






前言
爬虫广泛应用于各个领域,如搜索引擎索引网页、新闻聚合网站抓取新闻内容、价格比较网站获取商品信息等。它们可以帮助我们自动化获取大量的数据,并且可以在短时间内完成大量的工作。爬虫可以通过获取网页的源代码,解析其中的信息,并提取所需的数据。它们模拟了人类用户在网页上的行为,自动访问链接、点击按钮、填写表单等操作,以便能够收集需要的数据
一、etree.HTML()和.json()分别是什么?
新学到的有.json(),它是用于解析JSON格式数据的方法,JSON(javaScript Object Nation)是一种常用的数据交换格式,用于存储和传输结构化的数据。在python中,使用requests库发送HTTP请求并获取响应后,使用.json()方法将响应的JSON数据解析为python对象。
类似于etree.HTML()函数将HTML字符串解析为一个可操作的树形结构,以便进一步处理和提取数据
但是,在这段代码中,etree.HTML(hero_info_resp.text),这里hero_info_resp作为一个响应对象。它包含了虚许多与HTTP响应相关的信息,如状态码,头部信息和响应内容,为了获取响应内容,使用.text属性
二、步骤
1.请求英雄列表
代码如下(示例):
hero_list_url='https://pvp.qq.com/web201605/js/herolist.json'
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36 Edg/115.0.1901.203'
}
hero_list_resp=requests.get(hero_list_url,headers=headers)
for h in hero_list_resp.json():
ename=h.get('ename')
cname=h.get('cname')
2.请求单个英雄皮肤数据并保存在文件夹中
代码如下(示例):
if not os.path.exists(cname):
os.makedirs(cname)
hero_info_url='https://pvp.qq.com/web201605/herodetail/194.shtml'
hero_info_resp=requests.get(hero_info_url,headers=headers)
hero_info_resp.encoding='gbk'
e=etree.HTML(hero_info_resp.text)
names=e.xpath('//ul[@class="pic-pf-list pic-pf-list3"]/@data-imgname')[0]
names=[name[0:name.index('&')] for name in names.split('|')]
for i,n in enumerate(names):
resp=requests.get(f'http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/{ename}/{ename}-bigskin-{i+1}.jpg')
with open(f'{cname}/{n}.jpg','wb') as f:
f.write(resp.content)
print(f'已经下载{n}的皮肤')
sleep(1)
以下是代码展示
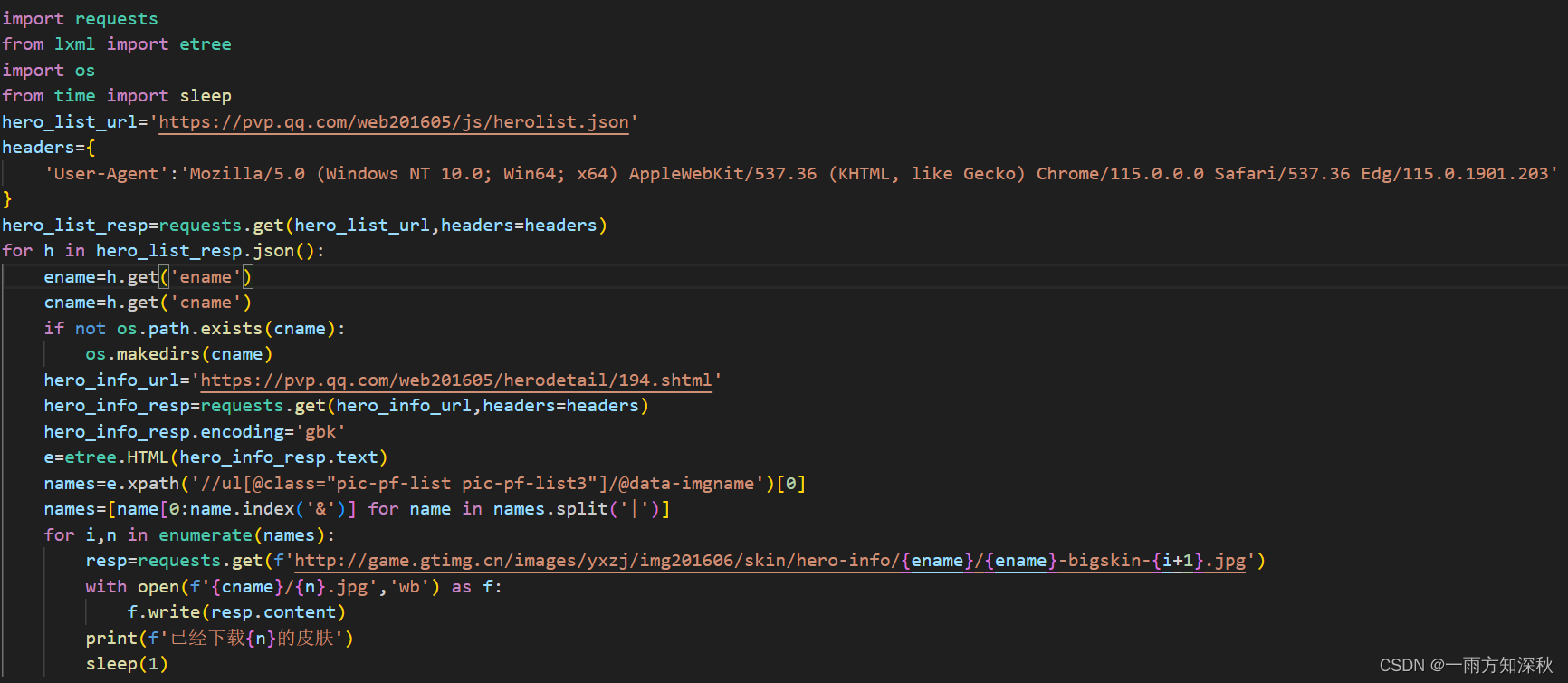
运行结果
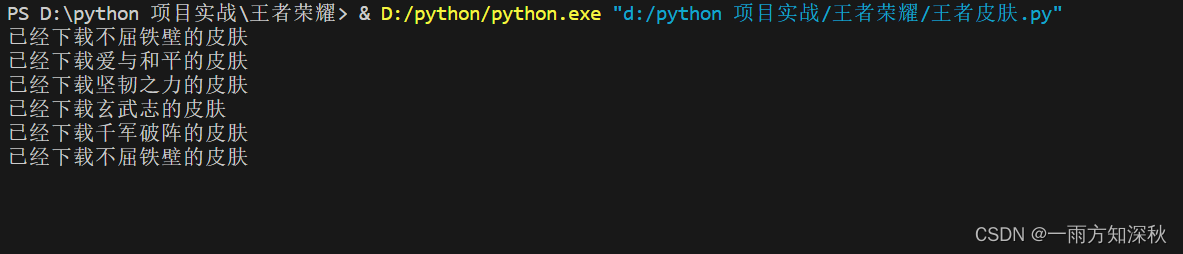
在左边栏目录会出现每个英雄皮肤名字的文件夹
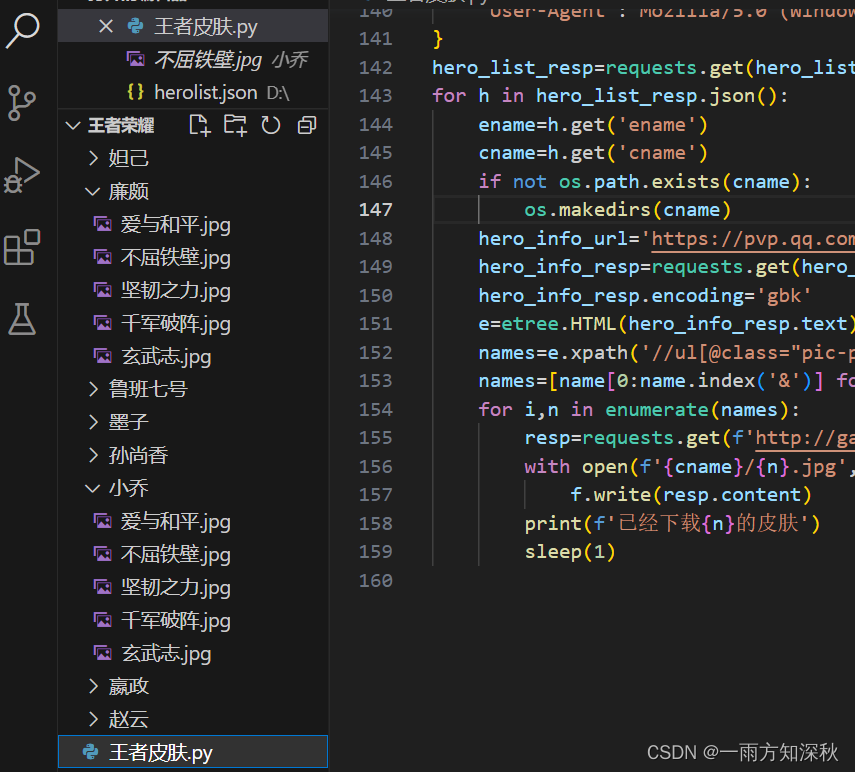
点开每个文件夹就能看到每个英雄的皮肤图片了
总结
for h in hero_list_resp.json():
ename=h.get('ename')
cname=h.get('cname')遍历json对象中的每个元素,将每个元素赋值给变量h,通过调用字典对象的.get()方法获取键对应的值。
if not os.path.exists(cname):
os.makedirs(cname)
段是用来检查当前目录下是否存在一个名为cname的文件或文件夹,如果不存在会返回False,则继续往下执行代码,并创建名字为cname的文件夹。
在请求单个英雄皮肤响应时出现乱码情况,将响应对象编码方式设置为国标码gbk,中国国标码
names=e.xpath('//ul[@class="pic-pf-list pic-pf-list3"]/@data-imgname')[0],用xpath从已经解析的HTML中提取属性值,这里提取的是单个英雄皮肤所有的名字。对names字符串进行拆分,对拆分后的的子字符串进行切片操作,获取每个字字符串到第一个&之间的部分,并将结果存储在名为names的列表中。
for i,n in enumerate(names):遍历names中的元素,在每次迭代时获取元素索引和值。















 3595
3595











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









