






试想一下,如果将来你工作后,你的老板让你写一个排序算法,而你会的算法中竟然没有快速排序,我想那个时候你最好不要声张,偷偷的去把快速排序算法找来敲进你的电脑,这样至少你不会被大伙取笑~~~
快排的基本介绍
快速排序算法最早是由图灵奖获得者Tony Hoare设计出来的,该算法被列为20世纪十大算法之一,也是我们必须要掌握的算法之一。快速排序的基本思想是:任取待排序元素序列中的某元素作为基准值,按照该排序码将待排序集合分割成两子序列,左子序列中所有元素均小于基准值,右子序列中所有元素均大于基准值,然后最左右子序列重复该过程,直到所有元素都排列在相应位置上为止。
快排的代码实现
目前快排的代码实现分为两种方式:一种是递归实现、一种是非递归实现。而递归实现有三种实现思想,希望大家能够理解。注意:下面车速较快,请系好安全带
递归——挖坑法
挖坑法的基本思想是:先将第一个数据(我们一般使用第一个或者最后一个数据)放在临时变量key中,形成第一个坑位(pivot)。先通过end往后找比key小的数据,找到了,就把end位置的数据放在坑(pivot)里,此时end为新的坑位;然后begin往前找比key大的数据,找到了,就把begin位置的数据放在新的坑(pivot)里,此时begin为新的坑位。当begin等于end时,说明待排序的数据已经找完了,此时begin(pivot)就是key元素的最终位置,实现了左边比key小,右边比key大。在用同样的方法,递归pivot左右两边的区间,最后完成排序。
参考代码如下:
#include <stdio.h>
//假设按照升序对arr数组中[left, right)区间中的元素进行排序
void Qsort1(int arr[], int left, int right)
{
//判断left和right是否满足成为区间
if (left >= right)
return;
int pivot = left;
int key = arr[left];
int begin = left;
int end = right;
while (begin < end)
{
//右边找小,找到放在坑里面
while (begin < end && arr[end] >= key)
end--;
//循环结束arr[end]小于key,把arr[end]放进坑里面
arr[pivot] = arr[end];
pivot = end;
//左边找大,找到放在坑里面
while (begin < end && arr[begin] <= key)
begin++;
//循环结束arr[begin]大于key,把arr[begin]放进坑里面
arr[pivot] = arr[begin];
pivot = begin;
}
//循环结束begin大于等于end,begin(end)为新的坑位
pivot = begin;
arr[pivot] = key;
//以pivot为边界形成左右两个部分[left,pivot - 1]和[pivot + 1,right]
//递归排[left,pivot - 1]
Qsort1(arr, left, pivot - 1);
//递归排[pivot + 1,right]
Qsort1(arr, pivot + 1, right);
}
int main()
{
int arr[] = { 4,9,2,8,3,7,1,5,0,6 };
int sz = sizeof(arr)/sizeof(arr[0]);
Qsort1(arr, 0, sz - 1);
return 0;
}请结合图示
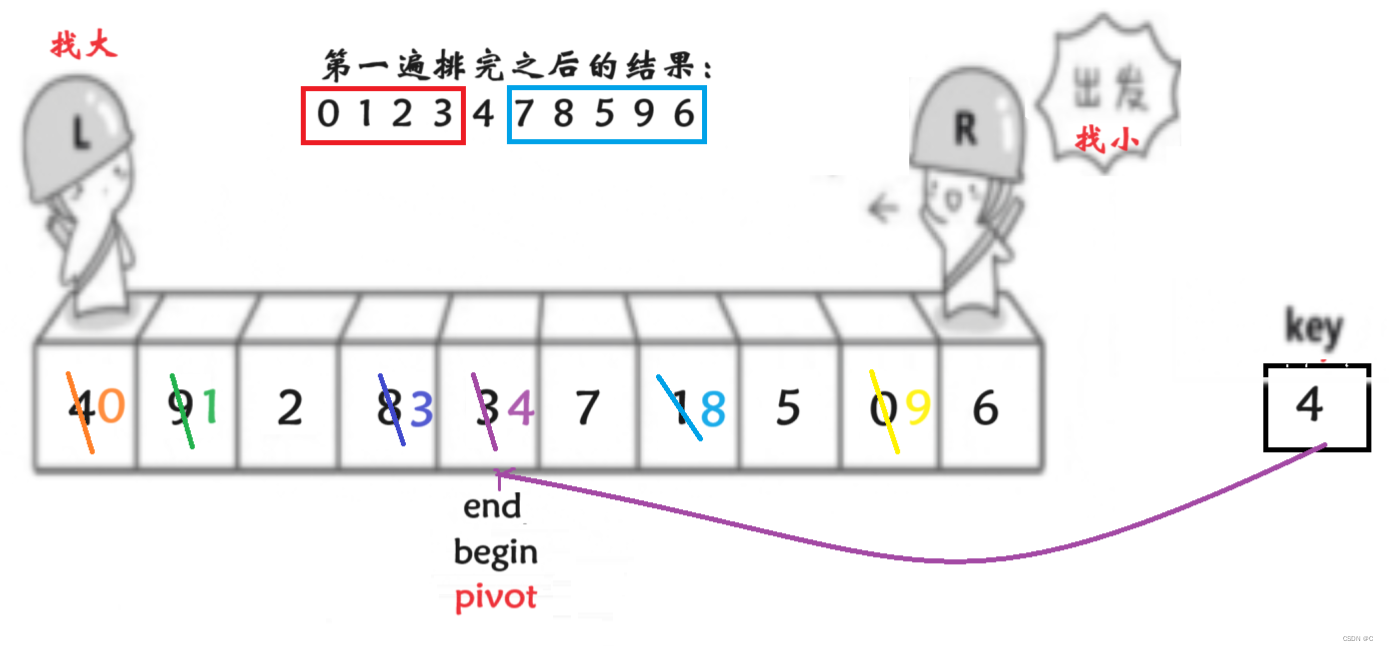 经过第一遍排序后pivot位置的元素4,实现了左边比4小,右边比4大。如果左边无序,重复此过程;右边同理。希望大家能够理解
经过第一遍排序后pivot位置的元素4,实现了左边比4小,右边比4大。如果左边无序,重复此过程;右边同理。希望大家能够理解
递归——左右指针法
左右指针法的基本思想与挖坑法基本类似,唯一不同的就是找到比key大或者小的数据不是直接赋值,而是进行交换。首先让key为第一个数据,让end从后往前找比key小的数据,找到了停下来,让begin从前往后找比key大的数据,找到了停下来,然后交换end位置和begin位置的数据;当end与begin相遇时,让begin(end)位置的数据与key交换。分别递归调用左右区间,直到数据有序为止。
参考代码如下:
//交换函数
void Swap(int* a, int* b)
{
int tmp = *a;
*a = *b;
*b = tmp;
}
void Qsort2(int arr[], int left, int right)
{
if (left >= right)
return;
int begin = left;
int end = right;
int key = begin;
while (begin < end)
{
//找小,停下来时就说明找到了
while (begin < end && arr[end] >= arr[key])
end--;
//找大,停下来时就说明找到了
while (begin < end && arr[begin] <= arr[key])
begin++;
//交换此时begin和end的数据
Swap(&arr[begin], &arr[end]);
}
//此时begin与end相等,与key交换
Swap(&arr[key], &arr[begin]);
//递归左半区间
Qsort2(arr, left, begin - 1);
//递归右半区间
Qsort2(arr, begin + 1, right);
}
int main()
{
int arr[] = { 4,9,2,8,3,7,1,5,0,6 };
int sz = sizeof(arr)/sizeof(arr[0]);
Qsort2(arr, 0, sz - 1);
return 0;
}请结合图示:

第一遍排完之后也是数组左边都比key小,右边都比key大。如果左边无序,就在进行递归,直到有序为止。右边同理,希望大家能够理解
递归——快慢指针法
快慢指针法的基本思想是:第一个数据定义为prev,第二个数据定义为cur,在定义一个key为第一个元素;让cur从当前位置开始往后寻找比key小的数据,如果找到了,就让prev向后走一步,然后交换prev位置和cur位置的元素;直到cur寻找到最后一个元素为止。最后在把prev位置的元素和key交换。递归调用,直到有序为止
参考代码如下:
void Swap(int* a, int* b)
{
int tmp = *a;
*a = *b;
*b = tmp;
}
void Qsort3(int arr[], int left,int right)
{
if (left >= right)
return;
int prev = left;
int cur = left + 1;
int key = left;
while (cur <= right)
{
//找小
if (arr[cur] < arr[key])
{
prev++;
Swap(&arr[prev], &arr[cur]);
}
cur++;
}
Swap(&arr[key], &arr[prev]);
//递归
Qsort3(arr, left, prev - 1);
Qsort3(arr, prev + 1, right);
}
int main()
{
int arr[] = { 4,9,2,8,3,7,1,5,0,6 };
int sz = sizeof(arr)/sizeof(arr[0]);
Qsort3(arr, 0, sz - 1);
return 0;
}请结合图示:
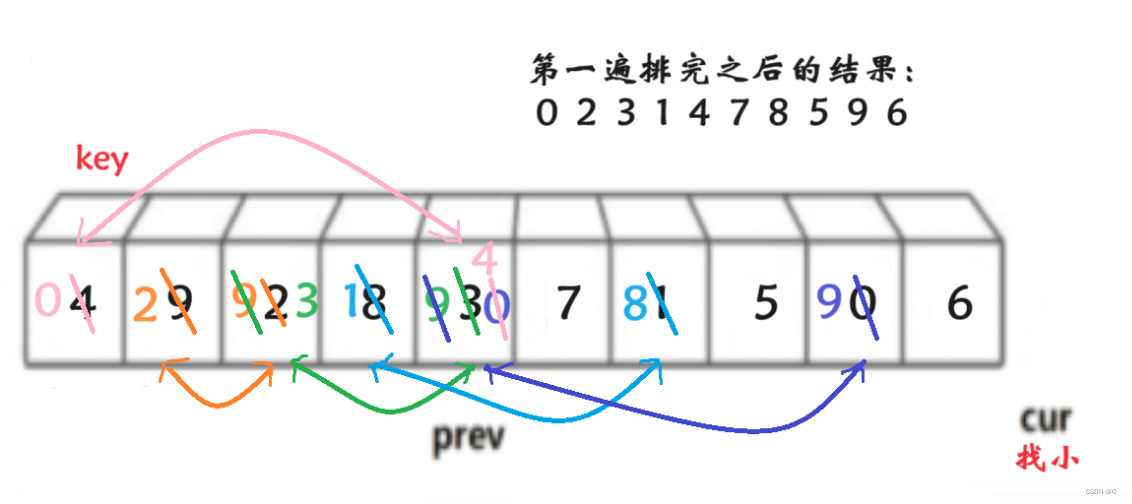
第一遍排完之后也是数组左边都比key小,右边都比key大。如果左边无序,就在进行递归,直到有序为止。右边同理,希望大家能够理解
非递归
非递归的基本思想就是:通过数据结构中的栈结构来模拟递归的过程,首先要拥有一个栈(在本篇文章中代码都是用C语言来实现的,因为C语言库里没有栈,所以栈是自己写的),然后选出来区间的上下限进行出栈入栈,之后进行单趟排序。之后就是和递归一样的思想,不同的是在这里是用数据结构栈来模拟的递归。
ps. Push为入栈;Pop为出栈;Top为获取栈顶元素 ;实现栈的代码没有在下面的参考代码里展示,参考代码只是调用了栈的相关接口,希望大家能够理解
参考代码如下:
//单趟排序函数,就是上面介绍的快慢指针法的单趟排
int SingleSort(int arr[], int left, int right)
{
if (left >= right)
return;
int prev = left;
int cur = left + 1;
int key = left;
while (cur <= right)
{
//找小
if (arr[cur] < arr[key])
{
prev++;
Swap(&arr[prev], &arr[cur]);
}
cur++;
}
Swap(&arr[key], &arr[prev]);
return prev;
}
void QsortNonR(int arr[], int sz)
{
ST st;
//初始化栈
STInit(&st);
//压栈,先入右边区间上限
STPush(&st, sz);
//压栈,再入左边区间下限
STPush(&st, 0);
//当栈里面为空时,退出
while (!STEmpty(&st))
{
//先获取左边区间下限
int left = STTop(&st);
STPop(&st);
//在获取右边区间上限
int right = STTop(&st);
STPop(&st);
//进行单趟排序
int keyIndex = SingleSort(arr, left, right);
//单趟排以后划分为[left,keyIndex - 1]和[keyIndex + 1,right]两个区间。
//先入右边区间,再入左边区间。这样会先处理左边在处理右边
//因为栈的特点是后进先出
if (keyIndex + 1 < right)
{
STPush(&st, right);
STPush(&st, keyIndex + 1);
}
if (keyIndex - 1 > left)
{
STPush(&st, keyIndex - 1);
STPush(&st, left);
}
}
//销毁栈
STDestroy(&st);
}
int main()
{
int arr[] = { 4,9,2,8,3,7,1,5,0,6 };
int sz = sizeof(arr)/sizeof(arr[0]);
QsortNonR(arr, sz - 1);
return 0;
}上面代码的注释特别详细,希望大家能够理解
快速排序的复杂度
我们来分析一下快速排序的性能。快速排序的时间性能在最优的情况下,时间复杂度为O(n*logn);最坏的情况,是在待排序的序列为正序或者逆序的情况下,时间复杂度为O(n*n)。就空间复杂度来说,主要是递归造成的栈空间的使用,最好的情况,空间复杂度为O(logn);最坏情况下,空间复杂度为O(n)。
更可惜的是,由于key的比较和交换是跳跃进行的,因此,快速排序是一种不稳定的排序方法。
ps. 稳定性:假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍在r[j]之前,则称这种排序算法是稳定的;否则称为不稳定的。
快速排序的优化
优化选取的坑位
我们在前面已经说过,快速排序最坏的时间复杂度为O(n*n),是在待排序序列有序的情况下。在有序的情况下,我们不管选择的最左边的数据为坑位,还是选择最右边的数据为坑位,每次划分的子区间只比上一次划分的子区间少一,而另一个子区间为空。所以就有了最坏的时间复杂度。那我们有没有办法让选取的坑位尽量为待排序序列的中间数据呢?答案是肯定的。下面我们来介绍一下三数取中。
三数取中,即取三个关键字先进行排序,将中间数作为坑位,一般取最左端、最右端和中间三个数,也可以随机选取。这样至少中间数一定不会是最小或者是最大的数,从概率上来说,取三个数均为最小或最大的数的可能性事微乎其微的,因此中间数位于较为中间的值的可能性就大大提高了。
参考代码如下:
int GetMidIndex(int arr[], int left, int right)
{
int mid = (left + right) / 2;
if (arr[mid] < arr[right])
{
if (arr[left] < arr[mid])
return mid;
else if (arr[right] < arr[left])
return right;
else
return left;
}
else//arr[mid] > arr[right]
{
if (arr[left] > arr[mid])
return mid;
else if (arr[right] > arr[left])
return right;
else
return left;
}
}有了三数取中,我们在平时书写快速排序代码时,只需要调用一下三数取中的代码,完全就可以避免最坏时间复杂度O(n*n)的出现。
优化小区间
对于一个数学科学家、博士生导师,他可以攻克世界性的难题,可以培养出最优秀的数学博士,但让他去教小学生“1+1=2”的算术课程,那他不一定有小学老师教的好。换句话说就是,大材小用有时候会变得反而不好用。我们知道快速排序在排非常大的数据量时,会有很大优势;但如果数据量很小,那还不如直接使用直接插入排序(直接插入排序是简单排序中性能最好的)。
ps. 直接插入排序算法的代码并没有在参考代码中出现,参考代码只是调用了一下
参考代码如下:
void QuickSort(int arr[], int left,int right)
{
if (left >= right)
return;
//调用三数取中
int index = GetMidIndex(arr, left, right);
Swap(&arr[left], &arr[index]);
int begin = left;
int end = right;
int pivot = begin;
int key = arr[pivot];
while (begin < end)
{
while (begin < end && arr[end] >= key)
end--;
arr[pivot] = arr[end];
pivot = end;
while (begin < end && arr[begin] <= key)
begin++;
arr[pivot] = arr[begin];
pivot = begin;
}
pivot = begin;
arr[pivot] = key;
//递归调用左子树和右子树,分治递归,这里不采用这种方法
//QuickSort(arr, left, pivot - 1);
//QuickSort(arr, pivot + 1, right);
//小区间优化
//大于10的意思是,当区间内的数据大于10个的时候,使用快速排序
//当然你也可以自己修改:大于100、大于1000都没有问题
if ((pivot - 1) - left > 10)
{
QuickSort(arr, left, pivot - 1);
}
else
{ //调用直接插入排序进行小区间排序
InsertSort(arr + left, (pivot - 1) - left + 1);
}
if (right - (pivot + 1) > 10)
{
QuickSort(arr, pivot + 1, right);
}
else
{
InsertSort(arr + pivot + 1, right - (pivot + 1) + 1);
}
}小区间优化和三数取中,已在上述代码中体现。希望大家能够理解
结语
好啦,本次的分享就到这里了,如果大家有疑惑的地方欢迎私信骚扰,另外,如果想要栈的实现代码和直接插入排序的代码,也可以私我。我们下次再见~~~
















 178
178











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











