







🌈Yu-Gateway::基于 Netty 构建的自研 API 网关,采用 Java 原生实现,整合 Nacos 作为注册配置中心。其设计目标是为微服务架构提供高性能、可扩展的统一入口和基础设施,承载请求路由、安全控制、流量治理等核心网关职能。
🌈项目代码地址:GitHub - YYYUUU42/YuGateway-master
如果该项目对你有帮助,可以在 github 上点个 ⭐ 喔 🥰🥰
🌈自研网关系列:可以点开专栏,参看完整的文档
目录
1、什么是过滤器
在我们的微服务架构中,构建了一个关键组件——网关服务,它作为系统的入口,负责对所有进、出流量进行统一管理和控制。为了实现这一功能,前面文章已成功将其注册至注册中心,并从配置中心获取了相关配置。接下来,我们将深入探讨如何构建网关服务的核心部分——过滤器链。
过滤器链,顾名思义,是由一系列有序排列的过滤器构成的执行链条。每个过滤器承载特定的业务逻辑,对经过的请求和响应进行特定处理。当一个过滤器完成其预设的过滤流程后,会遵循链条顺序,将请求传递给下一个过滤器继续执行。通过这种方式,过滤器链实现了对请求与响应的深度定制化处理。
过滤器链中的成员可根据其作用范围分为全局过滤器和局部过滤器两种类型:
- 全局过滤器:这类过滤器具有广泛的适用性,对所有进入网关的请求均进行处理。它们通常负责执行诸如身份验证、权限校验、日志记录、跨域支持等通用性操作,确保所有请求在到达具体业务服务前符合系统的基本规范和要求。
- 局部过滤器:Spring Cloud框架已为我们预置了一套局部过滤器,用于应对特定场景下的请求处理。尽管如此,我们依然可以根据实际需求,通过继承并实现相关接口来自定义局部过滤器,以满足特定业务逻辑或优化性能。
过滤器链的运作机制遵循严格的流程:
- 请求首先被送入链首的过滤器进行处理。
- 每个过滤器依据自身职责对请求进行检查、修改或增强,然后将处理后的请求传递给链中的下一个过滤器。
- 这一过程持续进行,直到链尾的路由过滤器接收到请求。路由过滤器的核心职责是根据请求信息和预设的路由规则,准确地将请求转发至相应的后台服务进行实际业务处理。
- 后台服务完成任务后,将响应返回给路由过滤器。
- 路由过滤器再将响应沿着过滤器链逆序传递,让每个过滤器有机会对响应进行必要的后期处理。
- 最终,经过完整过滤器链洗礼的响应被写回客户端。
在过滤器链执行过程中,若遇到任何异常情况,可通过设置专门的异常处理过滤器来捕获并妥善处理这些异常,如返回友好的错误信息、记录异常日志等,确保系统的稳定性和用户体验。
当请求在整个生命周期中均正常流转且后台服务处理完毕后,使用 context.writeAndFlush() 方法将处理结果(即响应数据)高效地写回客户端,标志着一次完整的请求响应流程在过滤器链的保驾护航下圆满结束。
综上所述,过滤器链作为网关服务的核心组件,通过串联各个具有特定功能的过滤器,对进出系统的请求与响应进行全方位、多层次的精细化管理,实现了微服务架构下流量的有效管控与优化。
大概流程图:
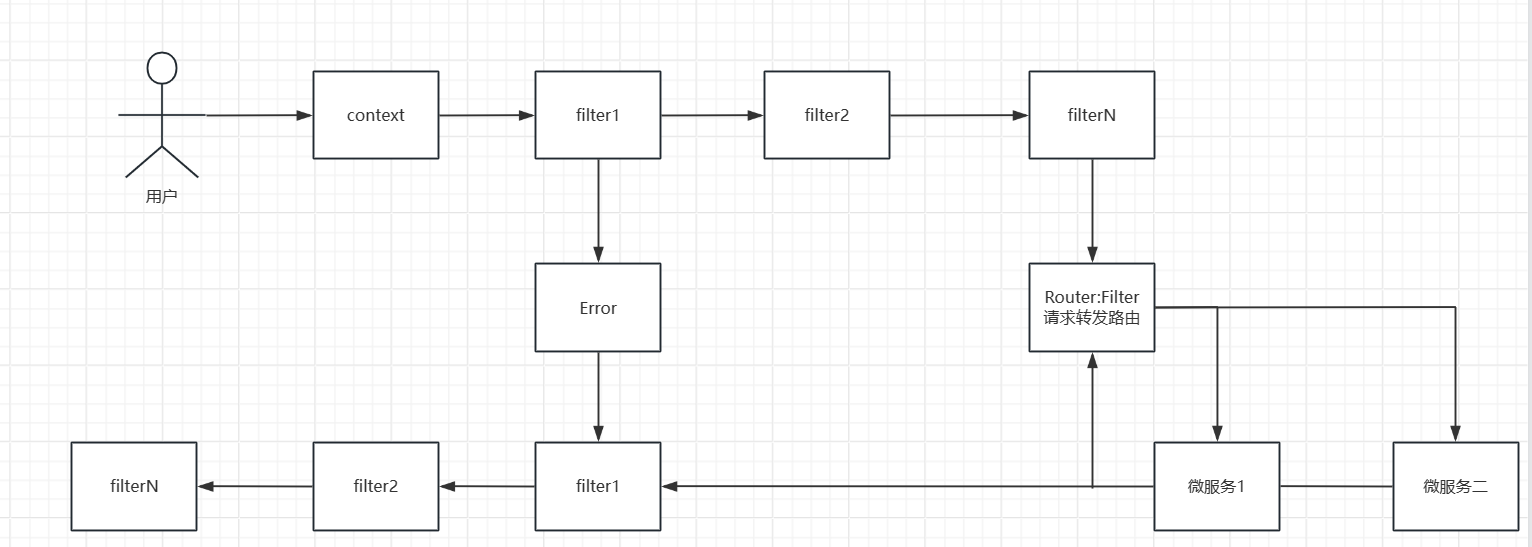
2、实现过滤器
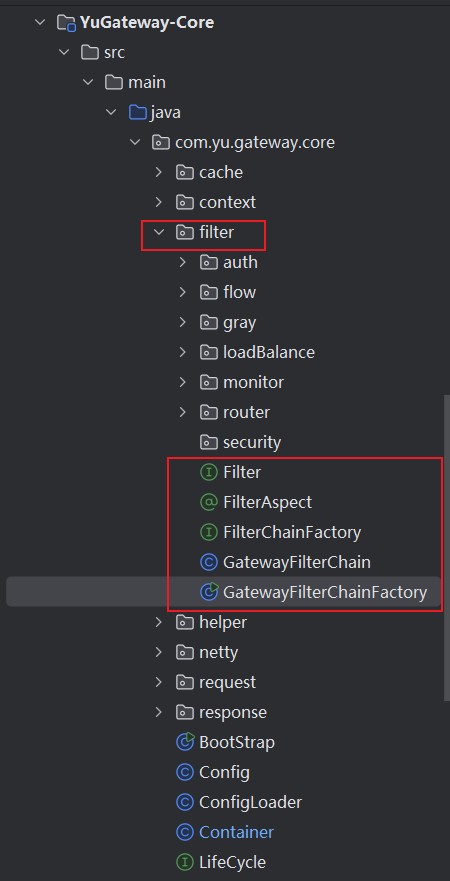
项目结构图
具体代码在 github 上,不一一展示
- Filter:这是一个接口,定义了过滤器需要实现的方法。所有的过滤器都需要实现这个接口,并实现doFilter方法来执行具体的过滤操作。getOrder方法用于获取过滤器的执行顺序。
- FilterAspect:这是一个注解,用于标记过滤器的一些属性,如ID、名称和执行顺序。这个注解被应用在实现了Filter接口的类上。
- FilterChainFactory:这是一个接口,定义了过滤器链工厂需要实现的方法。过滤器链工厂的主要职责是根据给定的上下文构建过滤器链。
- GatewayFilterChain:这是一个类,代表了过滤器链。它包含了一个过滤器列表,并提供了添加过滤器和执行过滤器链的方法。
- GatewayFilterChainFactory:这个类的具体实现可能会根据你的应用有所不同,但一般来说,它应该是FilterChainFactory接口的一个实现,负责创建GatewayFilterChain实例。这个类可能会使用单例模式,以确保整个应用只有一个GatewayFilterChainFactory实例。
总的来说,这些类和接口共同工作,以创建和管理过滤器链。过滤器链是由一系列过滤器组成的,这些过滤器按照特定的顺序执行,以对通过网关的请求进行处理。
3、实现流程
和之前一样,通过 debug 的方式来讲解过滤器链的实现
首先过滤器工厂具体实现类的无参构造
/**
* SPI加载本地过滤器实现类对象
* 过滤器存储映射 过滤器id - 过滤器对象
*/
public GatewayFilterChainFactory() {
//加载所有过滤器
ServiceLoader<Filter> serviceLoader = ServiceLoader.load(Filter.class);
serviceLoader.stream().forEach(filterProvider -> {
Filter filter = filterProvider.get();
FilterAspect annotation = filter.getClass().getAnnotation(FilterAspect.class);
log.info("load filter success:{},{},{},{}", filter.getClass(), annotation.id(), annotation.name(), annotation.order());
//添加到过滤集合
String filterId = annotation.id();
if (StringUtils.isEmpty(filterId)) {
filterId = filter.getClass().getName();
}
processorFilterIdMap.put(filterId, filter);
processFilterIdName.put(filterId, annotation.name());
});
}这里还是和注册和配置中心一样的思路,用 SPI 来加载类,加载实时可用的过滤器,组装为网关过滤器链
然后就将各个过滤器的id,名称,排序弄到 ConcurrentHashMap 中

其中 GatewayFilterChainFactory 类采用的是单例模式
在网关之中,GatewayFilterChainFactory 负责创建和管理过滤器链。由于过滤器链在整个应用中是共享的,因此没有必要为每个请求创建一个新的 GatewayFilterChainFactory 实例。
使用单例模式可以确保所有的请求都使用同一个GatewayFilterChainFactory实例,这样可以避免重复创建实例,节省内存,并保证所有请求使用的过滤器链的一致性。
此外,GatewayFilterChainFactory 在初始化时会加载所有的过滤器,这可能是一个耗时的操作。如果每个请求都创建一个新的 GatewayFilterChainFactory 实例,那么这个耗时的初始化操作就会被重复执行,这会影响应用的性能。
使用单例模式,初始化操作只会执行一次,可以提高应用的性能。 总的来说,这里使用单例模式是为了保证过滤器链的一致性,节省内存,提高性能。
在 NettyCoreProcessor 会获取 GatewayFilterChainFactory 这个单例的
/**
* 过滤器链工厂
*/
private FilterChainFactory chainFactory = GatewayFilterChainFactory.getInstance();在 process 方法中调用构建过滤器链条这个功能
// 创建并填充 GatewayContext 以保存有关传入请求的信息。
GatewayContext gatewayContext = RequestHelper.doContext(request, ctx);
// 组装过滤器并执行过滤操作
chainFactory.buildFilterChain(gatewayContext).doFilter(gatewayContext);构建过滤器链条利用本地缓存,主要确保对于同一规则ID的请求,可以复用已经构建的过滤器链,而不需要每次都重新构建,从而提高了性能
/**
* 过滤器链缓存(服务ID ——> 过滤器链)
* ruleId —— GatewayFilterChain
*/
private Cache<String, GatewayFilterChain> chainCache = Caffeine.newBuilder().recordStats().expireAfterWrite(10, TimeUnit.SECONDS).build();/**
* 构建过滤器链条
*/
@Override
public GatewayFilterChain buildFilterChain(GatewayContext ctx) throws Exception {
// 获取规则ID
String ruleId = ctx.getRules().getId();
// 从缓存中获取过滤器链
GatewayFilterChain chain = chainCache.getIfPresent(ruleId);
// 如果缓存中没有过滤器链,那么构建一个新的过滤器链
if (chain == null) {
chain = doBuildFilterChain(ctx.getRules());
// 将新构建的过滤器链添加到缓存中
chainCache.put(ruleId, chain);
}
// 返回过滤器链
return chain;
}构建一个新的过滤器链
根据给定的规则构建一个过滤器链,这个过滤器链用于处理 HTTP 请求
为什么每个服务请求最终最后需要添加路由过滤器
在网关中,路由过滤器的作用是将请求路由(转发)到适当的后端服务。
在过滤器链中,路由过滤器通常是最后一个执行的过滤器,因为它需要在所有其他过滤器(如权限、限流、负载均衡等)成功执行后才进行路由。
这个方法中,路由过滤器被添加到过滤器链的末尾,这是因为在执行所有其他过滤器并对请求进行各种检查和处理后,最后的步骤是将请求路由到适当的后端服务。
如果没有路由过滤器,那么即使请求通过了所有其他过滤器,也无法到达任何后端服务,因此每个服务请求最终都需要添加路由过滤器。
在 NettyCoreProcessor 中还会执行 doFilter() 方法,就是遍历过滤器链,逐个执行过滤
// 组装过滤器并执行过滤操作
chainFactory.buildFilterChain(gatewayContext).doFilter(gatewayContext);/**
* 执行过滤器链
*/
public GatewayContext doFilter(GatewayContext ctx) {
if (filters.isEmpty()) {
return ctx;
}
try {
for (Filter filter : filters) {
filter.doFilter(ctx);
}
} catch (Exception e) {
log.error("执行过滤器发生异常: {}", e.getMessage());
throw new RuntimeException(e);
}
return ctx;
}大概的过滤器设计就这样,还是需要自己根据代码 debug 一下才能根据清晰,点个 ⭐ !!!















 6862
6862

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









