






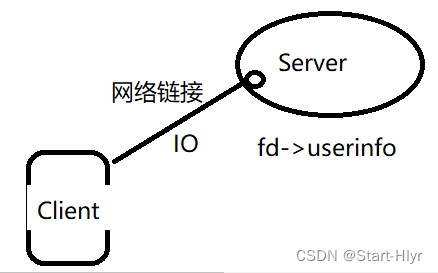
网络IO
网络IO就是建立在客户端和服务端的一个fd(File Descriptor)
网络IO(Input/Output)指的是计算机程序与网络之间进行数据交互的过程,网络IO是计算机与外部世界进行通信的桥梁。在网络编程和系统设计中,网络IO是一个至关重要的概念,因为它涉及到数据的发送、接收和处理:
-
定义
-
网络IO是计算机与外部设备(尤其是网络设备如网卡)之间的数据输入和输出操作。
-
它描述了计算机程序如何通过网络与其他计算机或设备进行通信。
-
-
主要类型
-
输入操作(Input):从网络接收数据到计算机内存或程序当中。
-
输出操作(Output):将计算机内存中的数据发送到网络上。
-
-
基本过程
-
网络IO操作通常包括两个主要部分:
-
IO的调用:系统调用,即程序请求操作系统执行网络IO操作。
-
IO的执行:在内核中相关数据的处理过程,包括数据的准备(如将数据加载到内核缓存)和数据的迁移(如从内核缓存到用户缓存)。
-
-
-
IO模型
-
为了提高网络IO的性能,通常使用不同的IO模型,如阻塞IO、非阻塞IO、IO多路复用(如select、poll、epoll)、异步IO等。
-
这些模型在处理网络IO时具有不同的行为,例如阻塞IO会导致请求进程等待IO准备就绪,而非阻塞IO则不会。
-
-
同步与异步
-
同步IO:导致请求进程阻塞,直到IO操作完成。
-
异步IO:不导致请求进程阻塞,IO操作在后台进行,完成后通过某种机制(如回调函数)通知进程。
-
-
内核空间与用户空间
-
在操作系统中,内核空间是操作系统内核运行的区域,具有访问硬件和内存的权限。
-
用户空间是用户程序运行的区域,不能直接访问内核空间的数据。因此,网络IO操作通常涉及用户空间和内核空间之间的数据交换。
-
-
性能考虑
-
网络IO操作的性能可以受到多种因素的影响,包括硬件性能、操作系统的优化、网络带宽和延迟等。
-
在高并发的网络应用中,优化网络IO性能对于提高整体系统的吞吐量和响应速度至关重要。
-
IO与TCP(Transmission Control Protocol,传输控制协议)连接
TCP连接通过三次握手建立,通过四次挥手断开
accept()函数分配IO、fd与tcp连接信息一对一
一请求一线程
一请求一线程(One Request Per Thread)是服务器处理并发请求的一种常见模式,特别是在使用多线程技术时
-
定义
-
当一个客户端请求到达服务器时,服务器会为该请求分配一个单独的线程来处理它。这样,每个请求都有自己独立的执行路径,互不干扰。
-
-
特点
-
独立性:每个线程都独立处理其对应的请求,互不依赖。
-
并发性:多个线程可以同时运行,从而服务器可以同时处理多个请求。
-
资源开销:线程的创建和销毁需要一定的资源开销,特别是当请求量非常大时,线程的频繁创建和销毁可能成为性能瓶颈。
-
-
优缺点
-
优点
-
逻辑清晰:每个线程处理一个请求,逻辑上容易理解和实现。
-
并发性好:多个线程可以同时运行,充分利用多核CPU的优势。
-
-
缺点
-
资源开销大:线程的创建和销毁需要消耗系统资源。
-
线程管理复杂:当线程数量很多时,线程的管理(如调度、同步等)会变得复杂。
-
可能的性能瓶颈:如果请求量非常大,线程的频繁创建和销毁可能成为性能瓶颈。
-
-
-
优化方案
-
线程池:使用线程池来管理线程,避免线程的频繁创建和销毁。线程池中的线程可以重复使用,从而降低资源开销。
-
异步I/O:采用异步I/O技术(如NIO、AIO等),可以在一个线程中处理多个请求,进一步提高并发性能。
-
负载均衡:通过负载均衡技术将请求分发到多个服务器上,从而分散负载,提高整体系统的处理能力。
-
-
实际应用
-
在Java Web开发中,常见的Web容器(如Tomcat、Jetty等)都支持一请求一线程的处理模式。这些容器会为每个HTTP请求分配一个单独的线程来处理,从而实现高并发处理。
-
在一些高性能的服务器框架中(如Netty、Mina等),通常会采用异步I/O和线程池技术来优化性能,实现更高并发处理能力和更好的资源利用率。
-
select
<sys/select.h> int select(int nfds, fd_set *readfds, fd_set *writefds,fd_set *exceptfds, struct timeval *timeout);
poll
<pool.h>
struct pollfd
{
int fd;
short events;//读(POLLIN)、写(POLLOUT)、异常(POLLERR等)
short revents;
};
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
//timeout:负值,表示一直等待;如果为零,表示立即返回;如果为正数,表示等待指定毫秒数
epoll
<sys/epoll.h>
struct epoll_event
{
__poll_t events;
__u64 data;
}EPOLL_PACKED;
int epoll_create(int size);
int epoll_ctl(int epfd,int op,int fd,struct epoll_event *_Nullable event);
//op 是操作类型,如 EPOLL_CTL_ADD(添加文件描述符)、EPOLL_CTL_MOD(修改文件描述符)和 EPOLL_CTL_DEL(删除文件描述符)
int epoll_wait(int epfd,struct epoll_event *events,int maxevents,int timeout);
int epoll_pwait(int epfd, struct epoll_event *events, int maxevents, int timeout, const sigset_t *sigmask);
//sigmask 是一个指向信号集的指针,定义了在 epoll_pwait 调用期间要阻塞的信号
总结
select、poll 和 epoll 都是针对IO的处理,IO事件触发
select、poll 和 epoll 是 Linux 系统中用于处理 I/O 多路复用的三种机制。它们允许一个进程监视多个文件描述符(通常是套接字),以查看它们是否准备好进行读、写或其他操作,而无需为每个文件描述符创建单独的线程或进程

-
select和poll:都是基于轮询的方式来实现I/O多路复用,时间复杂度为O(n),且都需要将整个文件描述符集合从用户空间复制到内核空间,造成不必要的开销。它们的主要区别在于poll没有文件描述符数量的限制。
-
epoll:采用了事件驱动的方式来实现I/O多路复用,时间复杂度为O(1),且使用了mmap内存映射技术来避免不必要的文件描述符集合的复制。此外,epoll还支持边缘触发模式,使得其在处理大量并发连接时具有更高的效率。因此,epoll是目前最好的多路复用技术之一。
为什么需要reactor
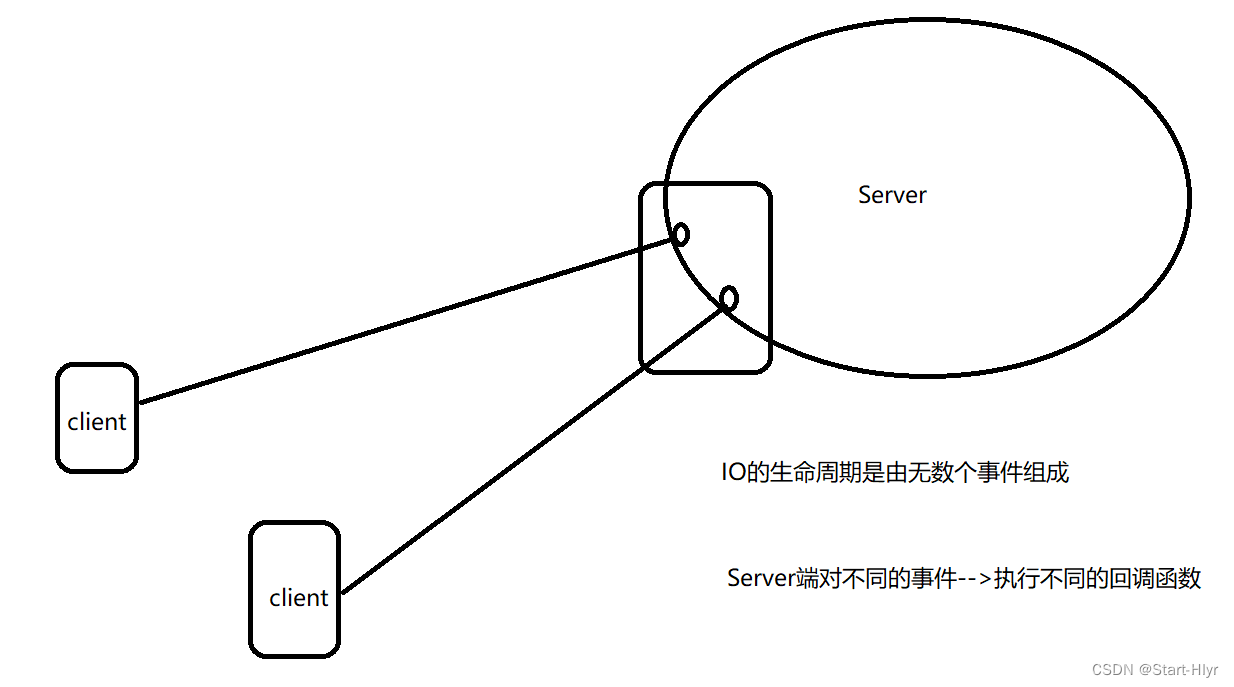
需要 Reactor(反应器)模式的主要原因是处理并发 I/O 操作时的高效性和可伸缩性。随着现代应用程序对并发性和性能要求的不断提高,传统的基于线程的并发模型在处理大量并发连接时可能会遇到一些问题,如线程开销大、上下文切换频繁等。Reactor 模式通过事件驱动和非阻塞 I/O 的方式,提供了一种更加高效和可伸缩的并发处理机制。
以下是需要 Reactor 模式的主要原因:
-
高性能:Reactor 模式通过非阻塞 I/O 和事件驱动的方式,能够高效地处理大量并发连接。它避免了为每个连接创建一个线程或进程的开销,而是使用一个或多个线程来处理多个连接上的事件。这大大减少了线程或进程的数量,降低了上下文切换的频率,从而提高了系统的整体性能。
-
可伸缩性:由于 Reactor 模式是基于事件驱动的,它能够根据系统的负载动态地调整资源的使用。当系统负载增加时,可以轻松地增加更多的 Reactor 线程或进程来处理事件,从而实现系统的水平扩展。这种可伸缩性使得 Reactor 模式非常适合处理大规模并发连接的场景。
-
响应性:Reactor 模式能够及时响应客户端的请求。当一个客户端发起一个请求时,Reactor 会立即将该请求封装成一个事件,并将其放入事件队列中。然后,一个或多个工作线程会从事件队列中取出事件并进行处理。这种处理方式使得客户端的请求能够得到及时的响应,提高了系统的响应性。
-
简化编程模型:Reactor 模式将 I/O 操作、事件处理以及业务逻辑处理分离开来,使得编程模型更加清晰和简单。开发人员可以专注于实现业务逻辑,而无需关心底层的 I/O 操作和事件处理细节。这降低了开发的复杂性,提高了代码的可维护性和可重用性。
-
支持多种 I/O 模型:Reactor 模式可以支持多种 I/O 模型,如同步 I/O、异步 I/O、非阻塞 I/O 等。这使得开发人员可以根据具体的应用场景选择合适的 I/O 模型,以实现最佳的性能和可伸缩性。
综上所述,Reactor 模式通过事件驱动和非阻塞 I/O 的方式,提供了一种高效、可伸缩且响应性好的并发处理机制。它在处理大量并发连接时具有显著的优势,因此被广泛应用于各种高性能的服务器和应用程序中。















 693
693

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









