






目录
分治法
思想:将整个问题分成若干个小问题后分而治之。将n个输入分解成k个不同子集,得到k个不同的与原问题性质相同的可独立求解的子问题。在求出子问题的解之后,能找到适当的方法把它们合并成整个问题的解。
抽象化控制
procedure DANDC(p,q)
global n, A(1:n); integer m, p, q;
//1≤p≤q≤n//
if SMALL(p,q)//问题规模足够小的时候,直接求解
then return(G(p,q))
else m<-DIVIDE(p,q) //分割
return(COMBINE( DANDC(p,m), DANDC(m+1,q)))//治、合
endif
end DANDC
//归并排序为例
Procedure MERGESORT(low,high)
int low, high, mid;
if low<high
then mid= (low+high)/2
call MERGESORT(low,mid)
call MERGESORT(mid+1,high)
call MERGE(low,mid,high)
endif
end MERGESORT
//自底向上,取消对栈的调用;优化时间消耗
Procedure MERGESORT1(n)
integer low, mid, high, step, k
step <- 1;
while step ≤n do
low <- 1
while low +step-1<n do
mid <- low + step-1
high <- min( mid+step, n);
MERGE(low, mid,high);
low = high +1;
repeat
step <- step* 2:
repeat
end MERGESORT1
计算时间:当分成的两个子问题的输入规模大致相等时,有:
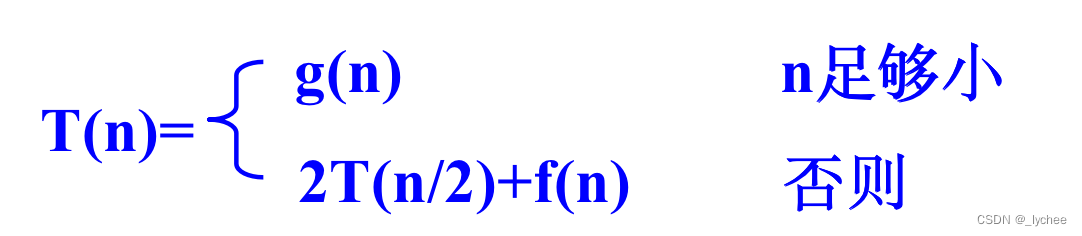
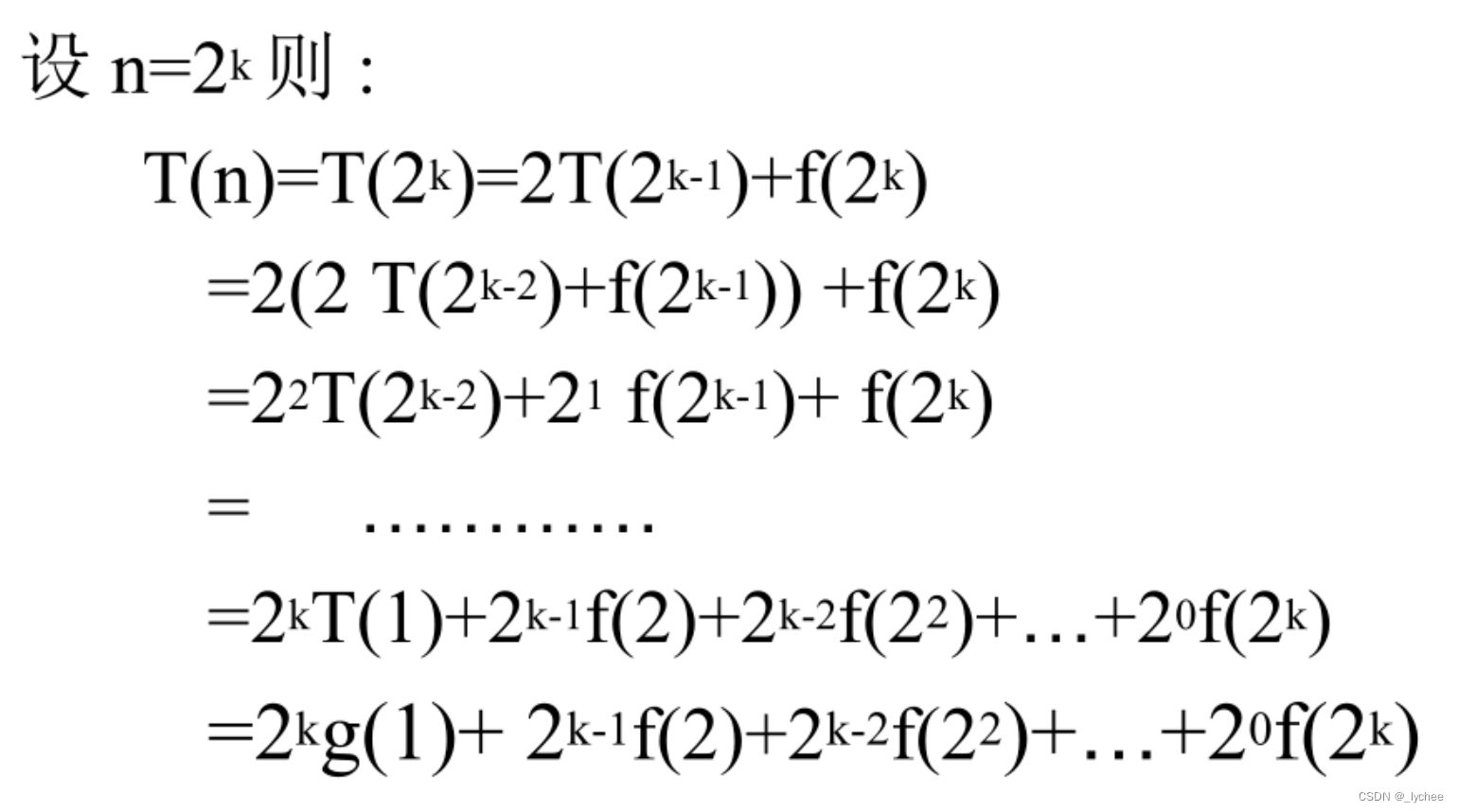
- g(n):对输入规模足够小的直接计算答案的时间;
- T(n):输入规模为n的问题用分治策略的计算时间;
- f(n):用Combine函数把子问题合成原问题的解的时间;
分治相关证明
二分检索算法正确性证明
如果n=0,则不进入循环,j=0,算法终止。 否则就会进入循环与数组A中的元素进行比较。
成功情况:
若x=A[mid],则j=mid,检索成功,算法终止。
否则,若x<A(mid),则x根本不可能在mid~high,检索范围缩小到low~mid-1。
反之,x>A(mid)时亦然。
不成功情况:
因为low,high和mid都是整形变量,按算法所述方式缩小检索范围总可以在有限步内使low>high,说明x不在A中,退出循环,j=0,算法终止。
定理4.2 若n在区域[2k-1, 2k)中,则对于一次成功的检索,二分检索算法至多作k次比较,而对于一次不成功的检索,或者作k-1次比较或者作k次比较。
证明:
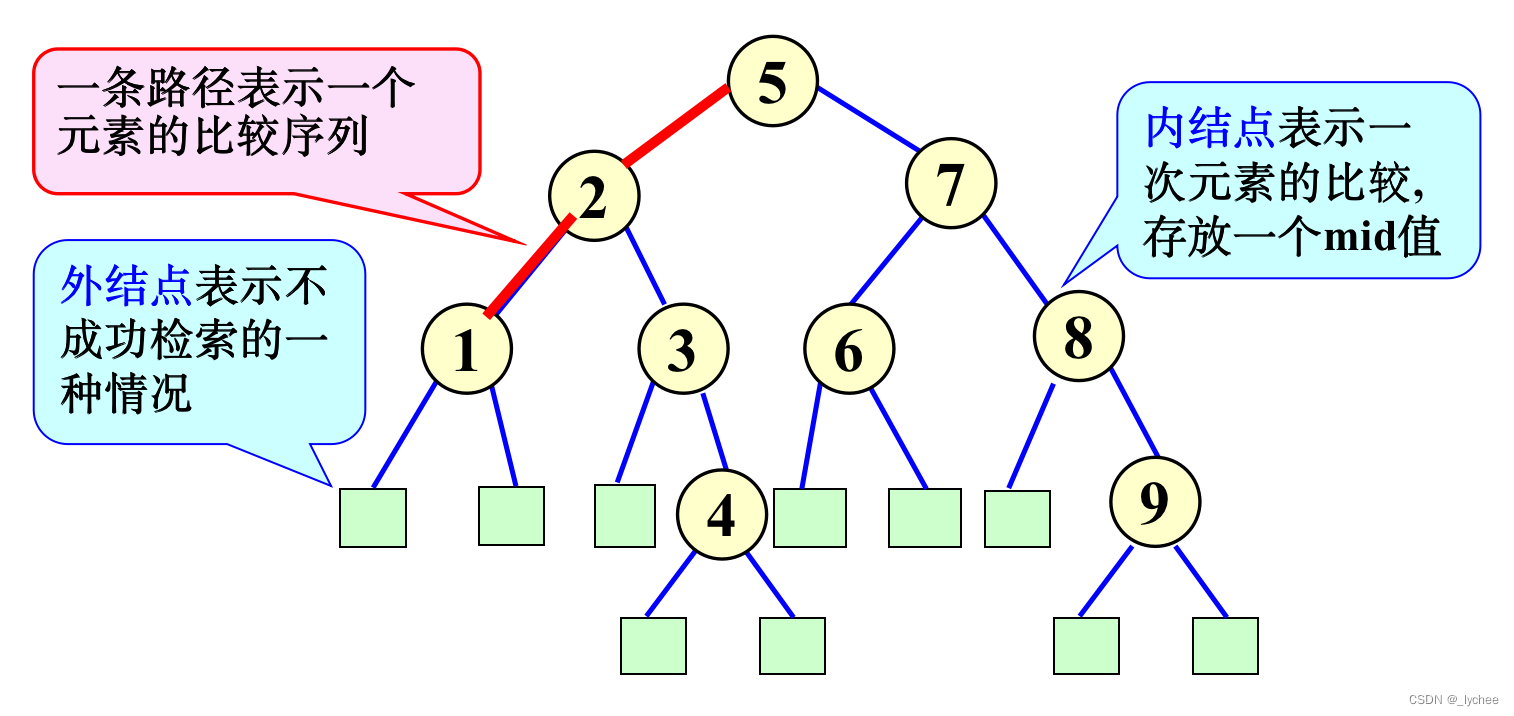
考察二分检索算法执行过程的二元比较树: 成功检索-e-内结点,不成功检索--外结点 由于2^k-1<= n <2^k, 内结点级数<=k(根在1级),外结点级数在k和k+1级。成功检索所需要的元素比较次数=级数,不成功检索所需要的元素比较次数=级数-1;
二元比较树
内部路径长度I:由根到所有内部节点的距离之和;
外部路径长度E:由根到所有外部节点的距离之和;
用数学归纳法容易证明E=I+2n。
定理4.3 设A(1:n)含有n(n≥1)个不同的元素,排序为A(1)<A(2)<…<A(n)。又设以比较为基础去判断是否x∈A(1:n)的任何算法在最坏情况下所需的最小比较次数是FIND(n),那么FIND(n)≥ 「 log(n+1)
证明:通过考察模拟求解检索问题的各种可能算法的比较树可知,FIND(n)不大于树中由根到一个叶子的最长路径的距离。在这所有的树中都必定有n个内节点与x在A中可能的n种出现情况相对应。如果一棵二元树的所有内节点所在的级数小于或等于级数k,则最多有2^k-1个内节点。因此n<= 2^k-1 ,即FIND(n)=k≥ log(n+1)
证明:任何以关键字比较为基础的分类算法, 最坏情况下的时间下界都是Ω(nlogn)。
n个关键字有n!种排列,从根到外节点的每一条 路径分别与一种唯一的 排列相对应。因此比较树必定至少有n!个外节点。最坏情况下比较次数 =比较树的最长路径=根到最远叶结点距离=树高T(n); 2^T(n)>=n!
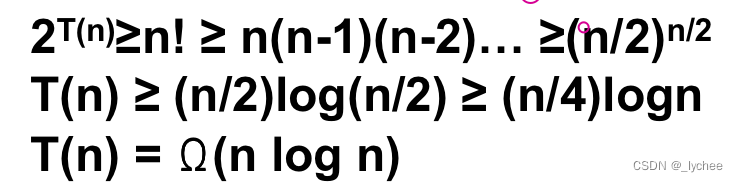
贪心
- 求解步骤:选取一种量度标准; 按此标准对n个输入进行排序; 按该顺序一次输入一个量; 如果这个输入量和当前该量度意义下的部分最优解加在一起不能产生一个可行解, 则不把此输入加入到这个部分解中。
- 思想:是在每一步都采取当前状态下最好或最优的选择,从而希望导致结果是最好或者最优的算法。
- 核心问题:选择能产生问题最优解的最优量度标准。
抽象化控制:
Procedure GREEDY(A, n) //A(1:n)包含n个输入,已排序 // solution←Φ //将解向量solution初始化为空// for i ←1 to n do x← SELECT(A)/*按某种最优量度标准从A中选择一个输入,把它赋值给x,并从A中消去它。*/ if FEASIBLE(solution,x) then solution←UNION(solution,x) endif repeat return (solution) end GREEDY
贪心证明
- 最优量度标准证明的基本思想
- 把这个贪心解与假定的最优解相比较,如果这两个解不同,就去找开始不同的第一个xi,然后设法用贪心解的这个xi去替换掉最优解中的那个xi,并证明最优解在分量代换前后的总效益值无任何变化。 反复进行这种代换, 直到新产生的最优解与贪心解完全一样, 从而证明了贪心解就是最优解。
定理 5.2:如果p1/w1 ≥ p2/w2 ≥ … ≥ pn/wn,则算法GREEDY-KNAPSACK对于给定的背包问题实例生成一个最优解。
procedure GREEDY-KNAPSACK(P,W,M,X,n) real P(1:n), W(1:n), X(1:n), M, cu; integer i, n; X= 0 cu = M for i = 1 to n do if (W(i)>cu) then exit endif X(i) = 1 cu = cu-W(i) repeat if (i≤n) then X(i) = cu/W(i) end GREEDY-KNAPSACK
设X=(x1,…,xn )是算法所生成的解。
1. 如果所有的xi 等于1,显然这个解就是最优解。
2. 否则,设j是使xj ≠ 1的最小下标, 由算法可知:
对于 1≤i<j , xi =1; 对于 j<i≤n , xi =0 ; 对于 i=j , 0 ≤ xj<1。
3. 若X不是最优解, 则必存在一个最优解 Y= (y1,…,yn),使得∑piyi >∑pixi 。
假定∑wiyi =M,设k是使得 yk ≠ xk的最小下标,则可以推出yk<xk成立。
现在, 假定把 yk 增加到 xk , 那么必须从(yk+1,…,yn) 中减去同样多的量, 使得所用的总容量仍为M。这导致一个新的解Z = (z1,…,zn), 其中 zi= xi, 1≤i≤k。
并且(k<i<=n)∑wi ( yi-zi )= wk ( zk-yk)

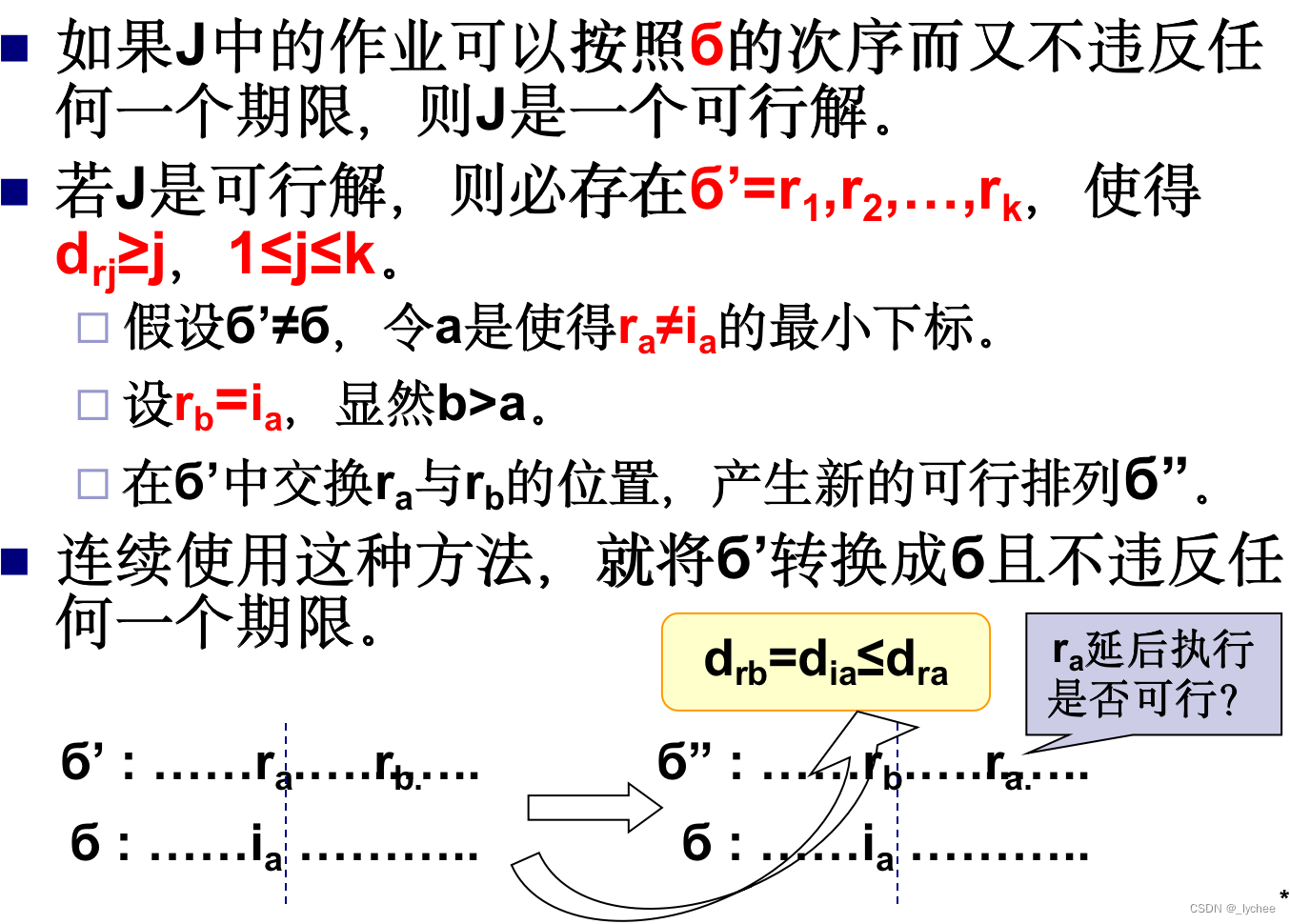
证明:对于作业排序问题用算法5.3所描述的贪心方法总是得到一个最优解。
算法
procedure GREEDY_JOB(D, J, n) // 作业按p1≥ p2≥ …≥ pn的次序输入;它们的期限值D(i)≥1,1≤i≤n,n≥1。J是在它们的截止期限前完成的作业的集合。// J←{1} for i ← 2 to n do if (J∪{i}的所有作业都能在它们的截止期限前完成 ) then J ← J∪{i} endif repeat end GREEDY_JOBJ是贪心方法求出的作业集合,I是一个最优解的作业集合。可以证明J和I具有相同的效益值,从而J也是最优解。 证明I≠J。
设SJ和SI分别是J和I的可行调度表。令调度表中相同作业在相同的时间片执行。
具体方法如下:
用J中作业a替换掉I中同时间片调用的作业b,得到作业集合I’=I-{b}∪{a}的一个可行调度表。显然,I’的效益值不小于I的效益值,并且I’比I少一个与J不同的作业。 重复应用上述转换,使I在不减效益值得情况下转换成J,因此J也必定是最优解,证毕。
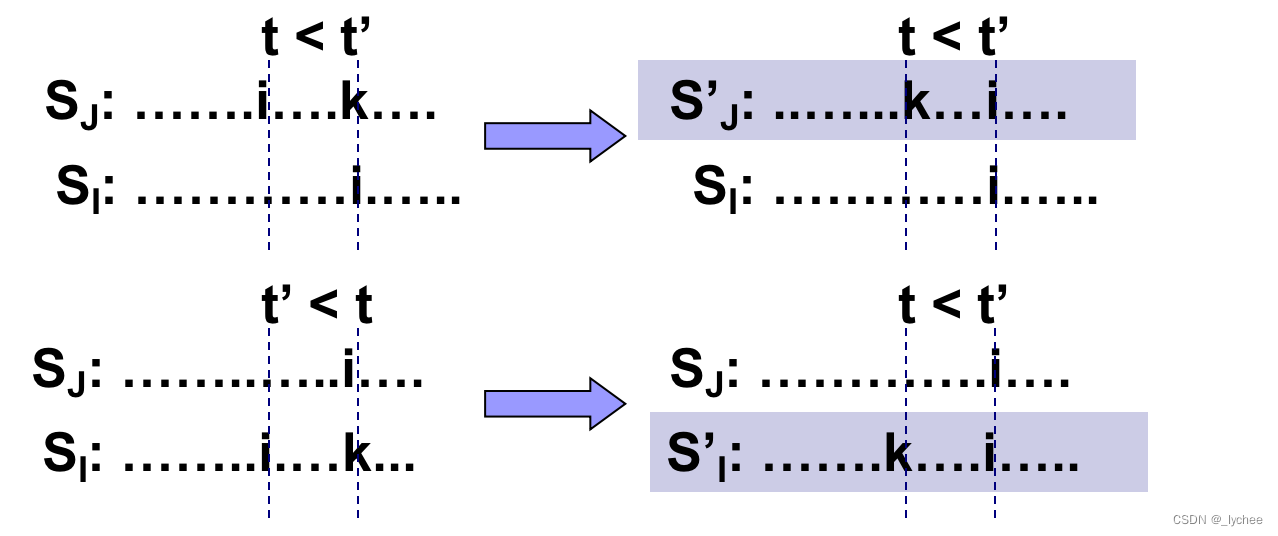
定理5.3:设J是k个作业的集合, б=i1,i2,…,ik是J中作业的一种排列, 它使得di1≤di2≤…≤dik。J是一个可行解, 当且仅当J中的作业可以按照б的次序而又不违反任何一个期限的情况来处理。
回溯
回溯法在解空间树上的搜索策略:
从根结点出发,按深度优先的策略搜索。 回溯法搜索至解空间树的任一结点时, 先判断该结点是否肯定不包含问题的解。如果肯定不包含, 则跳过以该结点为根的子树, 逐层向其祖先结点回溯。否则就进入该子树, 继续按深度优先的策略进行搜索。
步骤
- 针对所给问题定义出问题的解空间。
- 确定易于搜索的解空间树结构。
- 以深度优先方式搜索解空间树, 并在搜索过程中使用限界函数避免无效搜索。 首先根结点成为一个活结点, 同时也是当前的扩展结点。沿当前扩展结点向纵深方向移至一个新结点, 该新结点成为一个新的活结点, 并成为当前扩展结点。 如果当前扩展结点不能再向纵深方向移动, 则其成为死结点。此时回溯至最近的一个活结点, 并使该活结点成为当前的扩展结点。
概念
- 状态空间(state space): 由根结点到其他结点的所有路径确定了这个问题的状态空间。
- 显式约束:限定每个x只从一个给定的集合上取值。
- 隐式约束:描述了xi必须彼此相关的情况。
- 解空间:满足显式约束条件的所有元组。
- 可行解:解空间中满足隐式约束条件的决策序列。
- 解空间树:基于解空间画成的树形状。
- 问题状态(problem state): 树中的每一个结点确定所求解问题的一个问题状态。
- 解状态(solution states): 是这样一些问题状态S, 对于这些问题状态, 由根到S的那条路径确定了这个解空间中的一个元组。
- 答案状态(answer states): 是这样的一些解状态S, 对于这些解状态而言, 由根到S的这条路径确定了这问题的一个解。
- 静态树(static trees): 树结构与所要解决问题的实例无关。
- 动态树(dynamic trees): 树结构是与实例相关的, 且树结构是动态确定的。
- 活结点: 自己已经生成而其所有的儿子结点还没有全部生成的结点。
- E-结点(正在扩展的结点): 当前正在生成其儿子结点的活结点。
- 死结点: 不再进一步扩展或者其儿子结点已全部生成的结点。
效率影响因素
- 生成子节点的时间:生成下一个X(k)的时间
- 子节点的数量:满足显示约束条件的X(K)的数量
- 检验节点的时间:限界函数B(i)的计算时间
- 通过检验的节点数量:对于所有的i,满足Bi的X(k)的数目
抽象化控制
procedure RBACKTRACK(k) global X(1:n); int k, n; for ( 满足下式的每个X(k), X(k) 属于T(X(1)…X(k-1)) and B(X(1),…B(k))=true) do { if (X(1),…,X(k))是一条抵达答案结点的路径 then print (X(1)…X(k)); call RBACKTRACK(k+1); } end RBACKTRACK
分支限界法
与回溯法的区别:
- 回溯方法: 当前的E-结点R 一旦生成一个新的儿子结点C, 这个C结点就变成一个新的E-结点, 当检测完了子树C后, R结点就再次成为E-结点, 生成下一个儿子结点。(该方法也称为深度优先结点生成法)。
- 分支限界方法: 一个E-结点一直保持到变成死结点为止。它又分为两种方法: 宽度优先生成(队列方法)和D-检索(栈方法)。
LC检索:ĉ=f(h(X))+ĝ(X);
选取成本估计函数ĉ的值最小的活结点作为下一个E-结点。 伴有限界函数的LC-检索称为LC分枝-限界检索。
f(h(X))=结点X的级数,ĝ(X)=0时,则变为BFS检索。 f(h(X))=0,且每当Y是X的一个儿子时总有ĝ(X)≥ĝ(Y)时,则变为D-检索。
抽象化控制
T是一棵状态空间树
c是T中结点的成本函数
c(X)是根为X的子树中答案结点的最小成本
c(T)是T中最小成本答案结点的成本
line procedure LC(T, ĉ) If T是答案结点 then 输出T; return endif E←T 将活结点表初始化为空 loop for E的每个儿子X do if X是答案结点 then 输出从X到T的那条路径; return endif call ADD(X);PARENT(X)←E //把X加入活结点表 repeat if 不再有活结点 then print(“no answer node”); stop endif call LEAST(E) //选择ĉ最小的结点作为E-结点 repeat end LC
证明:
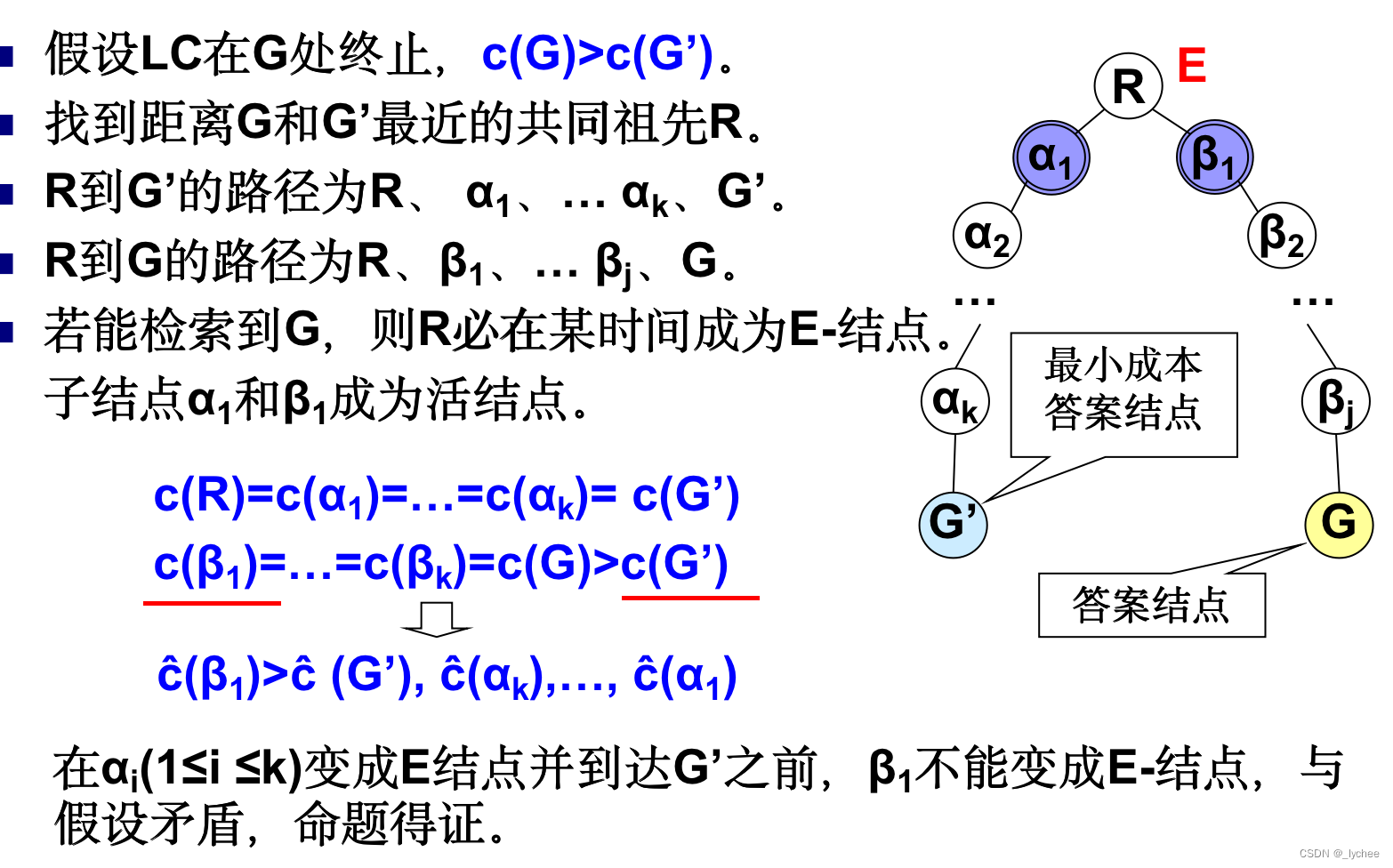
定理9.2 在有限状态空间树T中,对于每一个结点X,令ĉ(X)是c(X)的估计值且具有以下性质:对于每一对结点Y、Z,当且仅当c(Y)<c(Z)时有ĉ(Y)< ĉ(Z)。那么在使ĉ作为c的估计值时,算法LC到达一个最小的成本答案结点且终止。
一般只可能找到一个易于计算且具有如下特性的ĉ(.):对于每一个结点X,有ĉ(X) <=c(X)且对于答案结点X有ĉ(X) = c(X)。这显然不能保证算法LC找到最小成本答案结点。 因此将算法LC修改为LC1:
line procedure LC1(T, ĉ) E←T 将活结点表初始化为空 loop if E是答案结点 then 输出从E到T的那条路径; return endif for E的每个儿子X do call ADD(X);PARENT(X)←E repeat if 不再有活结点 then print(“no answer node”); stop endif call LEAST(E) repeat end LC1定理9.3 令ĉ是满足如下条件的函数,在状态空间树T中,对于每一个结点X,有ĉ(X)≤c(X) ,而对于T中的每一个答案结点X,有ĉ(X)=c(X)。如果算法在第5行终止,则所找到的答案结点是具有最小成本的答案结点。
证明:
结点E是答案结点,对于活结点表中的每一个结点L,一定有ĉ(E)≤ĉ(L)。由假设ĉ(E)=c(E)且对于每一个活结点L,ĉ(L)≤c(L) ,从而c(E)≤c(L),E是一个最小成本答案结点,
贪心习题
活动安排问题
设有n个活动的集合E={1,2,…,n},其中每个活动都要求使用同一资源,如演讲会场等,而在同一时间内只有一个活动能使用这一资源。每个活动i都有一个要求使用该资源的起始时间si和一个结束时间fi,且si <fi 。如果选择了活动i,则它在半开时间区间[si, fi)内占用资源。若区间[si, fi)与区间[sj, fj)不相交,则称活动i与活动j是相容的。也就是说,当si≥fj或sj≥fi时,活动i与活动j相容。
template< class Type>
void GreedySelector(int n, Type s[], Type f[], bool A[])
{//各活动的起始时间和结束时间存储于数组s和f中且按结束时间的非减
序排列
A[1]=true;//第一个活动先安排
int j=1;
for (int i=2;i<=n;i++) {
if (s[i]>=f[j]) { //满足约束条件
A[i]=true;
j=i;
}
else A[i]=false;
}
}连数
设有n个正整数 (n<=20), 将它们连接成一排, 组成一个最大的多位整数.
例如: n=3时, 3个整数13, 312, 343连接成的最大整数为: 34331213
又如: n=4时, 4个整数7,13,4,246连接成的最大整数为: 7424613
#include<bits/stdc++.h>
using namespace std;
bool cmp(string s1,string s2){
return s1+s2>s2+s1;//不能简单地s1>s2,因为202和20200,应该把202放前面
}
int main(){
int n;
string s[25];
cin>>n;
for(int i=0;i<n;i++){
cin>>s[i];
}
sort(s,s+n,cmp);
string ans;
for(int i=0;i<n;i++){
ans+=s[i];
}
cout<<ans<<endl;
}
分治习题
求逆序对
int count = 0; //记录逆序对数量
void Merge(int r[], int r1[], int low, int mid, int high) // 合并子序列
{
int i = low, j = mid + 1, k = low;
//int b;
while (i <= mid && j <= high) {
if (r[i] <= r[j]) { // 取较小者放入r1[k]中
r1[k++] = r[i++];
}
else {
count += mid - i + 1;// 若左子序列中的数1大于右子序列的数2,则数1后面的数都大于数2
r1[k++] = r[j++];
}
}
while (i <= mid) // 若第一个子序列没处理完,则进行收尾处理
r1[k++] = r[i++];
while (j <= high)
r1[k++] = r[j++];
}
void MergeSort(int r[], int low, int high) { // 进行归并排序
int mid, r1[1000], i;
if (low == high)
return;
else {
mid = (low + high) / 2; // 划分
MergeSort(r, low, mid); // 递归求左子序列中逆序对
MergeSort(r, mid + 1, high); // 递归求右子序列中逆序对
Merge(r, r1, low, mid, high); // 合并
for (i = low; i <= high; i++)
r[i] = r1[i];
}
}
找一枚假硬币
//减治法 Procedure Choose(low, mid,high) sum1=A[low+...mid-1] sum2=A[mid+...+high] if sum1<sum2 return -1; if sum2<sum1 return 1; return 0; end Procedure Find(n,j) integer A(1:N),j j=0;low=-1;high=n; while(low<high) do mid=(low+high)/2 temp=Choose(low, mid,high) case: -1:high=mid-1; 0:return; 1:low=mid+1; end case repeat j=low end
单峰数组
int find-peak(A[n])
low=1,high=n,mid=(low+high)/2;
while(low<high) do
if(A[mid-1]<A[mid]) then if(A[mid]>A[mid+1) return mid;
else low=mid
Endif
else high=mid
Endif
repeat
}














 8637
8637











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









