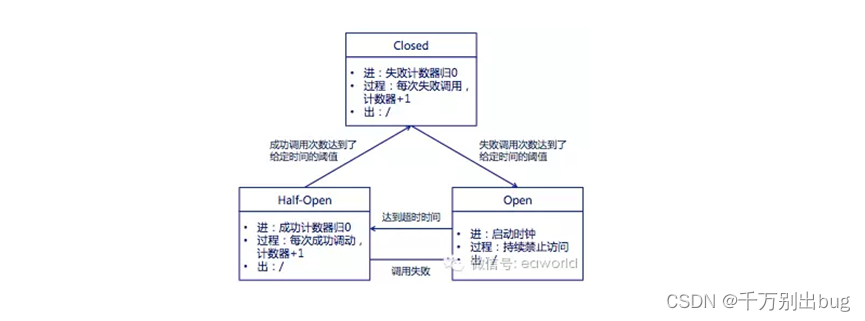
- Closed:熔断器关闭状态,调用失败次数积累,到了阈值(或一定比例)则启动熔断机制;
- Open:熔断器打开状态,此时对下游的调用都内部直接返回错误,不走网络,但设计了一个时钟选项,默认的时钟达到了一定时间(这个时间一般设置成平均故障处理时间,也就是MTTR),到了这个时间,进入半熔断状态;
- Half-Open:半熔断状态,允许定量的服务请求,如果调用都成功(或一定比例)则认为恢复了,关闭熔断器,否则认为还没好,又回到熔断器打开状态;
二、使用方式
1、创建新模块
2、在pom加入依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix-dashboard</artifactId>
</dependency>
3、在yml文件中配置文件
server:
port: 9990
spring:
application:
name: hystrix
eureka:
client:
service-url:
defaultZone: http:localhost:8686/eureka
instance:
prefer-ip-address: true
feign:
hystrix:
enabled: true
management:
endpoints:
web:
exposure:
include: 'hystrix.stream'
4、创建启动类
@SpringBootApplication
@EnableFeignClients
@EnableCircuitBreaker
@EnableHystrixDashboard
public class MydemoApplication {
public static void main(String[] args) {
SpringApplication.run(MydemoApplication.class, args);
}
}
注释解释:
@EnableCircuitBreaker :声明启动数据监控
@EnableHystrixDashboard :声明启动可视化界面
5.继续实现Feign接口类
6、启动项目

SpringCloud配置中心
当一个服务对的配置信息修改了,很有可能很多服务的配置文件也要进行修改,那么我们需要一个东西来统一管理他们的配置。
Spring Cloud Config配置中心,通过这个组件的服务端,为多个客户端提供配置服务。它可以将配置文件存储在本地,也可以存放远程的Git仓库,
一、本地管理配置流程
1.在pom文件中添加以下依赖

2.创建其本身的配置
server:
port: 8762
spring:
application:
name: nativeconfigserver
profiles:
active: native
cloud:
config:
server:
native:
search-locations: classpath:/shared
3.然后在你写的那个路径下创建文件
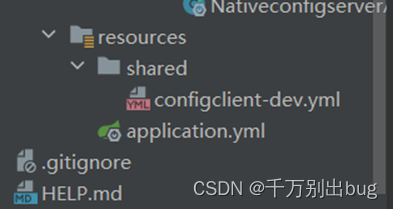
4.在启动类上声明配置中心
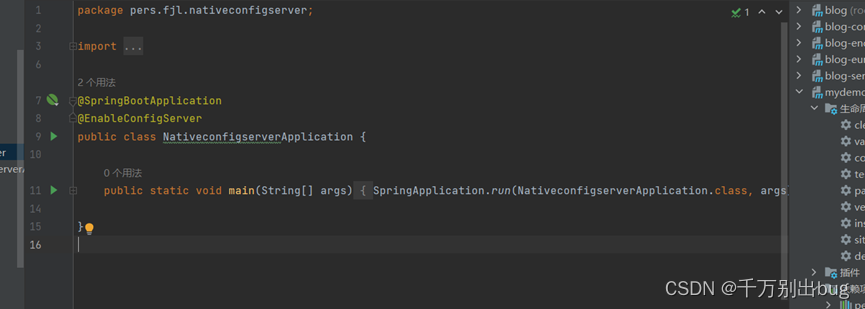
@EnableConfigServer : 声明配置中心
这样配置中心就搞好了,接下来就是调用配置中心
二、客户端调用配置中心
1.在pom文件中加入依赖
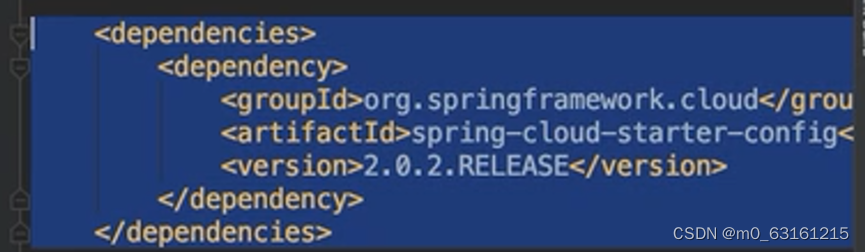
2.创建bootstrap,yml,配置读取本地配置中心的相关信息
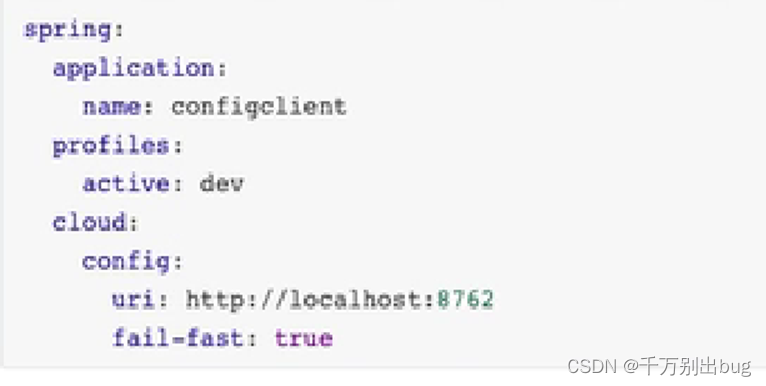
这样就取到了配置中心的配置信息。
Zipkin服务跟踪
ZipKin是一个可以采集并且跟踪分布式系统的中请求数据的组件,让开发者更加直观的监控到请求在各个微服务所耗费的时间等,Zipkin分为服务端和客户端。
一、使用流程
1.在pom中加入依赖

2.在yml中配置文件只需要端口信息
3.在启动类中进行配置
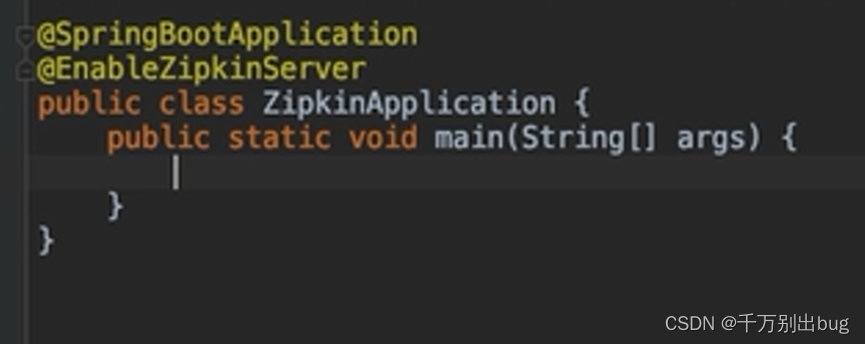
@EnableZipkinServer :声明是服务端
服务端就配置完毕,接下来进行客户端配置
二、配置客户端
1.首先在pom文件中加入依赖文件

2.然后在yml文件中配置信息
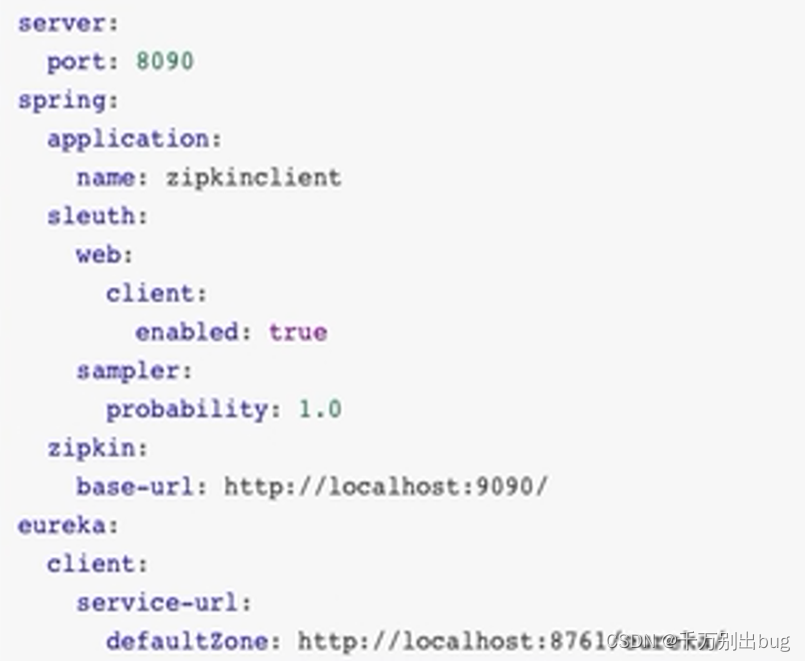
Spring.sleuth.web.client.enabled是否启动服务请求跟踪
Spring.sleuth.sampler.probability设置采样比例, 默认是1.0
Spring.zipkin.base-url是服务端的地址
完结撒花;















 1280
1280











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









