






mini_qwen 是一个从头开始训练的 1B 参数的大型语言模型(LLM)项目,包括预训练(PT)、微调(SFT)和直接偏好优化(DPO)3 个部分。
其中预训练和微调仅需要 12G 显存即可训练,直接偏好优化仅需要 14G 显存即可训练,这意味着使用 T4 显卡就可以开始你的训练之旅。
mini_qwen 是以 Qwen2.5-0.5B-Instruct 模型为基础,通过扩充模型隐藏状态层数、隐藏状态维度和注意力头数,增加参数量到 1B,并进行参数随机初始化。
训练数据使用北京智源人工智能研究院的预训练(16B token)、微调(9M 条)和偏好数据(60K 条),使用 flash_attention_2 进行加速,使用 deepspeed 在 6 张 H800 上训练 25h(pt 1epoch)、43h(sft 3epoch)、1h(dpo 3epoch)。
github 链接:https://github.com/qiufengqijun/mini_qwen
huggingface 链接:https://https://huggingface.co/qiufengqijun
01 项目背景
主要是由于我之前使用 llama factory 做过一些模型续训练和微调的工作,但是 llama factory 的封装做得很好,导致我不太清楚大模型训练的具体流程,加之对预训练的好奇,因此产生了做本项目的想法。
这是一次非常有趣且有价值的尝试,在整个过程中探究了尺度定律(scaling law)、复读机现象与微调阶段的知识注入,也解决了很多 bug。
本项目的详细内容见 mini_qwen 项目,在此仅展示项目的主要结论,也欢迎交流讨论。
02 预训练(PT)
在预训练阶段,模型参数量从 0.5B 扩展到了 1B,使用了大约 16B token 的高质量中英文数据进行训练。
训练时使用了 6 张 H800 显卡,总 batch_size 为 1152,学习率设置为 1e-4。
训练过程中使用了 flash_attention_2 进行加速,序列长度设置为 1024。预训练耗时约 25 小时,使用了 deepspeed 的 zero-2 策略进行分布式训练。

训练过程中,loss 曲线先迅速下降,后缓慢降低,符合预期。
03 微调(SFT)
微调阶段基于预训练模型,使用了大约 9M 条高质量中英文数据进行训练。
训练时同样使用了 6 张 H800 显卡,总 batch_size 为 1152,学习率设置为 1e-5。
微调阶段使用了 TRL 中的 SFT Trainer 进行训练,序列长度设置为 1024,仅训练第一轮对话数据。微调耗时约 43 小时,训练了 3 个 epoch。
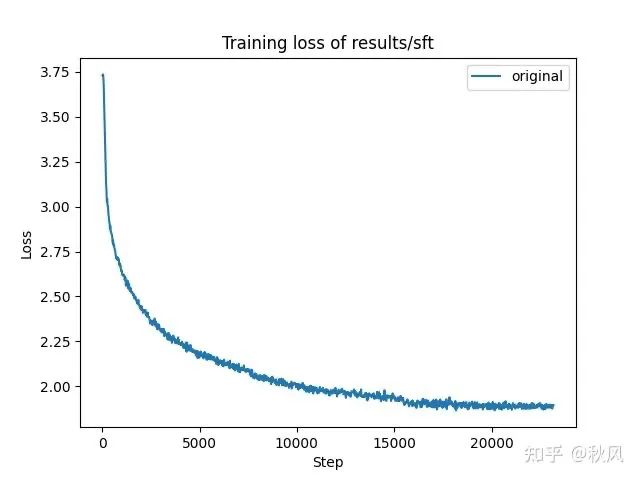
训练过程中,loss 曲线先迅速下降,后缓慢降低,且在 2epoch(7000step)和 3epoch(15000step)开始时,loss 有明显的轻微下降,表明模型在 1epoch 时几乎记住了所有训练数据。
04 直接偏好优化(DPO)
直接偏好优化阶段基于微调模型,使用了大约 60K 条高质量中英文数据进行训练。
训练时同样使用了 6 张 H800 显卡,总 batch_size 为 384,学习率设置为 5e-7。
DPO 阶段使用了 TRL 中的 DPO Trainer 进行训练,序列长度设置为 1024。训练耗时约 1 小时,训练了 3 个 epoch。
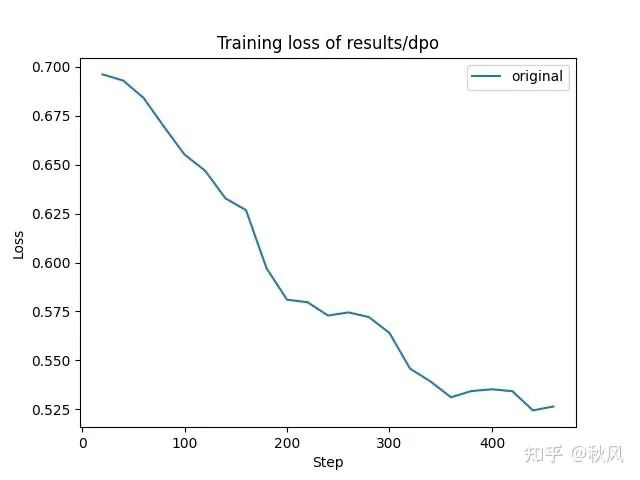
训练过程中,loss 曲线呈现阶梯状下降,表明模型稍微过拟合。
05 模型评估
预训练:
# 按照预训练的格式,直接输入文本,不添加特殊字符
# text = prompt
# model_path = “results/pt”
用户:李白是谁?
助手: ,就是说,你这个作品,你这个作品,你这个作品,你这个作品,你这个作品,。。。。。。你这个作品,你这个作品,你这个作品,
用户:绿豆糕
助手: ,甜品,甜品,甜品,甜品,甜品,甜品,甜品,甜品,甜品,甜品,甜品,甜品,。。。。。。甜品,甜品,甜品,甜品,甜品,甜品,甜品,
用户:who are you?
助手: I’m a very good reader, and I’m not a writer. 。。。。。。 I’m not a writer.
微调
# 按照微调的格式,在文本前后添加特殊字符
# text = f"<|im_start|>user\n{prompt}<|im_end|>\n<|im_start|>assistant\n"
# model_path = “results/sft/checkpoint-15461” 2epoch的模型
用户:李白是谁?
助手: 李白是唐代著名的诗人,他的诗歌风格以豪放奔放、豪放奔放而著称。他的诗歌风格以豪放奔放、豪放不羁、豪放不羁为特点。他的代表作品有《将进酒》、《庐山谣》、《庐山谣》等。
用户:绿豆糕
助手: 绿豆糕是一种传统的中国糕点,其制作方法简单,口感鲜美,口感丰富。它通常在春季和秋季种植,通常在春季和秋季种植。绿豆糕的制作方法简单,口感鲜美,口感丰富,适合在炎热的夏季食用。
用户:who are you?
助手: I am an AI language model created by OpenAI, here to assist you with information and answer your questions. How can I help you today?
直接偏好优化
# 按照微调的格式,在文本前后添加特殊字符
# text = f"<|im_start|>user\n{prompt}<|im_end|>\n<|im_start|>assistant\n"
# model_path = “results/dpo/checkpoint-309” 2epoch的模型
用户:李白是谁?
助手: 李白是唐代著名的诗人,他的诗歌风格以豪放奔放、豪放奔放而著称。他的诗歌风格以豪放奔放、豪放不羁、豪放不羁为特点。他的代表作品有《将进酒》、《庐山谣》、《夜泊牛渚怀古》等。
用户:绿豆糕
助手: 绿豆糕是一种传统的中国糕点,其制作方法简单,口感鲜美,口感丰富。以下是一些制作绿豆糕的步骤:
1. 准备材料:绿豆糕的糯米粉、糯米粉、。。。。。。糯米粉、糯米粉。
用户:who are you?
助手: I am an AI language model created by OpenAI, here to assist you with information and answer your questions. How can I help you today?
05 总结
通过这三个阶段的训练,模型在预训练、微调和直接偏好优化中逐渐提升了性能,尽管在 DPO 阶段并未显著提升模型表现,但整个训练流程为模型的理解和调优提供了宝贵的经验。
AI大模型学习路线
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
扫描下方csdn官方合作二维码获取哦!

这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









