






在上次的实践中进行了决策树的构建,本次实践就在上次的基础上进行对决策树的剪枝处理。
一、为什么决策树要进行剪枝处理?
决策树的过拟合的风险很大,因为理论上来说可以将数据完全分的开,如果树足够大,每个叶子节点就剩下了一个数据。那么,这就会造成模型在训练集上的拟合效果很好,但是泛化能力很差,对新样本的适应能力不足。所以,对决策树进行剪枝,可以降低过拟合的风险。
二、剪枝处理的基本放法
进行剪枝处理最基本的方法有两种:预剪枝与后剪枝。
1.预剪枝
预剪枝就是在构造决策树的过程中,先对每个结点在划分前进行估计,如果当前结点的划分不能带来决策树模型泛化性能的提升,则不对当前结点进行划分并且将当前结点标记为叶结点。
优缺点:预剪枝使得决策树的很多分支没有“展开”,降低了过拟合的风险,还能够减少决策树的训练时间以及预测事件开销。但是,有些分支可能当前划分不能提升模型的泛化性能甚至导致泛化性能暂时下降,但在其基础上的后续划分可能显著提高模型的性能。预剪枝的这种禁止分支展开,同样也给决策树带来了欠拟合的风险。
2.后剪枝
后剪枝就是先把整颗决策树构造完毕,然后自底向上的对非叶结点进行考察,若将该结点对应的子树换为叶结点能够带来泛华性能的提升,则把该子树替换为叶结点。
优缺点:相比预剪枝,后剪枝的优点是后剪枝决策树通常比预剪枝决策树保留了更多的分支;后剪枝决策树的欠拟合风险很小,泛化性能往往优于预剪枝决策树。后剪枝的缺点是决策树训练时间开销比未剪枝决策树和预剪枝决策树都要大的多。
三、代码实现剪枝处理
1.数据集准备
本次使用的数据集在上次实践中使
用的数据集基础上进行了部分修改。
| 温度 | 天气情况 | 人员齐全情况 | 场地情况 | 是否适宜进行社团活动 |
| 高 | 晴朗 | 齐全 | 人较多 | 否 |
| 适中 | 晴朗 | 齐全 | 宽敞 | 是 |
| 适中 | 降雨 | 齐全 | 宽敞 | 是 |
| 高 | 降雨 | 不齐全 | 人较多 | 否 |
| 高 | 降雨 | 不齐全 | 拥挤 | 否 |
| 适中 | 降雨 | 不齐全 | 宽敞 | 否 |
| 适中 | 阴天 | 不齐全 | 宽敞 | 是 |
| 适中 | 阴天 | 齐全 | 人较多 | 否 |
| 高 | 降雨 | 齐全 | 人较多 | 是 |
def createData():
data = np.array([['高','晴朗','齐全','人较多'],
['适中','晴朗','齐全','宽敞'],
['适中','降雨','齐全','宽敞'],
['高','降雨','不齐全','人较多'],
['高','降雨','不齐全','人较多'],
['适中','降雨','不齐全','宽敞'],
['适中','阴天','不齐全','宽敞'],
['适中','阴天','齐全','人较多'],
['高','降雨','齐全','人较多']])
label = np.array(['否', '是', '是', '否', '否', '否', '是', '否','是'])
name = np.array(['温度', '天气情况', '人员齐全情况', '场地情况'])
return data, label, name2.创建决策树并展现决策树
此部分代码在上次实践中展示,详情见完整代码。
决策树展现:

3. 创建剪枝决策树
def createTreePrePruning(dataTrain, labelTrain, dataTest, labelTest, names, method = 'id3'):
trainData = np.asarray(dataTrain)
labelTrain = np.asarray(labelTrain)
testData = np.asarray(dataTest)
labelTest = np.asarray(labelTest)
names = np.asarray(names)
# 如果结果为单一结果
if len(set(labelTrain)) == 1:
return labelTrain[0]
# 如果没有待分类特征
elif trainData.size == 0:
return voteLabel(labelTrain)
# 其他情况则选取特征
bestFeat, bestEnt = bestFeature(dataTrain, labelTrain, method = method)
# 取特征名称
bestFeatName = names[bestFeat]
# 从特征名称列表删除已取得特征名称
names = np.delete(names, [bestFeat])
# 根据最优特征进行分割
dataTrainSet, labelTrainSet = splitFeatureData(dataTrain, labelTrain, bestFeat)
# 预剪枝评估
# 划分前的分类标签
labelTrainLabelPre = voteLabel(labelTrain)
labelTrainRatioPre = equalNums(labelTrain, labelTrainLabelPre) / labelTrain.size
# 划分后的精度计算
if dataTest is not None:
dataTestSet, labelTestSet = splitFeatureData(dataTest, labelTest, bestFeat)
# 划分前的测试标签正确比例
labelTestRatioPre = equalNums(labelTest, labelTrainLabelPre) / labelTest.size
# 划分后 每个特征值的分类标签正确的数量
labelTrainEqNumPost = 0
for val in labelTrainSet.keys():
labelTrainEqNumPost += equalNums(labelTestSet.get(val), voteLabel(labelTrainSet.get(val))) + 0.0
# 划分后 正确的比例
labelTestRatioPost = labelTrainEqNumPost / labelTest.size
# 如果没有评估数据 但划分前的精度等于最小值0.5 则继续划分
if dataTest is None and labelTrainRatioPre == 0.5:
decisionTree = {bestFeatName: {}}
for featValue in dataTrainSet.keys():
decisionTree[bestFeatName][featValue] = createTreePrePruning(dataTrainSet.get(featValue), labelTrainSet.get(featValue)
, None, None, names, method)
elif dataTest is None:
return labelTrainLabelPre
# 如果划分后的精度相比划分前的精度下降, 则直接作为叶子节点返回
elif labelTestRatioPost < labelTestRatioPre:
return labelTrainLabelPre
else :
# 根据选取的特征名称创建树节点
decisionTree = {bestFeatName: {}}
# 对最优特征的每个特征值所分的数据子集进行计算
for featValue in dataTrainSet.keys():
decisionTree[bestFeatName][featValue] = createTreePrePruning(dataTrainSet.get(featValue), labelTrainSet.get(featValue)
, dataTestSet.get(featValue), labelTestSet.get(featValue)
, names, method)
return decisionTree (只粘贴了部分代码)
4.结果展示
预剪前的树:
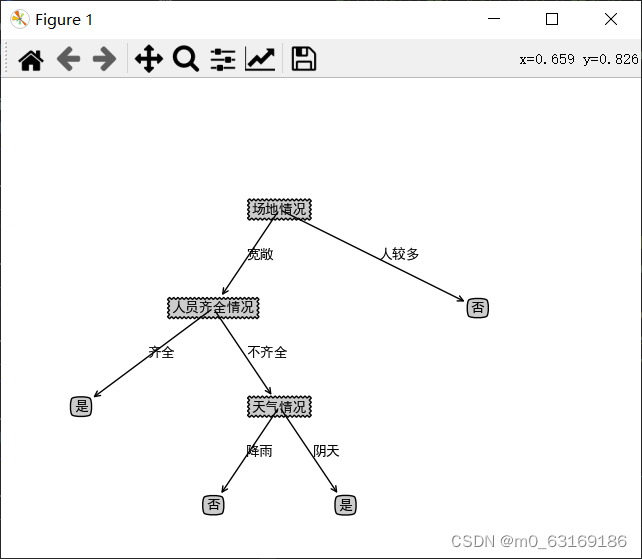
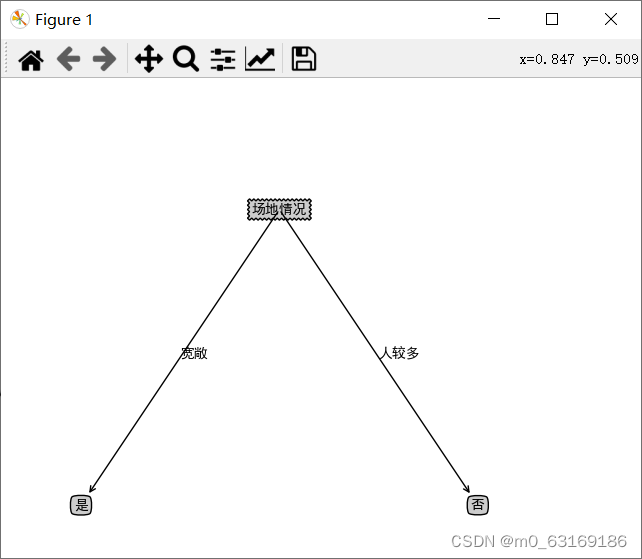
剪枝后的树:
四、总结
在时间开销上,预剪枝的训练时间开销降低、测试时间开销降低,而后剪枝的训练时间开销增加、测试时间开销降低。
在拟合风险方面,预剪枝的过拟合风险降低、欠拟合风险增加,而后剪枝的过拟合风险降低、欠拟合风险基本不变。
而后剪枝的泛化性能通常是优于预剪枝的。
完整代码:
链接:https://pan.baidu.com/s/1Zi7aZcCzWg3ug-2ligpatQ?pwd=3zfw
提取码:3zfw















 5162
5162











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









