






大作业:爬取微博评论文本并且分析文本的情感极性:pos or neg
外挂图片失败,请自行发挥想象!!!
2023.03.27更新:在构建模型的时候有个参数输错了,这会导致训练出来的网络准确率在65左右。更正已经push到GitHub仓库了,目前我训练的准确率能达到98%,loss损失函数的值小于0.1
设计背景
- 对微博评论数据进行文本情感分析,目前仅仅实现了对情感的正向或者负向的分析
系统思想
爬取评论数据
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7rHD0LNC-1669987829217)(C:\Users\moonchild\AppData\Roaming\Typora\typora-user-images\image-20221127142538470.png)]](https://i-blog.csdnimg.cn/blog_migrate/09c053cdec0261915d7571aff655de97.png)
以今天微博热搜榜上的话题:武汉全面推行场所码之中的一条微博为例,我们可以看到其中buildComment网络请求就包含我们所需的评论文本.具体请求表头及参数如下图:
回应数据是一个json格式文件,如下:

针对这个特点,我使用了如下代码来爬取微博评论数据:
URL = r'https://weibo.com/ajax/statuses/buildComments'
params = {
'flow':0,
'is_reload':1,
'id':ID, # 当前微博的ID
"is_show_bulletin":2,
'is_mix':0,
'count':50,
'uid':UID # 用户ID
}
temp = requests.get(url=URL,headers=headers,params=params)
temp = temp.json()
参数说明如下
"""
返回所有数据,注意或得到的json数据的格式:
ok:1,
filter_gorup:0/1, 分别是按热度排序和按时间排序
data:[], 数组,是所需要的评论数据,其中每一个又是一个json()格式数据,source可以获取到IP属地,text_raw是原始评论文本
rootComment,
total_number,
max_id: 下一条数据请求头之中的max_id
trendsText
"""
经过处理以后可以写入到了文本文件res.txt:
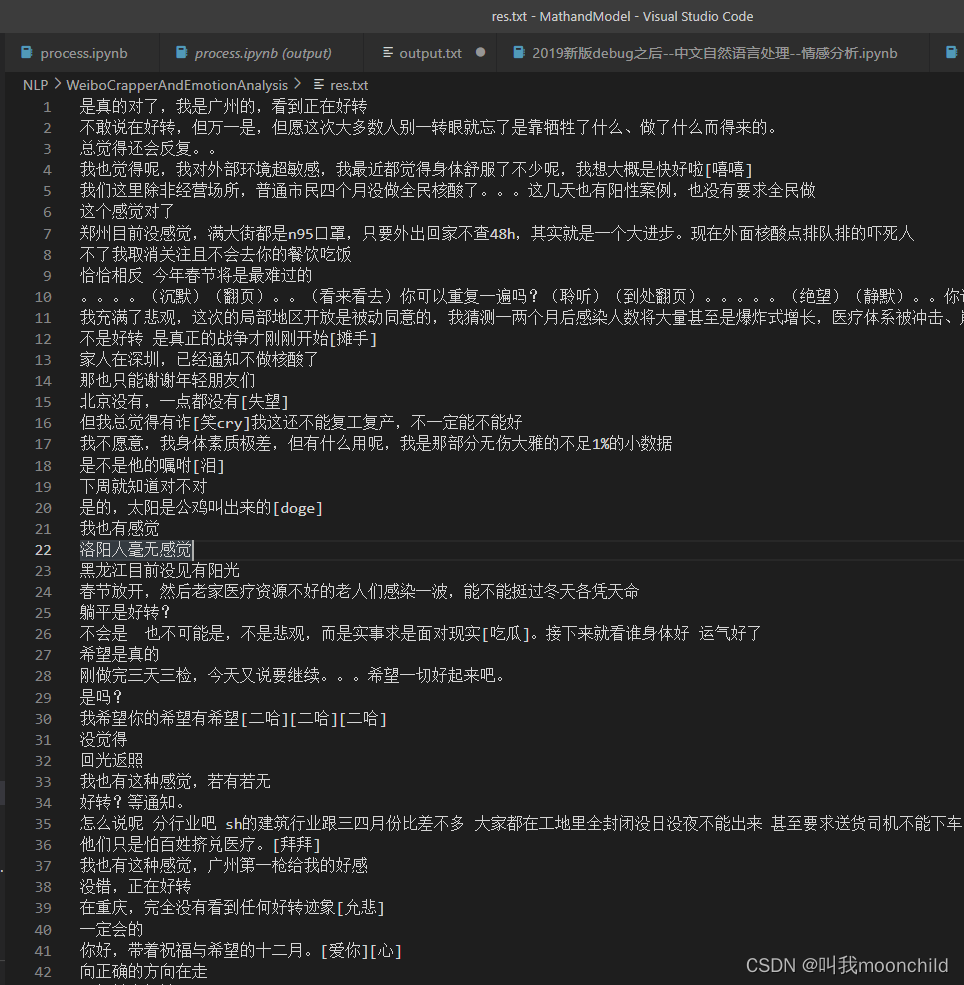
之后我生成了词云
wordcloud的生成
-
效果

-
生成词云的方法:主要是从
wordcloud库引入WordCloud方法.之后使用matplotlib展示并且保存照片即可
cloud = WordCloud(
width=2000,height=1600
, background_color="white"
, mode='RGB'
# , mask=backgroundImg
, max_words=2000
, max_font_size=200
, font_path=r'C:\Windows\Fonts\simkai.ttf' # 必须要添加中文字体地址,否则会生成方框
, relative_scaling=0.6
, random_state=50
# , scale=2
, stopwords=STOPWORDS.update(
['我', '了', '在', '和', '是', '作者', '中', '那', '也', '里', '没有', '着', '都', '但', '被', '到', '与', '使',
'很', '像', '说', '啊', '把', '又', '他', '之', 'w', 'W', '的', '你们', '你', '我们', '上', '而', '这',
'一个'])
).generate(wordList)
plt.imshow(cloud)
plt.axis("off")
plt.show()
文本情感模型的构建
-
本教程使用了北京师范大学中文信息处理研究所与中国人民大学 DBIIR 实验室的研究者开源的
chinese-word-vectors,GitHub地址 -
使用了GitHub上开源的微博评论语料库来训练模型:链接
-
主要步骤
- 导入主要使用的
gensim,jieba,tensorflow库 - 解压,并且使用
gensim来加载词向量模型 - 导入训练文本
- 导入训练语料,GitHub上开源的评论语料包括正面负面语料,共及12k
- 加载tensorflow的keras接口
- 分词,去掉所有的标点符号
- 统一训练文本的索引长度,这里使用了
np.mean()+2*np.std(),也就是使用了正态分布之中的平均长度+两个标准差长度作为标准长度,与理论模型一致,能够覆盖95%的文本 - 使用tensorflow提供的
pad_sequence()方法来统一化索引长度 - 使用sklearn分割训练数据和测试数据
- 创建模型,网络的主要结构如下:
- 导入主要使用的

a47a6c6b.png)
最后输出了dense_2层,(None,1),其中包含的数据便是文本的情感极性.
训练的结果如下:
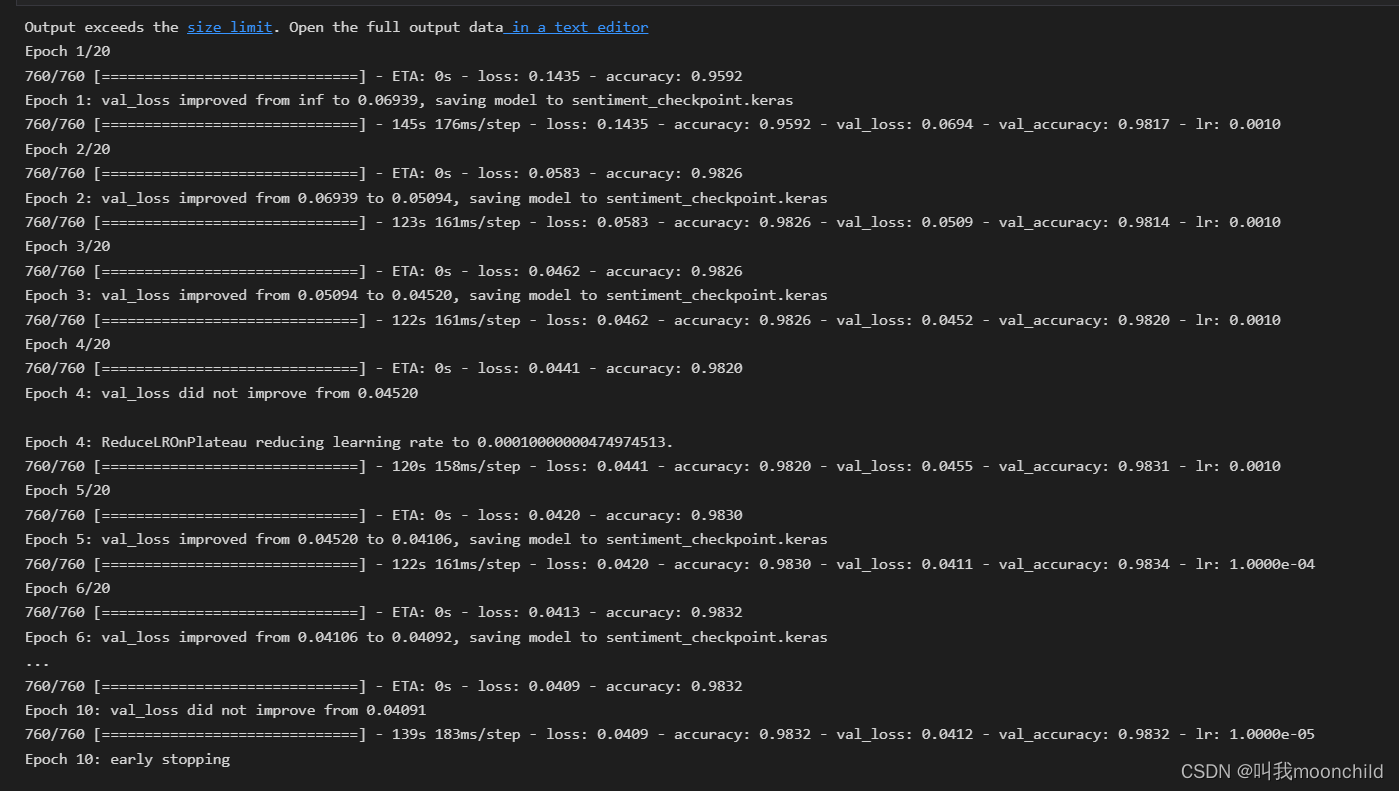
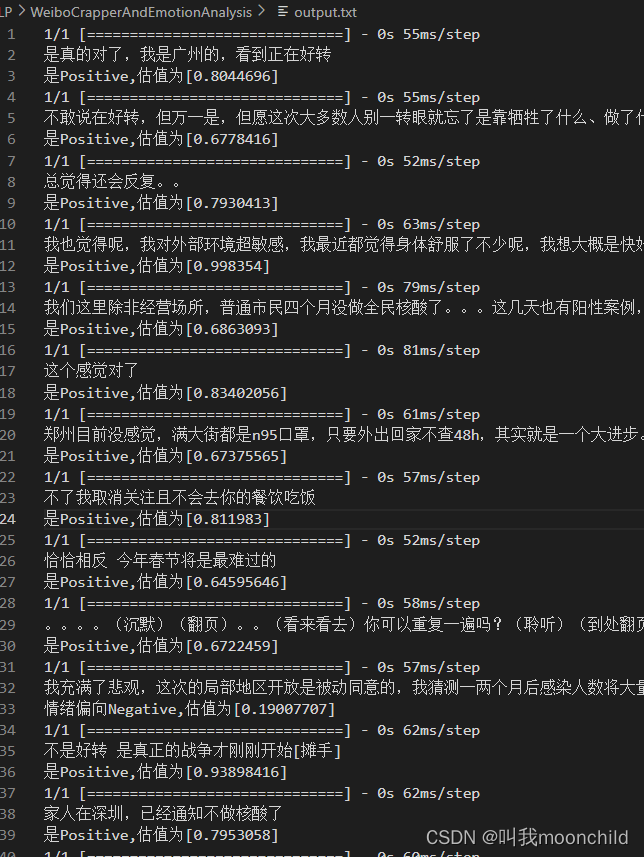
11. 最后输出的结果如下,我将其保存为了output.txt
> 1997 年 , Hochreiter 等[8] 提 出 了 长 短 期 记 忆(LSTM) 模型,用于解决循环神经网络 (RNN) 训练 时 的 梯 度 爆 炸 和 梯 度 消 失 问 题 , 使 得 RNN 能 真正 有 效 地 利 用 长 距 离 的 序 列 信 息 。 研 究 者 基 于LSTM 模 型 , 不 断 改 进 RNN 的 效 能 。 2014 年 , Su‐
> tskever 等[10] 提 出 了 多 层 LSTM 模 型 框 架 , 能 够 使 更高层次的 LSTM 模型捕捉到更长距离的信息;2015年,Li 等[11] 还提出了层次的 LSTM 模型,使用该模型分别处理词、句子和段落级别输入,并使用自动编码器 (auto encoder) 来检测文档特征抽取和重建
> 能力。
-
测试
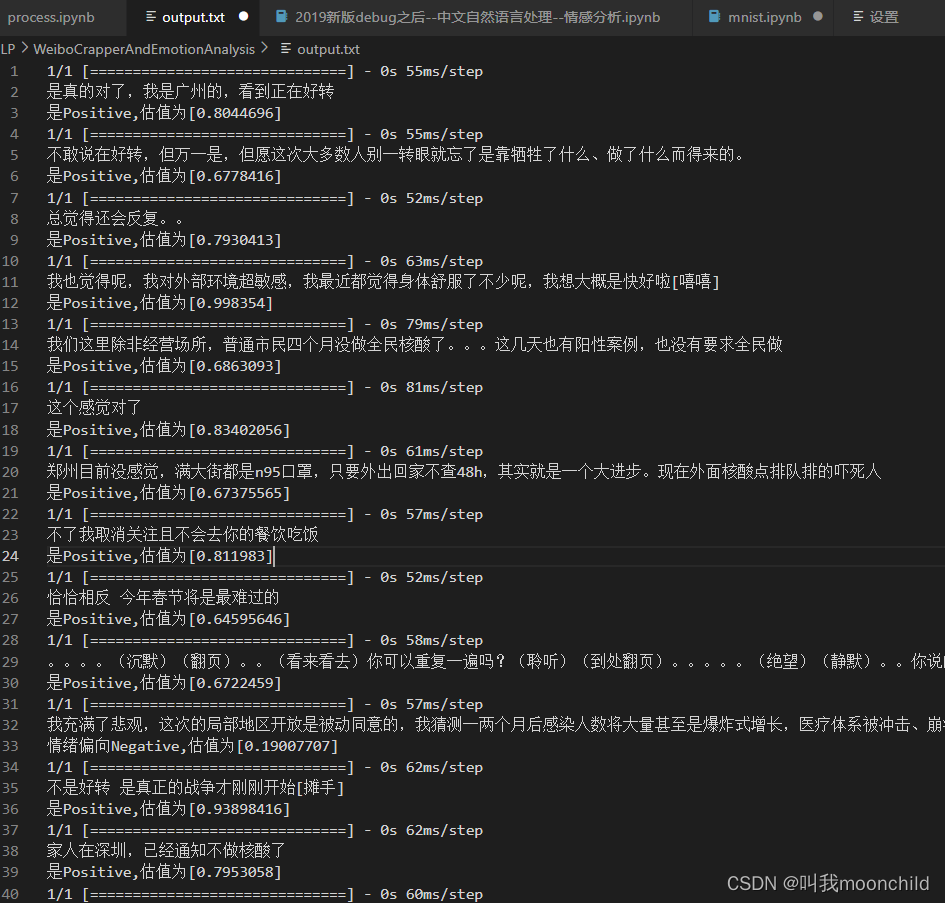
-
结果可视化:
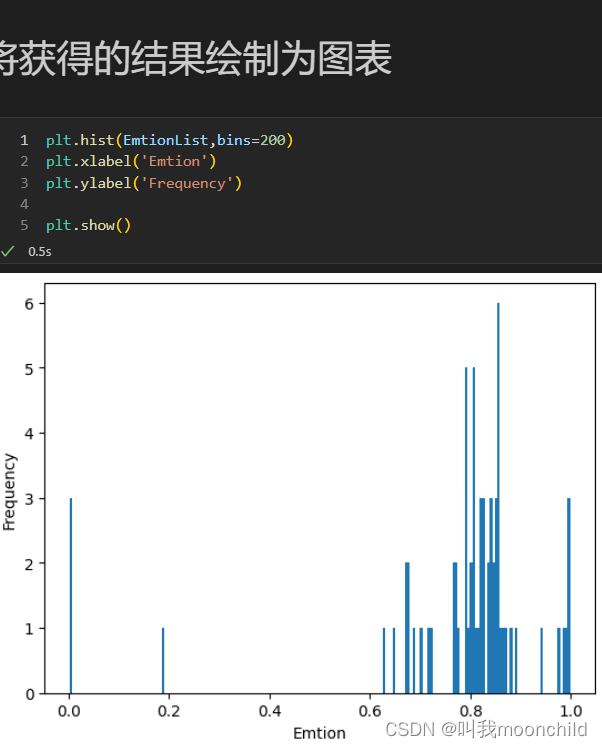
文件结构
本次作业主要包含以下文件:
- Crapper.py —用于爬取数据
- Cloud.py —用于生成词云
- process.ipynb —-jupternotebook文件,主要的模型训练文件
依赖文件:
- weibo_senti_100k.csv —–微博评论语料
- sgns.zhihu.bigram sgns.zhihu.bigram.bz2 ——上文提到的中文词向量模型
生成文件:
- Cloud.jpg —–词云图片
- res.txt ——从微博爬取的评论
反思
本次仅仅是粗略的实现了一个LTSM模型,过程之中也参照了许多开源的代码,视频,论文, 深知仓促完成的一个作业与Google Scholar上那些文章有如云泥之别.与之相比还缺少实验数据的比照,测试,分析等等步骤.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









