







文章目录
常见数据结构
常见的数据结构包括数组、链表、栈、队列、哈希表、树、堆、图,它们可以从“逻辑结构”和“物理结构”两个维度进行分类。
逻辑结构可被分为“线性”和“非线性”两大类。线性结构比较直观,指数据在逻辑关系上呈线性排列;非线性结构则相反,呈非线性排列。
- 线性数据结构:数组、链表、栈、队列、哈希表。
- 非线性数据结构:树、堆、图、哈希表。
非线性数据结构可以进一步被划分为树形结构和网状结构。
- 线性结构:数组、链表、队列、栈、哈希表,元素之间是一对一的顺序关系。
- 树形结构:树、堆、哈希表,元素之间是一对多的关系。
- 网状结构:图,元素之间是多对多的关系。
物理结构反映了数据在计算机内存中的存储方式,可分为连续空间存储(数组)和离散空间存储(链表)。物理结构从底层决定了数据的访问、更新、增删等操作方法,同时在时间效率和空间效率方面呈现出互补的特点。
所有数据结构都是基于数组、链表或二者的组合实现的。例如,栈和队列既可以使用数组实现,也可以使用链表实现;而哈希表的实现可能同时包含数组和链表。
- 基于数组可实现:栈、队列、哈希表、树、堆、图、矩阵、张量(维度 ≥3 的数组)等。
- 基于链表可实现:栈、队列、哈希表、树、堆、图等。
基于数组实现的数据结构也被称为“静态数据结构”,这意味着此类数据结构在初始化后长度不可变。相对应地,基于链表实现的数据结构被称为“动态数据结构”,这类数据结构在初始化后,仍可以在程序运行过程中对其长度进行调整。
数组
数组是一种线性数据结构,其将相同类型元素存储在连续的内存空间中。我们将元素在数组中的位置称为该元素的索引。
初始化
Python:
# 初始化数组
arr: list[int] = [0] * 5 # [ 0, 0, 0, 0, 0 ]
nums: list[int] = [1, 3, 2, 5, 4]
Go:
/* 初始化数组 */
var arr [5]int
// 在 Go 中,指定长度时([5]int)为数组,不指定长度时([]int)为切片
// 由于 Go 的数组被设计为在编译期确定长度,因此只能使用常量来指定长度
// 为了方便实现扩容 extend() 方法,以下将切片(Slice)看作数组(Array)
nums := []int{1, 3, 2, 5, 4}
访问元素
数组元素被存储在连续的内存空间中,这意味着计算数组元素的内存地址非常容易。给定数组内存地址(即首元素内存地址)和某个元素的索引,我们可以使用下图所示的公式计算得到该元素的内存地址,从而直接访问此元素。

我们发现数组首个元素的索引为 0 ,这似乎有些反直觉,因为从 1 开始计数会更自然。但从地址计算公式的角度看,索引的含义本质上是内存地址的偏移量。首个元素的地址偏移量是 0 ,因此它的索引为 0 也是合理的。
在数组中访问元素是非常高效的,我们可以在 O(1) 时间内随机访问数组中的任意一个元素。
Python:
def random_access(nums: list[int]) -> int:
"""随机访问元素"""
# 在区间 [0, len(nums)-1] 中随机抽取一个数字
random_index = random.randint(0, len(nums) - 1)
# 获取并返回随机元素
random_num = nums[random_index]
return random_num
Go:
/* 随机访问元素 */
func randomAccess(nums []int) (randomNum int) {
// 在区间 [0, nums.length) 中随机抽取一个数字
randomIndex := rand.Intn(len(nums))
// 获取并返回随机元素
randomNum = nums[randomIndex]
return
}
插入元素
数组元素在内存中是“紧挨着的”,它们之间没有空间再存放任何数据。如下图所示,如果想要在数组中间插入一个元素,则需要将该元素之后的所有元素都向后移动一位,之后再把元素赋值给该索引。
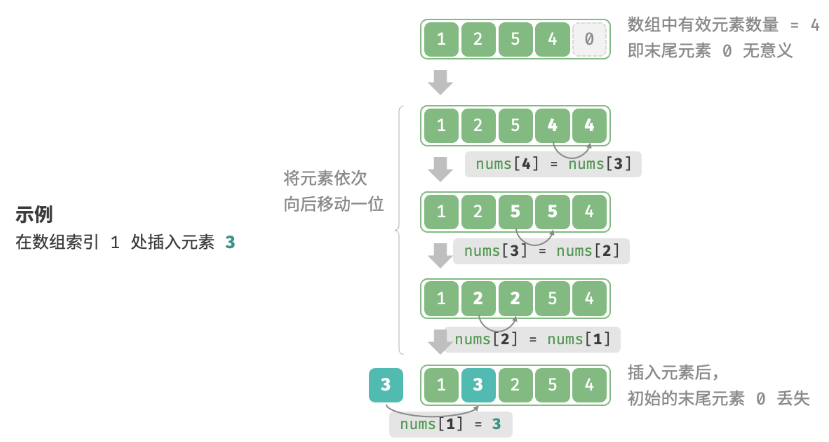
由于数组的长度是固定的,因此插入一个元素必定会导致数组尾部元素的“丢失”。
Python:
def insert(nums: list[int], num: int, index: int):
"""在数组的索引 index 处插入元素 num"""
# 把索引 index 以及之后的所有元素向后移动一位
for i in range(len(nums) - 1, index, -1):
nums[i] = nums[i - 1]
# 将 num 赋给 index 处元素
nums[index] = num
Go:
/* 在数组的索引 index 处插入元素 num */
func insert(nums []int, num int, index int) {
// 把索引 index 以及之后的所有元素向后移动一位
for i := len(nums) - 1; i > index; i-- {
nums[i] = nums[i-1]
}
// 将 num 赋给 index 处元素
nums[index] = num
}
删除元素
若想要删除索引i处的元素,则需要把索引i之后的元素都向前移动一位。
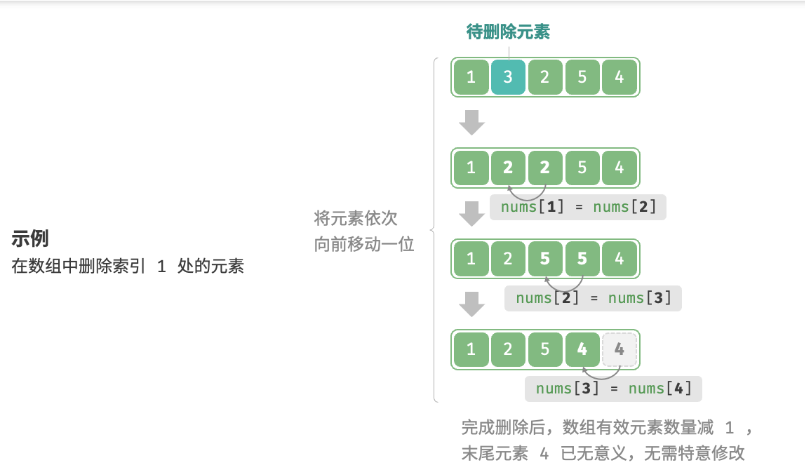
Python:
def remove(nums: list[int], index: int):
"""删除索引 index 处元素"""
# 把索引 index 之后的所有元素向前移动一位
for i in range(index, len(nums) - 1):
nums[i] = nums[i + 1]
Go:
/* 删除索引 index 处元素 */
func remove(nums []int, index int) {
// 把索引 index 之后的所有元素向前移动一位
for i := index; i < len(nums)-1; i++ {
nums[i] = nums[i+1]
}
}
总的来看,数组的插入与删除操作有以下缺点。
- 时间复杂度高:数组的插入和删除的平均时间复杂度均为O(n) ,其中 n为数组长度。
- 丢失元素:由于数组的长度不可变,因此在插入元素后,超出数组长度范围的元素会丢失。
- 内存浪费:我们可以初始化一个比较长的数组,只用前面一部分,这样在插入数据时,丢失的末尾元素都是“无意义”的,但这样做也会造成部分内存空间的浪费。
遍历数组
我们既可以通过索引遍历数组,也可以直接遍历获取数组中的每个元素。
Python:
def traverse(nums: list[int]):
"""遍历数组"""
count = 0
# 通过索引遍历数组
for i in range(len(nums)):
count += 1
# 直接遍历数组
for num in nums:
count += 1
# 同时遍历数据索引和元素
for i, num in enumerate(nums):
count += 1
Go:
/* 遍历数组 */
func traverse(nums []int) {
count := 0
// 通过索引遍历数组
for i := 0; i < len(nums); i++ {
count++
}
count = 0
// 直接遍历数组
for range nums {
count++
}
}
查找元素
在数组中查找指定元素需要遍历数组,每轮判断元素值是否匹配,若匹配则输出对应索引。因为数组是线性数据结构,所以上述查找操作被称为“线性查找”。
Python:
def find(nums: list[int], target: int) -> int:
"""在数组中查找指定元素"""
for i in range(len(nums)):
if nums[i] == target:
return i
return -1
Go:
/* 在数组中查找指定元素 */
func find(nums []int, target int) (index int) {
index = -1
for i := 0; i < len(nums); i++ {
if nums[i] == target {
index = i
break
}
}
return
}
扩容数组
在大多数编程语言中,数组的长度是不可变的。如果我们希望扩容数组,则需重新建立一个更大的数组,然后把原数组元素依次拷贝到新数组。这是一个O(n) 的操作,在数组很大的情况下是非常耗时的。
Python:
def extend(nums: list[int], enlarge: int) -> list[int]:
"""扩展数组长度"""
# 初始化一个扩展长度后的数组
res = [0] * (len(nums) + enlarge)
# 将原数组中的所有元素复制到新数组
for i in range(len(nums)):
res[i] = nums[i]
# 返回扩展后的新数组
return res
Go:
/* 扩展数组长度 */
func extend(nums []int, enlarge int) []int {
// 初始化一个扩展长度后的数组
res := make([]int, len(nums)+enlarge)
// 将原数组中的所有元素复制到新数组
for i, num := range nums {
res[i] = num
}
// 返回扩展后的新数组
return res
}
关于数组
数组存储在连续的内存空间内,且元素类型相同。这种做法包含丰富的先验信息,系统可以利用这些信息来优化数据结构的操作效率。
- 空间效率高: 数组为数据分配了连续的内存块,无须额外的结构开销。
- 支持随机访问: 数组允许在O(1) 时间内访问任何元素。
- 缓存局部性: 当访问数组元素时,计算机不仅会加载它,还会缓存其周围的其他数据,从而借助高速缓存来提升后续操作的执行速度。
连续空间存储是一把双刃剑,其存在以下缺点。
- 插入与删除效率低:当数组中元素较多时,插入与删除操作需要移动大量的元素。
- 长度不可变: 数组在初始化后长度就固定了,扩容数组需要将所有数据复制到新数组,开销很大。
- 空间浪费: 如果数组分配的大小超过了实际所需,那么多余的空间就被浪费了。
数组是一种基础且常见的数据结构,既频繁应用在各类算法之中,也可用于实现各种复杂数据结构。
- 随机访问:如果我们想要随机抽取一些样本,那么可以用数组存储,并生成一个随机序列,根据索引实现样本的随机抽取。
- 排序和搜索:数组是排序和搜索算法最常用的数据结构。快速排序、归并排序、二分查找等都主要在数组上进行。
- 查找表:当我们需要快速查找一个元素或者需要查找一个元素的对应关系时,可以使用数组作为查找表。假如我们想要实现字符到 ASCII 码的映射,则可以将字符的 ASCII 码值作为索引,对应的元素存放在数组中的对应位置。
- 机器学习:神经网络中大量使用了向量、矩阵、张量之间的线性代数运算,这些数据都是以数组的形式构建的。数组是神经网络编程中最常使用的数据结构。
- 数据结构实现:数组可以用于实现栈、队列、哈希表、堆、图等数据结构。例如,图的邻接矩阵表示实际上是一个二维数组。
链表
链表是一种线性数据结构,其中的每个元素都是一个节点对象,各个节点通过“引用”相连接。引用记录了下一个节点的内存地址,通过它可以从当前节点访问到下一个节点。链表的设计使得各个节点可以被分散存储在内存各处,它们的内存地址是无须连续的。
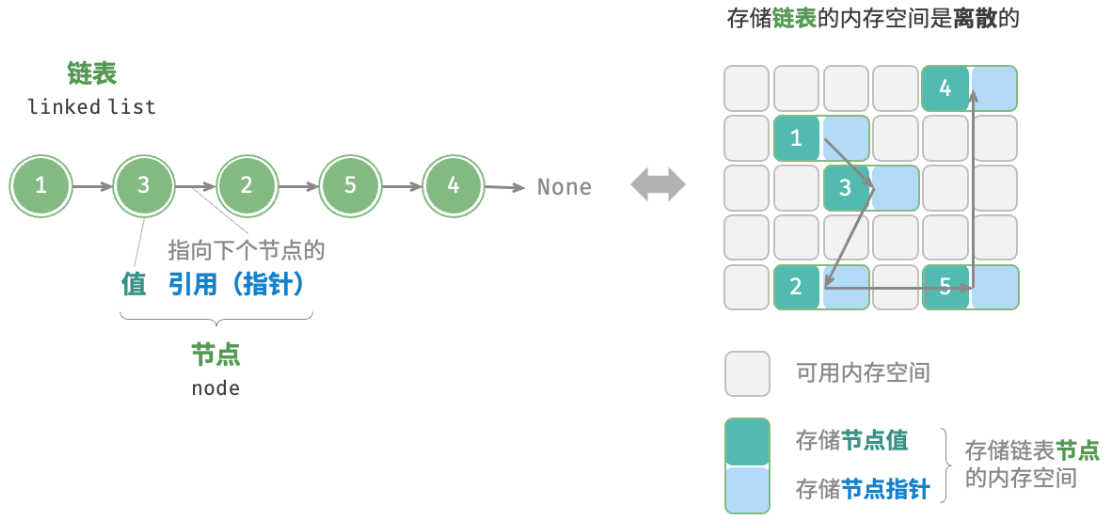
链表的组成单位是节点对象。每个节点都包含两项数据:节点的“值”和指向下一节点的“引用”。
- 链表的首个节点被称为“头节点”,最后一个节点被称为“尾节点”。
- 尾节点指向的是“空”,它在 Java、C++ 和 Python 中分别被记为 null、nullptr 和 None 。
- 在 C、C++、Go 和 Rust 等支持指针的语言中,上述的“引用”应被替换为“指针”。
链表节点 ListNode 除了包含值,还需额外保存一个引用(指针)。因此在相同数据量下,链表比数组占用更多的内存空间。
Python:
class ListNode:
"""链表节点类"""
def __init__(self, val: int):
self.val: int = val # 节点值
self.next: Optional[ListNode] = None # 指向下一节点的引用
Go:
/* 链表节点结构体 */
type ListNode struct {
Val int // 节点值
Next *ListNode // 指向下一节点的指针
}
// NewListNode 构造函数,创建一个新的链表
func NewListNode(val int) *ListNode {
return &ListNode{
Val: val,
Next: nil,
}
}
初始化
建立链表分为两步,第一步是初始化各个节点对象,第二步是构建引用指向关系。初始化完成后,我们就可以从链表的头节点出发,通过引用指向 next 依次访问所有节点。
Python:
# 初始化链表 1 -> 3 -> 2 -> 5 -> 4
# 初始化各个节点
n0 = ListNode(1)
n1 = ListNode(3)
n2 = ListNode(2)
n3 = ListNode(5)
n4 = ListNode(4)
# 构建引用指向
n0.next = n1
n1.next = n2
n2.next = n3
n3.next = n4
Go:
/* 初始化链表 1 -> 3 -> 2 -> 5 -> 4 */
// 初始化各个节点
n0 := NewListNode(1)
n1 := NewListNode(3)
n2 := NewListNode(2)
n3 := NewListNode(5)
n4 := NewListNode(4)
// 构建引用指向
n0.Next = n1
n1.Next = n2
n2.Next = n3
n3.Next = n4
数组整体是一个变量,比如数组 nums 包含元素 nums[0] 和 nums[1] 等,而链表是由多个独立的节点对象组成的。我们通常将头节点当作链表的代称,比如以上代码中的链表可被记做链表 n0 。
插入节点
在链表中插入节点非常容易。如下图所示,假设我们想在相邻的两个节点 n0 和 n1 之间插入一个新节点 P ,则只需要改变两个节点引用(指针)即可,时间复杂度为 O(1) 。
相比之下,在数组中插入元素的时间复杂度为 O(n) ,在大数据量下的效率较低。
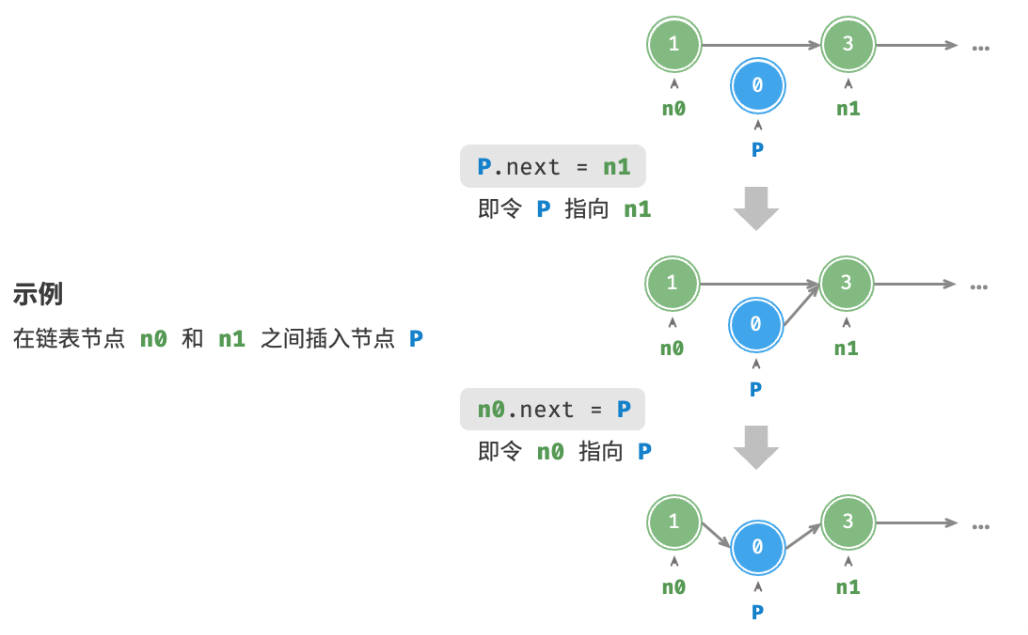
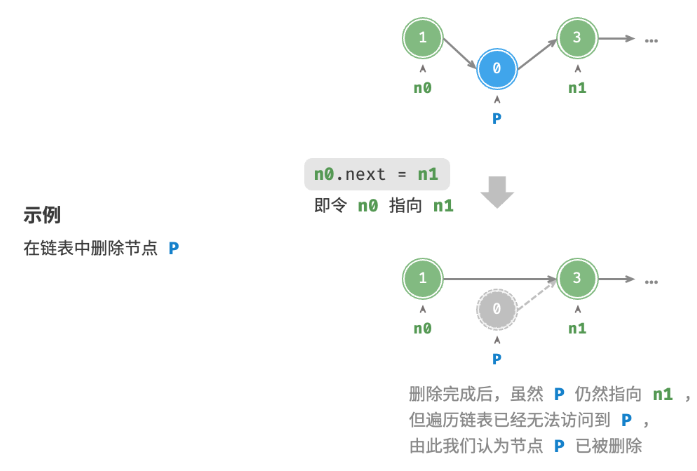
删除节点
在链表中删除节点也非常方便,只需改变一个节点的引用(指针)即可。
请注意,尽管在删除操作完成后节点 P 仍然指向 n1 ,但实际上遍历此链表已经无法访问到 P ,这意味着 P 已经不再属于该链表了。
Python:
def remove(n0: ListNode):
"""删除链表的节点 n0 之后的首个节点"""
if not n0.next:
return
# n0 -> P -> n1
P = n0.next
n1 = P.next
n0.next = n1
Go:
/* 删除链表的节点 n0 之后的首个节点 */
func removeNode(n0 *ListNode) {
if n0.Next == nil {
return
}
// n0 -> P -> n1
P := n0.Next
n1 := P.Next
n0.Next = n1
}
访问节点
在链表访问节点的效率较低。如上节所述,我们可以在O(1) 时间下访问数组中的任意元素。链表则不然,程序需要从头节点出发,逐个向后遍历,直至找到目标节点。也就是说,访问链表的第i个节点需要循环i−1 轮,时间复杂度为O(n) 。
Python:
def access(head: ListNode, index: int) -> ListNode | None:
"""访问链表中索引为 index 的节点"""
for _ in range(index):
if not head:
return None
head = head.next
return head
Go:
/* 访问链表中索引为 index 的节点 */
func access(head *ListNode, index int) *ListNode {
for i := 0; i < index; i++ {
if head == nil {
return nil
}
head = head.Next
}
return head
}
查找节点
遍历链表,查找链表内值为 target 的节点,输出节点在链表中的索引。此过程也属于线性查找。
Python:
def find(head: ListNode, target: int) -> int:
"""在链表中查找值为 target 的首个节点"""
index = 0
while head:
if head.val == target:
return index
head = head.next
index += 1
return -1
Go:
/* 在链表中查找值为 target 的首个节点 */
func findNode(head *ListNode, target int) int {
index := 0
for head != nil {
if head.Val == target {
return index
}
head = head.Next
index++
}
return -1
}
常见类型
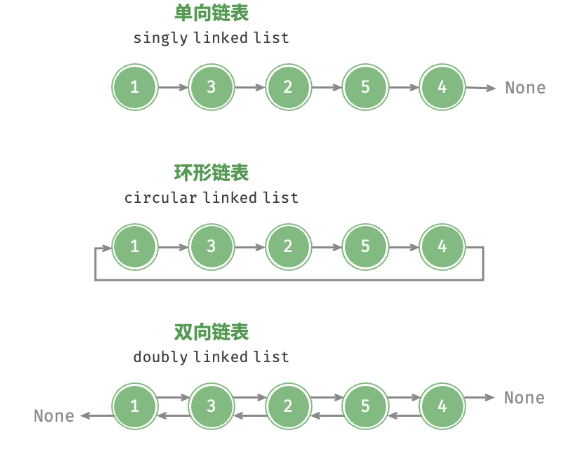
- 单向链表:即上述介绍的普通链表。单向链表的节点包含值和指向下一节点的引用两项数据。我们将首个节点称为头节点,将最后一个节点称为尾节点,尾节点指向空 None 。
- 环形链表:如果我们令单向链表的尾节点指向头节点(即首尾相接),则得到一个环形链表。在环形链表中,任意节点都可以视作头节点。
- 双向链表:与单向链表相比,双向链表记录了两个方向的引用。双向链表的节点定义同时包含指向后继节点(下一个节点)和前驱节点(上一个节点)的引用(指针)。相较于单向链表,双向链表更具灵活性,可以朝两个方向遍历链表,但相应地也需要占用更多的内存空间。
Python:
class ListNode:
"""双向链表节点类"""
def __init__(self, val: int):
self.val: int = val # 节点值
self.next: Optional[ListNode] = None # 指向后继节点的引用
self.prev: Optional[ListNode] = None # 指向前驱节点的引用
Go:
/* 双向链表节点结构体 */
type DoublyListNode struct {
Val int // 节点值
Next *DoublyListNode // 指向后继节点的指针
Prev *DoublyListNode // 指向前驱节点的指针
}
// NewDoublyListNode 初始化
func NewDoublyListNode(val int) *DoublyListNode {
return &DoublyListNode{
Val: val,
Next: nil,
Prev: nil,
}
}
典型应用
单向链表通常用于实现栈、队列、哈希表和图等数据结构。
- 栈与队列:当插入和删除操作都在链表的一端进行时,它表现出先进后出的的特性,对应栈;当插入操作在链表的一端进行,删除操作在链表的另一端进行,它表现出先进先出的特性,对应队列。
- 哈希表:链地址法是解决哈希冲突的主流方案之一,在该方案中,所有冲突的元素都会被放到一个链表中。
- 图:邻接表是表示图的一种常用方式,在其中,图的每个顶点都与一个链表相关联,链表中的每个元素都代表与该顶点相连的其他顶点。
双向链表常被用于需要快速查找前一个和下一个元素的场景。
- 高级数据结构:比如在红黑树、B 树中,我们需要访问节点的父节点,这可以通过在节点中保存一个指向父节点的引用来实现,类似于双向链表。
- 浏览器历史:在网页浏览器中,当用户点击前进或后退按钮时,浏览器需要知道用户访问过的前一个和后一个网页。双向链表的特性使得这种操作变得简单。
- LRU 算法:在缓存淘汰算法(LRU)中,我们需要快速找到最近最少使用的数据,以及支持快速地添加和删除节点。这时候使用双向链表就非常合适。
循环链表常被用于需要周期性操作的场景,比如操作系统的资源调度。
- 时间片轮转调度算法:在操作系统中,时间片轮转调度算法是一种常见的 CPU 调度算法,它需要对一组进程进行循环。每个进程被赋予一个时间片,当时间片用完时,CPU 将切换到下一个进程。这种循环的操作就可以通过循环链表来实现。
- 数据缓冲区:在某些数据缓冲区的实现中,也可能会使用到循环链表。比如在音频、视频播放器中,数据流可能会被分成多个缓冲块并放入一个循环链表,以便实现无缝播放。
数组VS链表
| 数组 | 链表 | |
|---|---|---|
| 存储方式 | 连续内存空间 | 离散内存空间 |
| 缓存局部性 | 友好 | 不友好 |
| 容量扩展 | 长度不可变 | 可灵活扩展 |
| 内存效率 | 占用内存少、浪费部分空间 | 占用内存多 |
| 访问元素 | 通过索引直接访问,O(1) | 需要遍历查找,O(n) |
| 添加元素 | 需要移动元素,O(n) | 直接插入节点,O(1) |
| 删除元素 | 需要移动元素,O(n) | 直接删除节点,O(1) |
数组相对于链表,缓存局部性更友好的原因是数组在实现上使用的是连续的内存空间,可以借助CPU的缓存机制,预读数组中的数据,所以访问效率越高。这是因为操作系统的局部性原理的存在,数组的连续存储空间的特性充分使用了局部性原理,也就是说硬件的高速缓存加速了数组的访问,而链表离散存储的特性注定它不能更快。
列表
数组长度不可变导致实用性降低。为解决此问题,出现了一种被称为动态数组的数据结构,即长度可变的数组,也常被称为列表。
初始化
Python:
# 初始化列表
# 无初始值
list1: list[int] = []
# 有初始值
list: list[int] = [1, 3, 2, 5, 4]
Go:
/* 初始化列表 */
// 无初始值
list1 := []int
// 有初始值
list := []int{1, 3, 2, 5, 4}
访问元素
列表本质上是数组,因此可以在O(1) 时间内访问和更新元素,效率很高。
Python:
# 访问元素
num: int = list[1] # 访问索引 1 处的元素
# 更新元素
list[1] = 0 # 将索引 1 处的元素更新为 0
Go:
/* 访问元素 */
num := list[1] // 访问索引 1 处的元素
/* 更新元素 */
list[1] = 0 // 将索引 1 处的元素更新为 0
插入与删除元素
相较于数组,列表可以自由地添加与删除元素。在列表尾部添加元素的时间复杂度为O(1) ,但插入和删除元素的效率仍与数组相同,时间复杂度为 O(n) 。
Python:
# 清空列表
list.clear()
# 尾部添加元素
list.append(1)
list.append(3)
list.append(2)
list.append(5)
list.append(4)
# 中间插入元素
list.insert(3, 6) # 在索引 3 处插入数字 6
# 删除元素
list.pop(3) # 删除索引 3 处的元素
Go:
/* 清空列表 */
list = nil
/* 尾部添加元素 */
list = append(list, 1)
list = append(list, 3)
list = append(list, 2)
list = append(list, 5)
list = append(list, 4)
/* 中间插入元素 */
list = append(list[:3], append([]int{6}, list[3:]...)...) // 在索引 3 处插入数字 6
/* 删除元素 */
list = append(list[:3], list[4:]...) // 删除索引 3 处的元素
遍历列表
Python:
# 通过索引遍历列表
count = 0
for i in range(len(list)):
count += 1
# 直接遍历列表元素
count = 0
for n in list:
count += 1
Go:
/* 通过索引遍历列表 */
count := 0
for i := 0; i < len(list); i++ {
count++
}
/* 直接遍历列表元素 */
count = 0
for range list {
count++
}
拼接列表
给定一个新列表 list1 ,我们可以将该列表拼接到原列表的尾部。
Python:
# 拼接两个列表
list1: list[int] = [6, 8, 7, 10, 9]
list += list1 # 将列表 list1 拼接到 list 之后
Go:
/* 拼接两个列表 */
list1 := []int{6, 8, 7, 10, 9}
list = append(list, list1...) // 将列表 list1 拼接到 list 之后
排序列表
Python:
# 排序列表
list.sort() # 排序后,列表元素从小到大排列
Go:
/* 排序列表 */
sort.Ints(list) // 排序后,列表元素从小到大排列
简单实现
为了加深对列表工作原理的理解,下面尝试实现一个简易版列表,包括以下三个重点设计。
- 初始容量:选取一个合理的数组初始容量。在本示例中,我们选择 10 作为初始容量。
- 数量记录:声明一个变量 size,用于记录列表当前元素数量,并随着元素插入和删除实时更新。根据此变量,我们可以定位列表尾部,以及判断是否需要扩容。
- 扩容机制:若插入元素时列表容量已满,则需要进行扩容。首先根据扩容倍数创建一个更大的数组,再将当前数组的所有元素依次移动至新数组。在本示例中,我们规定每次将数组扩容至之前的 2 倍。
Python:
class MyList:
"""列表类简易实现"""
def __init__(self):
"""构造方法"""
self.__capacity: int = 10 # 列表容量
self.__nums: list[int] = [0] * self.__capacity # 数组(存储列表元素)
self.__size: int = 0 # 列表长度(即当前元素数量)
self.__extend_ratio: int = 2 # 每次列表扩容的倍数
def size(self) -> int:
"""获取列表长度(即当前元素数量)"""
return self.__size
def capacity(self) -> int:
"""获取列表容量"""
return self.__capacity
def get(self, index: int) -> int:
"""访问元素"""
# 索引如果越界则抛出异常,下同
if index < 0 or index >= self.__size:
raise IndexError("索引越界")
return self.__nums[index]
def set(self, num: int, index: int):
"""更新元素"""
if index < 0 or index >= self.__size:
raise IndexError("索引越界")
self.__nums[index] = num
def add(self, num: int):
"""尾部添加元素"""
# 元素数量超出容量时,触发扩容机制
if self.size() == self.capacity():
self.extend_capacity()
self.__nums[self.__size] = num
self.__size += 1
def insert(self, num: int, index: int):
"""中间插入元素"""
if index < 0 or index >= self.__size:
raise IndexError("索引越界")
# 元素数量超出容量时,触发扩容机制
if self.__size == self.capacity():
self.extend_capacity()
# 将索引 index 以及之后的元素都向后移动一位
for j in range(self.__size - 1, index - 1, -1):
self.__nums[j + 1] = self.__nums[j]
self.__nums[index] = num
# 更新元素数量
self.__size += 1
def remove(self, index: int) -> int:
"""删除元素"""
if index < 0 or index >= self.__size:
raise IndexError("索引越界")
num = self.__nums[index]
# 索引 i 之后的元素都向前移动一位
for j in range(index, self.__size - 1):
self.__nums[j] = self.__nums[j + 1]
# 更新元素数量
self.__size -= 1
# 返回被删除元素
return num
def extend_capacity(self):
"""列表扩容"""
# 新建一个长度为原数组 __extend_ratio 倍的新数组,并将原数组拷贝到新数组
self.__nums = self.__nums + [0] * self.capacity() * (self.__extend_ratio - 1)
# 更新列表容量
self.__capacity = len(self.__nums)
def to_array(self) -> list[int]:
"""返回有效长度的列表"""
return self.__nums[: self.__size]
Go:
/* 列表类简易实现 */
type myList struct {
numsCapacity int
nums []int
numsSize int
extendRatio int
}
/* 构造函数 */
func newMyList() *myList {
return &myList{
numsCapacity: 10, // 列表容量
nums: make([]int, 10), // 数组(存储列表元素)
numsSize: 0, // 列表长度(即当前元素数量)
extendRatio: 2, // 每次列表扩容的倍数
}
}
/* 获取列表长度(即当前元素数量) */
func (l *myList) size() int {
return l.numsSize
}
/* 获取列表容量 */
func (l *myList) capacity() int {
return l.numsCapacity
}
/* 访问元素 */
func (l *myList) get(index int) int {
// 索引如果越界则抛出异常,下同
if index < 0 || index >= l.numsSize {
panic("索引越界")
}
return l.nums[index]
}
/* 更新元素 */
func (l *myList) set(num, index int) {
if index < 0 || index >= l.numsSize {
panic("索引越界")
}
l.nums[index] = num
}
/* 尾部添加元素 */
func (l *myList) add(num int) {
// 元素数量超出容量时,触发扩容机制
if l.numsSize == l.numsCapacity {
l.extendCapacity()
}
l.nums[l.numsSize] = num
// 更新元素数量
l.numsSize++
}
/* 中间插入元素 */
func (l *myList) insert(num, index int) {
if index < 0 || index >= l.numsSize {
panic("索引越界")
}
// 元素数量超出容量时,触发扩容机制
if l.numsSize == l.numsCapacity {
l.extendCapacity()
}
// 将索引 index 以及之后的元素都向后移动一位
for j := l.numsSize - 1; j >= index; j-- {
l.nums[j+1] = l.nums[j]
}
l.nums[index] = num
// 更新元素数量
l.numsSize++
}
/* 删除元素 */
func (l *myList) remove(index int) int {
if index < 0 || index >= l.numsSize {
panic("索引越界")
}
num := l.nums[index]
// 索引 i 之后的元素都向前移动一位
for j := index; j < l.numsSize-1; j++ {
l.nums[j] = l.nums[j+1]
}
// 更新元素数量
l.numsSize--
// 返回被删除元素
return num
}
/* 列表扩容 */
func (l *myList) extendCapacity() {
// 新建一个长度为原数组 extendRatio 倍的新数组,并将原数组拷贝到新数组
l.nums = append(l.nums, make([]int, l.numsCapacity*(l.extendRatio-1))...)
// 更新列表容量
l.numsCapacity = len(l.nums)
}
/* 返回有效长度的列表 */
func (l *myList) toArray() []int {
// 仅转换有效长度范围内的列表元素
return l.nums[:l.numsSize]
}
Refercences:https://www.hello-algo.com/chapter_array_and_linkedlist/
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











