






目录
搭建开发环境
(springboot + mybatis + vue)
功能说明:操作用户表,做一个企业员工(用户)数据的导入导出
1.准备数据库
/*
Navicat MySQL Data Transfer
Source Server : 127.0.0.1
Source Server Version : 50727
Source Host : 127.0.0.1:3306
Source Database : report_manager_db
Target Server Type : MYSQL
Target Server Version : 50727
File Encoding : 65001
Date: 2020-03-21 22:06:35
*/
CREATE DATABASE /*!32312 IF NOT EXISTS*/`report_manager_db` /*!40100 DEFAULT CHARACTER SET utf8 */;
USE `report_manager_db`;
SET FOREIGN_KEY_CHECKS=0;
-- ----------------------------
-- Table structure for tb_dept
-- ----------------------------
DROP TABLE IF EXISTS `tb_dept`;
CREATE TABLE `tb_dept` (
`id` bigint(20) DEFAULT NULL COMMENT '部门编号',
`dept_name` varchar(100) DEFAULT NULL COMMENT '部门编号'
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of tb_dept
-- ----------------------------
INSERT INTO `tb_dept` VALUES ('5', '资产管理部');
INSERT INTO `tb_dept` VALUES ('6', '质量监察部');
INSERT INTO `tb_dept` VALUES ('7', '营销部');
INSERT INTO `tb_dept` VALUES ('1', '销售部');
INSERT INTO `tb_dept` VALUES ('2', '人事部');
INSERT INTO `tb_dept` VALUES ('3', '财务部');
INSERT INTO `tb_dept` VALUES ('4', '技术部');
-- ----------------------------
-- Table structure for tb_province
-- ----------------------------
DROP TABLE IF EXISTS `tb_province`;
CREATE TABLE `tb_province` (
`id` bigint(50) NOT NULL,
`name` varchar(100) DEFAULT NULL COMMENT '省份或直辖市或特别行政区名称',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of tb_province
-- ----------------------------
INSERT INTO `tb_province` VALUES ('1', '北京市');
INSERT INTO `tb_province` VALUES ('2', '天津市');
INSERT INTO `tb_province` VALUES ('3', '上海市');
INSERT INTO `tb_province` VALUES ('4', '重庆市');
INSERT INTO `tb_province` VALUES ('5', '河北省');
INSERT INTO `tb_province` VALUES ('6', '山西省');
INSERT INTO `tb_province` VALUES ('7', '辽宁省');
INSERT INTO `tb_province` VALUES ('8', '吉林省');
INSERT INTO `tb_province` VALUES ('9', '黑龙江省');
INSERT INTO `tb_province` VALUES ('10', '江苏省');
INSERT INTO `tb_province` VALUES ('11', '浙江省');
INSERT INTO `tb_province` VALUES ('12', '安徽省');
INSERT INTO `tb_province` VALUES ('13', '福建省');
INSERT INTO `tb_province` VALUES ('14', '江西省');
INSERT INTO `tb_province` VALUES ('15', '山东省');
INSERT INTO `tb_province` VALUES ('16', '河南省');
INSERT INTO `tb_province` VALUES ('17', '湖北省');
INSERT INTO `tb_province` VALUES ('18', '湖南省');
INSERT INTO `tb_province` VALUES ('19', '广东省');
INSERT INTO `tb_province` VALUES ('20', '海南省');
INSERT INTO `tb_province` VALUES ('21', '四川省');
INSERT INTO `tb_province` VALUES ('22', '贵州省');
INSERT INTO `tb_province` VALUES ('23', '云南省');
INSERT INTO `tb_province` VALUES ('24', '陕西省');
INSERT INTO `tb_province` VALUES ('25', '甘肃省');
INSERT INTO `tb_province` VALUES ('26', '青海省');
INSERT INTO `tb_province` VALUES ('27', '台湾省');
INSERT INTO `tb_province` VALUES ('28', '内蒙古自治区');
INSERT INTO `tb_province` VALUES ('29', '广西壮族自治区');
INSERT INTO `tb_province` VALUES ('30', '西藏自治区');
INSERT INTO `tb_province` VALUES ('31', '宁夏回族自治区');
INSERT INTO `tb_province` VALUES ('32', '新疆维吾尔自治区');
INSERT INTO `tb_province` VALUES ('33', '香港特别行政区');
INSERT INTO `tb_province` VALUES ('34', '澳门特别行政区');
-- ----------------------------
-- Table structure for tb_resource
-- ----------------------------
DROP TABLE IF EXISTS `tb_resource`;
CREATE TABLE `tb_resource` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`name` varchar(50) DEFAULT NULL,
`price` double(10,1) DEFAULT NULL,
`user_id` bigint(20) DEFAULT NULL,
`need_return` tinyint(1) DEFAULT NULL COMMENT '是否需要归还',
`photo` varchar(200) DEFAULT NULL COMMENT '照片',
PRIMARY KEY (`id`),
KEY `fk_user_id` (`user_id`),
CONSTRAINT `fk_user_id` FOREIGN KEY (`user_id`) REFERENCES `tb_user` (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of tb_resource
-- ----------------------------
INSERT INTO `tb_resource` VALUES ('1', '记录本', '2.0', '3', '0', '\\resource_photos\\3\\1.jpg');
INSERT INTO `tb_resource` VALUES ('2', '笔记本电脑', '7000.0', '3', '1', '\\resource_photos\\3\\2.jpg');
INSERT INTO `tb_resource` VALUES ('3', '办公桌', '1000.0', '3', '1', '\\resource_photos\\3\\3.jpg');
INSERT INTO `tb_resource` VALUES ('4', '订书机', '50.0', '4', '1', '\\resource_photos\\4\\1.jpg');
INSERT INTO `tb_resource` VALUES ('5', '双面胶带', '5.0', '4', '0', '\\resource_photos\\4\\2.jpg');
INSERT INTO `tb_resource` VALUES ('6', '资料文件夹', '10.0', '4', '0', '\\resource_photos\\4\\3.jpg');
INSERT INTO `tb_resource` VALUES ('7', '打印机', '1200.0', '4', '1', '\\resource_photos\\4\\4.jpg');
-- ----------------------------
-- Table structure for tb_user
-- ----------------------------
DROP TABLE IF EXISTS `tb_user`;
CREATE TABLE `tb_user` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '用户ID',
`user_name` varchar(100) DEFAULT NULL COMMENT '姓名',
`phone` varchar(15) DEFAULT NULL COMMENT '手机号',
`province` varchar(50) DEFAULT NULL COMMENT '省份',
`city` varchar(50) DEFAULT NULL COMMENT '城市',
`salary` int(10) DEFAULT NULL,
`hire_date` datetime DEFAULT NULL COMMENT '入职日期',
`dept_id` bigint(20) DEFAULT NULL COMMENT '部门编号',
`birthday` datetime DEFAULT NULL COMMENT '出生日期',
`photo` varchar(200) DEFAULT NULL COMMENT '照片路径',
`address` varchar(300) DEFAULT NULL COMMENT '现在住址',
PRIMARY KEY (`id`),
KEY `fk_dept` (`dept_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of tb_user
-- ----------------------------
INSERT INTO `tb_user` VALUES ('1', '大一', '13800000001', '北京市', '北京市', '11000', '2001-01-01 21:18:29', '1', '1981-03-02 00:00:00', '\\static\\user_photos\\1.jpg', '北京市西城区宣武大街1号院');
INSERT INTO `tb_user` VALUES ('2', '不二', '13800000002', '河北省', '石家庄市', '12000', '2002-01-02 21:18:29', '2', '1982-03-02 00:00:00', '\\static\\user_photos\\2.jpg', '北京市西城区宣武大街2号院');
INSERT INTO `tb_user` VALUES ('3', '张三', '13800000003', '河北省', '石家庄市', '13000', '2003-03-03 21:18:29', '3', '1983-03-02 00:00:00', '\\static\\user_photos\\3.jpg', '北京市西城区宣武大街3号院');
INSERT INTO `tb_user` VALUES ('4', '李四', '13800000004', '河北省', '石家庄市', '14000', '2004-02-04 21:18:29', '4', '1984-03-02 00:00:00', '\\static\\user_photos\\4.jpg', '北京市西城区宣武大街4号院');
INSERT INTO `tb_user` VALUES ('5', '王五', '13800000005', '河北省', '唐山市', '15000', '2005-03-05 21:18:29', '5', '1985-03-02 00:00:00', '\\static\\user_photos\\5.jpg', '北京市西城区宣武大街5号院');
INSERT INTO `tb_user` VALUES ('6', '赵六', '13800000006', '河北省', '承德市省', '16000', '2006-04-06 21:18:29', '6', '1986-03-02 00:00:00', '\\static\\user_photos\\6.jpg', '北京市西城区宣武大街6号院');
INSERT INTO `tb_user` VALUES ('7', '沈七', '13800000007', '河北省', '秦皇岛市', '17000', '2007-06-07 21:18:29', '7', '1987-03-02 00:00:00', '\\static\\user_photos\\7.jpg', '北京市西城区宣武大街7号院');
INSERT INTO `tb_user` VALUES ('8', '酒八', '13800000008', '河北省', '秦皇岛市', '18000', '2008-07-08 21:18:29', '6', '1988-03-02 00:00:00', '\\static\\user_photos\\8.jpg', '北京市西城区宣武大街8号院');
INSERT INTO `tb_user` VALUES ('9', '第九', '13800000009', '山东省', '德州市', '19000', '2009-03-09 21:18:29', '1', '1989-03-02 00:00:00', '\\static\\user_photos\\9.jpg', '北京市西城区宣武大街9号院');
INSERT INTO `tb_user` VALUES ('10', '石十', '13800000010', '山东省', '青岛市', '20000', '2010-07-10 21:18:29', '4', '1990-03-02 00:00:00', '\\static\\user_photos\\10.jpg', '北京市西城区宣武大街10号院');
INSERT INTO `tb_user` VALUES ('11', '肖十一', '13800000011', '山东省', '青岛市', '21000', '2011-12-11 21:18:29', '4', '1991-03-02 00:00:00', '\\static\\user_photos\\11.jpg', '北京市西城区宣武大街11号院');
INSERT INTO `tb_user` VALUES ('12', '星十二', '13800000012', '山东省', '青岛市', '22000', '2012-05-12 21:18:29', '4', '1992-03-02 00:00:00', '\\static\\user_photos\\12.jpg', '北京市西城区宣武大街12号院');
INSERT INTO `tb_user` VALUES ('13', '钗十三', '13800000013', '山东省', '济南市', '23000', '2013-06-13 21:18:29', '3', '1993-03-02 00:00:00', '\\static\\user_photos\\13.jpg', '北京市西城区宣武大街13号院');
INSERT INTO `tb_user` VALUES ('14', '贾十四', '13800000014', '山东省', '威海市', '24000', '2014-06-14 21:18:29', '2', '1994-03-02 00:00:00', '\\static\\user_photos\\14.jpg', '北京市西城区宣武大街14号院');
INSERT INTO `tb_user` VALUES ('15', '甄世武', '13800000015', '山东省', '济南市', '25000', '2015-06-15 21:18:29', '4', '1995-03-02 00:00:00', '\\static\\user_photos\\15.jpg', '北京市西城区宣武大街15号院');
-- ----------------------------
-- Table structure for tb_month
-- ----------------------------
DROP TABLE IF EXISTS `tb_month`;
CREATE TABLE `tb_month` (
`name` varchar(2) DEFAULT NULL COMMENT '月份'
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of tb_month
-- ----------------------------
INSERT INTO `tb_month` VALUES ('01');
INSERT INTO `tb_month` VALUES ('02');
INSERT INTO `tb_month` VALUES ('03');
INSERT INTO `tb_month` VALUES ('04');
INSERT INTO `tb_month` VALUES ('05');
INSERT INTO `tb_month` VALUES ('06');
INSERT INTO `tb_month` VALUES ('07');
INSERT INTO `tb_month` VALUES ('08');
INSERT INTO `tb_month` VALUES ('09');
INSERT INTO `tb_month` VALUES ('10');
INSERT INTO `tb_month` VALUES ('11');
INSERT INTO `tb_month` VALUES ('12');2.导入项目
导入后结构如下
3.启动引导类,在浏览器中访问localhost:8080/list.html
Excel说明
在企业级应用开发中,Excel报表是一种最长金的报表需求,Excel报表开发一般分为两种形式:
1、为了方便操作,基于Excel的报表批量上传数据,也就是把Excel中的数据导入到系统中
2、通过java代码生成Excel报表。也就是把系统中的数据导出到Excel中,方便查阅
Excel的版本
-
Excel2003是一个特有的二进制格式,其核心结构是符合文档类型的结构,存储数据量较小
-
Excel2007的核心结构是XML类型的结构,采用的是基于XML的压缩方式,使其占用的空间更小
常见的Excel操作工具
java中常见的用来操作Excel的方式一般有两种:JXL和POI
JXL(跳过)
JXL只能对Excel进行操作,属于比较老的框架,它只支持到Excel 95-2000的版本。JXL现在已经停止更新,用JXL做项目已经比较少见
POI
POI是apache的项目,可对微软的Word,Excel,PPT进行操作,包括office2003和2007,Excle2003和2007。 poi现在一直有更新。所以现在主流使用POI。
API对象介绍 工作簿 : WorkBook (HSSFWordBook : 2003版本,XSSFWorkBook : 2007级以上) 工作表 : Sheet (HSSFSheet : 2003版本,XSSFSheet : 2007级以上) 行 : Row (HSSFRow : 2003版本,XSSFRow : 2007级以上) 单元格 : Cell (HSSFCell : 2003版本,XSSFCell : 2007级以上)
POI操作Excel
所需依赖:
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>4.0.1</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>4.0.1</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml-schemas</artifactId>
<version>4.0.1</version>
</dependency>POI操作Excel高低版本区别
在poi包中有如下几个主要对象和excel的几个对象对应:
| 对应excel名称 | 低版本中的类名 | 高版本中的类名 |
|---|---|---|
| 工作簿 | HSSFWorkbook | XSSFWorkbook |
| 工作表 | HSSFSheet | XSSFSheet |
| 行 | HSSFRow | XSSFRow |
| 单元格 | HSSFCell | XSSFCell |
| 单元格样式 | HSSFCellStyle | XSSFCellStyle |
入门案例:创建一个新的工作簿,里面随便写一句话
public class POIDemo01 {
// 操作高版本和低版本只是类的名称不一样,方法s
public static void main(String[] args) throws IOException {
XSSFWorkbook workbook = new XSSFWorkbook();//创建一个全新的工作簿
XSSFSheet sheet = workbook.createSheet("测试");//创建一个全新的工作表
XSSFRow row = sheet.createRow(0);//创建了第一行
XSSFCell cell = row.createCell(0);//创建了第一行的第一个单元格
cell.setCellValue("这是我第一次玩poi");
//把工作簿输出到本地磁盘
workbook.write(new FileOutputStream("D:\\temp\\a.xlsx"));
}
}
结果:

实现用户数据的导入
需求:把excel文档中的数据导入到系统中
内容如下:
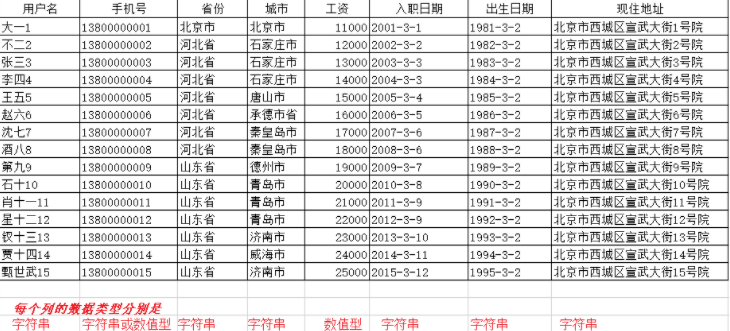
数据的导入就是读取excel中的内容,转成对象插入到数据库中
思路:
一般来说,即将导入的文件,每个列代表什么意思基本上都是固定的,比如第一列是用户姓名,最后一列是用户住址,并且在做excel时对每个列的类型都是有要求的,这样就可以给我们开发带来很大的简便
最终目标就是读取每一行数据,把数据转成用户的对象,保存到表中
实现步骤:
-
根据上传的文件创建Workbook
-
获取到第一个sheet工作表
-
从第二行开始读取数据
-
读取每一个单元格,把内容放到用户对象的相关属性中
代码实现
controller中接收excel文件,将文件交给userService进行处理
@PostMapping(value = "/uploadExcel",name = "上传用户数据")
public void uploadExcel(MultipartFile file) throws Exception{
userService.uploadExcel(file);
}service层upload方法实现:
// 上传用户数据
public void uploadExcel(MultipartFile file) throws Exception {
// 有内容的workbook工作薄
Workbook workbook = new XSSFWorkbook(file.getInputStream());
// 获取到第一个工作表
Sheet sheet = workbook.getSheetAt(0);
int lastRowIndex = sheet.getLastRowNum();//当前sheet的最后一行的索引值
// 读取工作表中的内容
Row row = null;
User user = null;
for (int i = 1; i <= lastRowIndex; i++) {
row = sheet.getRow(i);
// 用户名 手机号 省份 城市 工资 入职日期 出生日期 现住地址
String userName = row.getCell(0).getStringCellValue(); //用户名
String phone = null; //手机号
try {
phone = row.getCell(1).getStringCellValue();
} catch (Exception e) {
phone = row.getCell(1).getNumericCellValue() + "";
}
String province = row.getCell(2).getStringCellValue(); //省份
String city = row.getCell(3).getStringCellValue(); //城市
Integer salary = ((Double) row.getCell(4).getNumericCellValue()).intValue(); //工资
Date hireDate = simpleDateFormat.parse(row.getCell(5).getStringCellValue()); //入职日期
Date birthDay = simpleDateFormat.parse(row.getCell(6).getStringCellValue()); //出生日期
String address = row.getCell(7).getStringCellValue(); //现住地址
System.out.println(userName + ":" + phone + ":" + province + ":" + city + ":" + salary + ":" + hireDate + ":" + birthDay + ":" + address);
user = new User();
user.setUserName(userName);
user.setPhone(phone);
user.setProvince(province);
user.setCity(city);
user.setSalary(salary);
user.setHireDate(hireDate);
user.setBirthday(birthDay);
user.setAddress(address);
// 执行插入user方法
userMapper.insert(user);
}
}使用POI导出
需求:做一个简单的excel的导出,不要求有什么样式
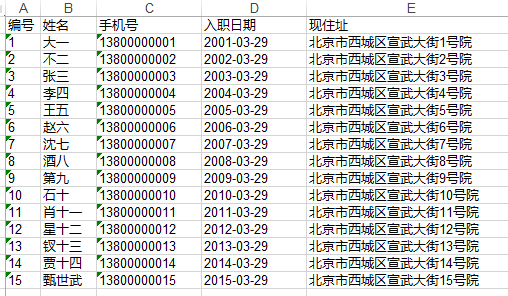
基本思路
-
创建一个全新的工作簿
-
在新的工作簿中创建一个新的工作表
-
在工作表中创建第一行作为标题行,标题固定
-
从第二行循环遍历创建,有多少条用户数据就应该创建多少行
-
把每一个user对象的属性放入到相应的单元格中
代码实现
在controller中添加方法,将response作为参数交给userService的具体实现方法,由service层的方法实现具体的导出
@GetMapping(value = "/downLoadXlsxByPoi",name = "使用POI导出用户数据")
public void downLoadXlsxByPoi(HttpServletResponse response) throws Exception{
userService.downLoadXlsxByPoi(response);
}service层downLoadXlsxByPoi方法实现:
// 使用POI导出用户列表数据
public void downLoadXlsxByPoi(HttpServletResponse response) throws Exception {
// 1、创建一个全新的工作薄
Workbook workbook = new XSSFWorkbook("");
// 2、创建全新的工作表
Sheet sheet = workbook.createSheet("用户数据");
// 设置列宽 第一个参数位列的索引
sheet.setColumnWidth(0, 5 * 256); //第二个参数为列的宽度,一个标准字母的宽度为256
sheet.setColumnWidth(1, 8 * 256);
sheet.setColumnWidth(2, 15 * 256);
sheet.setColumnWidth(3, 15 * 256);
sheet.setColumnWidth(4, 30 * 256);
// 3、处理固定的标题 编号 姓名 手机号 入职日期 现住址
String[] titles = new String[]{"编号", "姓名", "手机号", "入职日期", "现住址"};
Row titleRow = sheet.createRow(0);
Cell cell = null;
for (int i = 0; i < 5; i++) {
cell = titleRow.createCell(i);
cell.setCellValue(titles[i]);
}
// 4、从第二行开始循环遍历 向单元格中放入数据
List<User> userList = userMapper.selectAll();
int rowIndex = 1;
Row row = null;
for (User user : userList) {
row = sheet.createRow(rowIndex);
// 编号 姓名 手机号 入职日期 现住址
cell = row.createCell(0);
cell.setCellValue(user.getId());
cell = row.createCell(1);
cell.setCellValue(user.getUserName());
cell = row.createCell(2);
cell.setCellValue(user.getPhone());
cell = row.createCell(3);
cell.setCellValue(simpleDateFormat.format(user.getHireDate()));
cell = row.createCell(4);
cell.setCellValue(user.getAddress());
rowIndex++;
}
// 一个流两个头
String filename = "员工数据.xlsx";
response.setHeader("content-disposition", "attachment;filename=" + new String(filename.getBytes(), "ISO8859-1"));
response.setContentType("application/vnd.openxmlformats-officedocument.spreadsheetml.sheet");
workbook.write(response.getOutputStream());
}基于模板导出列表数据
需求:按照如下样式导出excel
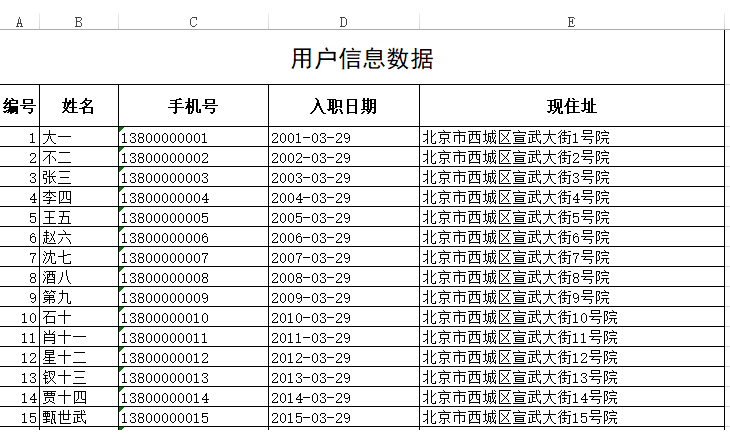
思路:准备一个excel模板,放入到项目中,然后读取到模板后向里面放入数据
实现:
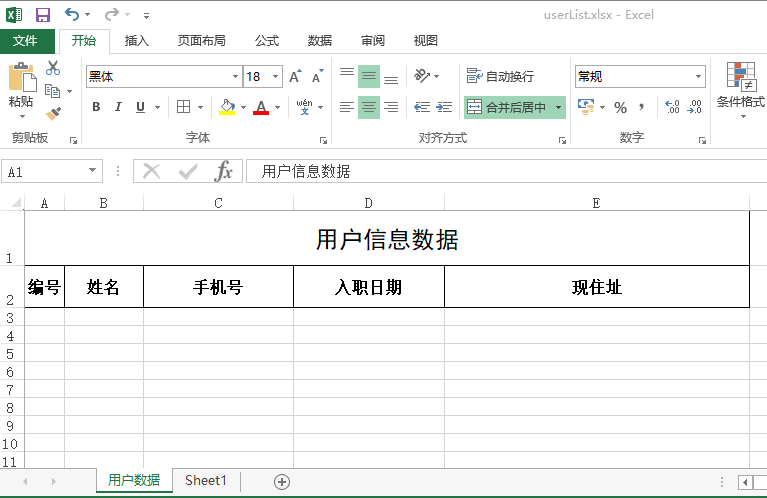
第一步:准备一个excel作为导出的模板,模板内容如下
第一个sheet
第二个sheet
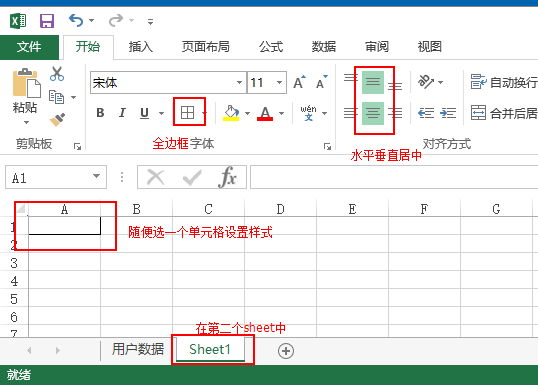
第二步:将模板改为英文名,放入项目中
第三步:在Userservice中实现方法
/**
* 使用poi导出用户列表数据 根据模板的样式导出
* 第二个sheet用于存放需要的样式
*/
public void downLoadXlsxByPoiWithTemplate(HttpServletResponse response) throws Exception {
// 1、获取到模板
File rootFile = new File(ResourceUtils.getURL("classpath:").getPath()); //获取项目的根目录
File templateFile = new File(rootFile, "/excel_template/userList.xlsx");
Workbook workbook = new XSSFWorkbook(templateFile);
// 2、查询所有的用户数据
List<User> userList = userMapper.selectAll();
// 3、放入到模板中
Sheet sheet = workbook.getSheetAt(0);
// 获取准备好的内容单元格的样式 第2个sheet的第一行的第一个单元格中
CellStyle contentRowCellStyle = workbook.getSheetAt(1).getRow(0).getCell(0).getCellStyle();
int rowIndex = 2;
Row row = null;
Cell cell = null;
for (User user : userList) {
row = sheet.createRow(rowIndex);
row.setHeightInPoints(15);
cell = row.createCell(0);
cell.setCellStyle(contentRowCellStyle);
cell.setCellValue(user.getId());
cell = row.createCell(1);
cell.setCellStyle(contentRowCellStyle);
cell.setCellValue(user.getUserName());
cell = row.createCell(2);
cell.setCellStyle(contentRowCellStyle);
cell.setCellValue(user.getPhone());
cell = row.createCell(3);
cell.setCellStyle(contentRowCellStyle);
cell.setCellValue(simpleDateFormat.format(user.getHireDate()));
cell = row.createCell(4);
cell.setCellStyle(contentRowCellStyle);
cell.setCellValue(user.getAddress());
rowIndex++;
}
// 把第二个sheet删除
workbook.removeSheetAt(1);
// 4、导出文件
String filename = "员工数据.xlsx";
response.setHeader("content-disposition", "attachment;filename=" + new String(filename.getBytes(), "ISO8859-1"));
response.setContentType("application/vnd.openxmlformats-officedocument.spreadsheetml.sheet");
workbook.write(response.getOutputStream());
}导出用户详细数据
点击用户列表中的下载按钮,下载文件内容如下

思路:最简单的方式就是先根据案例制作模板,导出时查询用户数据、读取模板,把数据放入到模板中对应的单元格中,其中先处理最基本的数据,稍后再处理图片
实现
第一步:制作一个excel导出模板,如下

第二步:将制作好的模板放入到项目中
第三步:再Controller中添加方法
@GetMapping(value = "/download",name = "使用POI导出用户详细数据")
public void downloadUserInfoByTemplate(Long id,HttpServletResponse response) throws Exception{
userService.downloadUserInfoByTemplate(id,response);
}第四步:再UserService中添加方法
```java
public void downloadUserInfoByTemplate(Long id, HttpServletResponse response) throws Exception {
// 1、获取到模板
File rootFile = new File(ResourceUtils.getURL("classpath:").getPath()); //获取项目的根目录
File templateFile = new File(rootFile, "/excel_template/userInfo.xlsx");
Workbook workbook = new XSSFWorkbook(templateFile);
Sheet sheet = workbook.getSheetAt(0);
// 2、根据ID获取某一个用户数据
User user = userMapper.selectByPrimaryKey(id);
// 3、把用户数据放入到模板中
// 用户名 第2行第2列
sheet.getRow(1).getCell(1).setCellValue(user.getUserName());
// 手机号 第3行第2列
sheet.getRow(2).getCell(1).setCellValue(user.getPhone());
// 生日 第4行第2列
sheet.getRow(3).getCell(1).setCellValue(simpleDateFormat.format(user.getBirthday()));
// 工资 第5行第2列
sheet.getRow(4).getCell(1).setCellValue(user.getSalary());
// 入职日期 第6行第2列
sheet.getRow(5).getCell(1).setCellValue(simpleDateFormat.format(user.getHireDate()));
// 省份 第7行第2列
sheet.getRow(6).getCell(1).setCellValue(user.getProvince());
// 现住址 第8行第2列
sheet.getRow(7).getCell(1).setCellValue(user.getAddress());
// 司龄 第6行第4列 使用公式稍后处理 =CONCATENATE(DATEDIF(B6,TODAY(),"Y"),"年",DATEDIF(B6,TODAY(),"YM"),"个月")
// sheet.getRow(5).getCell(3).setCellFormula("CONCATENATE(DATEDIF(B6,TODAY(),\"Y\"),\"年\",DATEDIF(B6,TODAY(),\"YM\"),\"个月\")");
// 城市 第7行第4列
sheet.getRow(6).getCell(3).setCellValue(user.getCity());
// 照片的位置
// 开始处理照片
// 先创建一个字节输出流
ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();
// 读取图片 放入了一个带有缓存区的图片类中
BufferedImage bufferedImage = ImageIO.read(new File(rootFile, user.getPhoto()));
// 把图片写入到了字节输出流中
// user.getPhoto()
String extName = user.getPhoto().substring( user.getPhoto().lastIndexOf(".")+1).toUpperCase();
ImageIO.write(bufferedImage,extName,byteArrayOutputStream);
// Patriarch 控制图片的写入 和ClientAnchor 指定图片的位置
Drawing patriarch = sheet.createDrawingPatriarch();
// 指定图片的位置 开始列3 开始行2 结束列4 结束行5
// 偏移的单位:是一个英式公制的单位 1厘米=360000
ClientAnchor anchor = new XSSFClientAnchor(0,0,0,0,2,1,4,5);
// 开始把图片写入到sheet指定的位置
int format = 0;
switch (extName){
case "JPG":{
format = XSSFWorkbook.PICTURE_TYPE_JPEG;
}
case "JPEG":{
format = XSSFWorkbook.PICTURE_TYPE_JPEG;
}
case "PNG":{
format = XSSFWorkbook.PICTURE_TYPE_PNG;
}
}
patriarch.createPicture(anchor,workbook.addPicture(byteArrayOutputStream.toByteArray(),format));
// 处理照片结束
// 4、导出文件
String filename = "员工(" + user.getUserName() + ")详细数据.xlsx";
response.setHeader("content-disposition", "attachment;filename=" + new String(filename.getBytes(), "ISO8859-1"));
response.setContentType("application/vnd.openxmlformats-officedocument.spreadsheetml.sheet");
workbook.write(response.getOutputStream());
}
```
自定义导出详细数据的引擎
说明:使用上面的方法导出数据时,必须要提前知道要到处数据再哪一行哪一个单元格,但是如果模板一旦发生调整,那么我们的java代码必须要修改,我们可以自定义导出的引擎,有了这个引擎即使模板修改了,我们的java代码也不用修改
思路:在制作模板时,在需要插入数据的位置做上标记,在导出时,对象的属性要和标记做对应,如果对应匹配一样,就把值赋值到相应位置
第一步:制作模板,将模板文件添加到项目中
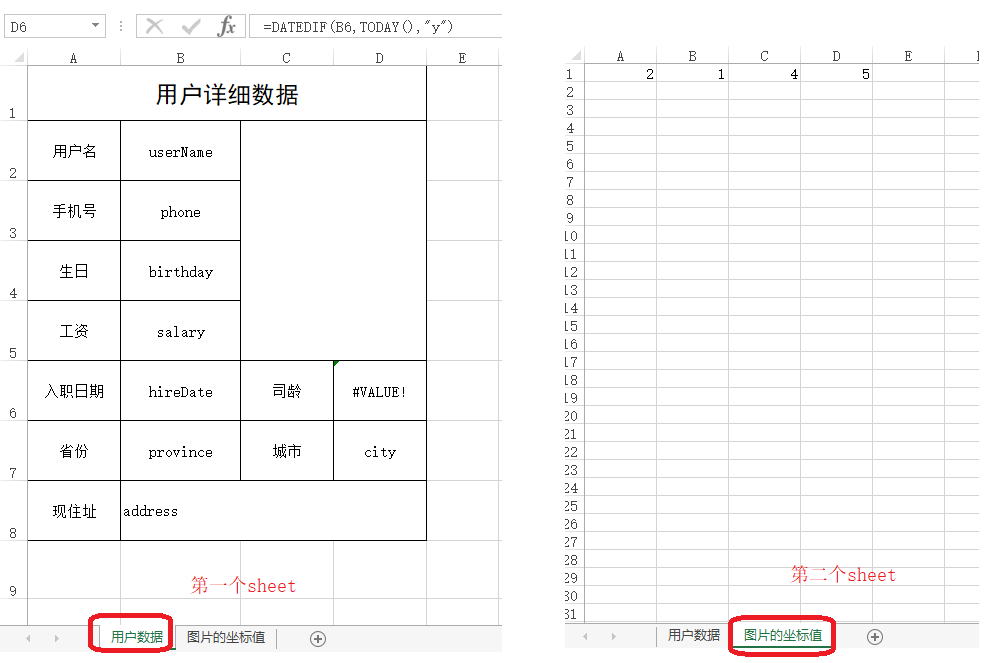
模板中添加了username、phone、birthday等用于标记,后台通过标记判断应该填入什么数据
图片的坐标可以写入到第二个sheet中,后台获取起始坐标结束坐标,如何把图片字节流写入到图片中
第二部:实现导出的引擎代码
public class ExcelExportEngine {
public static Workbook writeToExcel(Object object,Workbook workbook,String imagePath) throws Exception{
// 把一个Bean转成map
Map<String, Object> map = EntityUtils.entityToMap(object);
Sheet sheet = workbook.getSheetAt(0);
// 循环100行,每一行循环100个单元格
Row row = null;
Cell cell = null;
for (int i = 0; i < 100; i++) {
row = sheet.getRow(i);
if(row==null){
break;
}else{
for (int j = 0; j < 100; j++) {
cell = row.getCell(j);
if(cell!=null){
writeToCell(cell,map);
}
}
}
}
if(imagePath!=null){
// 开始处理照片
// 先创建一个字节输出流
ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();
// 读取图片 放入了一个带有缓存区的图片类中
BufferedImage bufferedImage = ImageIO.read(new File(imagePath));
// 把图片写入到了字节输出流中
// user.getPhoto()
String extName = imagePath.substring( imagePath.lastIndexOf(".")+1).toUpperCase();
ImageIO.write(bufferedImage,extName,byteArrayOutputStream);
// Patriarch 控制图片的写入 和ClientAnchor 指定图片的位置
Drawing patriarch = sheet.createDrawingPatriarch();
// 指定图片的位置 开始列3 开始行2 结束列4 结束行5
// 偏移的单位:是一个英式公制的单位 1厘米=360000
Sheet sheet1 = workbook.getSheetAt(1);
int col1 = ((Double)sheet1.getRow(0).getCell(0).getNumericCellValue()).intValue();
int row1 = ((Double)sheet1.getRow(0).getCell(1).getNumericCellValue()).intValue();
int col2 = ((Double)sheet1.getRow(0).getCell(2).getNumericCellValue()).intValue();
int row2 = ((Double)sheet1.getRow(0).getCell(3).getNumericCellValue()).intValue();
ClientAnchor anchor = new XSSFClientAnchor(0,0,0,0,col1,row1,col2,row2);
// 开始把图片写入到sheet指定的位置
int format = 0;
switch (extName){
case "JPG":{
format = XSSFWorkbook.PICTURE_TYPE_JPEG;
}
case "JPEG":{
format = XSSFWorkbook.PICTURE_TYPE_JPEG;
}
case "PNG":{
format = XSSFWorkbook.PICTURE_TYPE_PNG;
}
}
patriarch.createPicture(anchor,workbook.addPicture(byteArrayOutputStream.toByteArray(),format));
workbook.removeSheetAt(1);
}
return workbook;
}
// 比较单元格中的值,是否和map中的key一致,如果一致向单元格中放入map这个key对应的值
private static void writeToCell(Cell cell, Map<String, Object> map) {
CellType cellType = cell.getCellType();
switch (cellType){
case FORMULA:{
break;
}default:{
String cellValue = cell.getStringCellValue();
if (StringUtils.isNotBlank(cellValue)){
for (String key : map.keySet()) {
if(key.equals(cellValue)){
cell.setCellValue(map.get(key).toString());
}
}
}
}
}
}
}
第三步:修改UserService中的方法
public void downloadUserInfoByTemplate2(Long id, HttpServletResponse response) throws Exception {
// 1、获取模板
File rootFile = new File(ResourceUtils.getURL("classpath:").getPath()); //获取项目的根目录
File templateFile = new File(rootFile, "/excel_template/userInfo2.xlsx");
Workbook workbook = new XSSFWorkbook(templateFile);
// 2、根据ID获取某一个用户数据
User user = userMapper.selectByPrimaryKey(id);
// 3、通过自定义的引擎放入数据
workbook = ExcelExportEngine.writeToExcel(user,workbook, rootFile.getPath()+ user.getPhoto());
// 4 导出文件
String filename = "员工(" + user.getUserName() + ")详细数据.xlsx";
response.setHeader("content-disposition", "attachment;filename=" + new String(filename.getBytes(), "ISO8859-1"));
response.setContentType("application/vnd.openxmlformats-officedocument.spreadsheetml.sheet");
workbook.write(response.getOutputStream());
}
百万数据导出
概述
Excel 2003:在POI中使用HSSF对象时,excel2003最多只允许存储65536条数据,一般用来处理较少的数据量。这时对于百万级别数据,excel肯定处理不了
Excel 2007:当POI升级到XSSF对象时,它可以直接支持excel2007以上版本,因为它采用ooxml格式。这时excel可以支持1048576条数据,单个sheet表就支持近百万条数据。但实际运行时还可能存在问题,原因是执行POI报表所产生的行对象,单元格对象,字体对象,他们都不会销毁这就导致OOM的风险
解决方案分析
对于百万数据量的excel导入导出,只讨论基于excel2007的解决方案。在ApahcePoi官方提供了对操作大数据量的导入导出的工具和解决办法,操作excel2007使用XSSF对象,可以分为三种模式:
java代码解析xml
dom4j:一次性加载xml文件再解析
SAX:逐行加载xml文件再解析
用户模式:用户模式有许多封装好的方法操作简单,但创建太多对象,非常耗内存
事件模式:基于SAX方式解析XML,SAX全程Simple API for XML,它是一个接口,也是一个软件包。它是一种xml解析的替代方法,不同于dom解析xml文档时把所有内容一次性加载到内存中的方案,它逐行扫描文档,一边扫描,一边解析
SXSSF对象:是用来生成海量excel数据文件,主要原理是借助临时存储空间生成excel
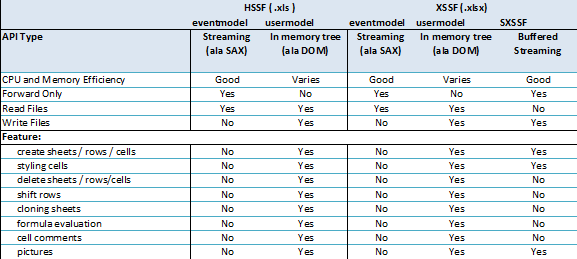
原理分析
在实例化SXSSFWorkBook这个对象时,可以指定在内存中所产生的POI导出相关对象的数量(默认100),一旦内存中的对象的个数达到这个指定值时,就将内存中的这些对象的内容写入到磁盘中(XML的文件格式),就可以将这些对象从内存中销毁,以后只要达到这个值,就会以类似的处理方式处理,直至Excel导出完成。
百万数据的导出
模拟数据
1、创建表
CREATE TABLE `tb_user2` (
`id` bigint(20) NOT NULL COMMENT '用户ID',
`user_name` varchar(100) DEFAULT NULL COMMENT '姓名',
`phone` varchar(15) DEFAULT NULL COMMENT '手机号',
`province` varchar(50) DEFAULT NULL COMMENT '省份',
`city` varchar(50) DEFAULT NULL COMMENT '城市',
`salary` int(10) DEFAULT NULL,
`hire_date` datetime DEFAULT NULL COMMENT '入职日期',
`dept_id` bigint(20) DEFAULT NULL COMMENT '部门编号',
`birthday` datetime DEFAULT NULL COMMENT '出生日期',
`photo` varchar(200) DEFAULT NULL COMMENT '照片路径',
`address` varchar(300) DEFAULT NULL COMMENT '现在住址'
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
2、创建存储过程
DELIMITER $$ -- 重新定义“;”分号
DROP PROCEDURE IF EXISTS test_insert $$ -- 如果有test_insert这个存储过程就删除
CREATE PROCEDURE test_insert() -- 创建存储过程
BEGIN
DECLARE n int DEFAULT 1; -- 定义变量n=1
SET AUTOCOMMIT=0; -- 取消自动提交
while n <= 5000000 do
INSERT INTO `tb_user2` VALUES ( n, CONCAT('测试', n), '13800000001', '北京市', '北京市', '11000', '2001-03-01 21:18:29', '1', '1981-03-02 00:00:00', '\\static\\user_photos\\1.jpg', '北京市西城区宣武大街1号院');
SET n=n+1;
END while;
COMMIT;
END $$3、开始执行
CALL test_insert();插入500w数据大概需要200到300秒左右
思路分析
导出时使用的是SXSSFWorkBook这个类,一个工作表sheet最多只能放1048576行数据, 当我们的业务数据已超过100万了,一个sheet就不够用了,必须拆分到多个工作表。
导出百万数据时有两个弊端:
1、不能使用模板
2、不能使用太多的样式
也就是说导出的数据太多时必须要放弃一些。
代码实现
UserController代码
@GetMapping(value = "/downLoadMillion",name = "导出百万数据")
public void downLoadMillion(HttpServletResponse response) throws Exception{
userService.downLoadMillion(response);
}UserServce代码
// 百万数据的导出 1、肯定使用高版本的excel 2、使用sax方式解析Excel(XML)
// 限制:1、不能使用模板 2、不能使用太多的样式
public void downLoadMillion(HttpServletResponse response) throws Exception {
// 指定使用的是sax方式解析
Workbook workbook = new SXSSFWorkbook(); //sax方式就是逐行解析
// Workbook workbook = new XSSFWorkbook(); //dom4j的方式
// 导出500W条数据 不可能放到同一个sheet中 规定:每个sheet不能超过100W条数据
int page = 1;
int num = 0 ;// 记录了处理数据的个数
int rowIndex = 1; //记录的是每个sheet的行索引
Row row = null;
Sheet sheet = null;
while (true){
List<User> userList = this.findPage(page, 100000);
if(CollectionUtils.isEmpty(userList)){
break; //用户数据为空 跳出循环
}
// 0 1000000 2000000 3000000 4000000 5000000
if(num%1000000==0){ //表示应该创建新的标题
sheet = workbook.createSheet("第"+((num/1000000)+1)+"个工作表");
rowIndex = 1; //每个sheet中的行索引重置
// 设置小标题
// 编号 姓名 手机号 入职日期 现住址
String[] titles = new String[]{"编号","姓名","手机号","入职日期","现住址"};
Row titleRow = sheet.createRow(0);
for (int i = 0; i < 5; i++) {
titleRow.createCell(i).setCellValue(titles[i]);
}
}
for (User user : userList) {
row = sheet.createRow(rowIndex);
row.createCell(0).setCellValue(user.getId());
row.createCell(1).setCellValue(user.getUserName());
row.createCell(2).setCellValue(user.getPhone());
row.createCell(3).setCellValue(simpleDateFormat.format(user.getHireDate()));
row.createCell(4).setCellValue(user.getAddress());
rowIndex++;
num++;
}
page++; //当前页码加1
}
String filename = "百万用户数据的导出.xlsx";
response.setHeader("content-disposition", "attachment;filename=" + new String(filename.getBytes(), "ISO8859-1"));
response.setContentType("application/vnd.openxmlformats-officedocument.spreadsheetml.sheet");
workbook.write(response.getOutputStream());
}百万数据导入数据库
需求:使用POI基于事件模式解析案例提供的Excel文件
思路分析
用户模式:加载并读取Excel时,是通过一次性的将所有数据加载到内存中再去解析每个单元格内容。当Excel数据量较大时,由于不同的运行环境可能会造成内存不足甚至OOM异常
事件模式:逐行扫描文件,一边扫描一遍解析。由于应用程序只是在读取数据时检查数据,因此不需要将数据存储在内存中,这对于大型文档的解析是个巨大优势
代码实现
步骤分析
-
设置POI的事件模式
-
根据Excel获取文件流
-
根据文件流创建OPCPackage用来组合读取到的xml 组合出来的数据占用空间更少
-
创建XSSFReader对象
-
-
Sax解析
-
自定义Sheet处理器
-
创建Sax的XmlReader对象
-
设置Sheet的时间处理器
-
逐行读取
-
自定义处理器
public class SheetHandler implements XSSFSheetXMLHandler.SheetContentsHandler {
// 编号 用户名 手机号 入职日期 现住址
private User user=null;
@Override
public void startRow(int rowIndex) { //每一行的开始 rowIndex代表的是每一个sheet的行索引
if(rowIndex==0){
user = null;
}else{
user = new User();
}
}
@Override //处理每一行的所有单元格
public void cell(String cellName, String cellValue, XSSFComment comment) {
if(user!=null){
String letter = cellName.substring(0, 1); //每个单元名称的首字母 A B C
switch (letter){
case "A":{
user.setId(Long.parseLong(cellValue));
break;
}
case "B":{
user.setUserName(cellValue);
break;
}
}
}
}
@Override
public void endRow(int rowIndex) { //每一行的结束
if(rowIndex!=0){
System.out.println(user);
}
}
}自定义解析
public class ExcelParser {
public void parse (String path) throws Exception {
//1.根据Excel获取OPCPackage对象
OPCPackage pkg = OPCPackage.open(path, PackageAccess.READ);
try {
//2.创建XSSFReader对象
XSSFReader reader = new XSSFReader(pkg);
//3.获取SharedStringsTable对象
SharedStringsTable sst = reader.getSharedStringsTable();
//4.获取StylesTable对象
StylesTable styles = reader.getStylesTable();
XMLReader parser = XMLReaderFactory.createXMLReader();
// 处理公共属性:Sheet名,Sheet合并单元格
parser.setContentHandler(new XSSFSheetXMLHandler(styles,sst, new SheetHandler(), false));
XSSFReader.SheetIterator sheets = (XSSFReader.SheetIterator) reader.getSheetsData();
while (sheets.hasNext()) {
InputStream sheetstream = sheets.next();
InputSource sheetSource = new InputSource(sheetstream);
try {
parser.parse(sheetSource);
} finally {
sheetstream.close();
}
}
} finally {
pkg.close();
}
}
}
测试
public class POIDemo5 {
public static void main(String[] args) throws Exception{
new ExcelParser().parse("C:\\Users\\syl\\Desktop\\百万用户数据的导出.xlsx");
}
} opencsv操作csv文件
CSV文件简介
CSV文件:Comma-Separated Values,中文叫逗号分隔符或者字符分隔符,其文件以纯文本的形式存储表格数据。该文件是一个字符序列,可以由任意数目的记录组成,记录间以某种换行符分割。每条记录由字段组成,字段间的分隔符是其他字符或字符串。所有的记录都有完全相同的字段序列,相当于一个结构化表的纯文本形式。用文本文件、excel或者类似于文本文件的编辑器都可以打开CSV文件
为了简化开发,可以使用opencsv类库来导出csv文件
<dependency>
<groupId>com.opencsv</groupId>
<artifactId>opencsv</artifactId>
<version>4.5</version>
</dependency>opencsv常用api
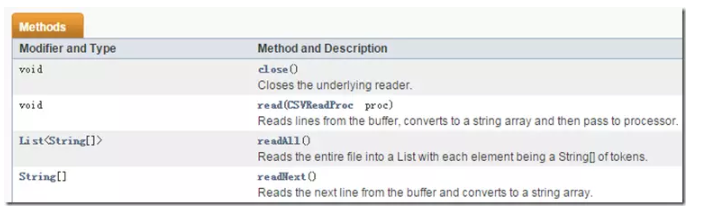
写入到csv文件会用到CSVWriter对象,创建此对象常见api如下
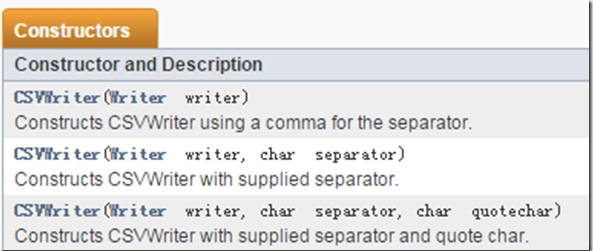
使用CSVWriter对象写入数据常用的方法如下:

读取csv文件会用到CSVReader对象,创建此对象常见API如下
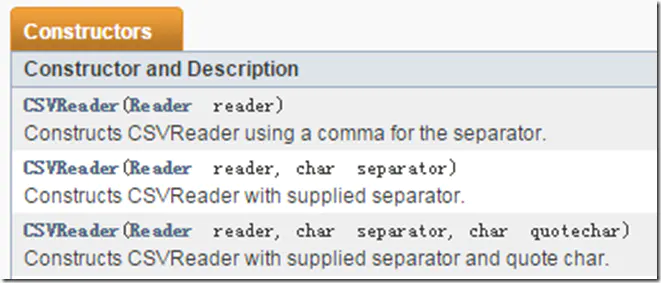
构造器中涉及的三个参数:
-
reader:读取文件的流对象,常用的是BufferedReader、InputStreamReader
-
separator:用于定义前面提到的分割符,默认为逗号CSVWriter.DEFAULT_SEPARATOR用于分割分列
-
quotechar:用于定义各个列的引号,有时候csv文件中会用引号或者其他符号将一个列引起来,例如一行可能是:“1”,“2”,“3”,如果想读出的字符不包含引号,就可以把参数设为 CSVWriter.NO_QUOTE_CHARACTER
read方法
导出csv文件
需求:把用户的列表数据导出到csv文件中
代码实现
UserController代码
@GetMapping(value = "/downLoadCSV",name = "导出用户数据到CSV文件中")
public void downLoadCSV(HttpServletResponse response){
userService.downLoadCSV(response);
}UserService代码
public void downLoadCSV(HttpServletResponse response) {
try {
// 准备输出流
ServletOutputStream outputStream = response.getOutputStream();
// 文件名
String filename="百万数据.csv";
// 设置两个头 一个是文件的打开方式 一个是mime类型
response.setHeader( "Content-Disposition", "attachment;filename=" + new String(filename.getBytes(),"ISO8859-1"));
response.setContentType("text/csv");
// 创建一个用来写入到csv文件中的writer
CSVWriter writer = new CSVWriter(new OutputStreamWriter(outputStream,"utf-8"));
// 先写头信息
writer.writeNext(new String[]{"编号","姓名","手机号","入职日期","现住址"});
// 如果文件数据量非常大的时候,我们可以循环查询写入
int page = 1;
int pageSize=200000;
while (true) { //不停地查询
List<User> userList = this.findPage(page, pageSize);
if (CollectionUtils.isEmpty(userList)) { //如果查询不到就不再查询了
break;
}
// 把查询到的数据转成数组放入到csv文件中
for (User user : userList) {
writer.writeNext(new String[]{user.getId().toString(),user.getUserName(),user.getPhone(),simpleDateFormat.format(user.getHireDate()),user.getAddress()});
}
writer.flush();
page++;
}
writer.close();
} catch (Exception e) {
e.printStackTrace();
}
}opencsv读取csv文件
//读取百万级数据的csv文件
public class CsvDemo {
private static SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd");
public static void main(String[] args) throws Exception {
CSVReader csvReader = new CSVReader(new FileReader("d:\\百万用户数据的导出.csv"));
String[] titles = csvReader.readNext(); //读取到第一行 是小标题
// "编号","姓名","手机号","入职日期","现住址"
User user = null;
while (true){
user = new User();
String[] content = csvReader.readNext();
if(content==null){
break;
}
user.setId(Long.parseLong(content[0]));
user.setUserName(content[1]);
user.setPhone(content[2]);
user.setHireDate(simpleDateFormat.parse(content[3]));
user.setAddress(content[4]);
System.out.println(user);
}
}
}
POI导出word
需求:在列表页面点击合同按钮,点击跳转到合同页面,页面中有下载按钮,点击下载,把页面内容导出到word

POI操作Word的api介绍
1、poi操作word正文
XWPFDocument代表一个docx文档,其可以用来度docx文档,也可以用来写docx文档
一个文档包含多个段落,一个段落包含多个runs文本,一个runs包含多个Run,Run是文档的最小单元
获取所有段落:List<XWPFParagraph>paragraphs=word.getParagraphs();
获取一个段落中的所有片段Run:XWPFRun run = xwpfRuns.get(index);
2、poi操作word中的表格
一个文档包含多个表格,一个表格包含多行,一行包含多列单元格
获取所有表格:List<XWPFTable> xwpfTables = doc.getTables();
获取一个表格中的所有行:List<XWPFTableRow> xwpfTableRows = xwpfTable.getRows();
获取一行中的所有列:List<XWPFTableCell> xwpfTableCells = xwpfTableRow.getTableCells();
获取一格里的内容:List<XWPFParagraph> paragraphs = xwpfTableCell.getParagraphs();
之后和正文段落一样
思路分析 :首先我们先制作一个word模板,把动态的内容先写特殊字符然后替换,表格需要自己创建然后向表格中放内容

代码实现
第一步:制作模板,将模板文件放入到项目中
第二步:提供根据id查询用户的方法,并且用户中带有办公资源数据
User类中添加一个集合属性

UserController代码
根据用户id查询用户对象
@GetMapping("/{id}")
public User findById(@PathVariable("id") Long id){
return userService.findById(id);
}UserService代码
查询用户信息,并且查询用户的办公用品数据,赋值到用户中
@Autowired
private ResourceMapper resourceMapper;
public User findById(Long id) {
//查询用户
User user = userMapper.selectByPrimaryKey(id);
//根据用户id查询办公用品
Resource resource = new Resource();
resource.setUserId(id);
List<Resource> resourceList = resourceMapper.select(resource);
user.setResourceList(resourceList);
return user;
}
第三步:完成word导出功能
Controller代码
@GetMapping(value = "/downloadContract",name = "导出用户合同")
public void downloadContract(Long id,HttpServletResponse response) throws Exception{
userService.downloadContract(id,response);
}UserService代码
先准备两个方法,一个是指定的单元格中放入图片,另一个是复制word中表格的行
// 向单元格中写入图片
private void setCellImage(XWPFTableCell cell, File imageFile) {
XWPFRun run = cell.getParagraphs().get(0).createRun();
// InputStream pictureData, int pictureType, String filename, int width, int height
try(FileInputStream inputStream = new FileInputStream(imageFile)) {
run.addPicture(inputStream,XWPFDocument.PICTURE_TYPE_JPEG,imageFile.getName(), Units.toEMU(100),Units.toEMU(50));
} catch (Exception e) {
e.printStackTrace();
}
}
// 用于深克隆行
private void copyRow(XWPFTable xwpfTable, XWPFTableRow sourceRow, int rowIndex) {
XWPFTableRow targetRow = xwpfTable.insertNewTableRow(rowIndex);
targetRow.getCtRow().setTrPr(sourceRow.getCtRow().getTrPr());
// 获取源行的单元格
List<XWPFTableCell> cells = sourceRow.getTableCells();
if(CollectionUtils.isEmpty(cells)){
return;
}
XWPFTableCell targetCell = null;
for (XWPFTableCell cell : cells) {
targetCell = targetRow.addNewTableCell();
// 附上单元格的样式
// 单元格的属性
targetCell.getCTTc().setTcPr(cell.getCTTc().getTcPr());
targetCell.getParagraphs().get(0).getCTP().setPPr(cell.getParagraphs().get(0).getCTP().getPPr());
}
}完成导出的主体方法
/**
* 下载用户合同数据
*/
public void downloadContract(Long id,HttpServletResponse response) throws Exception {
// 1、读取到模板
File rootFile = new File(ResourceUtils.getURL("classpath:").getPath()); //获取项目的根目录
File templateFile = new File(rootFile, "/word_template/contract_template.docx");
XWPFDocument word = new XWPFDocument(new FileInputStream(templateFile));
// 2、查询当前用户User--->map
User user = this.findById(id);
Map<String,String> params = new HashMap<>();
params.put("userName",user.getUserName());
params.put("hireDate",simpleDateFormat.format(user.getHireDate()));
params.put("address",user.getAddress());
// 3、替换数据
// 处理正文开始
List<XWPFParagraph> paragraphs = word.getParagraphs();
for (XWPFParagraph paragraph : paragraphs) {
List<XWPFRun> runs = paragraph.getRuns();
for (XWPFRun run : runs) {
String text = run.getText(0);
for (String key : params.keySet()) {
if(text.contains(key)){
run.setText(text.replaceAll(key,params.get(key)),0);
}
}
}
}
// 处理正文结束
// 处理表格开始 名称 价值 是否需要归还 照片
List<Resource> resourceList = user.getResourceList(); //表格中需要的数据
XWPFTable xwpfTable = word.getTables().get(0);
XWPFTableRow row = xwpfTable.getRow(0);
int rowIndex = 1;
for (Resource resource : resourceList) {
// 添加行
// xwpfTable.addRow(row);
copyRow(xwpfTable,row,rowIndex);
XWPFTableRow row1 = xwpfTable.getRow(rowIndex);
row1.getCell(0).setText(resource.getName());
row1.getCell(1).setText(resource.getPrice().toString());
row1.getCell(2).setText(resource.getNeedReturn()?"需求":"不需要");
File imageFile = new File(rootFile,"/static"+resource.getPhoto());
setCellImage(row1.getCell(3),imageFile);
rowIndex++;
}
// 处理表格开始结束
// 4、导出word
String filename = "员工(" + user.getUserName() + ")合同.docx";
response.setHeader("content-disposition", "attachment;filename=" + new String(filename.getBytes(), "ISO8859-1"));
response.setContentType("application/vnd.openxmlformats-officedocument.spreadsheetml.sheet");
word.write(response.getOutputStream());
}easyPOI
简介:是近几年在开发市场上流行的一种简化poi开发的类库:easyPOI
作用:excel的快速导入导出,excel模板导出,word模板导出,可以仅仅5行代码就可以完成excel的导入导出,修改导出格式
适用人群:不太熟悉poi的 不想写太多重复代码的 只是简单导入导出的 喜欢使用模板的
目标:easyPOI的目标不是代替poi,而是让一个不懂导入导出的快速使用poi完成excel和word的各种操作,而不是看很多poi才可以完成这项工作。easyPOI完全代替不了poi
需要的依赖
(把项目中的poi依赖去掉)
<dependency>
<groupId>cn.afterturn</groupId>
<artifactId>easypoi-base</artifactId>
<version>4.1.0</version>
</dependency>
<dependency>
<groupId>cn.afterturn</groupId>
<artifactId>easypoi-web</artifactId>
<version>4.1.0</version>
</dependency>
<dependency>
<groupId>cn.afterturn</groupId>
<artifactId>easypoi-annotation</artifactId>
<version>4.1.0</version>
</dependency>
或是springboot
<dependency>
<groupId>cn.afterturn</groupId>
<artifactId>easypoi-spring-boot-starter</artifactId>
<version>4.1.0</version>
</dependency>easyPOI注解方式导出
第一步:修改实体类,添加注解
其中主要用到的注解是@Excel注解
注解详情:
| 属性 | 类型 | 类型 | 说明 |
|---|---|---|---|
| name | String | null | 列名 |
| needMerge | boolean | fasle | 纵向合并单元格 |
| orderNum | String | "0" | 列的排序,支持name_id |
| replace | String[] | {} | 值得替换 导出是{a_id,b_id} 导入反过来 |
| savePath | String | "upload" | 导入文件保存路径 |
| type | int | 1 | 导出类型 1 是文本 2 是图片,3 是函数,10 是数字 默认是文本 |
| width | double | 10 | 列宽 |
| height | double | 10 | 列高,后期打算统一使用@ExcelTarget的height,这个会被废弃,注意 |
| isStatistics | boolean | fasle | 自动统计数据,在追加一行统计,把所有数据都和输出这个处理会吞没异常,请注意这一点 |
| isHyperlink | boolean | false | 超链接,如果是需要实现接口返回对象 |
| isImportField | boolean | true | 校验字段,看看这个字段是不是导入的Excel中有,如果没有说明是错误的Excel,读取失败,支持name_id |
| exportFormat | String | "" | 导出的时间格式,以这个是否为空来判断是否需要格式化日期 |
| importFormat | String | "" | 导入的时间格式,以这个是否为空来判断是否需要格式化日期 |
| format | String | "" | 时间格式,相当于同时设置了exportFormat 和 importFormat |
| databaseFormat | String | "yyyyMMddHHmmss" | 导出时间设置,如果字段是Date类型则不需要设置 数据库如果是string类型,这个需要设置这个数据库格式,用以转换时间格式输出 |
| numFormat | String | "" | 数字格式化,参数是Pattern,使用的对象是DecimalFormat |
| imageType | int | 1 | 导出类型 1 从file读取 2 是从数据库中读取 默认是文件 同样导入也是一样的 |
| suffix | String | "" | 文字后缀,如% 90 变成90% |
| isWrap | boolean | true | 是否换行 即支持\n |
| mergeRely | int[] | {} | 合并单元格依赖关系,比如第二列合并是基于第一列 则{1}就可以了 |
| mergeVertical | boolean | fasle | 纵向合并内容相同的单元格 |
此处注意必须要有空构造函数,否则会报错“对象创建错误”
/**
* 员工
*/
@Data
@Table(name="tb_user")
public class User {
@Id
@KeySql(useGeneratedKeys = true)
@Excel(name = "编号", orderNum = "0", width = 5)
private Long id; //主键
@Excel(name = "员工名", orderNum = "1", width = 15)
private String userName; //员工名
@Excel(name = "手机号", orderNum = "2", width = 15)
private String phone; //手机号
@Excel(name = "省份名", orderNum = "3", width = 15)
private String province; //省份名
@Excel(name = "城市名", orderNum = "4", width = 15)
private String city; //城市名
@Excel(name = "工资", orderNum = "5", width = 10)
private Integer salary; // 工资
@JsonFormat(pattern="yyyy-MM-dd")
@Excel(name = "入职日期", format = "yyyy-MM-dd",orderNum = "6", width = 15)
private Date hireDate; // 入职日期
private String deptId; //部门id
@Excel(name = "出生日期", format = "yyyy-MM-dd",orderNum = "7", width = 15)
private Date birthday; //出生日期
@Excel(name = "照片", orderNum = "10",width = 15,type = 2)
private String photo; //一寸照片
@Excel(name = "现在居住地址", orderNum = "9", width = 30)
private String address; //现在居住地址
private List<Resource> resourceList; //办公用品
}第二部:UserController添加方法
@GetMapping(value = "/downLoadWithEasyPOI",name = "使用EasyPOI下载Excel")
public void downLoadWithEasyPOI(HttpServletRequest request,HttpServletResponse response) throws Exception{
userService.downLoadXlsxWithEayPoi(request,response);
}第三步:UserService实现方法
public void downLoadXlsxWithEayPoi(HttpServletRequest request, HttpServletResponse response) throws Exception {
// 查询用户数据
List<User> userList = userMapper.selectAll();
//指定导出的格式是高版本的格式
ExportParams exportParams = new ExportParams("员工信息", "数据",ExcelType.XSSF);
// 直接使用EasyPOI提供的方法
Workbook workbook = ExcelExportUtil.exportExcel(exportParams, User.class, userList);
String filename="员工信息.xlsx";
// 设置文件的打开方式和mime类型
ServletOutputStream outputStream = response.getOutputStream();
response.setHeader( "Content-Disposition", "attachment;filename=" + new String(filename.getBytes(),"ISO8859-1"));
response.setContentType("application/vnd.openxmlformats-officedocument.spreadsheetml.sheet");
workbook.write(outputStream);
}easyPOI注解方式导入
Excel导入时需要的参数类ImportParams常用设置说明
-
读取指定的sheet比如要读取上传的第二个sheet 那么需要把startSheetIndex = 1 就可以了
-
读取几个sheet 比如读取前两个sheet,那么sheetNum = 2 就可以了
-
读取第二个到第五个sheet 设置startSheetIndex = 1 然后sheetNum = 4
-
读取全部的sheet sheetNum设置大点就可以了
-
保存Excel 设置 needVerfiy = true,默认保存的路径为upload/excelUpload/Test/yyyyMMddHHmss 保存名称上传时间五位随机数 如果自定义路径 修改下saveUrl 就可以了,同时saveUrl也是图片上传时候的保存的路径
-
判断一个Excel是不是合法的Excel importFields 设置下值,就是表示表头必须至少包含的字段,如果缺一个就是不合法的excel,不导入
-
图片的导入 有图片的导出就有图片的导入,导入的配置和导出是一样的,但是需要设置保存路径 1.设置保存路径saveUrl 默认为"upload/excelUpload" 可以手动修改 ImportParams 修改下就可以了
第一步:修改实体类,表明哪些需要导入
/**
* 员工
*/
@Data
@Table(name="tb_user")
public class User {
@Id
@KeySql(useGeneratedKeys = true)
@Excel(name = "编号", orderNum = "0", width = 5)
private Long id; //主键
@Excel(name = "员工名", orderNum = "1", width = 15,isImportField="true")
private String userName; //员工名
@Excel(name = "手机号", orderNum = "2", width = 15,isImportField="true")
private String phone; //手机号
@Excel(name = "省份名", orderNum = "3", width = 15,isImportField="true")
private String province; //省份名
@Excel(name = "城市名", orderNum = "4", width = 15,isImportField="true")
private String city; //城市名
@Excel(name = "工资", orderNum = "5", width = 10, type=10, isImportField="true") //type=10表示会导出数字
private Integer salary; // 工资
@JsonFormat(pattern="yyyy-MM-dd")
@Excel(name = "入职日期", format = "yyyy-MM-dd",orderNum = "6", width = 15,isImportField="true")
private Date hireDate; // 入职日期
private String deptId; //部门id
@Excel(name = "出生日期", format = "yyyy-MM-dd",orderNum = "7", width = 15,isImportField="true")
private Date birthday; //出生日期
@Excel(name = "照片", orderNum = "10",width = 15,type = 2,isImportField="true",savePath = "D:\\java_report\\workspace\\user_management\\src\\main\\resources\\static\\user_photos\\")
private String photo; //一寸照片
@Excel(name = "现在居住地址", orderNum = "9", width = 30,isImportField="true")
private String address; //现在居住地址
private List<Resource> resourceList; //办公用品
}
第二步:修改UserController中的导入方法
@PostMapping(value = "/uploadExcle", name = "上传用户数据")
public void uploadExcle(MultipartFile file) throws Exception{
// userService.uploadExcle(file);
userService.uploadExcleWithEasyPOI(file);
}第三步:在UserService中添加easyPOI导入的方法
public void uploadExcleWithEasyPOI(MultipartFile file) throws Exception {
ImportParams importParams = new ImportParams();
importParams.setTitleRows(1); //有多少行的标题
importParams.setHeadRows(1);//有多少行的头
List<User> userList = ExcelImportUtil.importExcel(file.getInputStream(),User.class,importParams);
System.out.println(userList);
for (User user : userList) {
user.setId(null);
userMapper.insertSelective(user);
}
}
模板方式导出数据
模板是处理复杂Excel的简单方法,复杂的excel样式,可以用excel直接编辑,完美的避开了代码编写样式的雷区,同时指令的支持,也提高了模板的有效性
采用的写法是{{}}代表表达式,然后根据表达式里面的数据取值
关于样式问题:easyPOI不会改变excel原有的样式
需求:导出用户的详细信息,
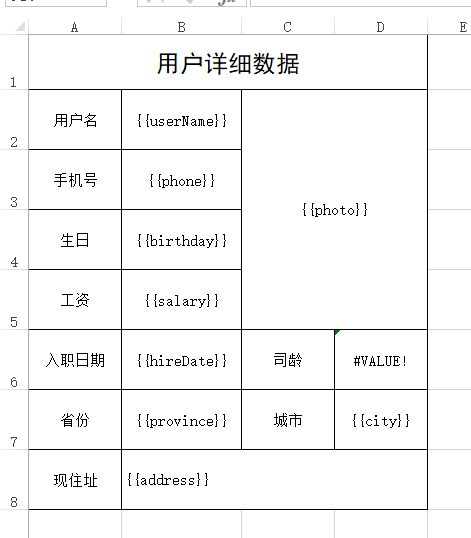
第一步:制作模板,将模板放入项目中
这个模板和前面做过的userInfo2.xlsx模板一样,只是变量使用了{{}}包起来了
第二步:改写UserController中导出用户信息的方法
@GetMapping(value = "/download",name = "导出用户详细信息")
public void downLoadUserInfoWithTempalte(Long id,HttpServletRequest request,HttpServletResponse response) throws Exception{
userService.downLoadUserInfoWithEastPOI(id,request,response);
}第三步:完成UserService中的方法
public void downLoadUserInfoWithEastPOI(Long id, HttpServletRequest request, HttpServletResponse response) throws Exception {
// 获取模板的路径
File rootPath = new File(ResourceUtils.getURL("classpath:").getPath()); //SpringBoot项目获取根目录的方式
File templatePath = new File(rootPath.getAbsolutePath(),"/excel_template/userInfo3.xlsx");
// 读取模板文件
TemplateExportParams params = new TemplateExportParams(templatePath.getPath(),true);
// 查询用户,转成map
User user = userMapper.selectByPrimaryKey(id);
Map<String, Object> map = EntityUtils.entityToMap(user);
ImageEntity image = new ImageEntity();
// image.setHeight(640); //测试发现 这里设置了长度和宽度在合并后的单元格中没有作用
// image.setWidth(380);
image.setRowspan(4);//向下合并三行
image.setColspan(2);//向右合并两列
image.setUrl(user.getPhoto());
map.put("photo", image);
Workbook workbook = ExcelExportUtil.exportExcel(params, map);
// 导出的文件名称
String filename="用户详细信息数据.xlsx";
// 设置文件的打开方式和mime类型
ServletOutputStream outputStream = response.getOutputStream();
response.setHeader( "Content-Disposition", "attachment;filename=" + new String(filename.getBytes(),"ISO8859-1"));
response.setContentType("application/vnd.openxmlformats-officedocument.spreadsheetml.sheet");
workbook.write(outputStream);
}easyPOI导出CSV
csv的导出基本上和excel的导出一致,大体参数也是一致的
| 属性 | 类型 | 默认值 | 功能 |
|---|---|---|---|
| encoding | String | UTF8 | 文件编码 |
| spiltMark | String | , | 分隔符 |
| textMark | String | “ | 字符串识别,可以去掉,需要前后一致 |
| titleRows | int | 0 | 表格头,忽略 |
| headRows | int | 1 | 标题 |
| exclusions | String[] | 0 | 忽略的字段 |
代码实现:
修改UserController中的方法
@GetMapping(value = "/downLoadCSV",name = "导出用户数据到CSV文件中")
public void downLoadCSV(HttpServletResponse response) throws Exception{
userService.downLoadCSVWithEasyPOI(response);
}实现UserService方法
public void downLoadCSVWithEasyPOI(HttpServletResponse response) throws Exception {
ServletOutputStream outputStream = response.getOutputStream();
// 文件名
String filename="百万数据.csv";
// 设置两个头 一个是文件的打开方式 一个是mime类型
response.setHeader( "Content-Disposition", "attachment;filename=" + new String(filename.getBytes(),"ISO8859-1"));
response.setContentType("application/csv");
// 创建一个用来写入到csv文件中的writer
CsvExportParams params = new CsvExportParams();
// 设置忽略的列
params.setExclusions(new String[]{"照片"}); //这里写表头 中文
List<User> list = userMapper.selectAll();
CsvExportUtil.exportCsv(params, User.class, list, outputStream);
}
说明:从上述的代码中可以发现,如果需要导出几百万数据时不可能全部加载到一个List中,所以easyPOI的方式导出csv是支持不了太大的数据量的,如果导出几百万条数据还是得选择opencsv方式导出
EasyPOI导出word
需求:使用easyPOI方式导出合同word文档
Word模板和Excel模板用法基本一致,支持的标签也是一致的,仅仅支持07版本的word也是只能生成后缀是docx的文档,poi对doc支持不好所以easyPOI中就没有支持doc,我们就拿docx做导出
模板中标签的用法:
下面列举EasyPoi支持的指令以及作用,最主要的就是各种fe的用法
三元运算 {{test ? obj:obj2}}
n: 表示 这个cell是数值类型 {{n:}}
le: 代表长度{{le:()}} 在if/else 运用{{le:() > 8 ? obj1 : obj2}}
fd: 格式化时间 {{fd:(obj;yyyy-MM-dd)}}
fn: 格式化数字 {{fn:(obj;###.00)}}
fe: 遍历数据,创建row
!fe: 遍历数据不创建row
$fe: 下移插入,把当前行,下面的行全部下移.size()行,然后插入
#fe: 横向遍历
v_fe: 横向遍历值
!if: 删除当前列 {{!if:(test)}}
单引号表示常量值 ‘’ 比如’1’ 那么输出的就是 1
&NULL& 空格
&INDEX& 表示循环中的序号,自动添加
]] 换行符 多行遍历导出
sum: 统计数据
第一步:根据上述指令要求,制作如下模板,并将模板放入项目中
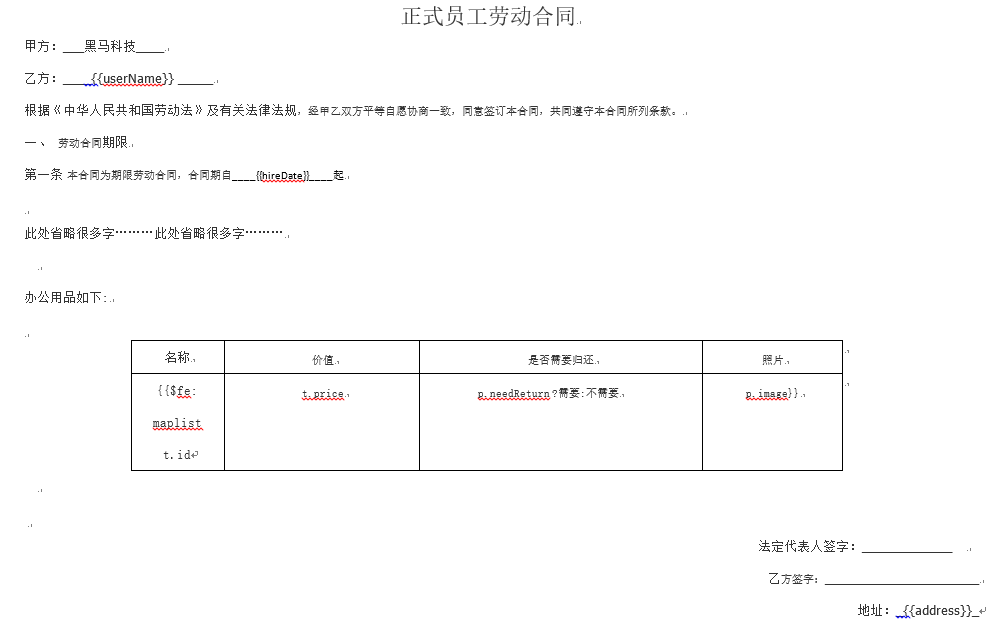
第二步:修改原来导出合同的方法
UserController
@GetMapping(value = "/downloadContract",name = "导出用户合同")
public void downloadContract(Long id,HttpServletResponse response) throws Exception{
userService.downloadContractWithEasyPOI(id,response);
}UserService添加方法
public void downloadContractWithEasyPOI(Long id,HttpServletResponse response) throws Exception {
File rootPath = new File(ResourceUtils.getURL("classpath:").getPath()); //SpringBoot项目获取根目录的方式
File templatePath = new File(rootPath.getAbsolutePath(),"/word_template/contract_template2.docx");
// 先获取导出word需要的数据
User user = this.findById(id);
// 把需要的数据放到map中,方便替换
Map<String,Object> params = new HashMap<String,Object>();
params.put("userName",user.getUserName());
params.put("hireDate",simpleDateFormat.format(user.getHireDate()));
params.put("address",user.getAddress());
// 下面是表格中需要的数据
List<Map> maplist = new ArrayList<>();
Map<String,Object> map = null;
for (Resource resource : user.getResourceList()) {
map = new HashMap<String,Object>();
map.put("name",resource.getName());
map.put("price",resource.getPrice());
map.put("needReturn",resource.getNeedReturn());
ImageEntity image = new ImageEntity();
image.setHeight(180);
image.setWidth(240);
image.setUrl(rootPath.getPath()+"\\static"+resource.getPhoto());
map.put("photo",image);
maplist.add(map);
}
// 把组建好的表格需要的数据放到大map中
params.put("maplist",maplist);
// 根据模板+数据 导出文档
XWPFDocument xwpfDocument = WordExportUtil.exportWord07(templatePath.getPath(), params);
String filename=user.getUserName()+"_合同.docx";
// 设置文件的打开方式和mime类型
ServletOutputStream outputStream = response.getOutputStream();
response.setHeader( "Content-Disposition", "attachment;filename=" + new String(filename.getBytes(),"ISO8859-1"));
response.setContentType("application/vnd.openxmlformats-officedocument.wordprocessingml.document");
xwpfDocument.write(outputStream);
}结果:

图中照片没有按照预想的正常显示,所以easyPOI不是万能的,如果有同样的需求还是得用POI来做
PDF文档简介
PDF(Portable Document Format的简称,意为“便携式文件格式”)是由Adobe Systems在1993年用于文件交换所发展出的文件格式。
PDF格式的文档的使用有如下好处: 1、跨平台 PDF文件格式与操作系统平台无关,也就是说,PDF文件不管是在Windows,Unix还是在苹果公司的Mac OS操作系统中都是通用的。不受平台的限制。越来越多的电子图书、产品说明、公司文告、网络资料、电子邮件开始使用PDF格式文件。
2、安全性高,不易修改 PDF是一种通用文件格式,不管创建源文档时使用的是哪些应用程序和平台,它均可以保留任何源文档的字体、图像、图形和版面设置。已成为世界上安全可靠地分发和交换电子文档及电子表单的实际标准。
3、阅读性能高,阅读舒适性好。
4、 相比Word格式的文档,PDF文件格式更为正式。 而WORD文档在跨平台使用方面不如PDF方便,而且WORD文档是可以进行编辑修改的,在安全性和可靠性上不如PDF,而且往往很难反映出用其它编辑软件排版的版面信息,使用上有一定的局限性。
所以,现在网站导出PDF也是比较普遍的,我们今天主要的课程就是学习如果导出PDF文件。
word转PDF
场景说明:把word转为pdf目前最简单的方法就是调用office方法,本质上就是打开word后另存为pdf
使用jacob,速度可以,word中的原样式也不会丢失
环境准备
jacob的jar包无法直接从中央仓库直接下载,需要添加到本地仓库中
第一步:进入jar包所在目录执行以下命令:
mvn install:install-file -DgroupId=com.jacob -DartifactId=jacob -Dversion=1.19 -Dfile=jacob.jar -Dpackaging=jar
第二步:将dll文件放到jre\bin目录下 64位放x64文件 32位放x86文件

在pom.xml中添加依赖
<dependency>
<groupId>com.jacob</groupId>
<artifactId>jacob</artifactId>
<version>1.19</version>
</dependency>代码测试
需求:将D盘下的word转成pdf
public class JacobDemo {
public static void main(String[] args) {
String source = "D:\\李四_合同.docx";
String target = "D:\\李四_合同.pdf";
System.out.println("Word转PDF开始启动...");
ActiveXComponent app = null;
try {
// 调用window中的程序
app = new ActiveXComponent("Word.Application");
// 调用的时候不显示窗口
app.setProperty("Visible", false);
// 获得所有打开的文档
Dispatch docs = app.getProperty("Documents").toDispatch();
Dispatch doc = Dispatch.call(docs, "Open", source).toDispatch();
System.out.println("转换文档到PDF:" + target);
// 另存为,将文档保存为pdf,其中Word保存为pdf的格式宏的值是17
Dispatch.call(doc, "SaveAs", target, 17);
Dispatch.call(doc, "Close");
} catch (Exception e) {
System.out.println("Word转PDF出错:" + e.getMessage());
} finally {
// 关闭office
if (app != null) {
app.invoke("Quit", 0);
}
}
}
}结果

JasperReport导出pdf
JasperReport是一个强大、灵活的报表生成工具,能够展示丰富的页面内容,并将之转换成PDF,HTML,或者XML格式。该库完全由Java写成,可以用于在各种Java应用程序,包括J2EE,Web应用程序中生成动态内容。只需要将JasperReport引入工程中即可完成PDF报表的编译、显示、输出等工作。
在开源的JAVA报表工具中,JasperReport发展是比较好的,比一些商业的报表引擎做得还好,如支持了十字交叉报表、统计报表、图形报表,支持多种报表格式的输出,如PDF、RTF、XML、CSV、XHTML、TEXT、DOCX以及OpenOffice。
数据源支持更多,常用 JDBCSQL查询、XML文件、CSV文件、HQL(Hibernate查询),HBase,JAVA集合等。还允许你义自己的数据源,通过JASPER文件及数据源,JASPER就能生成最终用户想要的文档格式。
JasperReport的开发步骤
生命周期
通常我们提到PDF报表的时候,浮现在脑海中的是最终的PDF文档文件。在JasperReports中,这只是报表生命周期的最后阶段。通过JasperReports生成PDF报表一共要经过三个阶段,我们称之为 JasperReport的生命周期,
这三个阶段为:
设计(Design)阶段、
执行(Execution)阶段
输出(Export)阶段,如下图所示:
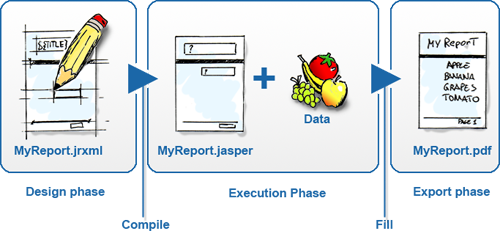
设计阶段(Design):所谓的报表设计就是创建一些模板,模板包含了报表的布局与设计,包括执行计算的复杂公式、可选的从数据源获取数据的查询语句、以及其它的一些信息。模板设计完成之后,我们将模板保存为JRXML文件(JR代表JasperReports),其实就是一个XML文件。
执行阶段(Execution):使用以JRXML文件编译为可执行的二进制文件(即.Jasper文件)结合数据进行执行,填充报表数据
输出阶段(Export):数据填充结束,可以指定输出为多种形式的报表
执行流程
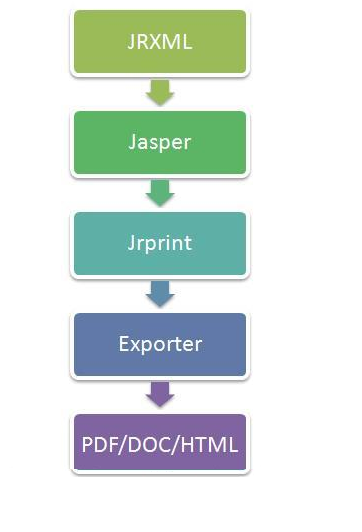
1、JRXML:报表填充模板,本质是一个XML.
JasperReport已经封装了一个dtd,只要按照规定的格式写这个xml文件,那么jasperReport就可以将其解析最终生成报表,但是jasperReport所解析的不是我们常见的.xml文件,而是.jrxml文件,其实跟xml是一样的,只是后缀不一样。
2、Jasper:由JRXML模板编译生成的二进制文件,用于代码填充数据。
解析完成后JasperReport就开始编译.jrxml文件,将其编译成.jasper文件,因为JasperReport只可以对.jasper文件进行填充数据和转换,这步操作就跟我们java中将java文件编译成class文件是一样的
3、Jrprint:当用数据填充完Jasper后生成的文件,用于输出报表。
这一步才是JasperReport的核心所在,它会根据你在xml里面写好的查询语句来查询指定是数据库,也可以控制在后台编写查询语句,参数,数据库。在报表填充完后,会再生成一个.jrprint格式的文件(读取jasper文件进行填充,然后生成一个jrprint文件)
4、Exporter:决定要输出的报表为何种格式,报表输出的管理类。
5、JasperReport可以输出多种格式的报表文件,常见的有Html,PDF,xls等
综上我们得知,对于使用JasperReport进行开发,我们重点关注只有如下四点:
-
制作报表模板
-
模板编译
-
构造数据
-
填充模板数据
模板工具Jaspersoft Studio
概述
Jaspersoft Studio是JasperReports库和JasperReports服务器的基于Eclipse的报告设计器; 它可以作为Eclipse插件或作为独立的应用程序使用。Jaspersoft Studio允许您创建包含图表,图像,子报表,交叉表等的复杂布局。您可以通过JDBC,TableModels,JavaBeans,XML,Hibernate,大数据(如Hive),CSV,XML / A以及自定义来源等各种来源访问数据,然后将报告发布为PDF,RTF, XML,XLS,CSV,HTML,XHTML,文本,DOCX或OpenOffice。
Jaspersoft Studio 是一个可视化的报表设计工具,使用该软件可以方便地对报表进行可视化的设计,设计结果为格式.jrxml 的XML 文件,并且可以把.jrxml 文件编译成.jasper 格式文件方便 JasperReport 报表引擎解析、显示。
JasperReport入门案例
1、导入依赖
<dependency>
<groupId>net.sf.jasperreports</groupId>
<artifactId>jasperreports</artifactId>
<version>6.5.0</version>
</dependency>
<dependency>
<groupId>org.olap4j</groupId>
<artifactId>olap4j</artifactId>
<version>1.2.0</version>
</dependency>
<dependency>
<groupId>com.lowagie</groupId>
<artifactId>itext</artifactId>
<version>2.1.7</version>
</dependency>
2、准备中文字体资源文件
jasperReports本身对中文支持不够好,如果涉及到中文,需要自己准备中文的资源
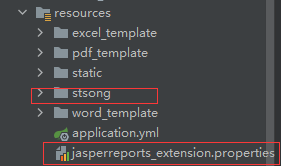
将图中的文件夹和properties文件放入resources目录下
第一步:使用Jaspersoft Studio制作一个简单的模板
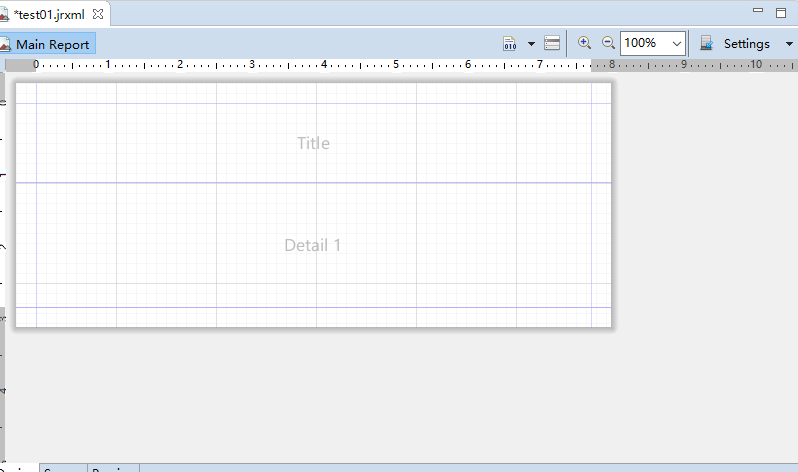
1、 创建新模板,删除不需要的Band
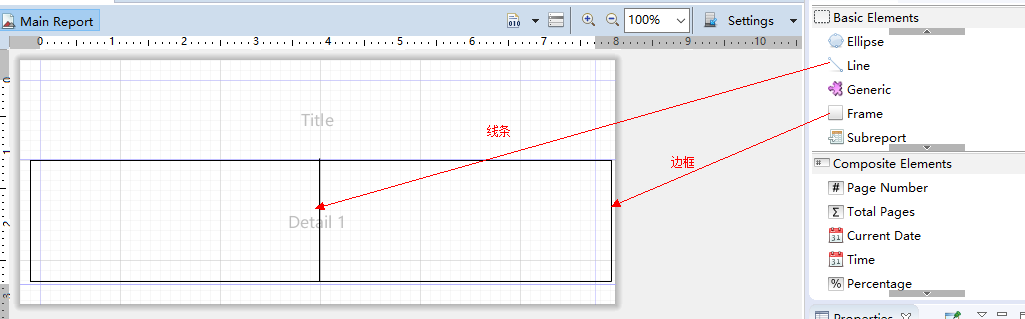
2、画边框和线
3、添加几个静态的文本
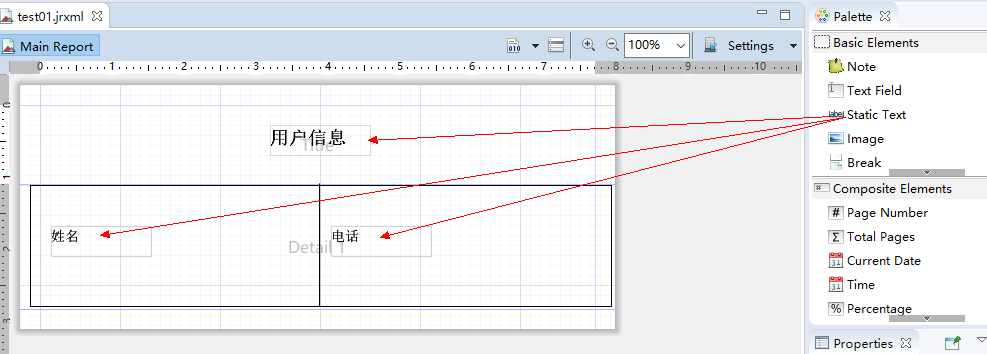
4、添加变量
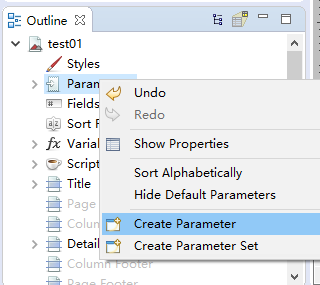
在右下角修改变量名称
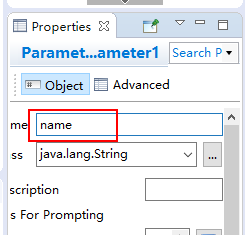
5、使用变量
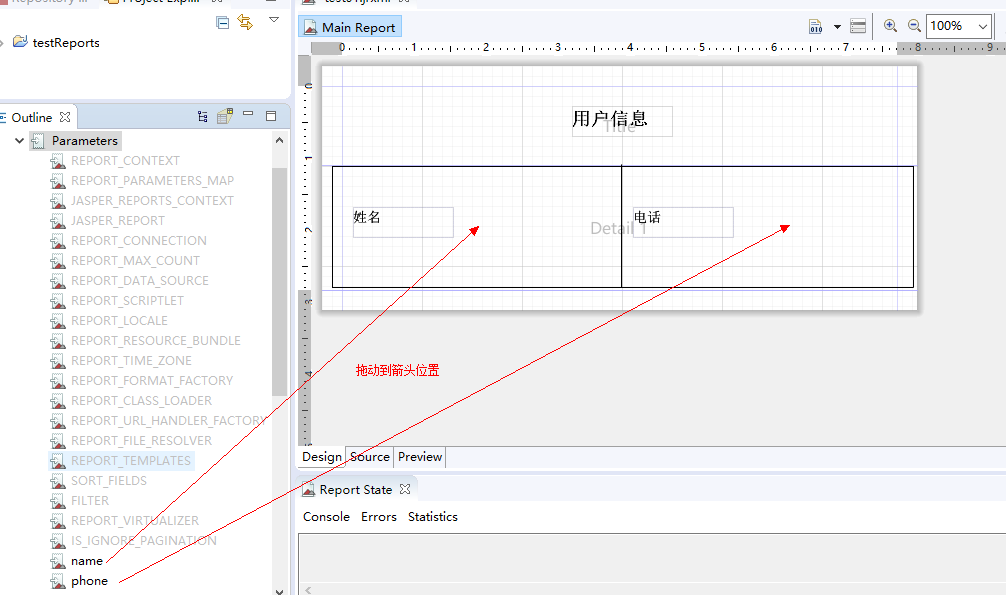
效果:

6、有中文的设置字体为华文宋体
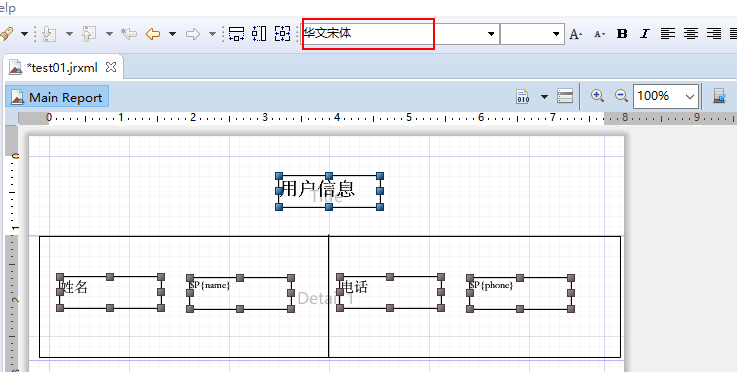
7、保存后编辑
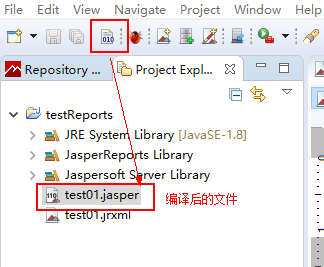
第二步:把test01.jasper文件放到磁盘中的某个位置

第三步:测试代码
public class PDFDemo1 {
/**
* 基于parameters以Map的形式填充数据
*/
public static void main(String[] args) throws Exception {
String filePath = "D:\\test01.jasper";
// 文件的输入流
InputStream inputStream = new FileInputStream(filePath);
//2.创建JasperPrint,向jasper文件中填充数据
FileOutputStream os = new FileOutputStream("d:\\demo1.pdf");
try {
Map parameters = new HashMap<>();
//设置参数 参数的key = 模板中使用的parameters参数的name
parameters.put("name","张三");
parameters.put("phone","13800000000");
//3.将JasperPrint已PDF的形式输出
JasperPrint jasperPrint = JasperFillManager.fillReport(inputStream,parameters,new JREmptyDataSource());
//导出
JasperExportManager.exportReportToPdfStream(jasperPrint,os);
} catch (JRException e) {
e.printStackTrace();
}finally {
os.flush();
}
}
}导出用户列表
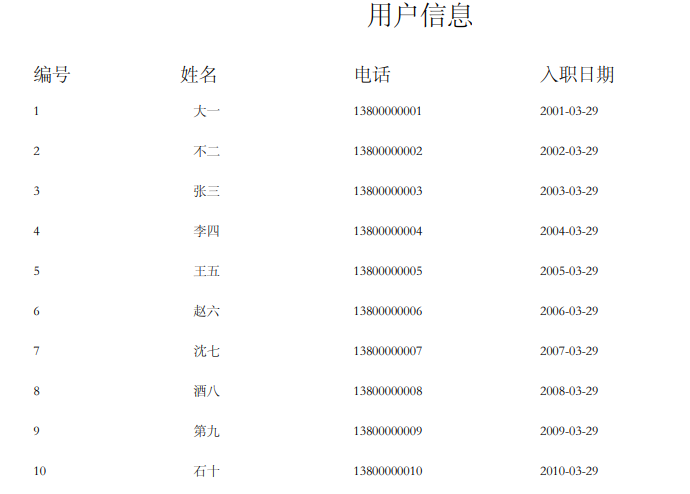
需求:导出如下用户列表
数据直接从数据库中获取
第一步:制作模板
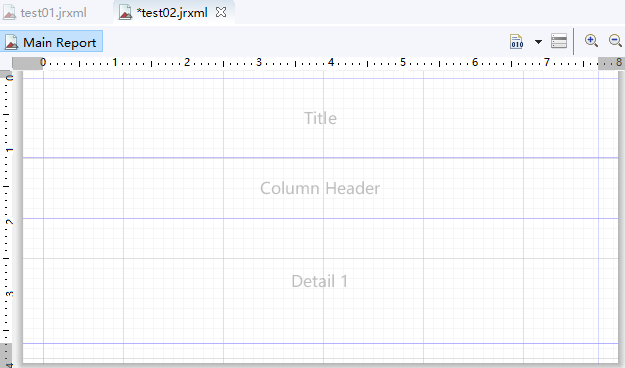
1、创建新模板
2、配置数据连接
使用JDBC数据源填充数据:使用Jaspersoft Studio 先要配置一个数据库连接
填写数据源的类型,选择“DatabaseJDBC Connection”
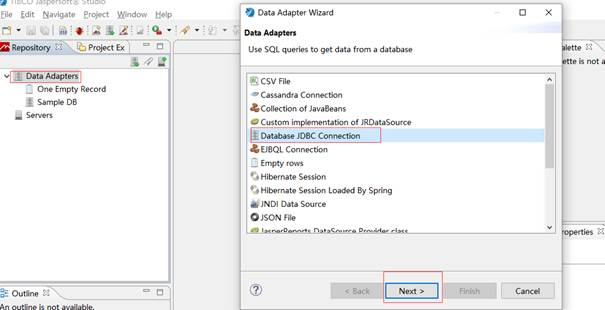
配置数据库信息

这一步,需要: (1)给创建的这个数据连接起个名字; (2)根据数据库选择驱动类型; Jaspersoft Studio 已经内置了很多常用数据库的驱动,使用的时候直接选就可以了。当然,如果这还满足不了你的话,你还可以添加你指定的 JDBC 驱动 jar 包。
3、读取表中属性
左下角右击模板名称选择 Dataset and Query
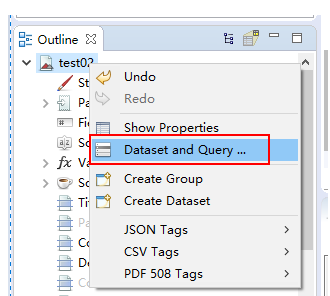
点击后:
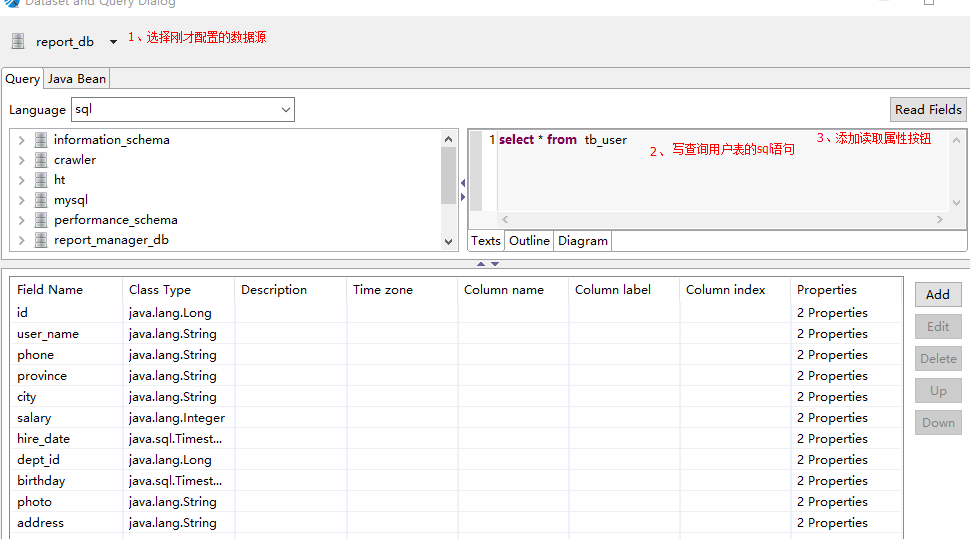
点击“OK”按钮
左下角的Fields中就有了我们想要的属性字段了
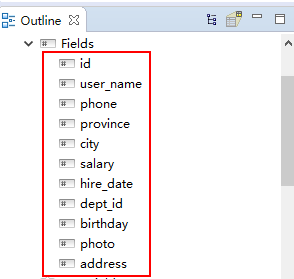
4、模板如下
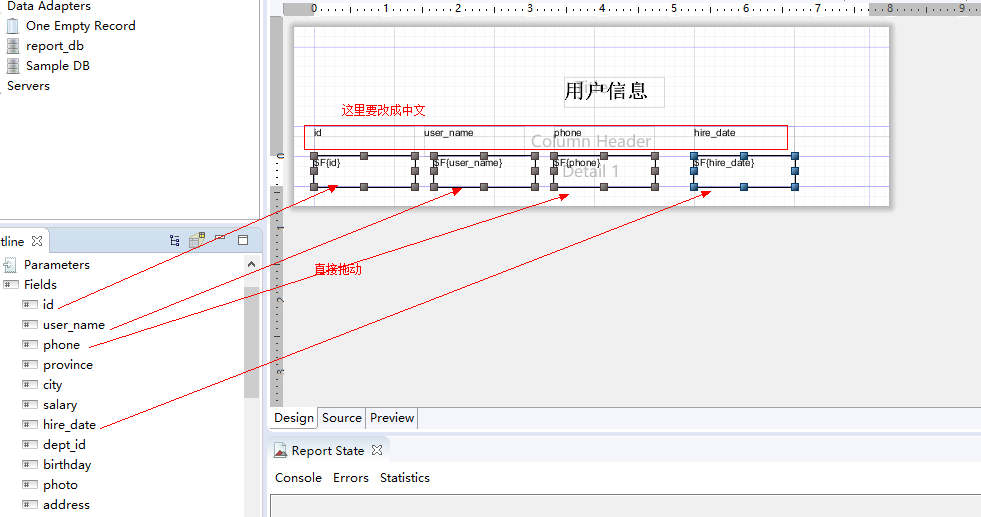
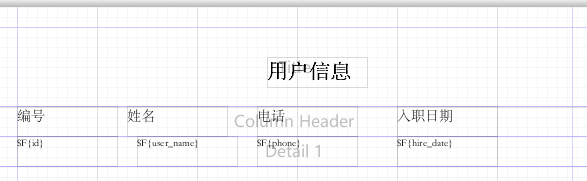
修改标题,并且要使用华文宋体
第二步:把编译后的jasper文件放入到项目中
第三步:完成代码
1、Controller中添加方法
@GetMapping(value = "/downLoadPDF",name = "导出PDF")
public void downLoadPDF(HttpServletResponse response) throws Exception{
userService.downLoadPDFByDB(response);
}2、Service添加方法
@Autowired
private HikariDataSource hikariDataSource;
public void downLoadPDFByDB(HttpServletResponse response) throws Exception {
// 获取模板文件
String ctxPath = ResourceUtils.getURL("classpath:").getPath();
String filePath = ctxPath+"/pdf_template/userList_db.jasper";
ServletOutputStream outputStream = response.getOutputStream();
// 文件名
String filename="用户列表数据.pdf";
// 设置两个头 一个是文件的打开方式 一个是mime类型
response.setHeader( "Content-Disposition", "attachment;filename=" + new String(filename.getBytes(),"ISO8859-1"));
response.setContentType("application/pdf");
// 文件的输入流
InputStream inputStream = new FileInputStream(filePath);
//2.创建JasperPrint,向jasper文件中填充数据
Map parameters = new HashMap<>();
//3.将JasperPrint已PDF的形式输出
JasperPrint jasperPrint = JasperFillManager.fillReport(inputStream,parameters,hikariDataSource.getConnection());
//导出
JasperExportManager.exportReportToPdfStream(jasperPrint,outputStream);
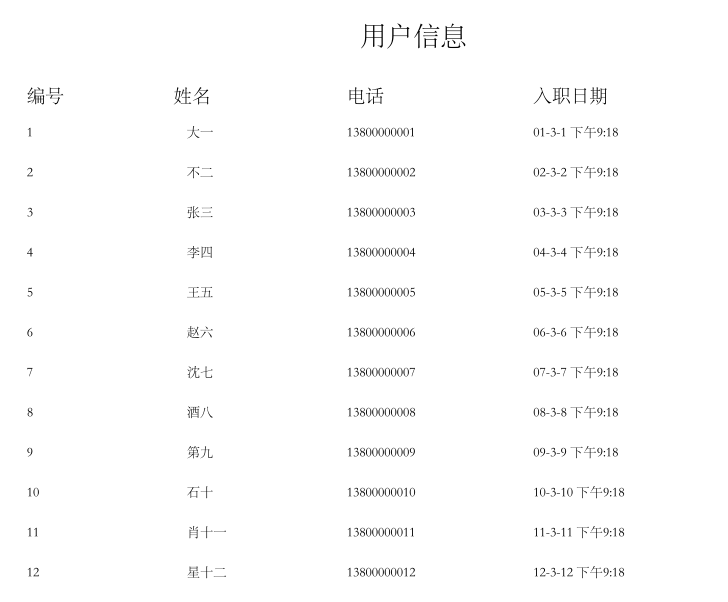
}效果如图
数据从后台获取
第一步:创建模板
第二步:把编译的后的模板文件放入到项目中
第三步:修改UserController中的代码
@GetMapping(value = "/downLoadPDF",name = "导出PDF")
public void downLoadPDF(HttpServletResponse response) throws Exception{
//userService.downLoadPDFByDB(response);
userService.downLoadPDF(response);
}第四步:完成UserService代码
1、在User中添加一个hireDateStr字段
@JsonIgnore //转json时不考虑这个字段
@Transient //表示非数据库字段
private String hireDateStr;2、UserService
public void downLoadPDF(HttpServletResponse response) throws Exception {
// 获取模板文件
String ctxPath = ResourceUtils.getURL("classpath:").getPath();
String filePath = ctxPath+"/pdf_template/userList.jasper";
ServletOutputStream outputStream = response.getOutputStream();
// 文件名
String filename="用户列表数据.pdf";
// 设置两个头 一个是文件的打开方式 一个是mime类型
response.setHeader( "Content-Disposition", "attachment;filename=" + new String(filename.getBytes(),"ISO8859-1"));
response.setContentType("application/pdf");
// 文件的输入流
InputStream inputStream = new FileInputStream(filePath);
//2.创建JasperPrint,向jasper文件中填充数据
Map parameters = new HashMap<>();
// 查询所有数据
List<User> userList = userMapper.selectAll();
// 给hireDateStr赋值
userList = userList.stream().map(user -> {
user.setHireDateStr(simpleDateFormat.format(user.getHireDate()));
return user;
}).collect(Collectors.toList());
JRBeanCollectionDataSource dataSource = new JRBeanCollectionDataSource(userList);
//3.将JasperPrint已PDF的形式输出
JasperPrint jasperPrint = JasperFillManager.fillReport(inputStream,parameters,dataSource);
//导出
JasperExportManager.exportReportToPdfStream(jasperPrint,outputStream);
}
















 2370
2370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









