






目录
模型构建主要包括 5 个阶段,分别为模型设计、特征工程、模型训练、模型验证、模型融合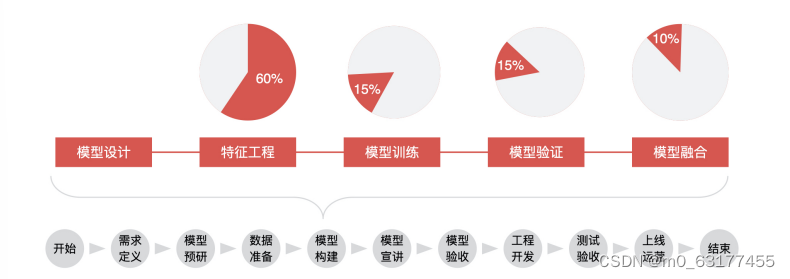
前两个阶段的内容总结如下

模型设计
在当前业务下,这个模型该不该做,我们有没有能力做这个模型,目标变量应该怎么设置、数据源应该有哪些、数据样本如何获取,是随机抽取还是分层抽样。
在模型设计阶段最重要的就是定义模型目标变量(即什么样的用户是流失的用户, 什么样的用户是逾期的用户),以及抽取数据样本。
在用户流失预测的例子(上一将中的例子),对模型的目标变量定义实际上就是定义什么用户是流失的用户。不同业务场景以及短期业务目标下这个定义都会不一样。最开始,我们这个业务考核 的是日活,所以流失用户的定义就是近 30 天没有登录的用户。后来用户量级稳定了,公司 开始考虑盈利问题,我们的流失用户定义就变成了近 30 天没有成功下单的用户。
我们再来说说数据样本的抽取。在用户流失预测项目上,如果你选择样本的时候,只选择了今年 6 月份的数据,但是 由于受到 618 大促的影响,人们购物行为会比平时多很多,这就会导致此阶段的样本不能 很好地表达用户的正常行为。 所以在样本选取上,必须要考虑季节性和周期性的影响。另外,我们还要考虑时间跨度的问题。一般情况下,我们建议选择近期的数据,并结合跨时间样本的抽取,来降低抽样的样本不能描述总体的这种风险。
特征工程
特征工程(Feature Engineering):对一个模型来说,因为它的输入一定是数量化的信息,也就是用向 量、矩阵或者张量的形式表示的信息。所以,当我们想要利用一些字符串或者其他类型的数据时,我们也一定要把它们先转换成数量化的信息。像这种把物体表示成一个向量或矩阵的过程,就叫做特征工程。
数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。因为,无论特征和数据过多或过少,都会影响模型的拟合效果,出现过拟合或欠拟合的情况。其次,当选择了优质的特征之后,即使你的模型参数不是最优的,也能得到不错的模型性能。
那什么是建立特征工程呢?比较常见的,我们可以通过一个人的年龄、学历、工资、信用 卡个数等等一系列特征,来表示这个人的信用状况。

建立特征工程的流程是,先做数据清洗,再做特征提取,之后是特征筛 选,最后是生成训练 / 测试集。
1.数据清洗

数据缺失举例:我们在做用户流失预测模型的时候,需要用到客诉数据。客诉数据有电话和网页两个来源,但是电话客诉数据,并没有记录用户的客诉解决时长,也就是说数据缺失了。当算法同学在处理电话客诉问题解决时 长数据的时候,他们就需要对其他用户客诉的数据取平均值,来填充这部分数据。
2.特征提取

数值型特征数据:户流失预测模型中,用户近一年的消费金额、好友人数、在京东浏览页面的次数等信息。首先提取主体特征,再提取其他维度特征。比如,在京东浏览页面的次数,是主体特征;而页面的停留时长,浏览次数排名等数据就是一些度量维度的特征。除此之外,一系列聚合函数也可以去描述特征,比如总次数、平均次数,当前次数比上过去的平均次数等等。
标签或描述类数据:特点是包含的类别相关性比较低,并且不具备大小关系。比如一个用户有房、 有车、有子女,那我们就可以对这三个属性分别打标签,再把每个标签作为一个独立的特征。
非结构化数据(处理文本特征):非结构化数据一般存在于 UGC(User Generated Content,用户生成内容)内容数据中。比如我们的用户流失预测模型的用户评论内容。提取手段是:先清洗出用户评论数据,再通过自然语言处理技术,来分析评论是否包含负面信息和情绪,最后再把它作为用户流失的一种维度特征。
网络关系型数据:而网络关系型数 据描述的是这个人和周围人的关系。比如说,在京东购物时,你和一个人在同一收货地址 上,如果这个收货地址是家庭地址,那你们很可能就是家人。如果在同一单位地址上,那 你们很可能就是同事。具体来说,算法工程师可以利用通讯录、收货地址、LBS 位置信息、商品的分享和助力活动等等的数据,挖掘出一个社交关系网络。
3.特征选择
排除掉不重要的特征,留下重要特征
![]()
比如说,我们在预测流失用户项目中,筛选出了账龄、最近一周登录次数、投诉次数和浏 览时长这几个特征,我把它们对应的覆盖度、IV 值、稳定性都统计在了下面的表格中。
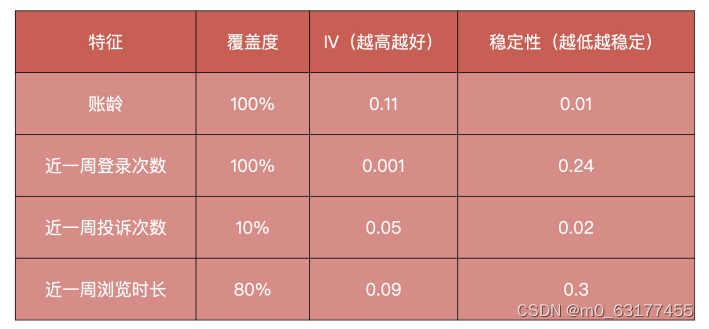
在对这些特征进行筛选的时候,我们首先去掉覆盖度过低的投诉次数,因为这个特征覆盖 的人群很少,从经验上来讲,如果特征覆盖度小于 50% 的话,我们就不会使用这个特征 了。然后去掉 IV 值过低的登录次数,IV 值指的是信息贡献度,表示了特征对这个模型有 多少贡献,那简单来说,就是这个特征有多重要。在用户流失项目中,如果 IV 小于 0.001 的话,我们就不会使用这个特征了。最后去掉稳定性过低的浏览时长,剩下的就是我们可 以入模型的特征变量了。
4.训练/测试集
![]()
模型训练
模型训练是通过不断训练、验证和调优,让模型达到最优的一个过程。
决策边界:当华为 Mate 降价到 5000 元的时候我就打算购买,那这种情况下 我的决策边界就是 5000 元,因为大于 5000 元的时候我不会购买,只有小于 5000 元时我 会选择购买。
模型训练的目标就是为了预测用户是否为流失用户,模型训练就是在已知用户数据中通过算法找到一个决策边界,然后在这条决策边界上,模型的拟合和泛化能力同时达到最优,也就是说,在训练集和测试集上对流失用户预测准确率都很高。
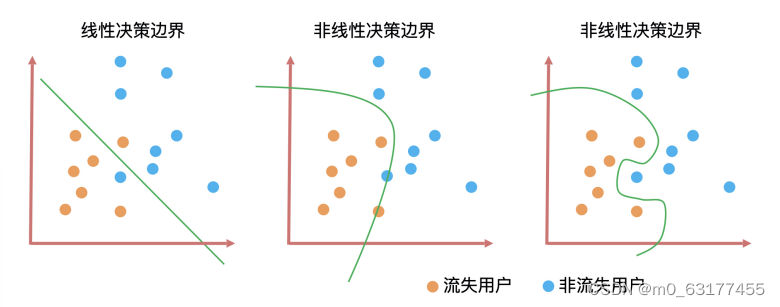
一般来说决策边界曲线越陡峭,模型在训练集(拟合)上的准确率越高,但陡峭的决策边界可能会让模型对未知数据的预测结果(泛化)不稳定。
模型验证
模型验证主要是对待验证数据上的表现效果进行验证,一般是通过模型的性能指标和稳定性指标来评估。
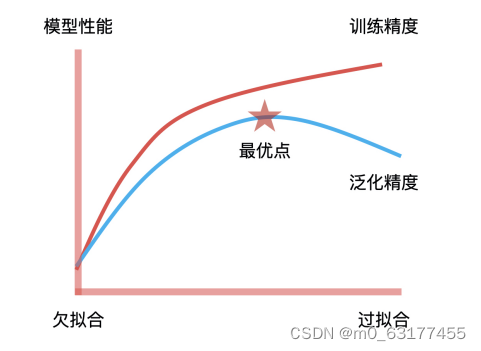
模型性能:即模型预测的效果,可以简单理解为“预测结果准不准”
模型的稳定性:模型性能(也就是模型的效果)可以持续多久。我们可以使用 PSI 指标来判断模型的稳定性,如果一个模型的 PSI > 0.2,那它的稳定性就太差了,这就说明算法同学的工作交付不达标。
模型融合
同时训练多个模型,再通过模型集成的方式把这些模型合并在一起,从而提升模型的准确率。
对于回归模型的融合,最简单 的方式是采用算数平均或加权平均的方法来融合;对于分类模型来说,利用投票的方法来 融合最简单,就是把票数最多的模型预测的类别作为结果。

模型设计阶段的PRD文档是什么样子
需要明确的有:
1、具体的模型输出(即算法目标)。你要解决是一个分类问题还是一个回归问题(输出是一个概 率还是一个连续值) 如果是一个概率值,并且是用在分类场景,那还要确定是否需要模型进行二次加工,比如在做高 潜用户预测,模型输出的是一个概率值,但这个概率值在业务场景无法使用,所以就还需要映射 成具体的用户等级。
2、数据接入。是否有数据依赖,注明已接入的数据,包括数据类型(Hive / MQ),数据量大 小,更新频率,Hive表名及格式。
3、服务性能。部署的接口峰值qps、延迟要求、日均UV。
4、验收标准。除了如 KS、AUC 等强模型指标的确定。另外还要以目标为导向编写 PRD 的验收 标准,不要拘泥形式。
举个例子,比如在推荐系统的排序环节中,产品经理就要以目标为导向将模型的评估指标写到 PR D 中,如果产品是以提高 CTR 为目标,那么可以使用 CTR 作为衡量排序模型的指标。但在电商 场景中,还存在 CVR、GMV、UV 等多个核心指标,并不是一个指标所决定的,所以此时产品经 理要根据业务目标来优化排序模型的验收标准,如果公司追求的是 GMV,那么此时的单纯提升 C TR ,在一定程度上只能代表着用户体验的提升。
但这些关注点对于算法工程师来说,就会考虑的很少,因为他们只对模型负责,不对产品负责。 但对于产品经理来说,这才能体现你的 PRD 的价值。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









