






1. 环境安装条件
1.1 版本兼容问题
本人在安装过程中遇到的很多问题是由版本不兼容导致的,安装完成后的版本:
Ubuntu 18.04.6
VMware Workstation16
VMtools-Tools-10.3.21
hadoop-3.1.2
jdk 1.8.0_362
windows11系统下安装vm15会出现蓝屏警告,安装vm17会出现vmware tools 下载完成后还是不能拖动共享文件的问题,可能是vmtools的版本与ubuntun不兼容的问题。当然如果您是能解决版本兼容问题的大佬就当我没说。
1.2 关于VMware-tools的作用
安装完成重启主机后大家都能发现桌面上多了个光驱,鼠标可以在windows系统和linux系统随意滑动,windows的文件也可以直接拖动到linux系统。可能大家没发现的:同步了虚拟机和主机的时间,提供了高显示分辨率,更新虚拟机中的显卡驱动,使虚拟机中的XWindows可以运行在SVGA模式下。
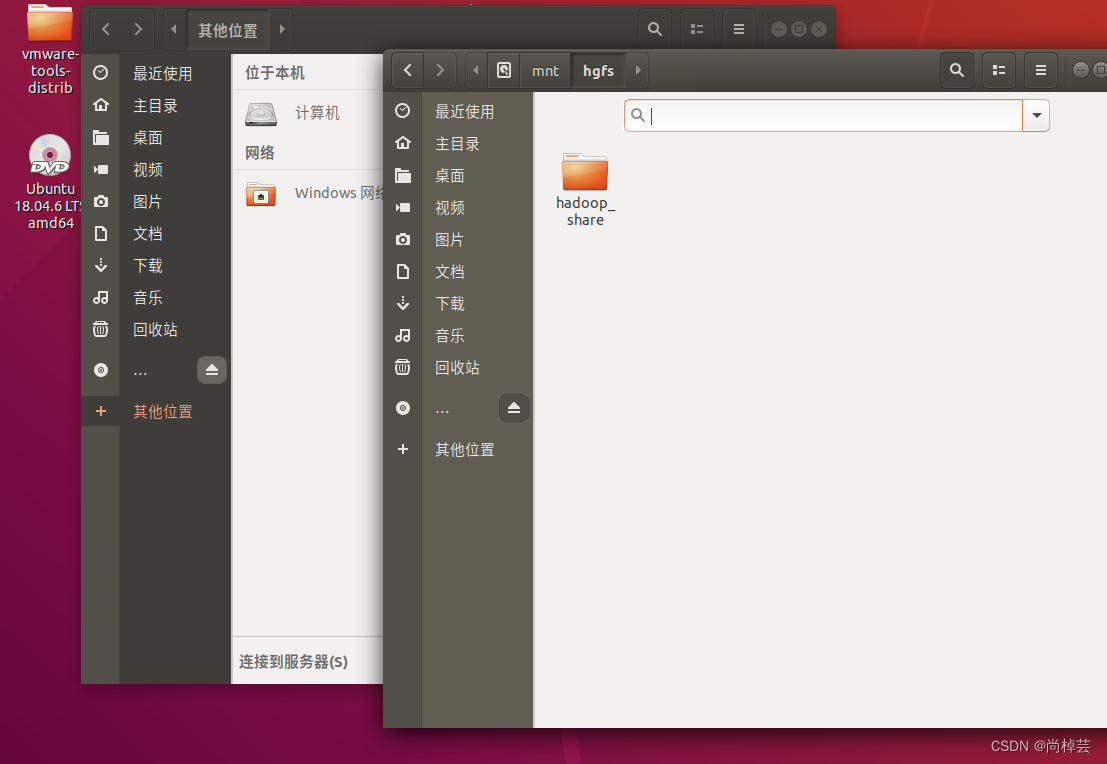
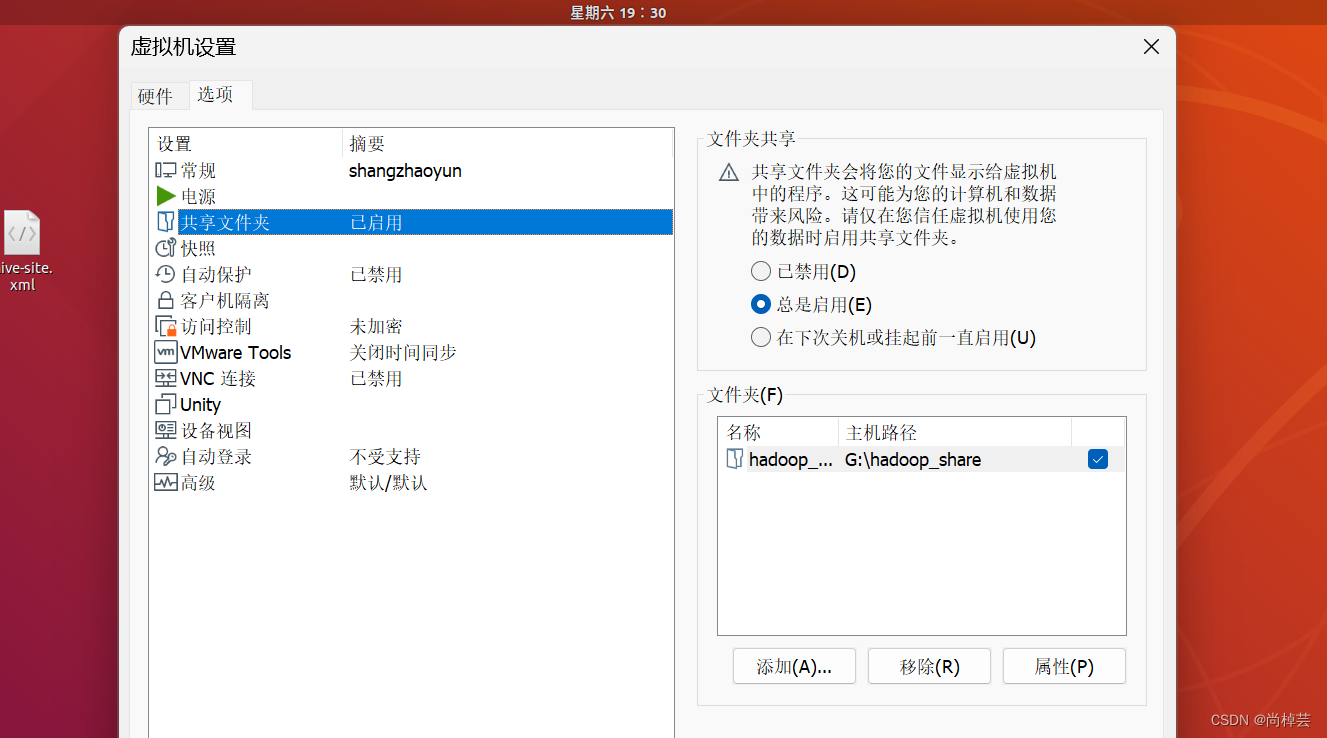
本人在安装完vmtools后有时能够拖动文件,又是拖不进去。就很神奇,当然也就是文件共享没有实现,有另一种方法:在虚拟机设置界面选中“选项”标签中的“共享文件夹”并进行设置,之后可以在ubuntu系统中,点开文件夹,中找到master>mnt>hgfs查看共享的文件。
2. Hadoop 伪分布式集群安装与配置
2.2.1 创建用户hadoop
(1)查看hadoop用户是否存在。
$ cat /etc/passwd |grep hadoop
(2)如果用户hadoop不存在,则创建用户haop,继续执行步骤(3).如果用户hadoop存在,则执行步骤(4)。
(3)创建用户hadoop,并设置密码为hadoop.
$ sudo useradd -m hadoop -s/bin/bash
设置用户hadoop的密码为hadoop (注意:密码不回显);
$ sudo passwd hadoop
(4)将用户hadoop添加到sudo组中,为用户授权。
$ sudo adduser hadoop sudo
2.2.2修改 主机名与域名映射
(1)修改虚拟机主机名称为master.
编辑/etc/hostname文件,写入虚拟机主机名称“master":
$ sudo gedit /etc/hostname
(2)将虚拟机的IP地址与主机名称写入/etc/hosts中,完成域名映射的添加。
$ sudo gedit /etc/hosts
在文件末尾添加一行下列信息:
192.168.189.128 master
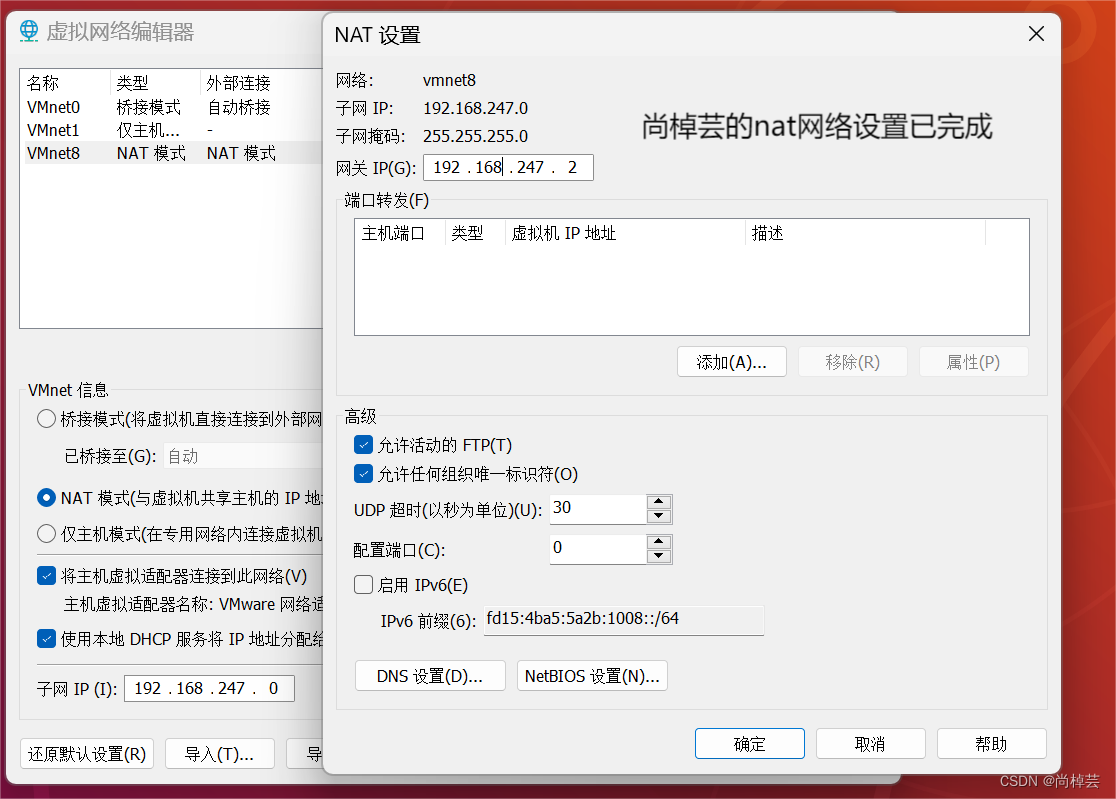
其中,192.168.247.0 为虚拟机IP地址,master 为主机名称。修改完后,保存文件。虚拟机ip地址在哪看?
在编辑>虚拟网络编辑器 可查看。
(3)重新启动虚拟机,以用户hadoop登录系统。
$ sudo reboot
2.3 SSH免密登录设置
为了实现Hadoop集群节点之间的SsH免密码登录,需要进行SSH免密码登录设(1)在虚拟机上安装SSH。
执行下列命令安装SSH:
$ sudo ap-get update
$ sudo apt-get install openssh-server
(2)在虚拟机上生成公钥和私钥。
$ ssh-keygen -t rsa
执行过程一路回车就行了。
执行完成后,在~/目录下(/home/hadoop) 自动创建目录.ssh,内部包含id_rsa(私钥)id_ rsa.pub (公钥)两个文件。
(3)将虚拟机的公钥发送到要登录节点的.ssh/authorized keys文件中。
$ cd ~/.ssh
$ ssh-copy-id -i id_rsa.pub hadoop@master
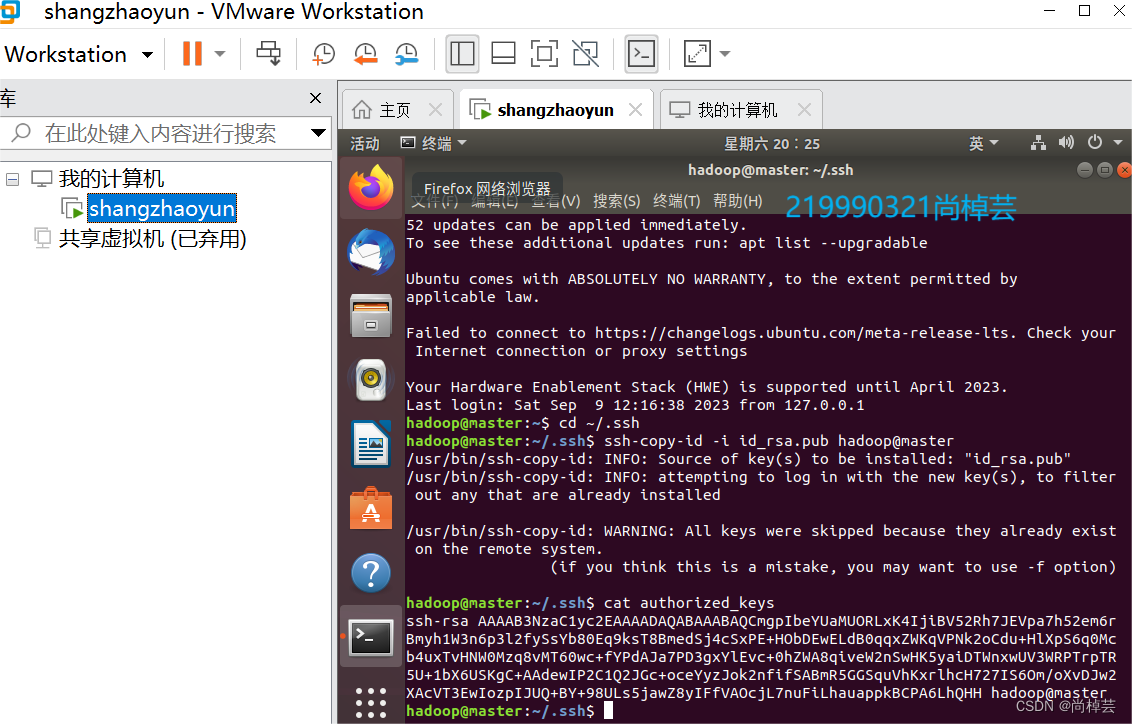
查看 ~./.ssh/authorized_keys 文件:
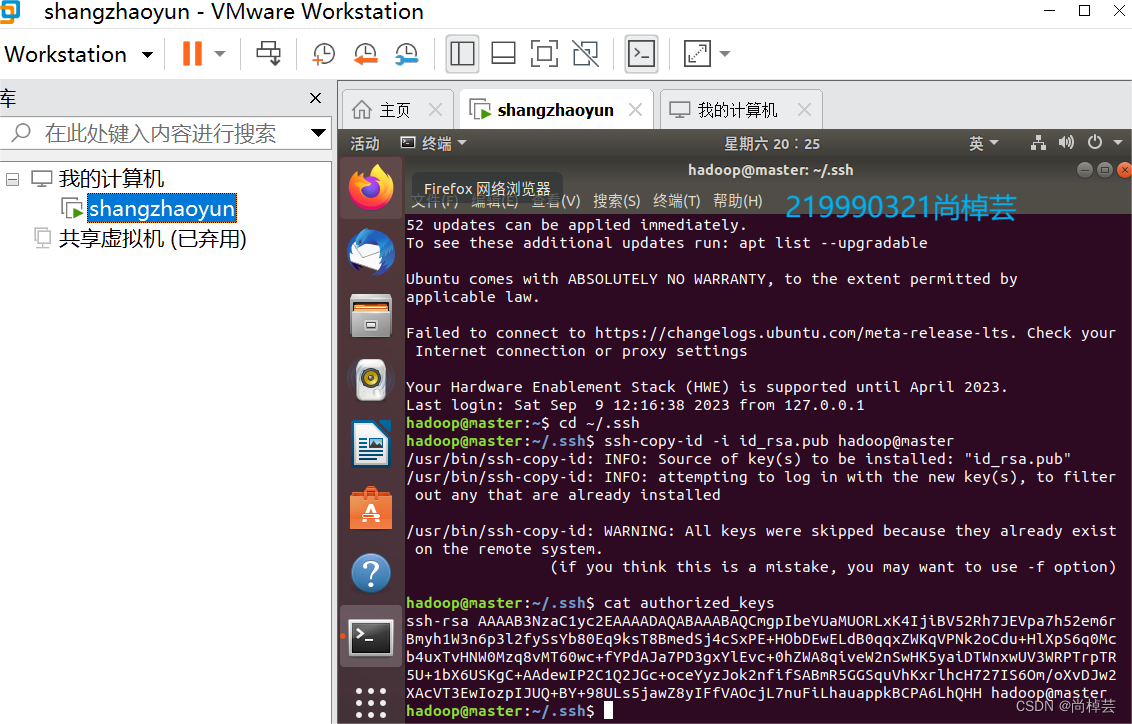
(4)测试SSH免密登录: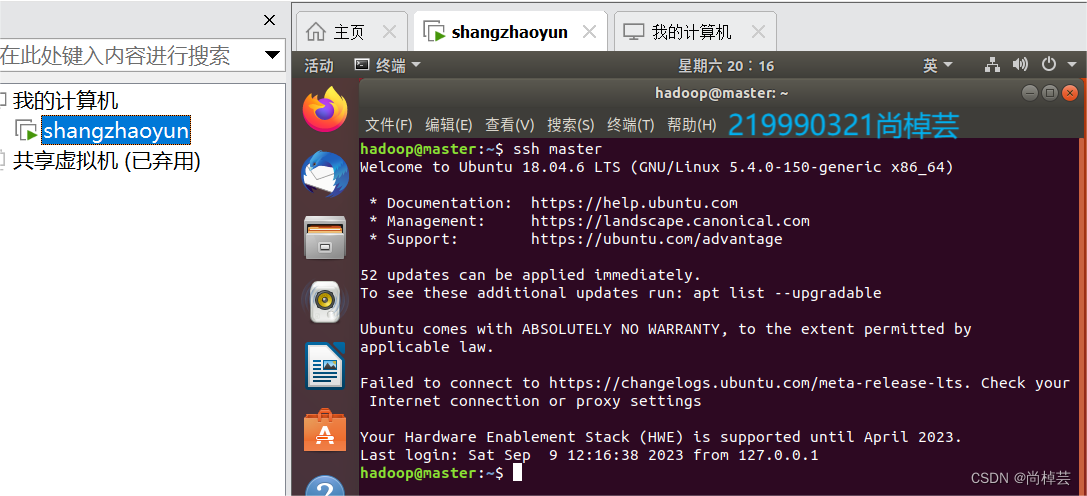
2.4 安装JAVA环境
(1)创建jvm目录,并改名。
$ sudo mkdir /usr/lib/jvm/
$ sudo chown-R hadoop /usr/lib/jvm
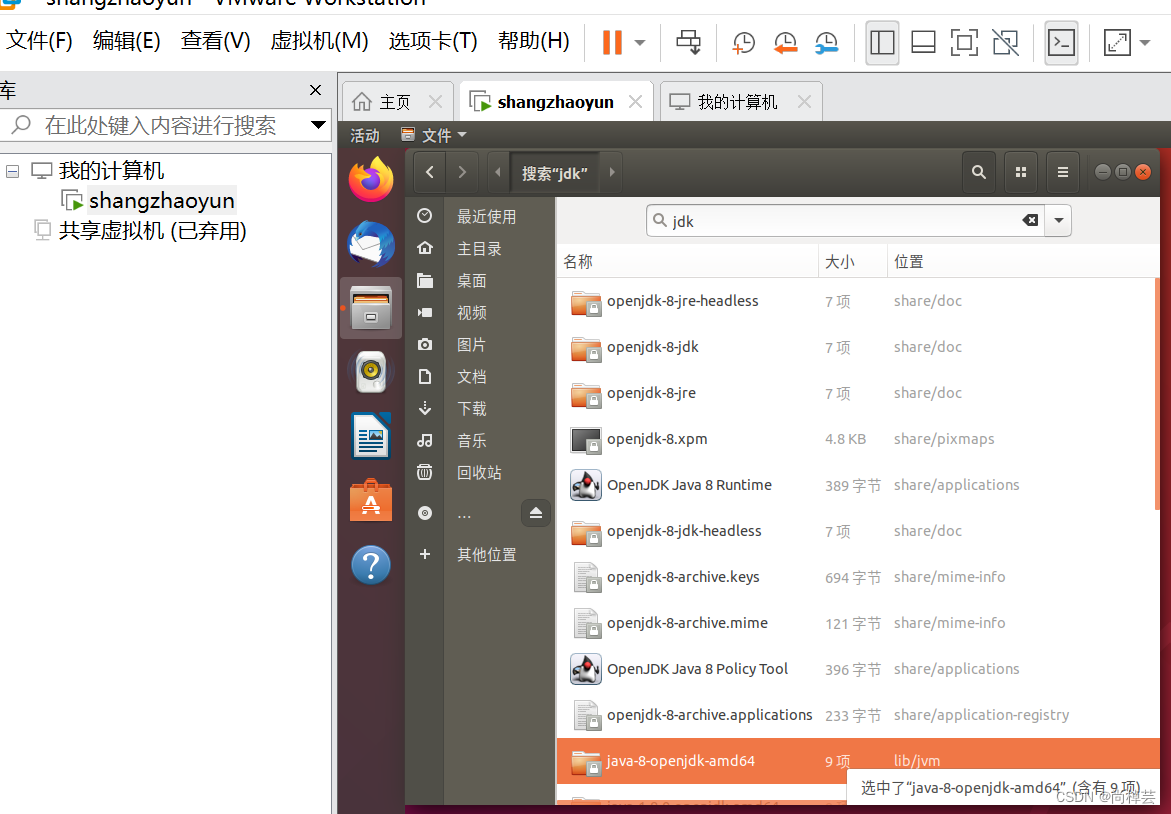
(2)书上给的是解压安装的步骤,但是为什么不能直接在虚拟机里直接下载JDK8安装呢?
虚拟机中打开终端
$ sudo apt-get install openjdk-8-jre openjdk-8-jdk
(3)配置环境变量,并生效。
$ gedit ~./bashrc
(4)配置bashrc文件,注意,在后面伪分布式集群配置的时候还要编辑该文件
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-amd64
export JRE_HOME=$JAVA_HOME/jre
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
export CLASSPATH=$CLASSPATH:.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export HADOOP_HOME=/usr/local/hadoop
export PATH=$HADOOP_HONE/bin:$HADOOP_HOME/sbin:$PATH
export HBASE_HOME=/usr/local/hbase
export PATH=$PATH:$HBASE_HOME/bin
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin
(5)使环境生效:
$ source ~/.bashrc
(6)验证是否成功:
注意要两种方法去验证
$ java -version
$ javac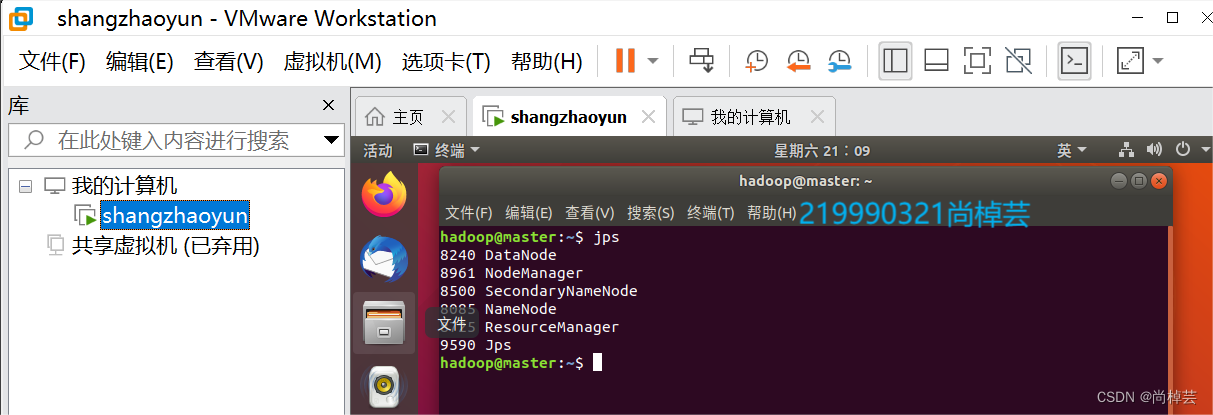
2.5伪分布式集群安装与配置
(1)使用tar命令解压安装hadoo-3.1.2.tar.gz文件到目录/usr/local中,并将文件夹重命名F hadoop.
$ cd ~/下载 #进入源文件hadoop-3.1.2.tar.gz所在目录
sudo tar -zxvfhadoo 3.1.2.tar.gz-C /usr/local ##j解压文件
$ cd /usr/local
$ sudo mv hadoop-3.1.2 hadoop #为简化操作, 将文件夹重命名为hadoop
(2)将目录/usr/local/hadoop的所有者修改为用户hadoop。
$ sudo chown -R hadoop /usr/local/hadoop
(3)配置环境变量,并使其生效。
①使用gedit命令打开用户的配置文件.bashrc。如果前面你copy我的,就不用打开了
$ gedit ~/.bashrc
②在文件中加入下列内容:
export HADOOP_HOME=/usr/local/hadoop
export PATH=$HADOOP_HONE/bin:$HADOOP_HOME/sbin:$PATH
❸使环境变量生效。
$ source ~/.bashrc
(4)配置Hadoop文件。
①配置hadoop-env.sh 文件。
用gedit 命令打开hadop-env.sh文件:
$ gedit /usr/local/hadoop/etc/hadoop/hadoop-env.sh
将第37行代码“# JAVA HME” (那一行)修改为. export JAVA_HOME=/usr/lib/jvm/最后一个是我图中选中的这个
②配置core-site.xml文件。
用gedit命令打开core-site.xml文件:
在< configuration>和</ configuration>标记之间写入下列内容:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other
temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
配置hdfs-site.xml文件
$ gedit /usr/local/hadoop/etc/hadoop/core-site.xml
在 < configuration>和</ configuration> 标记之间写入下列内容:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
(5)格式化。
$ hdfs namenode -format
(6)重新格式化
$ stop-all.sh
$ cd /usr/local/hadoop
$ rm -r dfs/ logs/ tmp/
$ hdfs namenode -format
$ start-all.sh
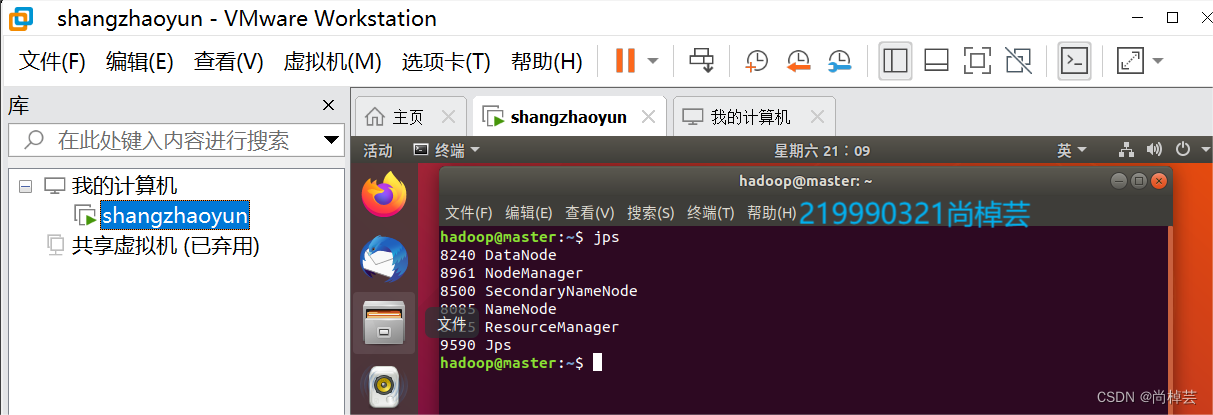
(6)检查:
1.$ jps
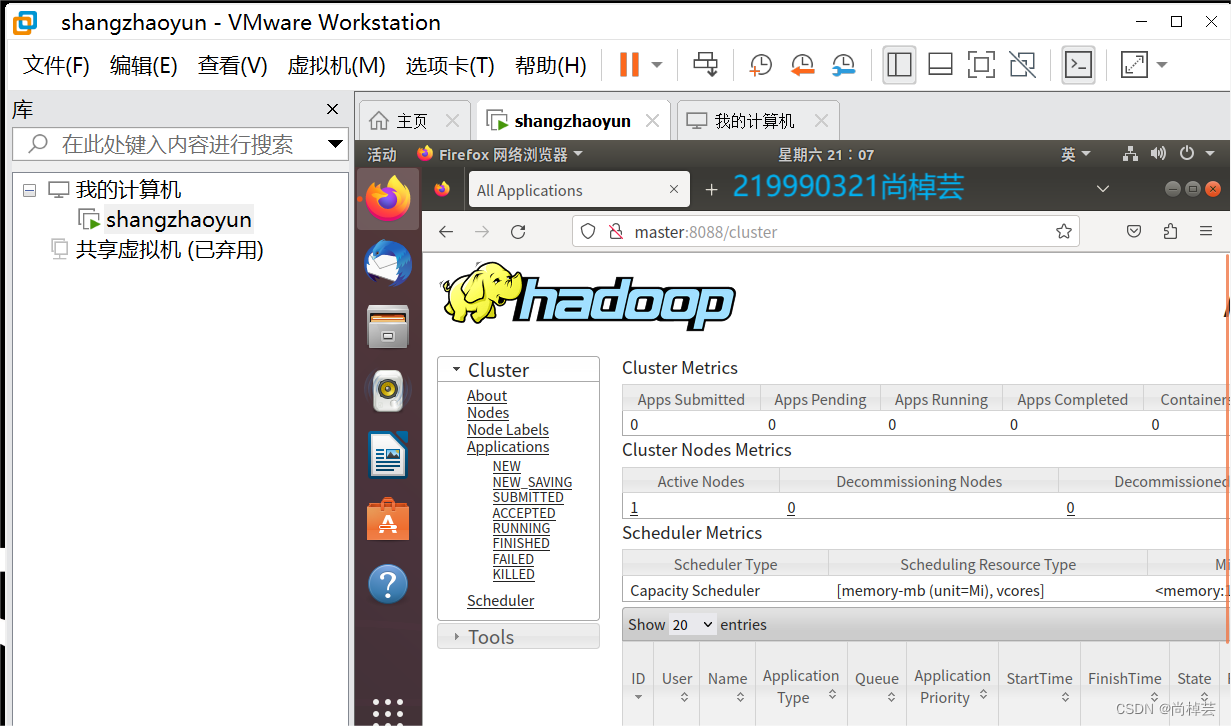
2.浏览器打开8088端口
3.浏览器打开9870端口

3. 总结
各位可以CV,我不介意。
风景照片是一位姓马的高中筒靴(如玉一样的女孩)给的。
3.1 家乡的风景:
3.2 一群牛

3.3 白沙湾

3.4 学习?
学个P!

















 1163
1163











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











