







一、背景介绍
在进行个人博客撰写时,实现了一个功能:用户登录博客之后,可以进行添加博客。在写博客时,项目中使用了markdown的api,因此用户书写博客后,博客是使用markdown格式进行展示。譬如下图:

点击 写博客之后,页面跳转来到markdown编辑器界面。
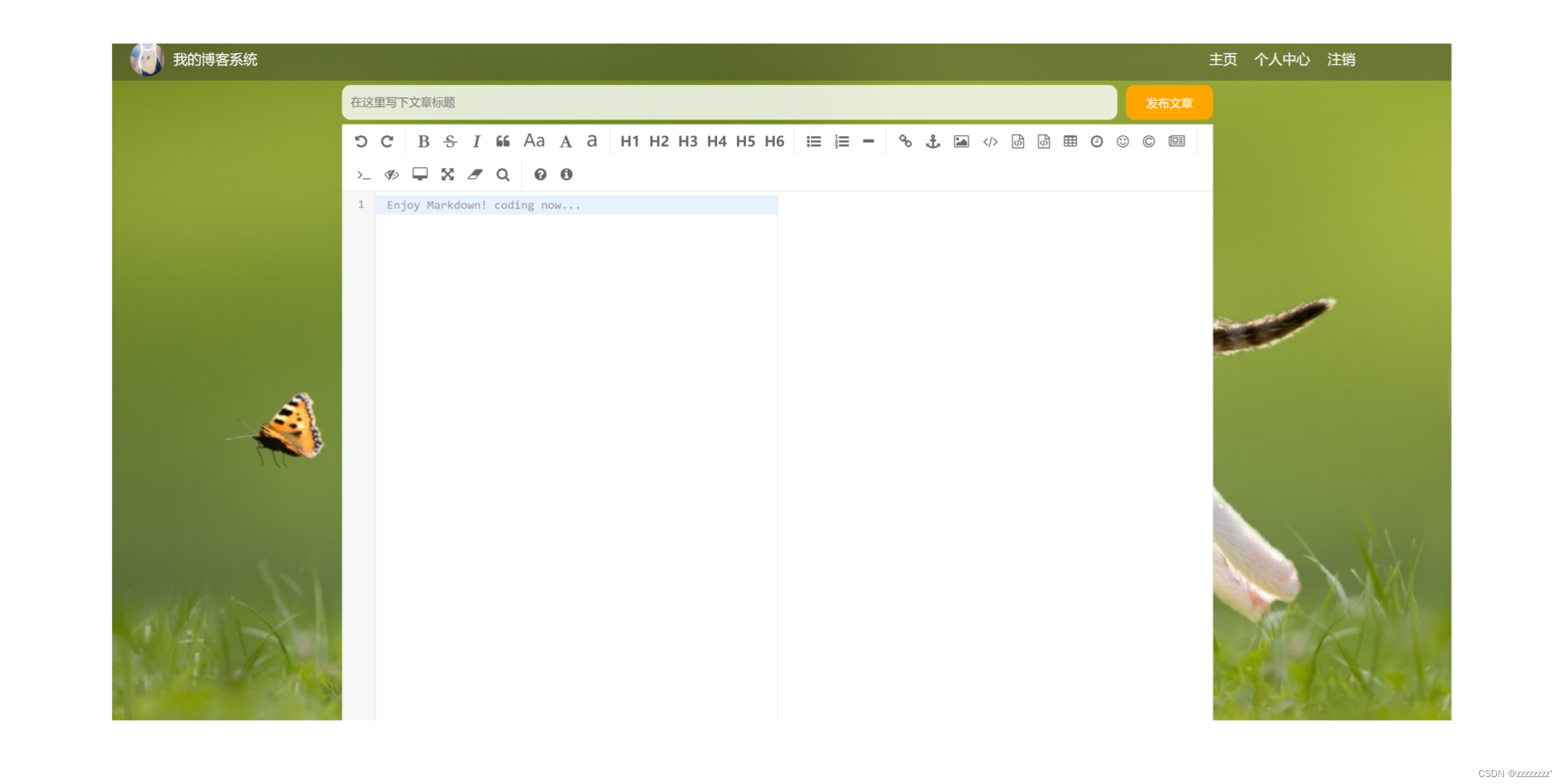
在markdown中写博客时,markdown有自己的格式。譬如像# 表示一级目录,## 表示二级目录… 当我们书写:#浅谈SpringBoot ,在markdown中表示一级目录,#是不存在的,#表示的是一种格式,但如果这行话不在markdown中展示的话,#是存在的,因此此时整篇文章通篇带着#、···这些字符的话,整篇文本就会显得杂乱。

markdown格式的文本在markdown中展示是没有问题的,一些特定字符如#会被markdown识别成特定格式,但是如果markdown格式不在markdown中展示,而是在别的地方展示,markdown格式中特殊字符如#没办法被识别自定转成特定格式,文章就会除了文本之外,还有很多特殊字符,这样的文章是杂乱无章,降低用户的可读性。此时我们就需要将markdown格式的文本转化成纯文本格式,以保证文章展示的可读性和高可用性。

那么如何去除markdown格式,转化成纯文本格式呢?
二、将markdown格式转化成纯文本格式
1、在pom.xml中添加依赖
在pom.xml中添加下述依赖:

依赖:
<dependency>
<groupId>org.commonmark</groupId>
<artifactId>commonmark</artifactId>
<version>0.17.0</version>
</dependency>
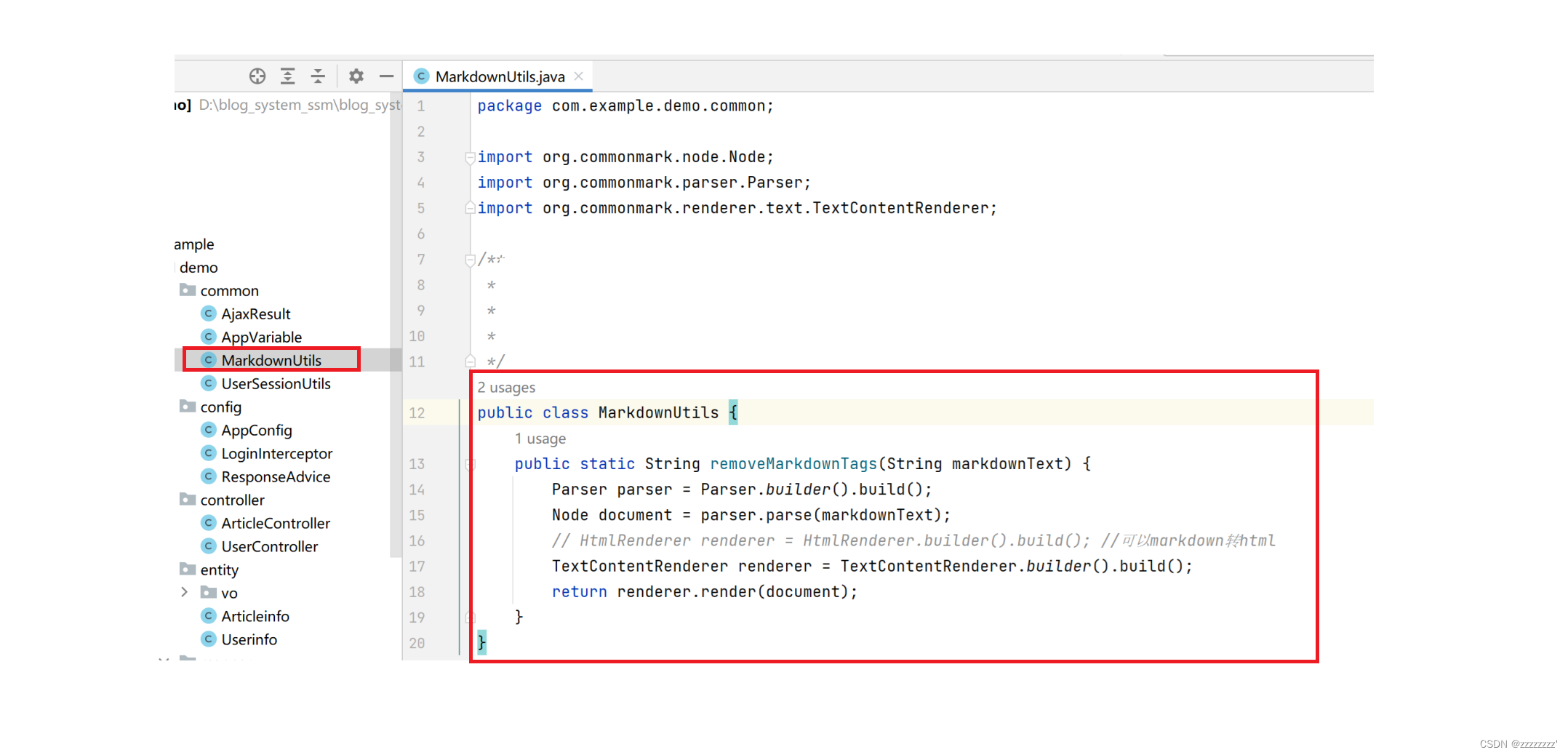
2、java代码
import org.commonmark.node.Node;
import org.commonmark.parser.Parser;
import org.commonmark.renderer.text.TextContentRenderer;
/**
* @author hzz
* @createtime 2024/01/31
* @function 去除markdown格式,将markdown转成纯文本
*/
public class MarkdownUtils {
public static String removeMarkdownTags(String markdownText) {
Parser parser = Parser.builder().build();
Node document = parser.parse(markdownText);
// HtmlRenderer renderer = HtmlRenderer.builder().build(); //可以markdown转html
TextContentRenderer renderer = TextContentRenderer.builder().build();
return renderer.render(document);
}
}
在项目中调用上述java代码,将markdown格式转成纯文本格式。
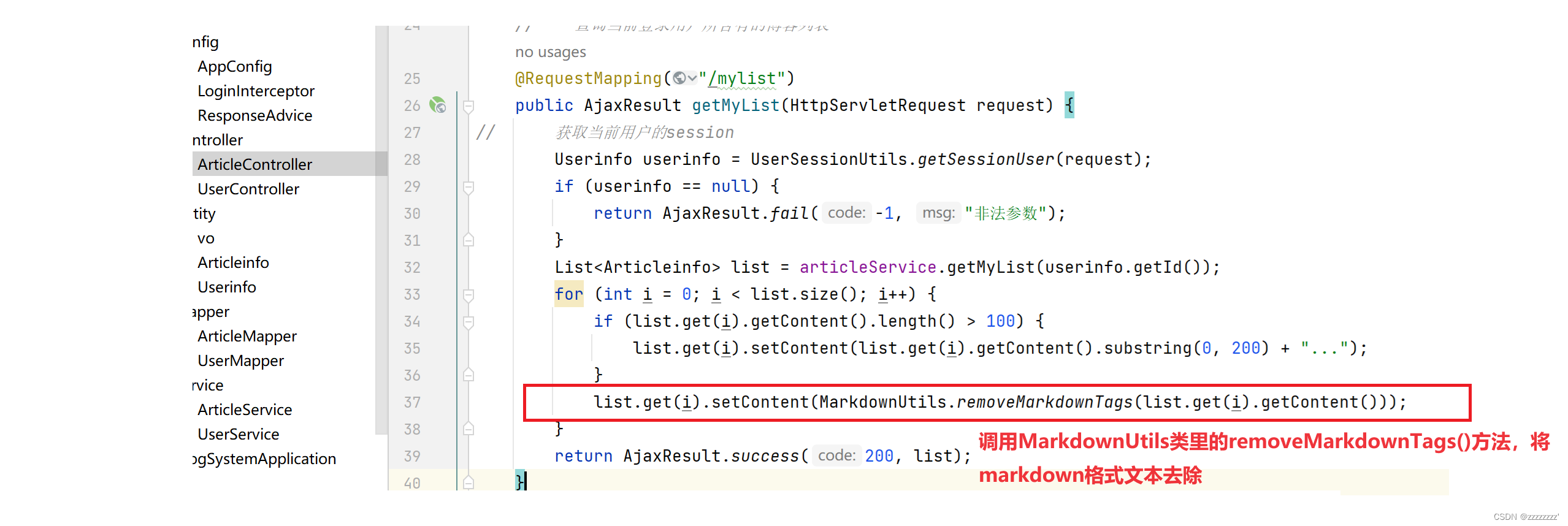
去除markdown格式之后的文本效果:


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









