






今天在开发过程中遇到一个问题,一个shell脚本文件报错。模拟一下现场大概是这样:
cd 目标目录
vi test2.sh显示脚本内容为
#!/bin/bash
echo '我是SJLoveIT'./test2.sh执行,结果报错了

一般这种就是换行符的问题了,file命令看下,没问题啊,是LF(unix)换行符
![]()
如果是CRLF(windows)换行符,后面会多一个“with CRLF line terminators”
![]()
还是不放心,用unix2dos和dos2unix转换再用file命令验证一下,的确是LF(unix)换行符。
编码也没问题,是UTF8。那咋回事呢?
从提示上可以看出下些端倪,肯定是跟#!/bin/bash这个有关。再复习下#!/bin/bash
可以知道这就是指定解释器的标识,表示要用/bin/bash这个解释器去执行此脚本。
但是这个#!/bin/bash标识只对./命令有用。也就是说,用./的方式执行脚本的时候,就会通过#!/bin/bash去识别出该用/bin/bash这个解释器。如果直接用sh命令执行呢,就已经显式指定解释器了,那这行就当做普通注释了。

你甚至可以用#!/bin/cat 放在第一行,然后./执行

执行的效果就跟直接 /bin/cat test3.sh 一样
回到正题,这个报错就出在第一行,用notepad看看呢
刚才file的时候没注意,现在发现问题了,怎么编码是UTF-8 BOM?
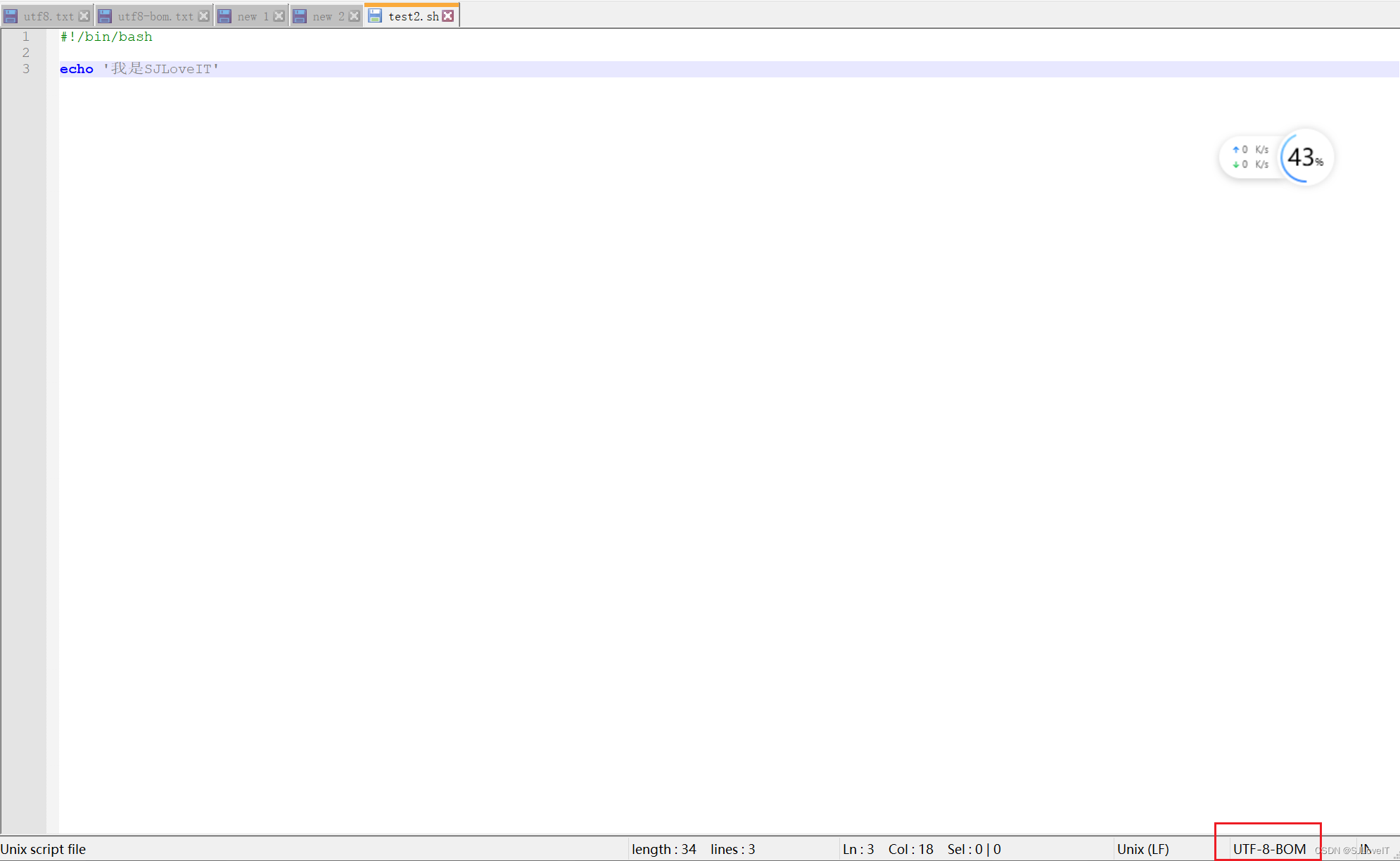
查阅资料可知,BOM是Byte Order Mark的缩写,是用来标记文件编码的大小端的(这个后面讲),UTF8是不需要标记大小端的。
在UCS 编码中有一个叫做 "Zero Width No-Break Space" ,中文译名作“零宽无间断间隔”的字符,它的编码是 FEFF。而 FFFE 在UCS中是不存在的字符,所以不应该出现在实际传输中。UCS 规范建议我们在传输字节流前,先传输字符 "Zero Width No-Break Space"。这样如果接收者收到 FEFF,就表明这个字节流是 Big-Endian 的;如果收到FFFE,就表明这个字节流是 Little- Endian 的。因此字符 "Zero Width No-Break Space" (“零宽无间断间隔”)又被称作 BOM。
UTF-8不需要 BOM 来表明字节顺序,但可以用 BOM 来表明编码方式。字符 "Zero Width No-Break Space" 的 UTF-8 编码是 EF BB BF。所以如果接收者收到以 EF BB BF 开头的字节流,就知道这是 UTF-8编码了。Windows 就是使用 BOM 来标记文本文件的编码方式的。
感觉还是没太明白,先简单理解就是(本文后面会再来研究这个问题),BOM这个标记是用来表示文件编码信息的。BOM这个东西,一般在windows平台用得比较多,但是linux中常常无法正确识别。一般而言utf8(不带bom)才是utf8的“正版”,而utf8-bom则相对用得比较少。
用notepad转成UTF8(不带BOM)的格式,再传到服务器上执行,果然就没问题了!!!至此问题已经定位并解决了,但是这个东西似乎还似懂非懂的,我们继续深挖!!
资料中说会以EF BB BF开头?是真的吗?
咱们用notepad的HEX-Edit看看二进制码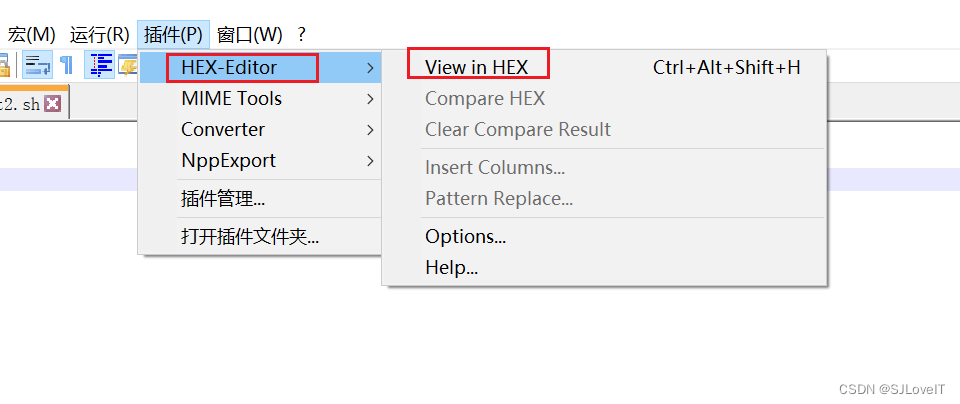
果然是这样!!!
新建空白文件,分别用utf8和utf8 bom编码,首先文件大小就不一样


utf8编码的只占0个字节,而utf8 bom编码的,虽然文本内容为空白,但已经占用了3个字节。用notepad看下,果然是你!

再看下编码,这个EF BB BF果然对应UNICODE的FEFF,也就是所谓的“Zero Width No-Break Space”字符。编码查询网站

不禁又想到一个问题,notepad等文本编辑器是怎么识别文件的编码的呢?
(1)检测文件头标识
(2)提示用户选择
(3)根据一定的规则猜测
最标准的途径是检测文本最开头的几个字节,开头字节 Charset/encoding,如下表:
如果开头两个字节是0xFFFE,那么就是Unicode,否则是ANSI。原文链接:https://blog.csdn.net/longcjx/article/details/6908299
再来看下所谓大端(Big-Endian)、小端(Little- Endian)的问题。UTF-8没有大小端的区别,为什么?这篇文章基本解释得很好了。
浅析——为什么UTF-16需要大端小端,而UTF-8不需要_utf16大端小端-CSDN博客
关于编码的基础知识,可参考
建议收藏,彻底搞懂字符编码问题,从此告别中文乱码
好了,到这里就差不多了,大家有问题可在评论区一起讨论。















 679
679

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









