







目录
3.逻辑回归(LR,Logistic Regression)
4.朴素贝叶斯(NBM,Naive Bayesian Model)
6.支持向量机机(Support Vector Machine,SVM)
机器学习分类
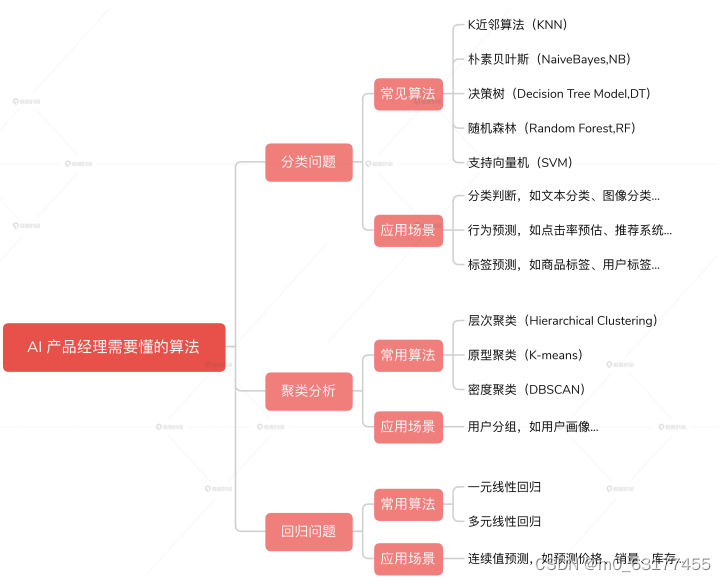
分类问题、回归问题、聚类问题
1.K近邻算法(K-Nearest Neighbor)
KNN 是基于距离的一个简单分类算法。
原理:对于一个待测的样本点,我们去参考周围最近的已知样本点的分类,如果周围最近的 K 个样本点属于第一类,我们就可以把这个待测样本点归于第一类。
优点:简单易懂,实现起来非常容易,不需要进行训练;在处理边界不规则数据的分类问题时要比线性分类器的效果好
缺点:只适合小数据集,因为它在处理数据量比较大的样本时会非常 耗时,所以,在实际工业中,我们一般会选用 Kd-tree 来进行预测。对数据容错性偏低,当待测样本周围的 K 个 数据样本中存在错误样本的时候,就会对预测结果有很大的影响。
例子:预测候选人能不能拿到 Offer
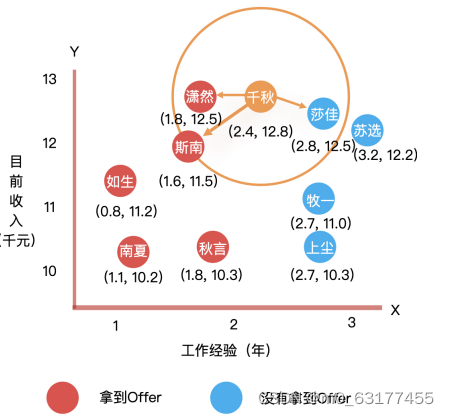
X 轴代表候选者的工作年限,Y 轴代表候选者目前的月收入,我 们对拿到 Offer 的人用红色进行了标记,对没拿到的用蓝色进行了标记。
现在让你预测千秋同学能否拿到offer。
假如k值取3,就在千秋同学的附近,选出距离他最近的 3 个人,分别是潇然、斯南和莎佳。这三人中,潇然和斯南同学都拿到了 Offer,莎佳同学没拿到 Offer。这样一来,我们就可以直接预测出千秋同学是可以拿到 Offer 的,因为距离最近的 三个人当中,拿到 Offer 的人数大于没有拿到 Offer 的人数,或者说“少数服从多数”。
当 K 取 1 的时候,就表示我们只评估与待测样本最近的一个样本的值是什么分类就行了, 如距离千秋同学最近的是莎佳,她最终没有拿到 Offer ,所以,我们就可以预测千秋同学 也拿不到 Offer。
当 K 取 9 的时候,就表示我们需要评估与样本集个数一样的样本点。可想而知,最终的结 果就和整体的样本分布一样了,哪个分类的样本多,预测结果就是哪个分类,模型也就不 起作用了。
当 K 越小的时候,模型就越容易过拟合;K 越大的时候,就越容易欠拟合。所以,对于 K 的取值,一种有效的办法就是从 1 开始不断地尝试,并对比准确率,然后选取效果最好的那个 K 值。
2.线性回归(Linear Regression)
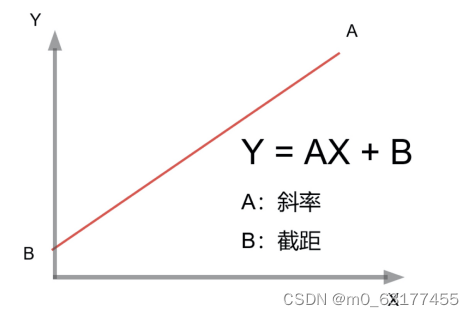
原理:已知线性回归方程是 Y = AX + B,我们将已有数据代入到这个方程中,然后求得出一组 A 和 B 的最优解,最终拟合出一条直线,使得图中每个点到直线的距离最短,也就是损失函数最小。这样,我们就能通过这个最优化的 A 和 B 的值,估算出新的数据 X 和 Y 的关系,进行数据的预测。
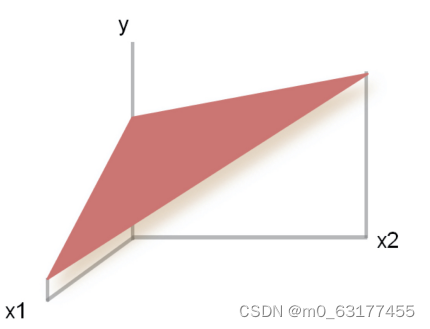
上面是一元回归方程,因为影响结果 Y 的其实只有一个影响因素 X。如果有多个影响因素,比如预测银行贷款,贷款人的工资和年龄都会影响贷款额度。这个时候,我们就要构建二元回归方程了,它的分布也不再是一 条直线,而是一个较为复杂的平面了,公式是 Y=A1 X +A2 X +B。同理,还有多元回归方程。
优点:简单易实现,运算效率高,可解释性很强。
缺点:预测的准确度比较低,不具备求解一个非线性分布的能力
应用场景:如预测身高、预测销售额、 预测房价、预测库存等等
3.逻辑回归(LR,Logistic Regression)
原理:在线性回归模型基础上,把原有预测的连续值转化成一个事件的概率,用来解决分类问题
当线性回归的预测结果,由于受到个别极端数值的影响而不准的时候,我们就可以用逻辑 回归来解决。
在数学中,我们通常会采取一些平
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









