







目录
一,排序的基本概念
(1).排序:
将一组数据元素序列重新排列,使得数据元素序列按某个数据项(关键字)有序。
排序依据:是依据数据元素的关键字。
若关键字是主关键字(关键字值不重复),这无论采用何种排序方法,排出的结果都是唯一的;
若关键字是次关键字(关键字值可以重复),则排出的结果可能不唯一。
一般情况下,
假设含n个记录的序列为{ R1, R2,...Rn}
其相应的关键字序列为{ K1, K2, ...Kn}
这些关键字相互之间可以进行比较,即在它们之间存在着这样一个关系:Kp1≤Kp2≤...≤Kpn
按此固有关系将上式记录序列重新排列为{Rp1,Rp2, ....,Rpn}的操作称作排序。
(2).稳定排序和不稳定排序
对于任意的数据元素序列,若排序前后所有相同关键字的相对位置都不变,则称该排序方法称为稳定的排序方法。
若存在一组数据序列,在排序前后,相同关键字的相对位置发生了变化,则称该排序方法称为不稳定的排序方法。
例如,对于关键字序列3,2, 3, 4,若某种排序方法排序后变为2,3,3,4,则该排序方法是不稳定的。
(3).内部排序和外部排序
若整个排序过程不需要访问外存便能完成,则称此类排序问题为内部排序;
反之,若参加排序的记录数量很大,整个序列的排序过程不可能在内存中完成,则称此类排序问题为外部排序。
(4).内部排序的方法
内部排序的过程是个逐步扩 大记录的有序序列长度的过程。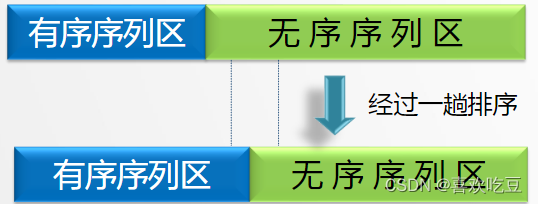
二,简单插入排序
基本思想:将无序子序列中的一个或几个记录"插入”到有序子序列中,从而增加有序子序列的长度。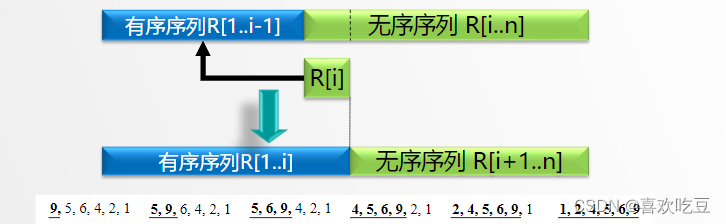

不同的定位方法导致不同的插入算法。
直接插入排序(基于顺序查找定位)
排序过程:整个排序过程为n- 1趟插入,即先将序列中第1个记录看成是一个有序子序列,然后从第2个记录开始,逐个进行插入,直至整个序列有序
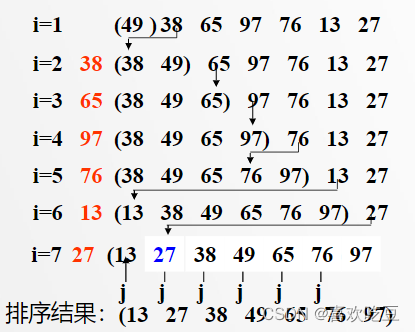
代码实现:
typedef struct
{ int key;//关键字
float info;//其他信息
}JD;
void straisort(D r[],int n)//对长度为n的序列排序
{ int ij;
for(i=2;i<=n;i++)
{ r[0]=r[i];
j=i-1;
while(r[0].key<r[jJ.key)
{ r[j+1]=r[j];
j-;
}
r[j+1]=r[0];
}
}
折半插入排序(基于折半查找定位)
希尔排序(基于逐趟缩小增量)

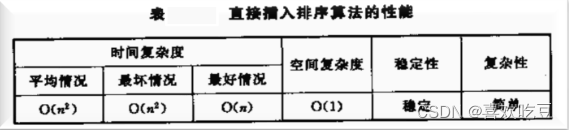
用直接插人排序,数据序列越接近有序,比较次数越少。
简单插入排序的本质?
比较和交换
序列中逆序的个数决定交换次数
平均逆序数量为C(n,2)/2 ,所以T(n)= 0(n2)
简单插入排序复杂度由什么决定? 逆序个数
如何改进简单插入排序复杂度?
●分组,比如C(n,2)/2> 2C((n/2),2)/2
●3,2,1有3组逆序对(3,1) (3,2) (2,1)需要交换3次。但相隔较远的
3,1交换一次后1,2,3就没有逆序对了。
●基本有序的插入排序算法复杂度接近O(n)
三,希尔排序(缩小增量法)
1,基本思想:
分割成若干个较小的子文件,对各个子文件分别进行直接插入排序,当文件达到基本有序时,再对整个文件进行一-次直接插入排序。
对待排记录序列先作“宏观”调整,再作“微观”调整。
"宏观"调整,指的是,"跳跃式”的插入排序。
2,排序过程:
首先将记录序列分成若干子序列,然后分别对每个子序列进行直接插入排序,最后待基本有序时,再进行一次直接插入排序
例如:将n个记录分成d个子序列:
{ R[1],R[1+d], R[1+2d], .. R[1+kd]}
{ R[2], R[2+d], R[2+2d], ... R[2+kd]}
{ R[d], R[2d], R[3d], .... R[kd], R[(k+1)d] }
其中,d称为增量,它的值在排序过程中从大到小逐渐缩小,直至最后一趟排序减
为1。
void shellsort(JD r[],int n,intd[],int T)
{ int i.j,k;
JD X;
k=0;
//循环每 一趟进行分组,组内进行简单插入排序
while(k<T)
{ for(i=d[k]+1;i<=n;i++)
//i为未排序记录的位置
{ x=r[i];
j=i-d[k]//j为本组i前面的记录位置
while((j>0)&&(x.key<r[j].key))
//组内简单插入排序
{ r[j+d[k]]=r[j];
j=jd[k];
}
r[j+d[k]]=x;
}
k++;
}
3,排序特点:
●子序列的构成不是简单的”逐段分割”,而是将相隔某个增量的记录组成一个子序列
●希尔排序可提高排序速度,因为分组后n值减小,n2更小,而T(n)=O(n2),所以T(n)从总体上看是减小了关键字较小的记录跳跃式前移,在进行最后一趟增量为1的插入排序时,序列已基本有序
●增量序列取法
无除1以外的公因子
最后一个增量值必须为1
希尔排序算法本身很简单,但复杂度分析很复杂.他适合于中等数据量大小的排序(成千上万的
数据量)
4,性能分析:

四,选择排序
1,基本思想:
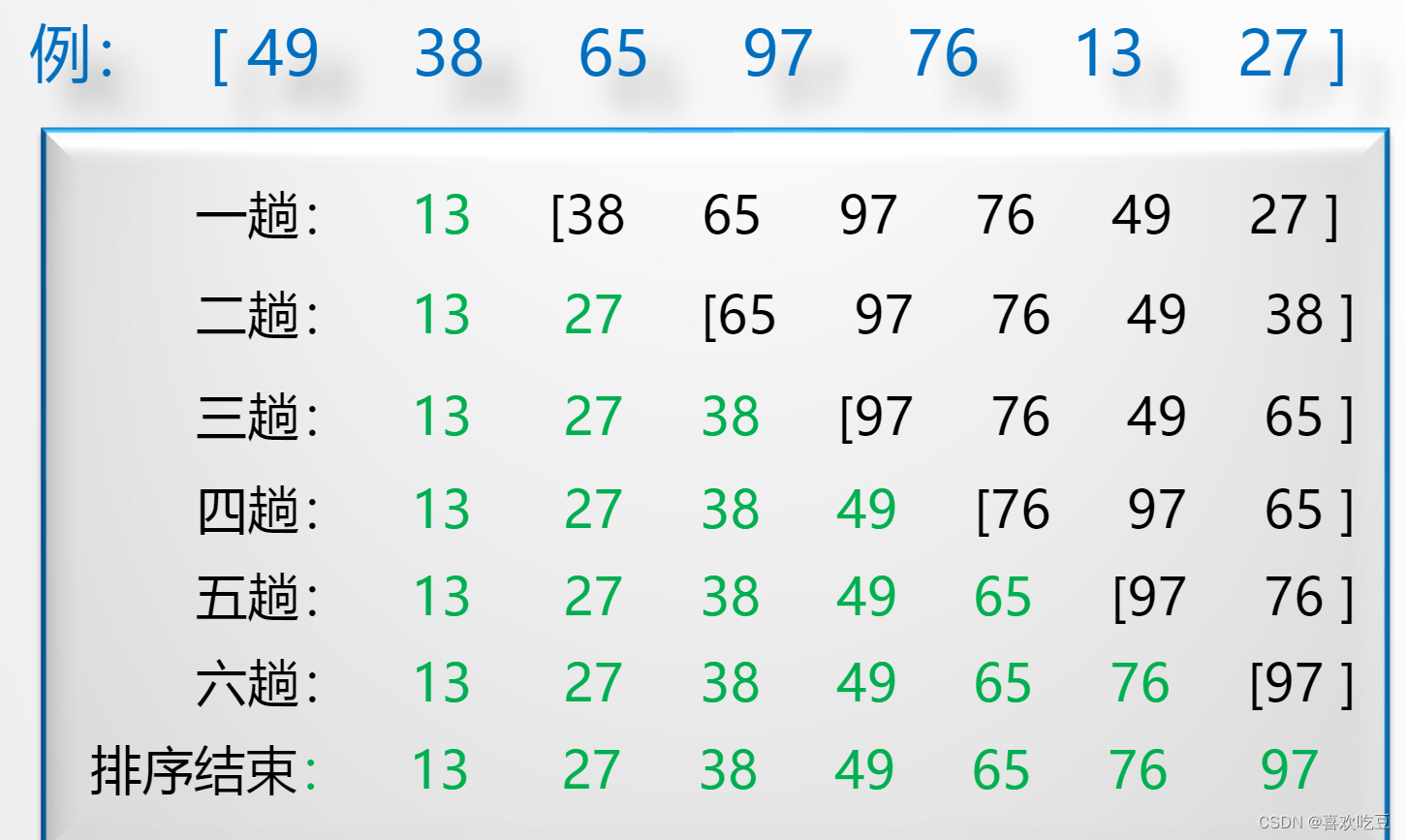
从无序子序列中“选择”关键字最小或最大的记录,并将它加入到有序子序列中,以此方法增加记录的有序子序列的长度。
假设排序过程中,待排记录序列的状态为: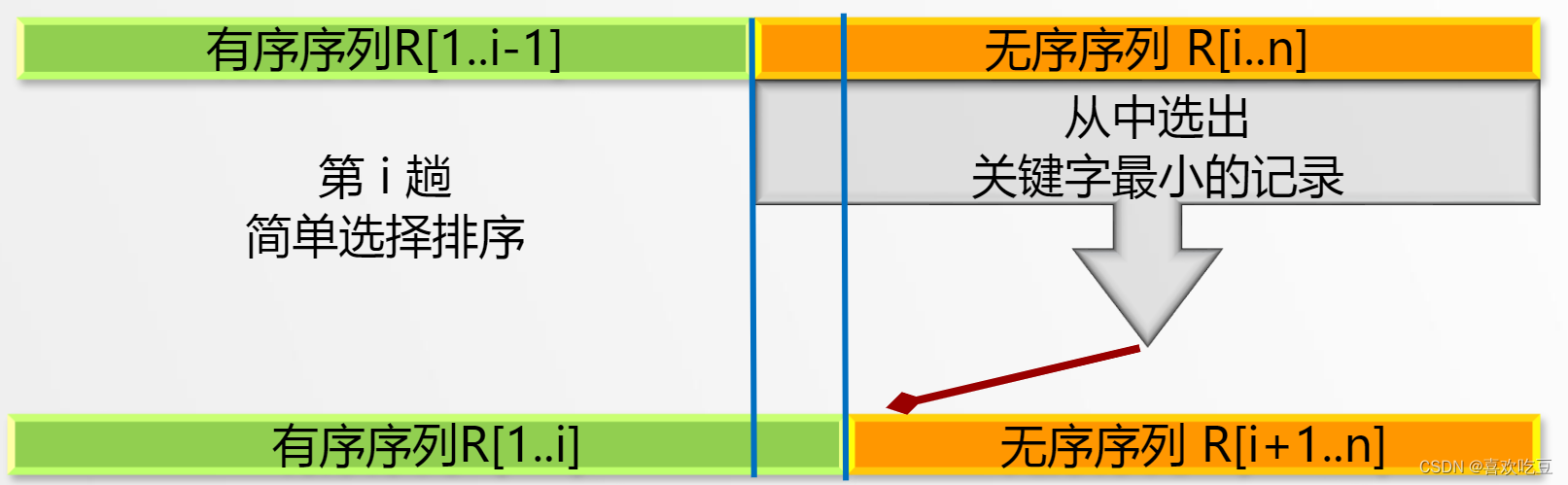
2,排序过程:
●首先通过n-1次关键字比较,从n个记录中找出关键字最小的记录,将它与
第一个记录交换
●再通过n-2次比较,从剩余的n-1个记录中找出关键字次小的记录,将它与
第二个记录交换
●重复上述操作,共进行n-1趟排序后,排序结束
3,代码实现:
void smp_ selesort(JD r[], int n){
int i,j,k;
JD x;
for (i = 1;i<n;i++){
k=i;
for (j =i+ 1;j <= n;j++)
if (r[j]. key<r[k].key) k = j;
if (i != k){
x = r[i];
r[i] = r[k];
r[k] = x;
}
}
}4,算法评价:

稳定性分析:

堆排序:

void Heap Sort ( ElementType A[],int N )
{ BuildHeap(A) ; /* O(N) */
for ( i=0; i<N; i++ )
TmpA[i] = DeleteMin(A) ; /* O(1ogN) */
for ( i=0; i<N; i++ ) /* O(N) */
A[i] = TmpA[i] ;
}

void Heap Sort ( ElementType A[],int N )
{ for ( i=N/2-1; i>=0; i-- ) /* BuildHeap */
PercDown( A,i, N ) ;
for ( i=N-1; i>0; i-- ) {
Swap( &A[0] ,&A[i] ) ; /* DeleteMax */
PercDown( A,0,i ) ;
}
}
五,归并排序
1,合并两个有序表

归并——将两个或两个以上的有序表组合成一个新的有序表,叫归并排序
2-路归并排序
排序过程
设初始序列含有n个记录,则可看成n个有序的子序列,每个子序列长度为1
两两合并,得到n/2个长度为2或1的有序子序列
再两两合并,...如此重复,直至得到一个长度为n的有序序列为止

迭代算法:
将序列的每一个数据看成一个长度为1的有序表,然后,将相邻两组进行归并得到长度为2的有序表(一 趟归并)再对相邻两组长度为2的有序表进行下一趟归并得到长度为4的有序表,这样一直进行下去,直到整个表归并成有序表。如果某一趟归并过程中,单出一个表,该表轮空,等待下一趟归并。
递归思想
将无序序列划分成大概均等的2个子序列,然后用同样的方法对2个子序列进行归并排序得到2个有序的子序列,再用合并2个有序表的方法合并这2个子序列,得到n个元素的有序序列。
void MSort( ElementType A[ ] ElementType TmpArray[ ] ,int Left, int Right )
{
int Center;
if( Left< Right ) { /* 待排序的数据在数组的下标位置*/
Center=(Left十Right)/2;
MSort( A, TmpArray, Left, Center ); /*T( N / 2) */
MSort( A, TmpArray, Center十1, Right );
/*T(N/2)*/
Merge( A, TmpArray, Left, Center + 1, Right ); /* O( N ) */
}
}
void Mergesort( ElementType A[ ],int N )
{ ElementType *TmpArray; /* need O(N) extra space */
TmpArray = malloc( N* sizeof( ElementType ) );
if ( TmpArray != NULL) {
MSort( A, TmpArray, 0,N-1 );
free( TmpArray );
}
else FatalError( "No space for tmp array!!" );
}
/* Lpos = start of left half, Rpos = start of right half */
void Merge( ElementType A[ ] ElementType TmpArray[ ],int Lpos, int Rpos, int RightEnd )
{
int i, LeftEnd, NumElements, TmpPost
LeftEnd = Rpos- 14;
TmpPos = Lpos;
NumElements = RightEnd- Lpos十1;
while( Lpos <= LeftEnd && Rpos <= RightEnd ) /* main loop */
if(A[Lpos]<=A[Rpos])
TmpArray[ TmpPos++ ]三A[ Lpos++ ];
else
TmpArray[ TmpPos++ ] 3 A[ Rpos++ ];
while( Lpos <= LeftEnd ) /* Copy rest of first half */
TmpArray[ TmpPos++ ] a A[ Lpos++ ];
while( Rpos <= RightEnd ) /* Copy rest of second half * /
TmpArray[ TmpPos++ ] = A[ Rpos++ ];
for( ie 0; i < NumElements; i+ +, RightEnd-- )
/* Copy TmpArray back */
{
A[ RightEnd ] = TmpArray[ RightEnd ];
printf(%od " A[RightEnd]);
}
}
2,算法评价:
时间复杂度:每-趟归并的时间复杂度为O(n),总共需要归并log2n趟,因而,总的时间复杂度为O(nlog2n)。
空间复杂度: 2-路归并排序过程中, 需要一个与表等长的存储单
元数组空间,因此,空间复杂度为O(n)。

六,交换排序
通过"交换"无序序列中的记录从而得到其中关键字最小或最大的记录,并将它加入到有序子序列中,以此方法增加记录的有序子序列的长度。
冒泡排序算法评价:

冒泡排序的改进:
快速排序算法评价:

算法特点:
●快速排序算法是不稳定的
对待排序序列49 49' 38 65,
快速排序结果为: 38 49' 49 65
●快速排序的性能跟初始序列中关键字的排列和选取的枢纽有关
●当初始序列按关键字有序(正序或逆序)时,性能最差,蜕化为冒泡
排序,时间复杂度为O(n2)
●常用“三者取中”法来选取划分记录,即取首记录r[s].key.尾记录r[t].key和中间记录r[(S+ t)/2].key三者的中间值为划分记录。
●快速排序算法的平均时间复杂度为O(nlogn)

七,基数排序
多关键字排序:
设序列{R1, R..... R},关键字有d位,
关键字(K0, k1.... Kd-1)有序是指:
对于序列中任意两个数据R;和R;(1≤i<j≤n)
都满足: (K:, K....K.-1)<. (K:0, K....K.-1)
其中:
K°称为"最主”位关键字,Kd-1称为 "最次” 位关键字
多关键字排序方法分为:
高位优先多关键字排序
低位优先多关键字排序
高位优先多关键字排序
先对K进行排序,并按K0的不同值将记录序列分成若干子序列之后,分别对K1进行排序,....依次类推,直至对最次位关键字Kd-1排序完成为止。
低位优先多关键字排序
首先按关键字Kd- 1进行排序,
然后按关键字Kd-2进行排序,。。。。依次类推,直至最后对最主位关键字K排序完成为止。

两种排序方法实现上有什么区别?哪种方法更好?为什么?
















 2312
2312











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











